
【全网首发】inline: 我的理解还停留在20年前原创
你好,我是雨乐~
在上篇文章访问私有变量——从技术实现的角度破坏"封装"性一文中,在第二个实现示例中,用到了inline 变量,一开始,是懵逼的,因为在我的印象中inline 仅仅函数,而在此处却用于声明变量。于是,赶紧去查阅资料,发现自CPP17开始,引入了inline 变量,这个时候突然不是那么自责了,毕竟我的cpp知识积累止步于cpp11。不过,为了研究那段代码,还是仔细研究了下,不看不要紧,一看吓一跳,原来我对inline的理解停留在n年前。于是赶紧恶补这方面的知识,而这篇文章呢,就是我最近研究的一个知识点总结。
狭隘的理解
inline源于C,与关键字register作用一样,旨在让编译器进行优化,inline的思想源自于C的预处理宏,而后者又源自汇编语言。其目标是省略因为函数调用而引起的部分开销。与预处理宏不一样的是,inline支持类型检查,而这就是inline引入C++的初衷(旨在具有宏的功能,且支持类型检查)。
在编译过程中,编译器维护了一组数据结构,称之为**符号表(Symbol Table)**。对于普通函数,编译器只把函数名称(对于c++来说,需要经过name mangling,毕竟运行函数重载,而C则不需要)和返回值记录在符号表里。而对于inline函数(编译器确认可以inline的),除上述的函数名称和返回值之外,也将函数的实现(究竟存放源代码还是编译后的汇编指令就看编译器的实现了)放在符号表中。当遇到内联函数的调用时,编译器首先检查调用是否正确(参数类型检查,返回结果是否被正确使用——对于普通函数也进行这些检查),检查无误后将内联函数的函数体替换掉对它的调用,从而省去调用函数的开销(参数入栈,汇编CALL等),这就是inline后性能优于普通函数调用的原因。
当然了,编译器是否决定inline,有它自己的规则,代码中指定inline关键字也只是建议编译器内联,最终是否真正inline取决于具体场景。
以上,就是我对inline的理解,也就是说在之前,我的错误理解是inline作用仅限于inline function,即编译时进行指令替换。
概念
在阅读本文后面的章节之前,需要先了解两个概念ADL和ODR。
ADL
ADL是Argument Dependent Lookup的缩写,又称为Koenig Lookup(最开始以发明人的名称进行命名),一般译为参数依赖查找,是用于在函数调用表达式中查找非限定函数名称的规则集。
可以理解为如果在使用函数的上下文中找不到函数定义,我们可以在其参数的名字空间中查找该函数的定义。
c++11标准对其定义如下:
When the postfix-expression in a function call (5.2.2) is an unqualified-id, other namespaces not considered during the usual unqualified lookup (3.4.1) may be searched, and in those namespaces, namespace-scope friend function declarations (11.3) not otherwise visible may be found. These modifications to the search depend on the types of the arguments (and for template template arguments, the namespace of the template argument).
这种方式其实我们经常用到,比如,在上篇文章访问私有成员——从技术实现的角度破坏"封装" 性友元函数那一块已经用到了(在类内进行函数定义(参数为类类型),类外无序声明可以直接调用),只是没有留意罢了~~
通过个例子来简单理解下,该例子来源于stackoverflow:
namespace MyNamespace {
class MyClass {};
void doSomething(MyClass) {}
}
MyNamespace::MyClass obj; // global object
int main() {
doSomething(obj); // Works Fine - MyNamespace::doSomething() is called.
}如上例,doSomething()首先在其上下文中查找定义(namespace的除外),没有找到,然后依赖了ADL规则,在其参数obj所在范围(MyNamespace)内找到了定义,所以编译正常。
ODR
ODR是One definition Rule的缩写,中文称之为单一定义规则。
cppreference中的定义如下:
Only one definition of any variable, function, class type, enumeration type, concept (since C++20) or template is allowed in any one translation unit (some of these may have multiple declarations, but only one definition is allowed).
One and only one definition of every non-inline function or variable that is odr-used (see below) is required to appear in the entire program (including any standard and user-defined libraries). The compiler is not required to diagnose this violation, but the behavior of the program that violates it is undefined.
