
概述
首先我们来简单的看一下 Go GC中做了什么事,以及它里面比较耗时的地方是什么,我们才能对它进行优化。
首先对于 GC 来说有这么几个阶段:
- sweep termination(清理终止):会触发 STW ,所有的 P(处理器) 都会进入 safe-point(安全点);
- the mark phase(标记阶段):恢复程序执行,GC 执行根节点的标记,这包括扫描所有的栈、全局对象以及不在堆中的运行时数据结构;
- mark termination(标记终止):触发 STW,扭转 GC 状态,关闭 GC 工作线程等;
- the sweep phase(清理阶段):恢复程序执行,后台并发清理所有的内存管理单元;
在这几个阶段中,由于标记阶段是要从根节点对堆进行遍历,对存活的对象进行着色标记,因此标记的时间和目前存活的对象有关,而不是与堆的大小有关,也就是堆上的垃圾对象并不会增加 GC 的标记时间。
并且对于现代操作系统来说释放内存是一个非常快的操作,所以 Go 的 GC 时间很大程度上是由标记阶段决定的,而不是清理阶段。
在什么时候会触发 GC ?
我在这篇文章 https://www.luozhiyun.com/archives/475 做源码分析的时候有详细的讲到过,我这里就简单的说下。
在 Go 中主要会在三个地方触发 GC:
1、监控线程 runtime.sysmon 定时调用;
2、手动调用 runtime.GC 函数进行垃圾收集;
3、申请内存时 runtime.mallocgc 会根据堆大小判断是否调用;
runtime.sysmon
Go 程序在启动的时候会后台运行一个线程定时执行 runtime.sysmon 函数,这个函数主要用来检查死锁、运行计时器、调度抢占、以及 GC 等。
它会执行 runtime.gcTrigger中的 test 函数来判断是否应该进行 GC。由于 GC 可能需要执行时间比较长,所以运行时会在应用程序启动时在后台开启一个用于强制触发垃圾收集的 Goroutine 执行 forcegchelper 函数。
不过 forcegchelper 函数在一般情况下会一直被 goparkunlock 函数一直挂起,直到 sysmon 触发GC 校验通过,才会将该被挂起的 Goroutine 放转身到全局调度队列中等待被调度执行 GC。
runtime.GC
这个比较简单,会获取当前的 GC 循环次数,然后设值为 gcTriggerCycle 模式调用 gcStart 进行循环。
runtime.mallocgc
我在内存分配 https://www.luozhiyun.com/archives/434 这一节讲过,对象在进行内存分配的时候会按大小分成微对象、小对象和大对象三类分别执行 tiny malloc、small alloc、large alloc。
Go 的内存分配采用了池化的技术,类似 CPU 这样的设计,分为了三级缓存,分别是:每个线程单独的缓存池mcache、中心缓存 mcentral 、堆页 mheap 。
tiny malloc、small alloc 都会先去 mcache 中找空闲内存块进行内存分配,如果 mcache 中分配不到内存,就要到 mcentral 或 mheap 中去申请内存,这个时候就会尝试触发 GC;而对于 large alloc 一定会尝试触发 GC 因为它直接在堆页上分配内存。
如何控制 GC 是否应该被执行?
