
分布式事务解决方案原创
数据不会无缘无故丢失,也不会莫名其妙增加
一、概述
1、曾几何时,知了在一家小公司做项目的时候,都是一个服务打天下,所以涉及到数据一致性的问题,都是直接用本地事务处理。
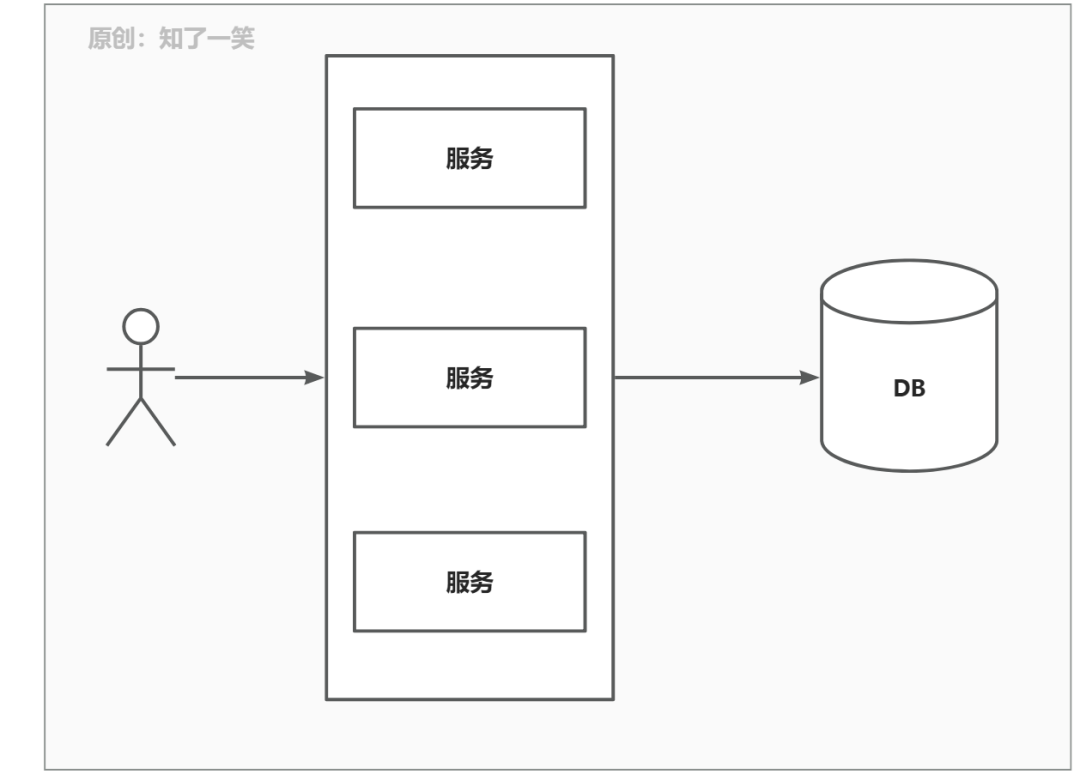
2、随着时间的推移,用户量增大了,发现一个Java服务扛不住了,于是技术大佬决定对于系统进行升级。根据系统的业务对于单体的一个服务进行拆分,然后对于开发人员也进行划分,一个开发人员只开发和维护一个或几个服务中的问题,大家各司其职,分工合作。
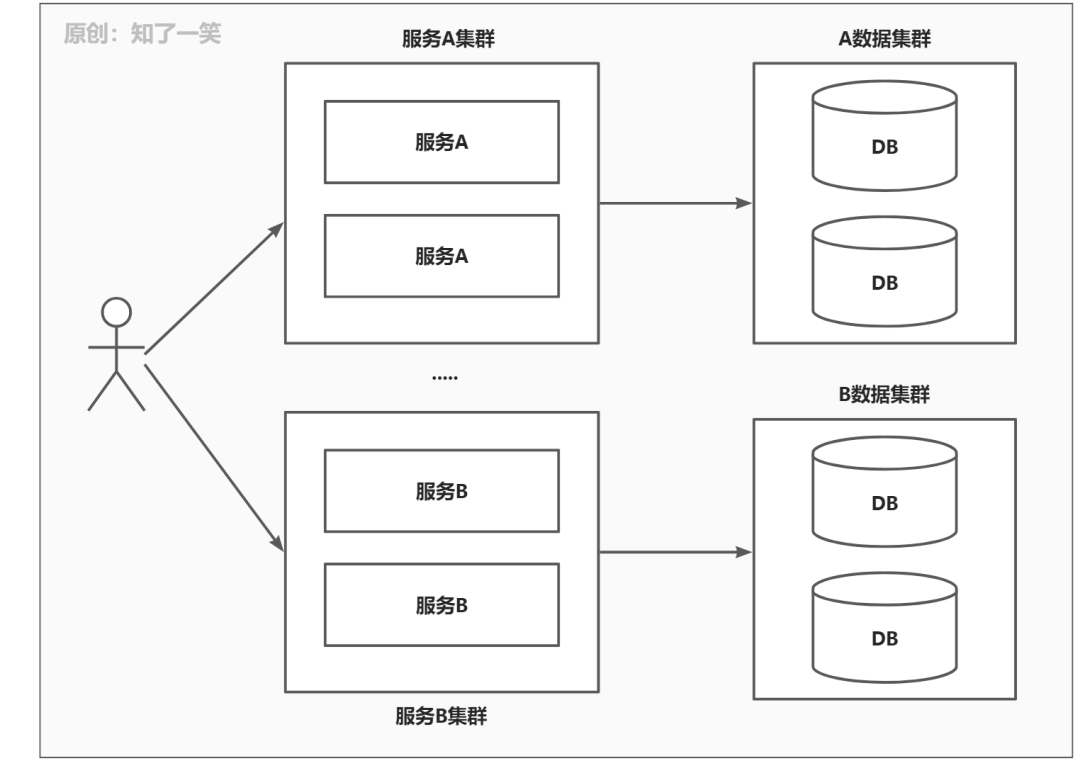
3、当然服务拆分不是一蹴而就的,这是一个耗时耗力的庞大工程,大多数系统都是进行多轮拆分,而后慢慢形成一个稳定的系统。
遵守一个核心思想:先按总体业务进行一轮拆分,后面再根据拆分后的服务模块,进行一个细致的拆分。
4、随着服务拆分之后,用户量是抗住了,但是发现数据都在不同的服务中存取,这就引出了一个新的问题:跨服务器,如何保证数据的一致性?当然,跨服务的分布式系统中不仅仅这个问题,还有其他的一些列问题,如:服务可用性、服务容错性、服务间调用的网络问题等等,这里只讨论数据一致性问题。
5、说到数据一致性,大致分为三种:强一致性、弱一致性、最终一致性。
-
强一致性:数据一旦写入,在任一时刻都能读取到最新的值。 -
弱一致性:当写入一个数据的时候,其他地方去读这些数据,可能查到的数据不是最新的 -
最终一致性:它是弱一致性的一个变种,不追求系统任意时刻数据要达到一致,但是在一定时间后,数据最终要达到一致。
从这三种一致型的模型上来说,我们可以看到,弱一致性和最终一致性一般来说是异步冗余的,而强一致性是同步冗余的,异步处理带来了更好的性能,但也需要处理数据的补偿。同步意味着简单,但也必然会降低系统的性能。
二、理论
上述说的数据一致性问题,其实也就是在说分布式事务的问题,现在有一些解决方案,相信大家多多少少都看到过,这里带大家回顾下。
2.1、二阶段提交
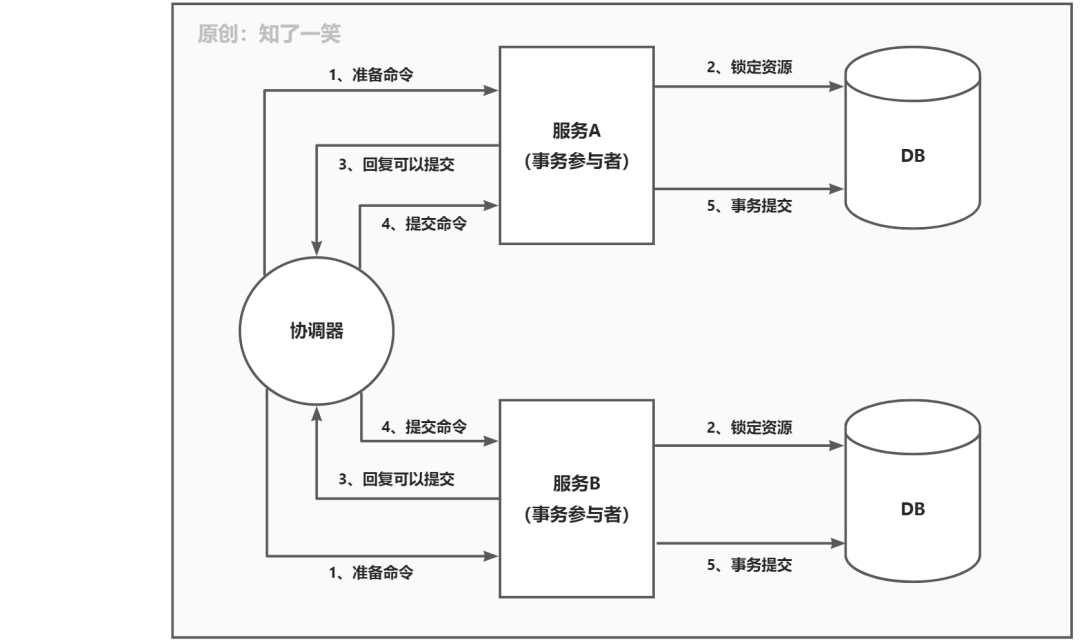
2PC是一种强一致性设计方案,通过引入一个事务协调器来协调各个本地事务(也称为事务参与者)的提交和回滚。2PC主要分为2个阶段:
1、第一阶段:事务协调器会向每个事务参与者发起一个开启事务的命令,每个事务参与者执行准备操作,然后再向事务协调器回复是否准备完成。但是不会提交本地事务,但是这个阶段资源是需要被锁住的。
2、第二阶段:事务协调器收到每个事务参与者的回复后,统计每个参与者的回复,如果每个参与者都回复“可以提交”,那么事务协调器会发送提交命令,参与者正式提交本地事务,释放所有资源,结束全局事务。但是有一个参与者回复“拒绝提交”,那么事务协调器发送回滚命令,所有参与者都回滚本地事务,待全部回滚完成,释放资源,取消全局事务。事务提交流程
