
一次偶然机会发现的MySQL“负优化”转载
最开始先给大家两条sql,请猜猜他们执行会有什么区别?
SELECT * from student s where age < 17 and name ='zhangsan12'
and create_time < '2023-01-17 10:23:08' order by age LIMIT 1
SELECT * from student s where age < 17 and name ='zhangsan12'
and create_time < '2023-01-17 10:23:08' order by age LIMIT 2
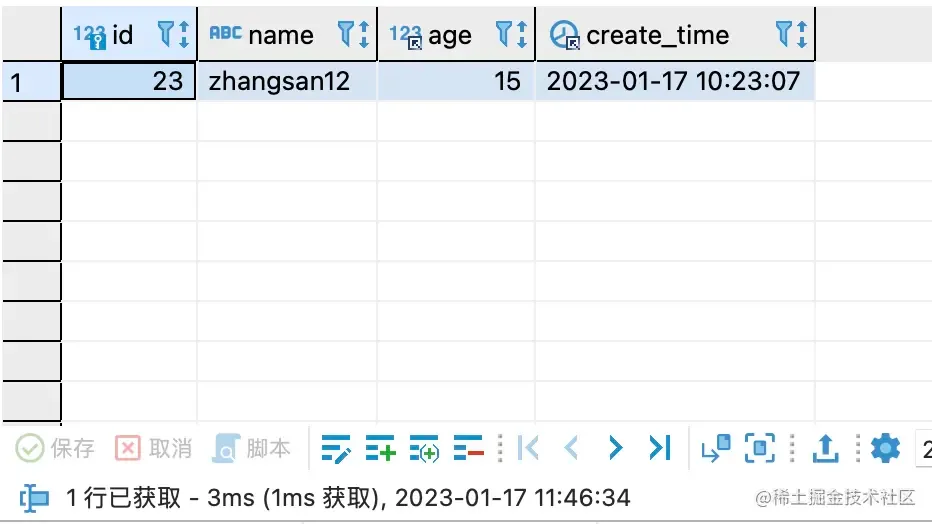
这两条sql看似只是limit的数值不同,但是第一个执行耗时3ms,第二个执行耗时66s,「相差2000多倍」。
故事的起因
今天要讲的这件事和上述的两个sql有关,是数年前遇到的一个关于MySQL查询性能的问题。主要是最近刷到了一些关于MySQL查询性能的文章,大部分文章中讲到的都只是一些常见的索引失效场合,于是我回想起了当初被那个离奇的“索引失效”支配的恐惧。
场景复现
由于事情已经过去多年,因此我只能凭借记忆在本地的数据库进行模拟。首先创建数据库school,数据表student:
CREATE TABLE `student` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
`age` int DEFAULT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `student_age_IDX` (`age`) USING BTREE,
KEY `student_create_time_IDX` (`create_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
结构简单明了,其中age和create_time使用BTREE构建了索引。
在使用存储过程往数据库填充了500w条左右的数据后,我们使用如下的sql来进行测试:
SELECT * from student s where age < 17 and name ='zhangsan12' and create_time < '2023-01-17 10:23:08' order by age LIMIT 1
结果如下:
之后尝试执行如下sql:
SELECT * from student s where age < 17 and name ='zhangsan12' and create_time < '2023-01-17 10:23:08' order by age LIMIT 2
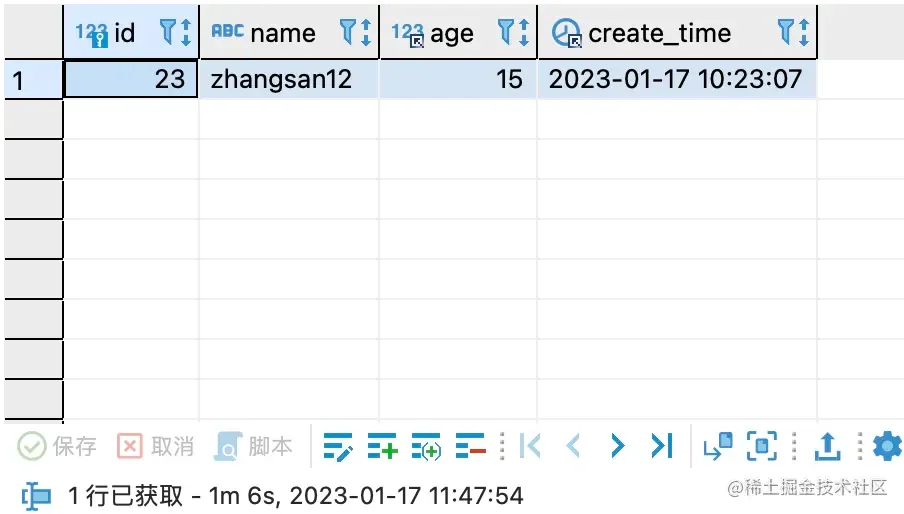
查询结果
这就是我们开篇提到的那两个sql,性能差距是2000多倍。那么问题来了,为什么limit的值会影响sql性能,并且会差别如此之大?故事要从MySQL的优化说起。
MySQL的“负优化”
在分析sql性能的时候,我们当然最常用的是EXPLAIN,将两个sql分别EXPLAIN,结果如下:


可以看到sql执行计划并无二致,那么为什么执行时间却相差这么远呢?
查找相关文档就可以在MySQL的官网找到如下的解释:
❝If you combine LIMIT row_count with ORDER BY, MySQL stops sorting as soon as it has found the first row_count rows of the sorted result, rather than sorting the entire result. If ordering is done by using an index, this is very fast. If a filesort must be done, all rows that match the query without the LIMIT clause are selected, and most or all of them are sorted, before the first row_count are found. After the initial rows have been found, MySQL does not sort any remainder of the result set.
❞
大致意思就是LIMIT与ORDER BY一起使用MySQL会在找到LIMIT设定的值后立即返回。虽然没有找到具体的原理性的解释,但是从上述的这个描述中我们也能够大致理解这个思路了。
在MySQL中LIMIT与ORDER BY是特殊的组合,尤其是当ORDER BY中的存在BTREE索引的情况下。
普通的查询是根据条件进行筛选,然后在结果集中排序,然后获取LIMIT条数的数据,但是在具备上述条件的特殊sql中执行逻辑是这样的,根据ORDER BY字段的B+树索引来查找满足条件的数据,直到凑满LIMIT设定的数值为止,这就存在一个问题,在结果集中的数据大于LIMIT的场景下,这个性能固然是非常棒的,但是如果最后的结果集中的数据小于LIMIT,就会存在永远凑不满的情况,所以最终这个MySQL的性能优化就会变成全表扫描的“负优化”。
「根据上述的情况来看的话我们可以大胆猜测,既然是索引导致的优化问题,那么是不是把age字段的索引去掉反而会更快?」
手动执行DROP INDEX student_age_IDX ON school.student删除索引,然后执行语句,果然执行速度变成了毫秒级:
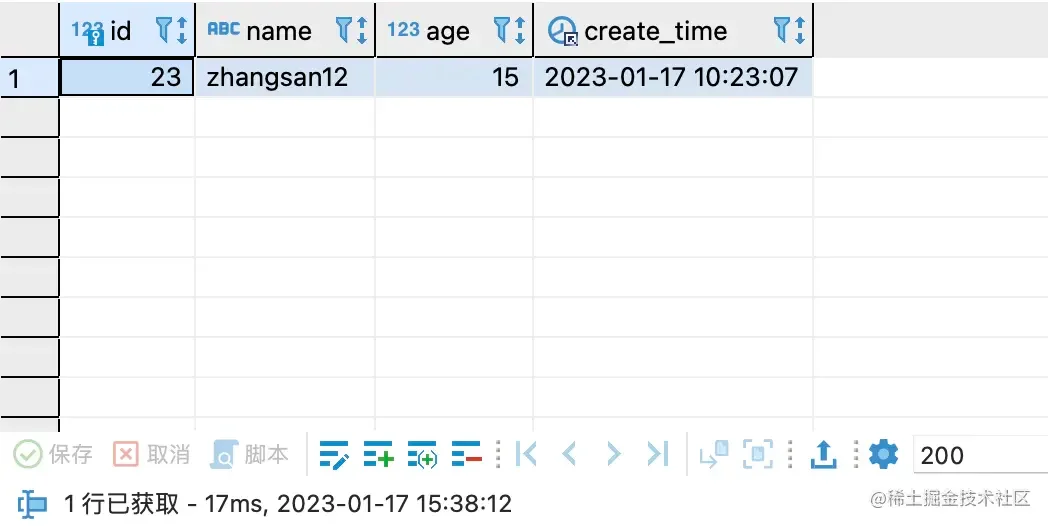
查看执行计划发现在执行时使用了create_time的索引,因此其速度也能保持在毫秒级。

然后我们干脆把create_time的索引也去除掉:

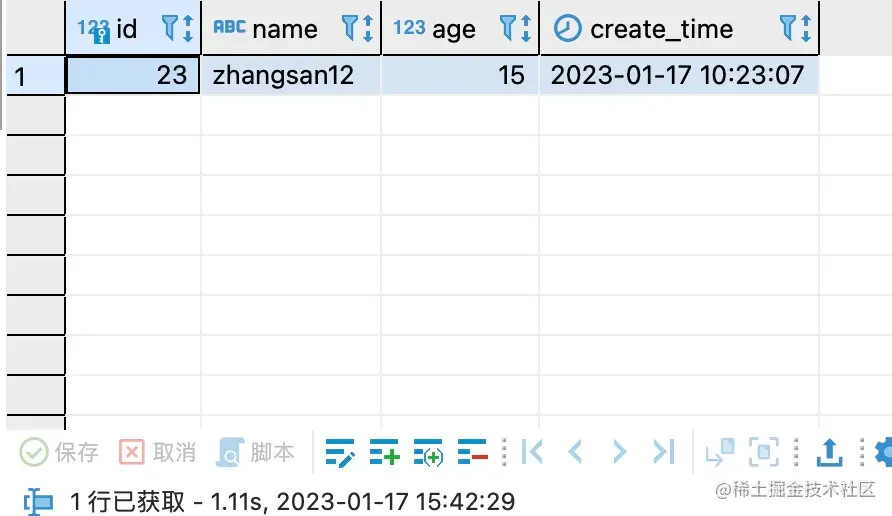
可以看到没有索引的情况下耗时也不过是1秒出头,远远不是66秒。可见在这种情况下MySQL的性能优化甚至远远比不上无索引的查询。
总结
其实出现这个问题的场景也不算十分特殊,但是排查原因相当困难。当初是花了好几天查资料翻文档加上不断实验才找到了问题所在。只能说MySQL在解析和执行sql的背后做了很多的优化,但是这部分对于不够熟悉了解的人来说确实是太黑盒,遇到类似的问题排查也很困难。也许这就是程序员成长路上的必经之路吧。