上面这三个触发 GC 的地方最终都会调用 gcStart 执行 GC,但是在执行 GC 之前一定会先判断这次调用是否应该被执行,并不是每次调用都一定会执行 GC, 这个时候就要说一下 runtime.gcTrigger中的 test 函数,这个函数负责校验本次 GC 是否应该被执行。
runtime.gcTrigger中的 test 函数最终会根据自己的三个策略,判断是否应该执行GC:
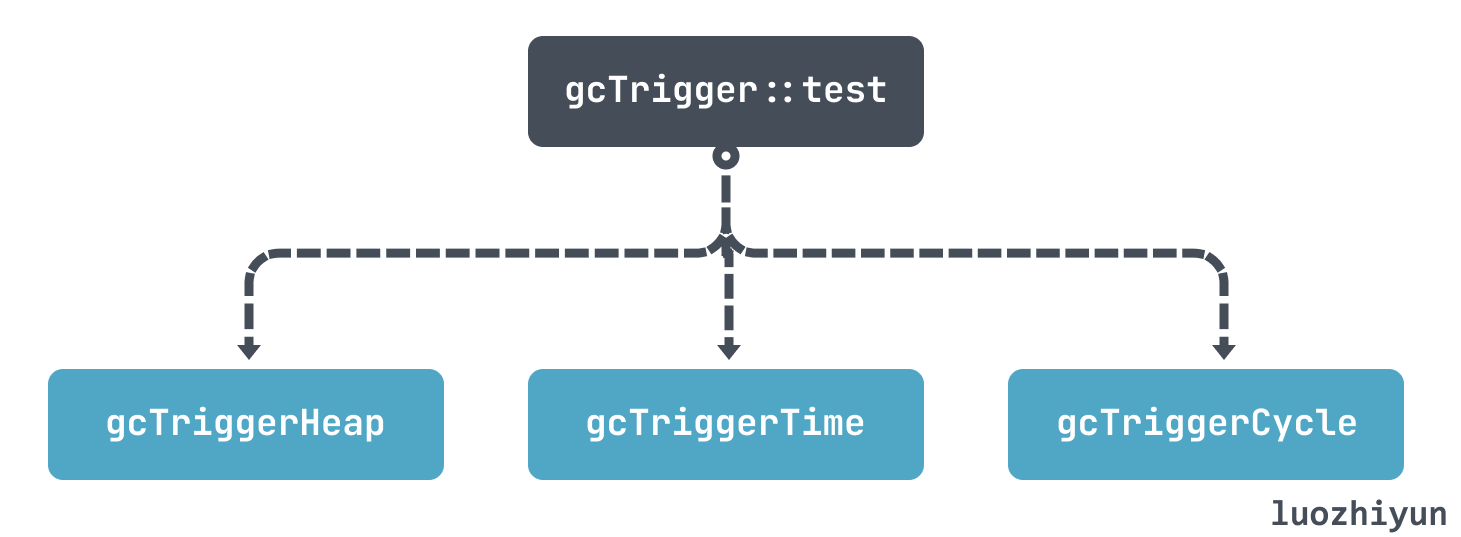
- gcTriggerHeap:按堆大小触发,堆大小和上次 GC 时相比达到一定阈值则触发;
- gcTriggerTime:按时间触发,如果超过 forcegcperiod(默认2分钟) 时间没有被 GC,那么会执行GC;
- gcTriggerCycle:没有开启垃圾收集,则触发新的循环;
如果是 gcTriggerHeap 策略,那么会根据 runtime.gcSetTriggerRatio 函数中计算的值来判断是否要进行 GC,主要是由环境变量 GOGC(默认值为100 ) 决定阈值是多少。
我们可以大致认为,触发 GC 的时机是由上次 GC 时的堆内存大小,和当前堆内存大小值对比的增长率来决定的,这个增长率就是环境变量 GOGC,默认是 100 ,计算公式可以大体理解为:
hard_target = live_dataset + live_dataset * (GOGC / 100).
假设目前是 100M 内存占用,那么根据上面公式,会到 200M 的时候才会触发 GC。
触发 GC 的时机其实并不只是 GOGC 单一变量决定的,在代码 runtime.gcSetTriggerRatio 里面我们可以看到它控制的是一个范围:
func gcSetTriggerRatio(triggerRatio float64) {
// gcpercent 由环境变量 GOGC 决定
if gcpercent >= 0 {
// 默认是 1
scalingFactor := float64(gcpercent) / 100
// 最大的 maxTriggerRatio 是 0.95
maxTriggerRatio := 0.95 * scalingFactor
if triggerRatio > maxTriggerRatio {
triggerRatio = maxTriggerRatio
}
// 最大的 minTriggerRatio 是 0.6
minTriggerRatio := 0.6 * scalingFactor
if triggerRatio < minTriggerRatio {
triggerRatio = minTriggerRatio
}
} else if triggerRatio < 0 {
triggerRatio = 0
}
memstats.triggerRatio = triggerRatio
trigger := ^uint64(0)
if gcpercent >= 0 {
// 当前标记存活的大小乘以1+系数triggerRatio
trigger = uint64(float64(memstats.heap_marked) * (1 + triggerRatio))
...
}
memstats.gc_trigger = trigger
...