从上述定义,可以看出,对于声明为非inline的函数或者变量,在整个程序里只允许有一个定义。而如果有多个的话,则会破坏ODR原则,在链接阶段因为多个符号冲突而失败。
C++程序通常由多个C++源文件组成(.cc/.cpp等),编译器在进行编译的时候,通常是将这些文件单独编译成模块或者目标文件,然后通过链接器将所有模块/目标文件链接到一个可执行文件或共享/静态库中。
在链接阶段,如果链接器可以找到多个同一个符号的定义,则认为是错误的,因为其不知道使用哪个,这个时候,就会出现链接器报错,如下这种:
error: redefinition of 'xxx'
而这个报错原因,就是因为没有遵循ODR原则,下图易于理解:
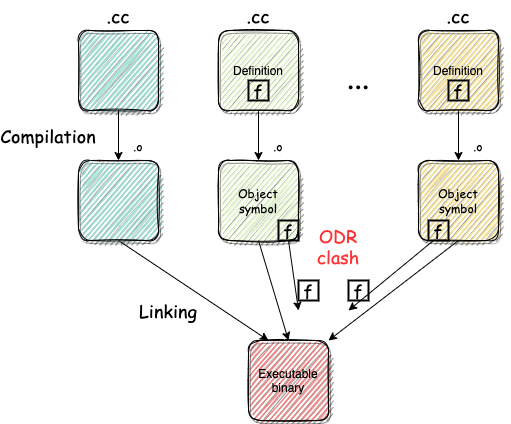
也就是说,函数或者变量在整个程序中只能定义一次(全局,非namespace 非inline等),而这种规则,往往使得我们在编码的时候,将声明放到某个头文件,比如header.h,而将定义放在header.cc。但是,往往在多人协作项目中,这种很难满足,比如对于函数名相同,参数相同,而实现不同,对于这种如果不采取其他方式的话,往往就会破坏ODR原则,导致链接失败。对于这种情况,往往使用static定义、namespace以及本文要讲的inline。
inline function
下面看下inline function的定义:
An inline function is one for which the compiler copies the code from the function definition directly into the code of the calling function rather than creating a separate set of instructions in memory.
从上面的定义可以看出,对于声明为inline的函数,在调用该inline函数的时候,编译器会直接进行代码替换,也就是说省略了函数调用这个步骤。
我们先看一段代码,如下:
inline int add(int a, int b){
return a + b;
}
int main(){
int x = 3
int y = 4;
int z = add(x, y);
// do sth
return 0;
}编译器会将上述代码优化为:
int main(){
int x = 3
int y = 4;
int z = x + y; // inline 代码替换
// do sth
return 0;
}
当然,上述是从编译器对inline函数处理的角度来理解的,往往编译器会进行更加直接的优化,即优化成int z = 7。
以上,可能就是大部分人认为的inline function,即对function 加 inline关键字以建议编译器将该函数进行inline。
但是,建议往往是建议,对于编译器来说,大部分的建议都不会被采纳,它(编译器)总是有自己的理由来决定在什么地方进行inline,什么地方进行函数调用,也就是说,编译器比开发人员更加清楚什么地方应该inline。或者说,大部分人认为的inline function,在理解上是狭隘的,或者说,对于Modern CPP来说,这种理解是错误的,是过时的。
inline 关键字用于函数,有两个作用,第一个作用(相对老版本编译器来说),就是前面说的(指令或者代码替换);而第二个,使得在多个翻译单元(Translation Unit, 在此可以理解为.cc/.cpp等源文件)定义同名同参函数成为了可能。
先看下面的代码:
file1.cc
int f() {
return 0;
}
int main() {
return f();
}
file2.cc
int f() { return 0; }使用如下命令进行编译:
gcc file1.cpp file2.cpp
在链接的时候,报错如下:
file2.cc:(.text+0x0): multiple definition of `f()'相信这种报错,大家都遇到过,而且不止一次。这是因为编译器在进行编译的时候,是以(.cc/cpp等)文件为单元进行单独编译成.o文件,然后在链接阶段对这些.o文件进行链接,发现有重复定义,这也就有了上面的报错,这种错误的根本原因就是违反了ODR原则。
这个时候,就是inline大显身手的时候。
在定义函数的时候,前面加上inline关键字,就可以避免上面的重复定义错误,这种做法相当于告诉编译器:在编译的时候,遇到这种包含inline关键字的重复定义函数,不用再报错了😁。
仍然是上述代码,唯一的区别就是在函数定义部分加了inline:
file1.cc
inline int f() {
return 0;
}
int main() {
return f();
}file2.cc
inline int f() { return 0; }编译,链接一切正常。
好了,现在回顾下前面那个例子报错的原因(重复定义嘛,废话)。编译器在编译的时候,只针对当前Translation Unit,也就是说编译器无法访问本翻译单元之外的目标文件(也就是说在编译当前文件的时候,不能查找之前的已经编译完成的目标文件是否有该函数定义),因此这种错误往往暴露在链接阶段,因为链接阶段每个函数仅允许有一个定义体。而对于具有关键字inline的函数声明或者定义,链接器在链接阶段,一但发现具有多个定义的inline函数,其只取一个,因此,对于同名同参的inline函数,如果其实现不同,则会引起未定义行为(链接器只取其中一个,具体规则依赖于编译器)。