事务回滚流程
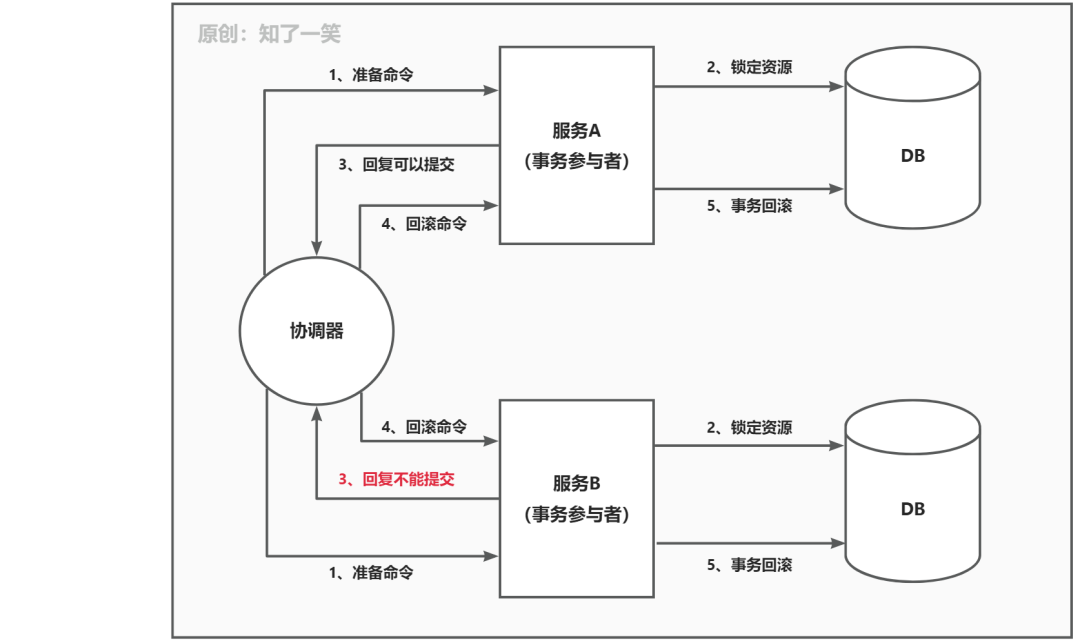
当然2PC存在的问题这里也提一下,一个是同步阻塞,这个会消耗性能。另一个是协调器故障问题,一旦协调器发生故障,那么所有的参与者处理资源锁定状态,那么所有参与者都会被阻塞。
2.2、三阶段提交
3PC主要是在2PC的基础上做了改进,主要为了解决2PC的阻塞问题。它主要是将2PC的第一阶段分为2个步骤,先准备,再锁定资源,并且引入了超时机制(这也意味着会造成数据不一致)。
3PC的三个阶段包括:CanCommit、PreCommit 和 DoCommit 具体细节就不展开赘述了,就一个核心观点:在CanCommit的时候并不锁定资源,除非所有参与者都同意了,才开始锁资源。
2.3、TCC柔性事务
相比较前面的2PC和3PC,TCC和那哥俩的本质区别就是它是业务层面的分布式事务,而2PC和3PC是数据库层面的。
TCC是三个单词的缩写:Try、Confirm、Cancel,也分为这三个流程。
Try:尝试,即尝试预留资源,锁定资源
Confirm:确认,即执行预留的资源,如果执行失败会重试
Cancel:取消,撤销预留的资源,如果执行失败会重试
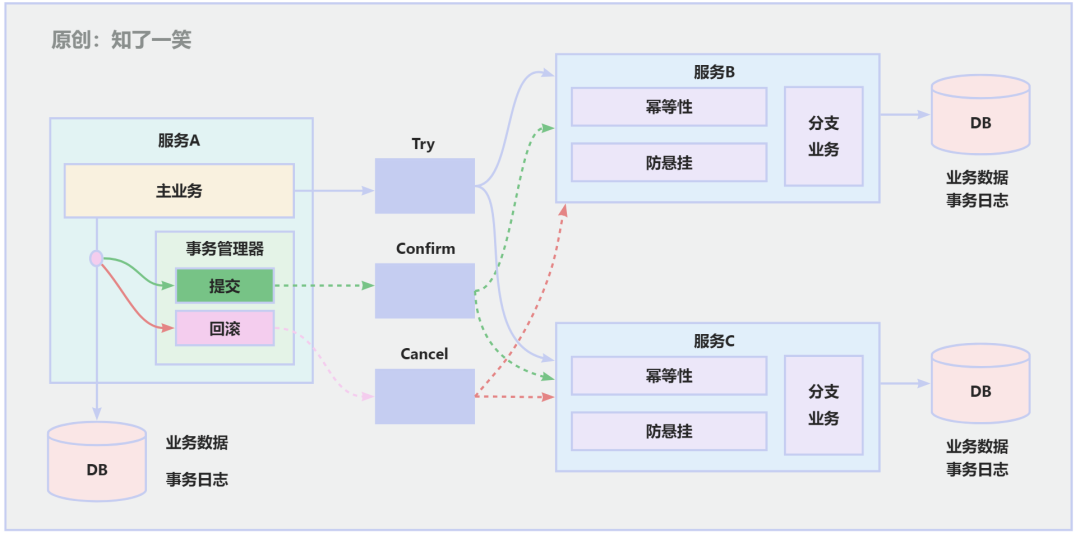
从上图可知,TCC对于业务的侵入是很大的,而且紧紧的耦合在一起。TCC相比较2PC和3PC,试用范围更广,可实现跨库,跨不同系统去实现分布式事务。缺点是要在业务代码中去开发大量的逻辑实现这三个步骤,需要和代码耦合在一起,提高开发成本。
事务日志:在TCC模式中,事务发起者和事务参与者都会去记录事务日志(事务状态、信息等)。这个事务日志是整个分布式事务出现意外情况(宕机、重启、网络中断等),实现提交和回滚的关键。
幂等性:在TCC第二阶段,confirm或者cancel的时候,这两个操作都需要保证幂等性。一旦由于网络等原因导致执行失败,就会发起不断重试。
防悬挂:由于网络的不可靠性,有异常情况的时候,try请求可能比cancel请求更晚到达。cancel可能会执行空回滚,但是try请求被执行的时候也不会预留资源。
2.4、Seata
关于seata这里就不多提了,用的最多的是AT模式,上回知了逐步分析过,配置完后只需要在事务发起的方法上添加@GlobalTransactional注解就可以开启全局事务,对于业务无侵入,低耦合。感兴趣的话请参考之前讨论Seata的内容。
三、应用场景
知了之前在一家公司遇到过这样的业务场景;用户通过页面投保,提交一笔订单过来,这个订单通过上游服务,处理保单相关的业务逻辑,最后流入下游服务,处理业绩、人员晋升、分润处理等等业务。对于这个场景,两边处理的业务逻辑不在同一个服务中,接入的是不同的数据库。涉及到数据一致性问题,需要用到分布式事务。
