
关于缓存异常:缓存雪崩、击穿、穿透的解决方案原创
前言
关于缓存异常,我们常见的有三个问题:缓存雪崩、缓存击穿、缓存穿透。这三个问题一旦发生,会导致大量请求直接落到数据库层面。如果请求的并发量很大,会影响数据库的运行,严重的会导致数据库宕机。
为了避免缓存异常带来的损失,我们需要了解每种异常的原因以及解决方案,提高系统的可靠性。
缓存雪崩
缓存雪崩是指大量的应用请求无法在Redis缓存中进行处理,从而使得大量请求发送到数据库层,导致数据库压力过大甚至宕机。
缓存雪崩的原因
第一个原因:同一时间缓存中的数据大面积过期。
具体来说,把热点数据保存在缓存中,并且设置了过期时间,如果在某一个时刻,大量的Key同时过期,此时,应用再访问这些数据的话,就会发生缓存缺失。然后应用就会把请求发送给数据库,如果应用的并发请求量很大,(比如秒杀),那么数据库的压力也会很大,这会进一步影响到其他正常业务的请求处理。
如下图所示:
第二个原因:Redis 缓存实例发生故障宕机。
解决方案
1、解决热点数据集中失效
针对大量数据集中失效带来的缓存雪崩问题,可以用下面几种方案解决:
-
均匀过期:给热点数据设置不同的过期时间,给每个key的失效时间加一个随机值;
-
设置热点数据永不过期:不设置失效时间,有更新的话,需要更新缓存;
-
服务降级:指服务针对不同的数据采用不同的处理方式:
a.业务访问的是非核心数据,直接返回预定义信息、空值或者报错; b.业务访问核心数据,则允许访问缓存,如果缓存缺失,可以读取数据库。
2、解决Redis实例宕机问题
方案一:实现服务熔断或者请求限流机制
我们通过监测Redis以及数据库实例所在服务器负载指标,如果发现Redis服务宕机,导致数据库的负载压力增大,我们可以启动服务熔断机制,暂停对缓存服务的访问。
但是这种方法对业务应用的影响比较大,我们也可以通过限流的方式降低这种影响。
举个例子:比如业务系统正常运行时,请求入口每秒最大允许进入的请求数是1万个,其中9000请求个可以被缓存处理,余下1000个会发送给数据库处理。
一旦发生雪崩,数据库每秒处理的请求突然增加到1万个,此时我们就可以启动限流机制。在前端请求入口处,只允许每秒进入1000个请求,其他的直接拒绝掉。这样就可以避免大量并发请求发送给数据库。
方案二:事前预防
通过主从节点的方式构建 Redis 缓存高可靠集群。如果 Redis 缓存的主节点故障宕机了,从节点还可以切换成为主节点,继续提供缓存服务,避免了由于缓存实例宕机而导致的缓存雪崩问题。
缓存击穿
缓存击穿和缓存雪崩有点像,但是也有一点区别。