}
具体阈值计算是比较复杂的,从 gcControllerState.endCycle 函数中可以看到执行 GC 的时机还要看以下几个因素:
- 当前 CPU 占用率,GC 标记阶段最高不能超过整个应用的 25%;
- 辅助 GC 标记对象 CPU 占用率;
- 目标增长率(预估),该值等于:(下次 GC 完后堆大小 - 堆存活大小)/ 堆存活大小;
- 堆实际增长率:堆总大小/上次标记完后存活大小-1;
- 上次GC时触发的堆增长率大小;
这些综合因素计算之后得到的一个值就是本次的触发 GC 堆增长率大小。这些都可以通过 GODEBUG=gctrace=1,gcpacertrace=1 打印出来。
下面我们看看一个具体的例子:
package main
import (
"fmt"
)
func allocate() {
_ = make([]byte, 1<<20)
}
func main() {
fmt.Println("start.")
fmt.Println("> loop.")
for {
allocate()
}
fmt.Println("< loop.")
}
使用 gctrace 跟踪 GC 情况:
[root@localhost gotest]# go build main.go
[root@localhost gotest]# GODEBUG=gctrace=1 ./main
start.
> loop.
...
gc 1409 @0.706s 14%: 0.009+0.22+0.076 ms clock, 0.15+0.060/0.053/0.033+1.2 ms cpu, 4->6->2 MB, 5 MB goal, 16 P
gc 1410 @0.706s 14%: 0.007+0.26+0.092 ms clock, 0.12+0.050/0.070/0.030+1.4 ms cpu, 4->7->3 MB, 5 MB goal, 16 P
gc 1411 @0.707s 14%: 0.007+0.36+0.059 ms clock, 0.12+0.047/0.092/0.017+0.94 ms cpu, 5->7->2 MB, 6 MB goal, 16 P
...
< loop.
上面展示了 3 次 GC 的情况,下面我们看看:
gc 1410 @0.706s 14%: 0.007+0.26+0.092 ms clock, 0.12+0.050/0.070/0.030+1.4 ms cpu, 4->7->3 MB, 5 MB goal, 16 P
内存
4 MB:标记开始前堆占用大小 (in-use before the Marking started)
7 MB:标记结束后堆占用大小 (in-use after the Marking finished)
3 MB:标记完成后存活堆的大小 (marked as live after the Marking finished)
5 MB goal:标记完成后正在使用的堆内存的目标大小 (Collection goal)
可以看到这里标记结束后堆占用大小是7 MB,但是给出的目标预估值是 5 MB,你可以看到回收器超过了它设定的目标2 MB,所以它这个目标值也是不准确的。
在 1410 次 GC 中,最后标记完之后堆大小是 3 MB,所以我们可以大致根据 GOGC 推测下次 GC 时堆大小应该不超过 6MB,所以我们可以看看 1411 次GC:
gc 1411 @0.707s 14%: 0.007+0.36+0.059 ms clock, 0.12+0.047/0.092/0.017+0.94 ms cpu, 5->7->2 MB, 6 MB goal, 16 P
内存
5 MB:标记开始前堆占用大小 (in-use before the Marking started)
7 MB:标记结束后堆占用大小 (in-use after the Marking finished)
2 MB:标记完成后存活堆的大小 (marked as live after the Marking finished)
6 MB goal:标记完成后正在使用的堆内存的目标大小 (Collection goal)
可以看到在 1411 次GC启动时堆大小是 5 MB 是在控制范围之内。
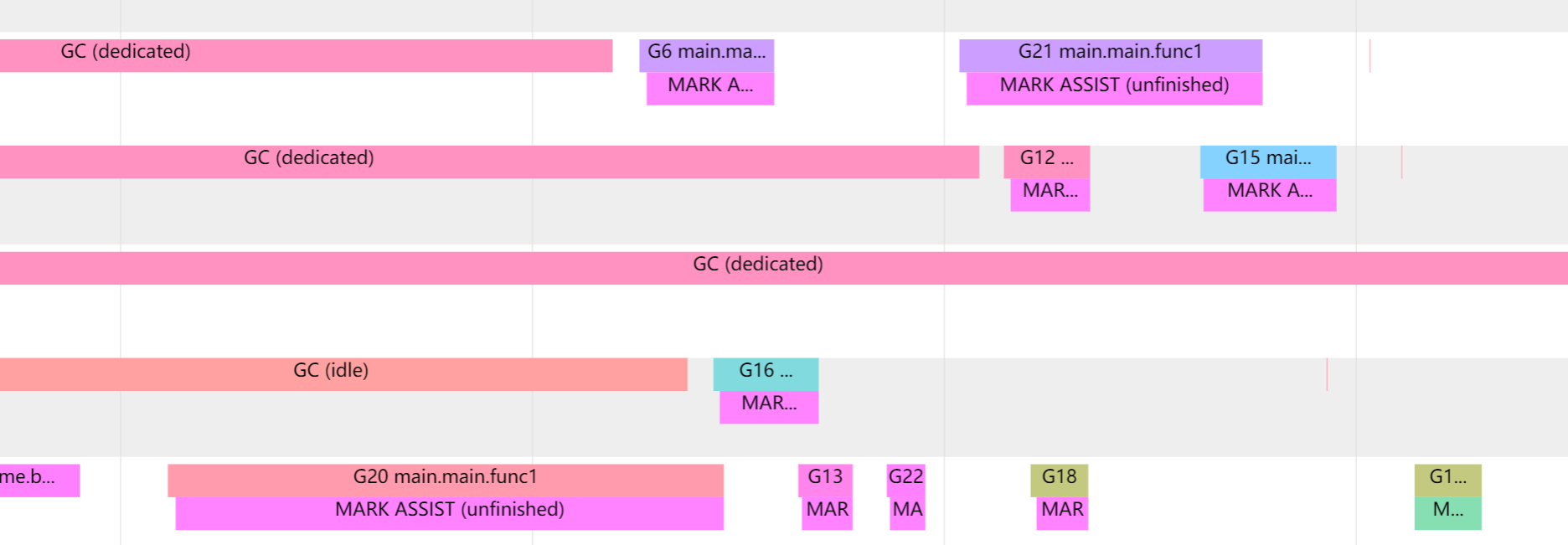
说了这么多 GC 的机制,那么有没有可能 GC 的速度赶不上制造垃圾的速度呢?这就引出了 GC 中的另一种机制:Mark assist。
如果收集器确定它需要减慢分配速度,它将招募应用程序 Goroutines 来协助标记工作。这称为 Mark assist 标记辅助。这也就是为什么在分配内存的时候还需要判断要不要执行 mallocgc 进行 GC。
在进行 Mark assist 的时候 Goroutines 会暂停当前的工作,进行辅助标记工作,这会导致当前 Goroutines 工作的任务有一些延迟。
而我们的 GC 也会尽可能的消除 Mark assist ,所以会让下次的 GC 时间更早一些,也就会让 GC 更加频繁的触发。
我们可以通过 go tool trace 来观察到 Mark assist 的情况:
Go Memory Ballast
上面我们熟悉了 Go GC 的策略之后,我们来看看 Go Memory Ballast 是怎么优化 GC 的。下面先看一个例子:
func allocate() {
_ = make([]byte, 1<<20)
}
func main() {
ballast := make([]byte, 200*1024*1024) // 200M
for i := 0; i < 10; i++ {
go func() {
fmt.Println("start.")
fmt.Println("> loop.")
for {
allocate()
}
fmt.Println("< loop.")
}()
}
runtime.KeepAlive(ballast)
我们运行上面的代码片段,然后我们对资源利用的情况进行简单的统计:
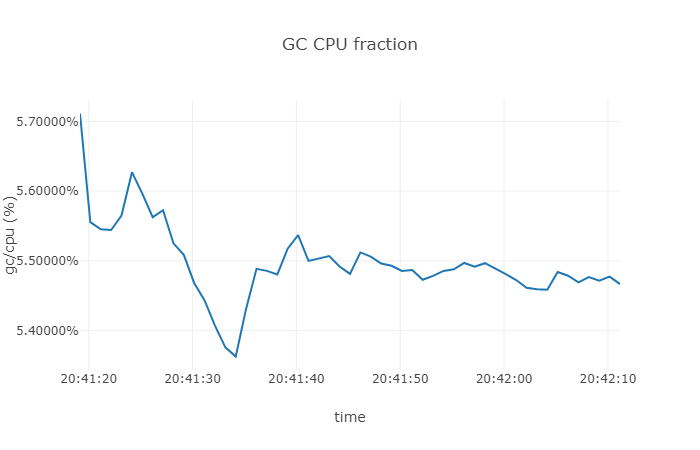
从上面的结果我们可以直到,GC 的 CPU 利用率大约在 5.5 % 左右。
下面我们把 ballast 内存占用去掉,看看会是多少:
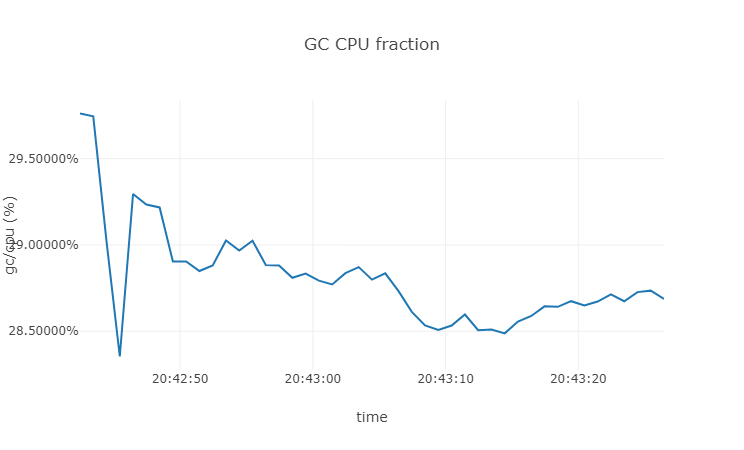
可以看到在没有 ballast 的时候 GC 的 CPU占用在 28% 左右。对 GC 的其他信息感兴趣的朋友可以使用 runtime.Memstats 定期抓取 GC 的信息进行打印。
那么为什么在申请了一个空的数组之后 CPU 占用会低这么多?首先我们在概述也讲到了,GC 会根据环境变量 GOGC 来决定下次 GC 的执行时机,所以如果我们申请了200M的数组,那么下次 GC 的时候大约会在 400M。由于我们上面的例子中,allocate 函数申请的对象都是临时对象,在 GC 之后会被再次减少到 200M 左右,所以下次执行 GC 的时机会被再次设置到 400M 。