对于上面介绍的几种方案,只是讨论了理论和思路,下面我来总结下这个业务场景中运用的一种实现方案。采用了本地消息表+MQ异步消息的方案实现了事务最终一致性,也符合当时的业务场景,相对强一致性,实现的性能较高。下面是该方案的思路图
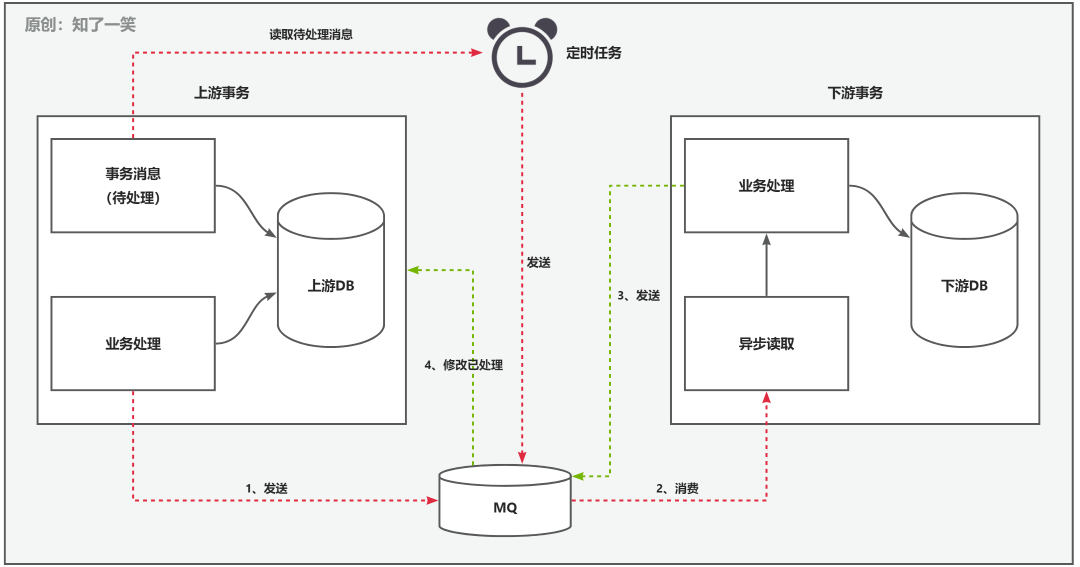
-
真实业务处理的状态可能会有多种,因此需要明确哪种状态需要定时任务补偿 -
假如某条单据一直无法处理结束,定时任务也不能无限制下发,所以本地消息表需要增加轮次的概念,重试多少次后告警,人工介入处理 -
因为MQ和定时任务的存在,难免会出现重复请求,因此下游要做好幂等防重,否则会出现重复数据,导致数据不一致
对于落地实现,话不多说,直接上代码。先定义两张表tb_order和tb_notice_message,分别存订单信息和本地事务信息
CREATE TABLE `tb_order` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`user_id` int(11) NOT NULL COMMENT '下单人id',
`order_no` varchar(255) CHARACTER SET latin1 NOT NULL COMMENT '订单编号',
`insurance_amount` decimal(16,2) NOT NULL COMMENT '保额',
`order_amount` decimal(16,2) DEFAULT NULL COMMENT '保费',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`is_delete` tinyint(4) DEFAULT '0' COMMENT '删除标识:0-不删除;1-删除',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `tb_notice_message` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`type` tinyint(4) NOT NULL COMMENT '业务类型:1-下单',
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '状态:1-待处理,2-已处理,3-预警',
`data` varchar(255) NOT NULL COMMENT '信息',