缓存雪崩是因为大面积的缓存失效,打崩了数据库。而缓存击穿是指某个访问非常频繁的热点数据,大量并发请求集中在这一个点访问,在这个Key失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿了一个洞。
解决方案
-
设置热点数据永不过期:不设置失效时间,有更新的话,需要更新缓存;
-
加互斥锁:单机可以使用synchronized、lock,分布式可以使用lua脚本。
缓存穿透
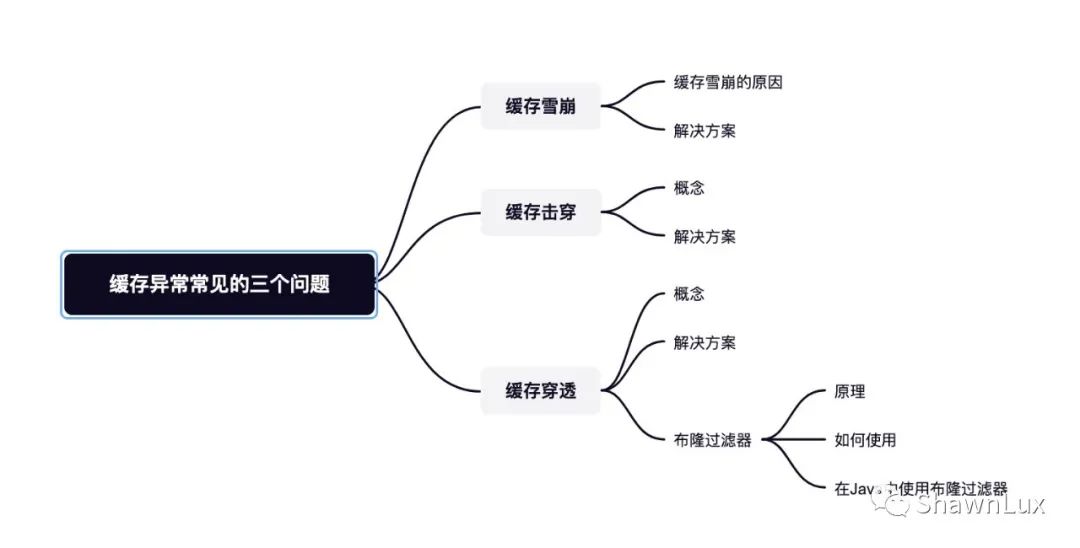
缓存穿透指用户要访问的数据既不在缓存中也不在数据库中,导致用户每次请求该数据时都要去数据库查一遍,然后返回空。
如果有恶意攻击者不断请求这种系统不存在的数据,会导致数据库压力过大,严重会击垮数据库。
解决方案
-
接口层增加校验:用户鉴权、参数校验(请求参数是否合法、请求字段是否不存在等等);
-
缓存空值/缺省值:发生缓存穿透时,我们可以在Redis中缓存一个空值或者缺省值(例如,库存缺省值为0),这样就避免了把大量请求发送给数据库处理,保持了数据库的正常运行。这种方法会存在两个问题:
a. 如果有大量的Key穿透,缓存空对象会占用宝贵的内存空间。针对这种情况可以给空对象设置过期时间。b. 设置过期时间之后,可能会有缓存与数据库不一致的情况。
-
布隆过滤器:快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力。
前面两种方案比较好理解,下面我们重点介绍下布隆过滤器。
布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
-
优点:空间效率和查询时间都远远超过一般的算法。
-
缺点:有一定的误识别率,删除困难。
布隆过滤器原理
布隆过滤器本质上是一个初始值都为 0 的二进制数组和 N 个哈希函数组成。
当我们想标记某个数据存在时(例如,数据x已被写入数据库),布隆过滤器会通过三个操作完成标记:
-
首先,使用 N 个哈希函数,分别计算这个数据的哈希值,得到 N 个哈希值。
-
然后,我们把这 N 个哈希值对 bit 数组的长度取模,得到每个哈希值在数组中的对应位置。
-
最后,我们把对应位置的 bit 位设置为 1,这就完成了在布隆过滤器中标记数据的操作。
如下图所示:
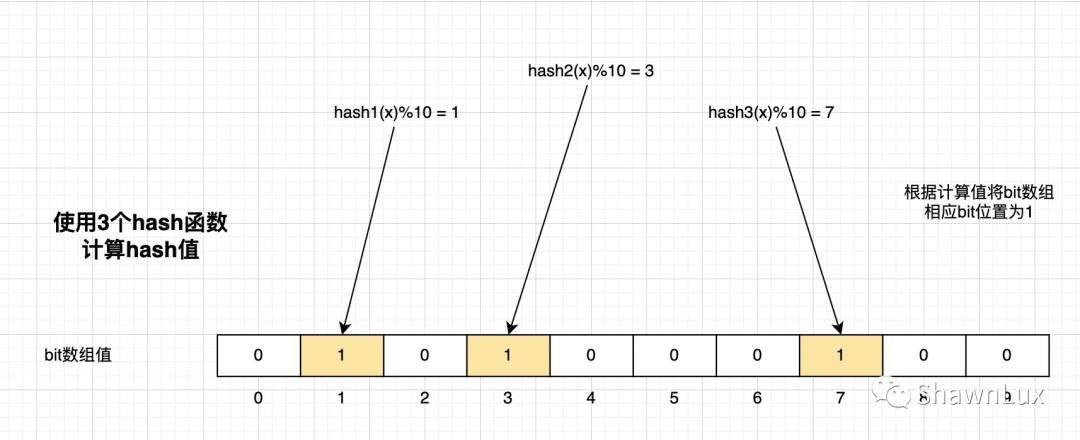
三次哈希,对应的二进制数组下标分别是 1、3、7,将原始数据从 0 变为 1。
同样的,我们标记数据y的逻辑也是一样的。如下图:
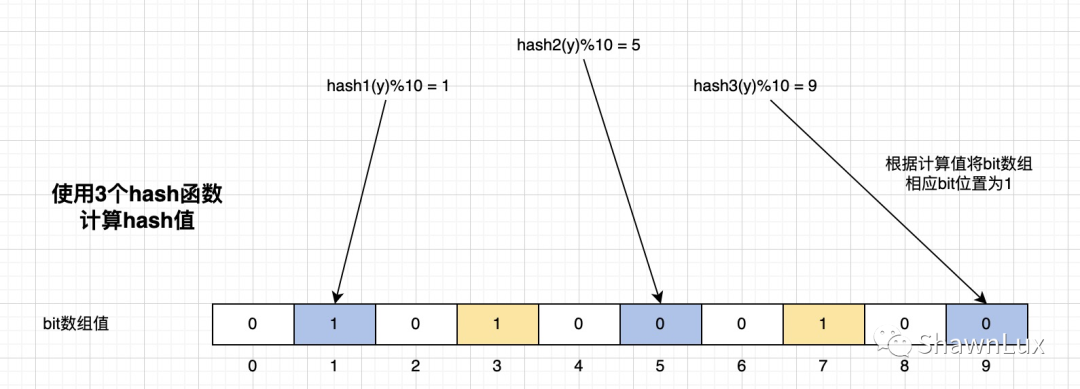