对于现在的编译器来说,inline 函数的功能更趋向于解决ODR问题,而至于传统意义理解上的替换等则可以忽略,这个仅仅是开发人员对编译器的一种建议,是否替换完全由编译器决定。
No matter how you designate a function as
inline, it is a request that the compiler is allowed to ignore: the compiler might inline-expand some, all, or none of the places where you call a function designated asinline.
inline variable
在C++中,类内变量的初始化经历了多次变动,每一次的变动都是因为前一次的初始化方式太过麻烦,究根到底,还是因为类内成员的初始化不能像一般变量一样,在声明的同时就加以定义。
假设有一个类Test,在C++11之前,初始化其变量,往往是这种方式:
class Test {
public:
Test() : value_(0) {}
private:
int value_;
};如果多一个构造函数的话,我们得这样写:
class Test {
public:
Test() : value_(0) {}
Test(bool) : value_(0) {}
private:
int value_;
};这种初始化变量的方式的缺点显而易见,有几个构造函数,就得初始化几次变量,很麻烦,且一不小心就容易出错。
为了解决上述问题,在C++11起,可以在类内直接对变量进行初始化,即支持non-static data member initializer,如下:
class Test {
private:
int value_ = 0;
};这样一来,即使有多个构造函数,成员变量初始化也仅需一次即在声明的时候直接进行初始化,而且便于阅读。
奈何历史债务还是太多了,C++11支持对非静态成员进行直接初始化,但是静态成员呢?貌似跟pre cpp11一样,没啥变化,如下:
class Test {
public:
static int value;
};
int Test::value = 1;如果我们直接在类内对静态变量进行定义的话,如下:
class Test {
private:
static int value_ = 0;
};则会编译失败,报错如下:
error: ISO C++ forbids in-class initialization of non-const static member 'Test::value_'为了像cpp11支持类内初始化成员变量一样,自cpp17起,对于静态成员也支持在声明时候进行初始化,即:
class Test {
private:
inline static int value_ = 0;
};与inline function一样,inline variable也允许在多个编译单元对同一个变量进行定义,并且在链接时只保留其中的一份作为该变量的定义。当然,同时在多个源文件中定义同一个inline变量必须保证它们的定义都相同,否则和inline函数一样,你没办法保证链接器最终采用的是哪个定义。
inline variable除了支持类内静态成员初始化外,也支持头文件中定义全局变量,这样不会违反ODR规则。
inline namespace
inline namespace自c++11引入,其主要作用在于版本控制,开发人员可以在namespace内建立抽象层,进而进行不同的版本切换,而无需对代码进行太多更改。
假设有这样一个场景,作为开发人员,我们需要对外提供一个库,作为该库的提供者,在版本升级的时候,需要做到向下兼容,而不是每次都升级后都需要使用者重新使用该最新的库编译其项目,换句话说,库的升级,要求对之前的版本无影响,而只有使用最新库的项目才能使用其最新的功能。
在项目最初,我们提供的库源码如下:
namespace mylib {
namespace v1 {
void foo();
}
using namespace v1;
}将该库交付出去后,使用者可以通过mylib::foo()(实际上调用的是mylib::v1::foo())这种方式进行调用,一切正常。
过了一段时间后,需要进行版本更迭,对该库进行升级,代码如下:
namespace mylib {
namespace v1 {
void foo();
}
namespace v2 {
void foo();
}
using namespace v2;
}好了,截止到目前,我们版本升级正常,在c++11之前,也确实是这么做的,不过这么做也确实有其局限性,也有很多场景下,使用using namespace具有其局限性。
override
如下代码场景:
namespace mylib {
namespace v1 {
void foo() {}
void foo(int a){}
}
using namespace v1;
void foo(char *str){}
}
int main() {
mylib::foo("abc"); // 编译成功
mylib::foo(1); // 编译失败
mylib::foo(); // 编译失败
return 0;