`retry_count` tinyint(4) DEFAULT '0' COMMENT '重试次数',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`is_delete` tinyint(4) NOT NULL DEFAULT '0' COMMENT '删除标识:0-不删除;1-删除',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4;
处理订单service,这里可以用到我们之前说过的装饰器模式,去装饰这个service。把保存本地事务,发送mq消息,交给装饰器类去做,而service只需要关心业务逻辑即可,也符合开闭原则。
/**
* @author 往事如风
* @version 1.0
* @date 2022/12/13 10:58
* @description
*/
@Service
@Slf4j
@AllArgsConstructor
public class OrderService implements BaseHandler<Object, Order> {
private final OrderMapper orderMapper;
/**
* 订单处理方法:只处理订单关联逻辑
* @param o
* @return
*/
@Override
public Order handle(Object o) {
// 订单信息
Order order = Order.builder()
.orderNo("2345678")
.createTime(LocalDateTime.now())
.userId(1)
.insuranceAmount(new BigDecimal(2000000))
.orderAmount(new BigDecimal(5000))
.build();
orderMapper.insert(order);
return order;
}
}
新增OrderService的装饰类OrderServiceDecorate,负责对订单逻辑的扩展,这里是添加本地事务消息,以及发送MQ信息,扩展方法添加了Transactional注解,确保订单逻辑和本地事务消息的数据在同一个事务中进行,确保原子性。其中事务消息标记处理中,待下游服务处理完业务逻辑,再更新处理完成。
/**
* @author 往事如风
* @version 1.0
* @date 2022/12/14 18:48
* @description
*/
@Slf4j
@AllArgsConstructor
@Decorate(scene = SceneConstants.ORDER, type = DecorateConstants.CREATE_ORDER)
public class OrderServiceDecorate extends AbstractHandler {
