
Apache Kafka入门级教程原创
Apache Kafka是什么?
摘抄自官网首页的一段话: Apache Kafka 是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序。
核心能力
Kafka具有高吞吐量,高可用性,永久存储于可用性的特性如下图所示:
高吞吐量
使用延迟低至 2 毫秒的机器集群以网络有限的吞吐量传递消息。
可扩展
将生产集群扩展到一千个代理、每天数万亿条消息、PB级数据、数十万个分区。弹性扩展和收缩存储和处理。
永久存储
将数据流安全地存储在分布式、持久、容错的集群中。
高可用性
在可用区域上有效地扩展集群或跨地理区域连接单独的集群。
生态系统
Kafka经过多年的发展生态系统已经非常庞大与丰富了,如下图所示:
内置流处理
使用事件时间和精确一次处理,通过连接、聚合、过滤器、转换等处理事件流。
连接到几乎任何东西
Kafka 开箱即用的 Connect 接口与数百个事件源和事件接收器集成,包括 Postgres、JMS、Elasticsearch、AWS S3 等。
客户端库
使用大量编程语言读取、写入和处理事件流。
大型生态系统开源工具
大型开源工具生态系统:利用大量社区驱动的工具。
信任和易用性
关键任务
通过保证排序、零消息丢失和高效的一次性处理来支持任务关键型用例。
被成千上万的组织信任
从互联网巨头到汽车制造商再到证券交易所,成千上万的组织都在使用Kafka。超过 500 万次独特的终身下载。
庞大的用户社区
Kafka 是 Apache 软件基金会五个最活跃的项目之一,在世界各地有数百场聚会。
丰富的在线资源
丰富的文档、在线培训、指导教程、视频、示例项目、Stack Overflow 等。
Kafka是如何工作的?
Kafka 是一个分布式系统,由通过高性能TCP 网络协议进行通信的服务器和客户端组成。它可以部署在本地和云环境中的裸机硬件、虚拟机和容器上。
服务端:
Kafka 作为一个或多个服务器的集群运行,可以跨越多个数据中心或云区域。其中一些服务器形成存储层,称为代理。其他服务器运行 Kafka Connect以将数据作为事件流持续导入和导出,以将 Kafka 与您现有的系统(例如关系数据库以及其他 Kafka 集群)集成。为了让您实现关键任务用例,Kafka 集群具有高度可扩展性和容错性:如果其中任何一个服务器出现故障,其他服务器将接管它们的工作,以确保持续运行而不会丢失任何数据。
客户端:
它们允许您编写分布式应用程序和微服务,以并行、大规模和容错方式读取、写入和处理事件流,即使在网络问题或机器故障的情况下也是如此。Kafka 附带了一些这样的客户端,这些客户端由 Kafka 社区提供的 数十个客户端增强:客户端可用于 Java 和 Scala,包括更高级别的 Kafka Streams库,用于 Go、Python、C/C++ 和许多其他编程语言以及 REST API。
快速入门使用
第 1 步:获取 KAFKA
下载最新的 Kafka 版本并解压:
$ wget https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz$ tar -xzf kafka_2.13-3.1.0.tgz$ cd kafka_2.13-3.1.0

第 2 步:启动KAFKA环境
注意:您的本地环境必须安装 Java 8+。
运行以下命令以按正确顺序启动所有服务:
1) 安装Java环境这里我以Centos yum安装 jdk11为例
-
查看本机是否自带java
rpm -qa|grep java-
有则卸载(选做)
rpm -e --nodeps java*-
查看yum中jdk版本
yum search jdk-
列出java11
yum list |grep java-11安装必要的(-y表示安装过程中都默认yes)
yum install -y java-11-openjdk.x86_64yum install -y java-11-openjdk-devel.x86_64yum install -y java-11-openjdk-headless.x86_64
启动Zookeeper