但是如果没有 ballast 数组,感兴趣的可以自行去测试一下,大约会在 4M 左右的时候会触发 GC,这无疑对于临时变量比较多的系统来说会造成相当频繁的 GC。
总之,通过设置 ballast 数组我们达到了延迟 GC 的效果,但是这种效果只会在临时变量比较多的系统中有用,对于全局变量多的系统,用处不大。
那么还有一个问题,在系统中无故申请 200M 这么大的内存会不会对内存造成浪费?毕竟内存这么贵。其实不用担心,只要我们没有对 ballast 数组进行读写,是不会真正用到物理内存占用的,我们可以用下面的例子看一下:
func main() {
_ = make([]byte, 100<<20)
<-time.After(time.Duration(math.MaxInt64))
}
$ ps -eo pmem,comm,pid,maj_flt,min_flt,rss,vsz --sort -rss | numfmt --header --to=iec --field 4-5 | numfmt --header --from-unit=1024 --to=iec --field 6-7 | column -t | egrep "[t]est|[P]ID"
%MEM COMMAND PID MAJFL MINFL RSS VSZ
0.0 test_alloc 31248 0 1.1K 7.4M 821M
可以看到虚拟内存VSZ占用很大,但是RSS 进程分配的内存大小很小。
func main() {
ballast := make([]byte, 100<<20)
for i := 0; i < len(ballast)/2; i++ {
ballast[i] = byte('A')
}
<-time.After(time.Duration(math.MaxInt64))
}
$ ps -eo pmem,comm,pid,maj_flt,min_flt,rss,vsz --sort -rss | numfmt --header --to=iec --field 4-5 | numfmt --header --from-unit=1024 --to=iec --field 6-7 | column -t | egrep "[t]est|[P]ID"
%MEM COMMAND PID MAJFL MINFL RSS VSZ
0.4 test_alloc 31692 0 774 60M 821M
但是如果我们要对它进行写入操作,RSS 进程分配的内存大小就会变大,剩下的可以自己去验证。
对于 Go Ballast 的讨论其实很早就有人提过 issue ,其实官方只需要加一个最小堆大小的参数即可,但是一直没有得到实现。相比之下 Java 就好很多GC 的调优参数,InitialHeapSize 就可以设置堆的初始值。
这也导致了很多对性能要求比较高的项目如: tidb,cortex 都在代码里加了一个这样的空数组实现。
Go GC Tuner
这个方法其实是来自 uber 的这篇文章里面介绍的。根本问题还是因为 Go 的 GC 太频繁了,导致标记占用了很高的 CPU,但是 Go 也提供了 GOGC 来调整 GC 的时机,那么有没有一种办法可以动态的根据当前的内存调整 GOGC 的值,由此来控制 GC 的频率呢?