private final NoticeMessageMapper noticeMessageMapper;
private final RabbitTemplate rabbitTemplate;
/**
* 装饰方法:对订单处理逻辑进行扩展
* @param o
* @return
*/
@Override
@Transactional
public Object handle(Object o) {
// 调用service方法,实现保单逻辑
Order order = (Order) service.handle(o);
// 扩展:1、保存事务消息,2、发送MQ消息
// 本地事务消息
String data = "{\"orderNo\":\"2345678\", \"userId\":1, \"insuranceAmount\":2000000, \"orderAmount\":5000}";
NoticeMessage noticeMessage = NoticeMessage.builder()
.retryCount(0)
.data(data)
.status(1)
.type(1)
.createTime(LocalDateTime.now())
.build();
noticeMessageMapper.insert(noticeMessage);
// 发送mq消息
log.info("发送mq消息....");
rabbitTemplate.convertAndSend("trans", "trans.queue.key", JSONUtil.toJsonStr(noticeMessage));
return null;
}
}
关于这个装饰者模式,之前有讲到过,可以看下之前发布的内容。
下游服务监听消息,处理完自己的业务逻辑后(如:业绩、分润、晋升等),需要发送MQ,上游服务监听消息,更新本地事务状态为已处理。这需要注意的是下游服务需要做幂等处理,防止异常情况下,上游服务数据的重试。
/**
* @author 往事如风
* @version 1.0
* @date 2022/12/13 18:07
* @description
*/
@Component
@Slf4j
@RabbitListener(queues = "trans.queue")
public class FenRunListener {
@Autowired
private RabbitTemplate rabbitTemplate;
@RabbitHandler
public void orderHandler(String msg) {
log.info("监听到订单消息:{}", msg);
// 需要注意幂等,幂等逻辑
log.info("下游服务业务逻辑。。。。。");
JSONObject json = JSONUtil.parseObj(msg);