}虽然通过using namespace让namespace v1下的两个函数foo()和foo(int)暴露在mylib下,但是外层的foo(char*)又把v1下的两个foo()函数覆盖了,这就main()中mylib::foo("abc")编译成功,而mylib::foo(1)和mylib::foo()编译失败的原因。
template specialization
不能使用using namespace的场景就行模板特化。
假设我们提供了个库,其代码如下:
namespace mylib {
namespace lib {
template<typename T> class MyClass{};
}
using namespace lib;
}
使用者通过mylib::MyClass 方式进行操作,如果某一天,使用者想对该模板类进行特化,即:
namespace mylib {
template<> class MyClass<Object>{};
}编译失败,这是因为c++98中,模板特化必须放在模板所需空间内,也就是说需要这样做:
namespace mylib {
namespace lib {
template<> class MyClass<Object>{};
}
}上面这种做法无疑是没问题的,但这样做的话,会暴露代码命名规则(虽然只是部分)。
ADL
示例如下:
namespace mylib {
class Class1 {};
namespace lib {
void foo1(Class1) {};
class Class2 {};
}
using namespace lib;
void foo2(Class2) {};
}
int main() {
mylib::Class1 c1;
mylib::Class2 c2;
foo1(c1);
foo2(c2);
}上述代码编译失败,这是因为使用using namespace只能保证被看到,而ADL规则在乎的则是被定义(这块比较抽象😁)。
inline
在前面的内容中,提到了使用using namespace也有其局限性,并不能满足所有场景,这个时候inline闪亮出场~~
对于覆盖问题,在namespace v1前加上inline即可,代码如下:
namespace mylib {
inline namespace v1 {
void foo() {}
void foo(int a){}
}
void foo(char *str){}
}
int main() {
mylib::foo("abc"); // 编译成功
mylib::foo(1); // 编译成功
mylib::foo(); // 编译成功
return 0;
}对于模板特化,使用inline如下:
namespace mylib {
inline namespace lib {
template<typename T> class MyClass{};
}
}
namespace mylib {
template<> class MyClass<Object>{};
}同样,对于ADL,仍然可以使用inline,如下:
namespace mylib {
class Class1 {};
inline namespace lib {
void foo1(Class1) {};
class Class2 {};
}
void foo2(Class2) {};
}
int main() {
mylib::Class1 c1;
mylib::Class2 c2;
foo1(c1);
foo2(c2);
}依然回到本节一开始的内容中,提到了inline namespace主要被用来做版本控制,依据上面的规则,我们很容易写出迭代代码
namespace mylib {
namespace v1 {
void foo();
}
}
// 版本2
namespace mylib {
namespace v1 {
void foo();
}
inline namespace v2 {
void foo();
}
}进退有度
示例代码如下:
namespace mylib {
inline namespace lib1 {
struct Object{};
}
namespace lib2 {
Object a; // ok,使用A::Object
struct Object{};
Object c; // ok, 使用C::Object
lib1::Object d; // ok,使用A::Object
}
}通过之前的内容,我们了解到加了inline的子namespace,对于其父namespace来说,就像在父namespace中声明定义的一样,即在namespace lib2中,变量a的类型是lib1::Object,而在lib2::Object对象定义后,c的类型为lib2::Object,也就是说其覆盖了之前的lib1::Object,显然破坏了namespace的隔离性(namespace为了隔离性而引入),而这也是Google Style建议不要使用inline namespace的原因。
俗话说,存在即合理,在使用方式上恰当的使用,往往会带来更多的便捷,否则...
今天的文章就到这,我们下期见!
你好,我是雨乐,从业十二年有余,历经过传统行业网络研发、互联网推荐引擎研发,目前在广告行业从业8年。目前任职某互联网公司高级技术专家一职,负责广告引擎的架构和研发。