在 Go 中其实提供了 runtime.SetFinalizer 函数,它会在对象被 GC 的时候最后回调一下。在 Go 中 它是这么定义的:
type any = interface{}
func SetFinalizer(obj any, finalizer any)
obj 一般来说是一个对象的指针;finalizer 是一个函数,它接受单个可以直接用 obj 类型值赋值的参数。也就是说 SetFinalizer 的作用就是将 obj 对象的析构函数设置为 finalizer,当垃圾收集器发现 obj 不能再直接或间接访问时,它会清理 obj 并调用 finalizer。
所以我们可以通过它来设置一个钩子,每次 GC 完之后检查一下内存情况,然后设置 GOGC 值:
type finalizer struct {
ref *finalizerRef
}
type finalizerRef struct {
parent *finalizer
}
func finalizerHandler(f *finalizerRef) {
// 为 GOGC 动态设值
getCurrentPercentAndChangeGOGC()
// 重新设置回去,否则会被真的清理
runtime.SetFinalizer(f, finalizerHandler)
}
func NewTuner(options ...OptFunc) *finalizer {
// 处理传入的参数
...
f := &finalizer{}
f.ref = &finalizerRef{parent: f}
runtime.SetFinalizer(f.ref, finalizerHandler)
// 设置为 nil,让 GC 认为原 f.ref 函数是垃圾,以便触发 finalizerHandler 调用
f.ref = nil
return f
}
上面的这段代码就利用了 finalizer 特性,在 GC 的时候会调用 getCurrentPercentAndChangeGOGC 重新设置 GOGC 值,由于 finalizer 会延长一次对象的生命周期,所以我们可以在 finalizerHandler 中设置完 GOGC 之后再次调用 SetFinalizer 将对象重新绑定在 Finalizer 上。
这样构成一个循环,每次 GC 都会有一个 finalizerRef 对象在动态的根据当前内存情况改变 GOGC 值,从而达到调整 GC 次数,节约资源的目的。
上面我们也提到过,GC 基本上根据本次 GC 之后的堆大小来计算下次 GC 的时机:
hard_target = live_dataset + live_dataset * (GOGC / 100).
比如本次 GC 完之后堆大小 live_dataset 是 100 M,对于 GOGC 默认值 100 来说会在堆大小 200M 的时候触发 GC。
为了达到最大化利用内存,减少 GC 次数的目的,那么我们可以将 GOGC 设置为:
(可使用内存最大百分比 - 当前占内存百分比)/当前占内存百分比 * 100
也就是说如果有一台机器,全部内存都给我们应用使用,应用当前占用 10%,也就是 100M,那么:
GOGC = (100%-10%)/10% * 100 = 900
然后根据上面 hard_target 计算公式可以得知,应用将在堆占用达到 1G 的时候开始 GC。当然我们生产当中不可能那么极限,具体的最大可使用内存最大百分比还需要根据当前情况进行调整。
那么换算成代码,我们的 getCurrentPercentAndChangeGOGC 就可以这么写:
var memoryLimitInPercent float64 = 100
func getCurrentPercentAndChangeGOGC() {
p, _ := process.NewProcess(int32(os.Getpid()))
// 获取当前应用占用百分比
memPercent, _ := p.MemoryPercent()
// 计算 GOGC 值
newgogc := (memoryLimitInPercent - float64(memPercent)) / memPercent * 100.0
// 设置 GOGC 值
debug.SetGCPercent(int(newgogc))
}
上面这段代码我省去了很多异常处理,默认处理,以及 memoryLimitInPercent 写成了一个固定值,在真正使用的时候,代码还需要再完善一下。
写到这里,上面 Go Memory Ballast 和 Go GC Tuner 已经达到了我们的优化目的,但是在我即将提稿的时候,曹春晖大佬发了一篇文章中,说到最新的 Go 版本中 1.19 beta1版本中新加了一个 debug.SetMemoryLimit 函数。
Soft Memory Limit
这一个优化来自 issue#48409,在 Go 1.19 版本中被加入,优化原理实际上和上面差不多,通过内置的 debug.SetMemoryLimit 函数我们可以调整触发 GC 的堆内存目标值,从而减少 GC 次数,降低GC 时 CPU 占用的目的。
在上面我们也讲了,Go 实现了三种策略触发 GC ,其中一种是 gcTriggerHeap,它会根据堆的大小设定下次执行 GC 的堆目标值。 1.19 版的代码正是对 gcTriggerHeap 策略做了修改。
通过代码调用我们可以知道在 gcControllerState。heapGoalInternal 计算 HeapGoal 的时候使用了两种方式,一种是通过 GOGC 值计算,另一种是通过 memoryLimit 值计算,然后取它们两个中小的值作为 HeapGoal。
func (c *gcControllerState) heapGoalInternal() (goal, minTrigger uint64) {
// Start with the goal calculated for gcPercent.