rabbitTemplate.convertAndSend("trans", "trans.update.order.queue.key", json.getInt("id"));
}
}
这里插个题外话,关于幂等的处理,我这里大致有两种思路 1、比如根据订单号查一下记录是否存在,存在就直接返回成功。2、redis存一个唯一的请求号,处理完再删除,不存在请求号的直接返回成功,可以写个AOP去处理,与业务隔离。言归正传,上游服务消息监听,下游发送MQ消息,更新本地事务消息为已处理,分布式事务流程结束。
/**
* @author 往事如风
* @version 1.0
* @date 2022/12/13 18:29
* @description
*/
@Component
@Slf4j
@RabbitListener(queues = "trans.update.order.queue")
public class OrderListener {
@Autowired
private NoticeMessageMapper noticeMessageMapper;
@RabbitHandler
public void updateOrder(Integer msgId) {
log.info("监听消息,更新本地事务消息,消息id:{}", msgId);
NoticeMessage msg = NoticeMessage.builder().status(2).id(msgId).updateTime(LocalDateTime.now()).build();
noticeMessageMapper.updateById(msg);
}
}
存在异常情况时,会通过定时任务,轮询的往MQ中发送消息,尽最大努力去让下游服务达到数据一致,当然重试也要设置上限;若达到上限以后还一直是失败,那不得不考虑是下游服务自身存在问题了(有可能就是代码逻辑存在问题)。
/**
* @author 往事如风
* @version 1.0
* @date 2022/12/14 10:25
* @description
*/
@Configuration
@EnableScheduling
@AllArgsConstructor
@Slf4j
public class RetryOrderJob {
private final RabbitTemplate rabbitTemplate;
private final NoticeMessageMapper noticeMessageMapper;
/**
* 最大自动重试次数
*/
private final Integer MAX_RETRY_COUNT = 5;
@Scheduled(cron = "0/20 * * * * ? ")