注意:很快,Apache Kafka将不再需要ZooKeeper。 下面这个Zookeeper是Kafka自带的Zookeeper 这个版本是3.6.3,Zookeeper启动命令如下所示:
bin/zookeeper-server-start.sh config/zookeeper.properties
启动kafka
打开另一个终端会话并运行:
bin/kafka-server-start.sh config/server.properties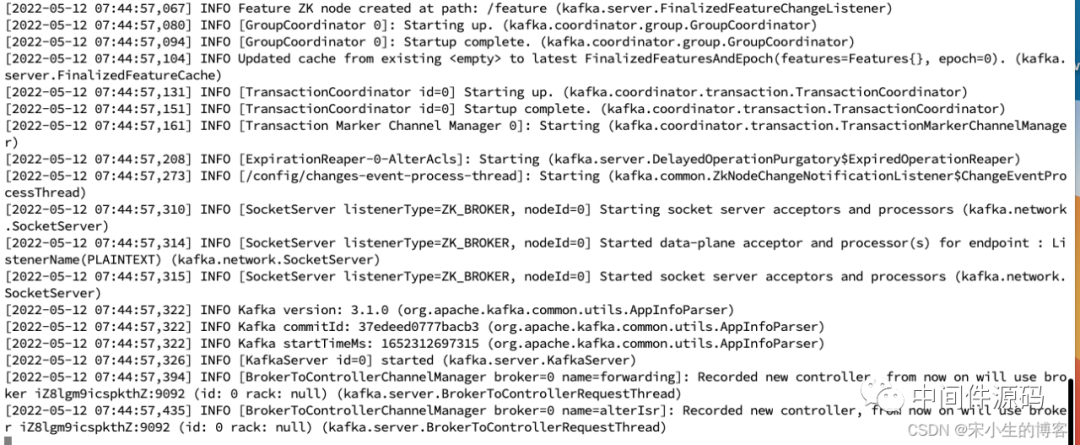
成功启动所有服务后,您将拥有一个基本的 Kafka 环境运行并可以使用。
第 3 步:创建一个主题来存储您的事件
Kafka 是一个分布式事件流平台,可让您跨多台机器 读取、写入、存储和处理 事件(在文档中也称为记录或 消息)。
示例事件包括支付交易、来自手机的地理位置更新、运输订单、来自物联网设备或医疗设备的传感器测量等等。这些事件被组织并存储在 主题中。非常简化,主题类似于文件系统中的文件夹,事件是该文件夹中的文件。
因此,在您编写第一个事件之前,您必须创建一个主题。打开另一个终端会话并运行:
bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
Kafka 的所有命令行工具都有其他选项:运行kafka-topics.sh不带任何参数的命令以显示使用信息。例如,它还可以显示 新主题 的分区数等详细信息:
bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092Topic:quickstart-events PartitionCount:1 ReplicationFactor:1 Configs: Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0
第 4 步:将一些事件写入主题
Kafka 客户端通过网络与 Kafka 代理通信以写入(或读取)事件。一旦收到,代理将以持久和容错的方式存储事件,只要您需要 - 甚至永远。
运行控制台生产者客户端将一些事件写入您的主题。默认情况下,您输入的每一行都会导致将一个单独的事件写入主题。
bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092This is my first eventThis is my second event
您可以随时停止生产者客户端Ctrl-C
第 5 步:消费事件
打开另一个终端会话并运行控制台使用者客户端以读取您刚刚创建的事件:
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092This is my first eventThis is my second event执行命令后会将所有消息消费掉入下图所示:

您可以随时停止消费者客户端Ctrl-C
随意尝试:例如,切换回您的生产者终端(上一步)以编写其他事件,并查看事件如何立即显示在您的消费者终端中。
因为事件被持久地存储在 Kafka 中,所以它们可以被尽可能多的消费者多次读取。您可以通过打开另一个终端会话并再次重新运行上一个命令来轻松验证这一点。
终止 Kafka 环境
现在您已经完成了快速入门,请随意拆除 Kafka 环境,或者继续玩。
Ctrl-C如果您还没有这样做,请 使用 停止生产者和消费者客户端。使用 停止 Kafka 代理Ctrl-C。最后,使用 . 停止 ZooKeeper 服务器Ctrl-C。如果您还想删除本地 Kafka 环境的任何数据,包括您在此过程中创建的任何事件,请运行以下命令:
$ rm -rf /tmp/kafka-logs /tmp/zookeeperKafka的概念和术语
事件
事件记录了世界或您的业务中“发生了某事” 的事实。在文档中也称为记录或消息。当您向 Kafka 读取或写入数据时,您以事件的形式执行此操作。从概念上讲,事件具有键、值、时间戳和可选的元数据标头。这是一个示例事件:
-
事件键:“爱丽丝”
-
事件值:“向 Bob 支付了 200 美元”
-