goal = c.gcPercentHeapGoal.Load() //通过 GOGC 计算 heapGoal
// 通过 memoryLimit 计算 heapGoal,并和 goal 比较大小,取小的
if newGoal := c.memoryLimitHeapGoal(); go119MemoryLimitSupport && newGoal < goal {
goal = newGoal
} else {
...
}
return
}
gcPercentHeapGoal 的计算方式如下:
func (c *gcControllerState) commit(isSweepDone bool) {
...
gcPercentHeapGoal := ^uint64(0)
if gcPercent := c.gcPercent.Load(); gcPercent >= 0 {
// HeapGoal = 存活堆大小 + (存活堆大小+栈大小+全局变量大小)* GOGC/100
gcPercentHeapGoal = c.heapMarked + (c.heapMarked+atomic.Load64(&c.lastStackScan)+atomic.Load64(&c.globalsScan))*uint64(gcPercent)/100
}
c.gcPercentHeapGoal.Store(gcPercentHeapGoal)
...
}
和我们上面提到的 hard_target 计算差别不大,可以理解为:
HeapGoal = live_dataset + (live_dataset+栈大小+全局变量大小)* GOGC/100
我们再看看memoryLimitHeapGoal计算:
func (c *gcControllerState) memoryLimitHeapGoal() uint64 {
var heapFree, heapAlloc, mappedReady uint64
heapFree = c.heapFree.load()
heapAlloc = c.totalAlloc.Load() - c.totalFree.Load()
mappedReady = c.mappedReady.Load()
memoryLimit := uint64(c.memoryLimit.Load())
nonHeapMemory := mappedReady - heapFree - heapAlloc
...
goal := memoryLimit - nonHeapMemory
...
return goal
}
上面这段代码基本上可以理解为:
goal = memoryLimit - 非堆内存
所以正因为 Go GC 的触发是取上面两者计算结果较小的值,那么原本我们使用 GOGC 填的太大怕导致 OOM,现在我们可以加上 memoryLimit 参数限制一下;或者直接 GOGC = off ,然后设置 memoryLimit 参数,通过它来调配我们的 GC。
总结
我们这篇主要通过讲解 Go GC 的触发机制,然后引出利用这个机制可以比较 hack 的方式减少 GC 次数,从而达到减少 GC 消耗。
Go Memory Ballast 主要是通过预设一个大数组,让 Go 在启动的时候提升 Go 下次触发 GC 的堆内存阈值,从而避免在内存够用,但是应用内临时变量较多时不断 GC 所产生的不必要的消耗。
Go GC Tuner 主要时通过 Go 提供的 GC 钩子,设置 Finalizer 在 GC 完之后通过当前的内存使用情况动态设置 GOGC,从而达到减少 GC 的目的。
Soft Memory Limit 是1.19版本的新特性,通过内置的方式实现了 GC 的控制,通过设置 memoryLimit 控制 GC 内存触发阈值达到减少 GC 的目的,原理其实和上面两种方式没有本质区别,但是由于内置在 GC 环节,可以更精细化的检查当前的非堆内存占用情况,从而实现更精准控制。
Reference
https://blog.twitch.tv/en/2019/04/10/go-memory-ballast-how-i-learnt-to-stop-worrying-and-love-the-heap/
https://github.com/golang/go/issues/23044
https://www.cnblogs.com/457220157-FTD/p/15567442.html
https://github.com/golang/go/issues/42430
https://eng.uber.com/how-we-saved-70k-cores-across-30-mission-critical-services/
https://xargin.com/dynamic-gogc/
https://github.com/cch123/gogctuner
https://golang.design/under-the-hood/zh-cn/part2runtime/ch08gc/pacing/
https://medium.com/a-journey-with-go/go-finalizers-786df8e17687
https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-garbage-collector
https://xargin.com/the-new-api-for-heap-limit/
https://pkg.go.dev/runtime/debug@master#SetMemoryLimit
https://tip.golang.org/doc/go1.19
https://github.com/golang/go/issues/48409