public void retry() {
log.info("定时任务,重试异常订单");
LambdaQueryWrapper<NoticeMessage> wrapper = Wrappers.lambdaQuery(NoticeMessage.class);
wrapper.eq(NoticeMessage::getStatus, 1);
List<NoticeMessage> noticeMessages = noticeMessageMapper.selectList(wrapper);
for (NoticeMessage noticeMessage : noticeMessages) {
// 重新发送mq消息
rabbitTemplate.convertAndSend("trans", "trans.queue.key", JSONUtil.toJsonStr(noticeMessage));
// 重试次数+1
noticeMessage.setRetryCount(noticeMessage.getRetryCount() + 1);
noticeMessageMapper.updateById(noticeMessage);
// 判断重试次数,等于最长限制次数,直接更新为报警状态
if (MAX_RETRY_COUNT.equals(noticeMessage.getRetryCount())) {
noticeMessage.setStatus(3);
noticeMessageMapper.updateById(noticeMessage);
// 发送告警,通知对应人员
// 告警逻辑(短信、邮件、企微群,等等)....
}
}
}
}
其实这里有个问题,一个上游服务对应多个下游服务的时候。这个时候往往不能存一条本地消息记录。
-
这里可以在消息表多加个字段next_server_count,表示一个订单发起方,需要调用的下游服务数量。上游服务监听的时候,每次会与下游的回调都减去1,直到数值是0的时候,再更新状态是已处理。但是要控制并发,这个字段是被多个下游服务共享的。 -
还有一种处理方案是为每个下游服务,都记录一条事务消息,用type字段去区分,标记类型。实现上游和下游对于事务消息的一对一关系。 -
最后,达到最大重试次数以后,可以将消息加入到一个告警列表,这个告警列表可以展示在管理后台或其他监控系统中,展示一些必要的信息,去供公司内部人员去人工介入,处理这种异常的数据,使得数据达到最终一致性。
四、总结
编程文档:
https://gitee.com/cicadasmile/butte-java-note
应用仓库:
https://gitee.com/cicadasmile/butte-flyer-parent