事件时间戳:“2020 年 6 月 25 日下午 2:06”
生产者和消费者
-
生产者是那些向 Kafka 发布(写入)事件的客户端应用程序
-
消费者是订阅(读取和处理)这些事件的那些客户端应用程序
-
在 Kafka 中,生产者和消费者完全解耦并且彼此不可知,这是实现 Kafka 众所周知的高可扩展性的关键设计元素。例如,生产者永远不需要等待消费者。Kafka 提供了各种保证,例如一次性处理事件的能力。
主题
-
事件被组织并持久地存储在主题中。非常简化,主题类似于文件系统中的文件夹,事件是该文件夹中的文件。示例主题名称可以是“付款”。
-
Kafka 中的主题始终是多生产者和多订阅者:一个主题可以有零个、一个或多个向其写入事件的生产者,以及零个、一个或多个订阅这些事件的消费者。
-
主题中的事件可以根据需要随时读取——与传统的消息传递系统不同,事件在消费后不会被删除。相反,您可以通过每个主题的配置设置来定义 Kafka 应该将您的事件保留多长时间,之后旧事件将被丢弃。Kafka 的性能在数据大小方面实际上是恒定的,因此长时间存储数据是非常好的
分区
主题是分区的,这意味着一个主题分布在位于不同 Kafka 代理上的多个“桶”中。数据的这种分布式放置对于可伸缩性非常重要,因为它允许客户端应用程序同时从多个代理读取和写入数据。当一个新事件发布到一个主题时,它实际上是附加到主题的分区之一。具有相同事件键(例如,客户或车辆 ID)的事件被写入同一个分区,并且 Kafka保证给定主题分区的任何消费者将始终以与写入事件完全相同的顺序读取该分区的事件。
此示例主题有四个分区 P1–P4。两个不同的生产者客户端通过网络将事件写入主题的分区,彼此独立地向主题发布新事件。具有相同键的事件(在图中由它们的颜色表示)被写入同一个分区。请注意,如果合适的话,两个生产者都可以写入同一个分区。
为了使您的数据具有容错性和高可用性,可以复制每个主题,甚至跨地理区域或数据中心,以便始终有多个代理拥有数据副本,以防万一出现问题,您想要对经纪人进行维护,等等。一个常见的生产设置是复制因子为 3,即始终存在三个数据副本。此复制在主题分区级别执行。
Kafka API
Kafka包括五个核心api:
-
Producer API 允许应用程序将数据流发送到 Kafka 集群中的主题。
-
Consumer API 允许应用程序从 Kafka 集群中的主题中读取数据流。
-
Streams API 允许将数据流从输入主题转换为输出主题。
-
Connect API 允许实现连接器,这些连接器不断地从某个源系统或应用程序拉入 Kafka,或从 Kafka 推送到某个接收器系统或应用程序。
-
Admin API 允许管理和检查主题、代理和其他 Kafka 对象
Producer API,Consumer API和Admin API 依赖的jar
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.1.0</version>
</dependency>
Streams API 依赖的jar
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>3.1.0</version>
</dependency>
使用 Scala 时,您可以选择包含该kafka-streams-scala库。开发人员指南中提供了有关使用 Kafka Streams DSL for Scala 的其他文档。
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams-scala_2.13</artifactId>
<version>3.1.0</version>
</dependency>
总结
可以看到当前案例中2.x版本使用Kafka是非常简单的,只需要下载好安装包,然后启动Zookeeper、启动Kakfa-Server即可,不过这个案例仅仅是参考自官网的入门级案例,如果想要借助Kafka在生产系统上使用仅仅这些事不够的,另外还需要保证Kafka消息的可靠性,集群的高可用等,如果对kafka更多原理及源码分析感兴趣可以关注《中间件源码》微信公众号订阅吧。