三次哈希,对应的二进制数组下标分别是 1、5、9,将原始数据从 0 变为 1。
下标 1,之前已经被操作设置成 1,则本次认为是哈希冲突,不需要改动。
Hash 规则:如果在 Hash 后,原始位它是 0 的话,将其从 0 变为 1;如果本身这一位就是 1 的话,则保持不变。
正是因为存在哈希冲突,导致布隆过滤器的判断存在误差。
因为哈希冲突的存在,导致布隆过滤器不能轻易删除数据,存在误删的风险。
布隆过滤器减少误差的方法:
-
增加二进制位数组的长度,这样hash后的数据会更加离散化,出现冲突的概率会大大降低;
-
增加Hash的次数,变相的增加数据特征,特征越多,冲突的概率越小。
布隆过滤器如何使用
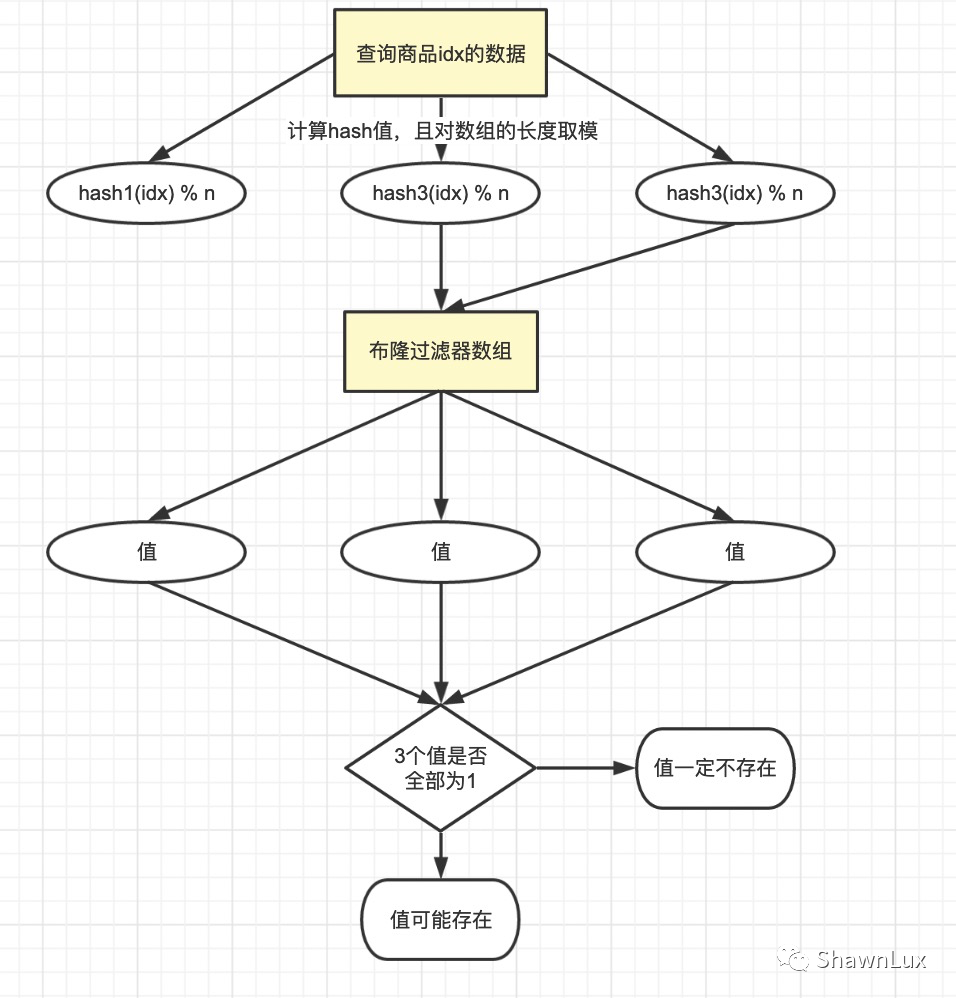
比如,当查询一件商品的缓存信息时,我们首先要判断这件商品是否存在。
-
通过三个哈希函数对商品id计算哈希值;
-
然后,在布隆数组中查找访问对应的位值,0或1;
-
判断,三个值中,只要有一个不是1,那么我们认为数据是不存在的。
如下图:
注意:布隆过滤器只能精确判断数据不存在情况,对于存在我们只能说是可能,因为存在Hash冲突情况,当然这个概率非常低。
在Java中使用布隆过滤器
在Java应用中使用布隆过滤器,我们可以通过Redisson实现,它内置了布隆过滤器。
首先引入依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.15.0</version>
</dependency>代码示例:
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient client = Redisson.create(config);
RBloomFilter<String> bloomFilter = client.getBloomFilter("test-bloom-filter");
// 初始化布隆过滤器,数组长度100W,误判率 1%
bloomFilter.tryInit(1000000L, 0.01);
// 添加数据
bloomFilter.add("Shawn");
// 判断是否存在
System.out.println(bloomFilter.contains("xujunson"));
System.out.println(bloomFilter.contains("Shawn"));
}
}
运行结果:
false // 肯定不存在
true // 可能存在,有1%的误判率好了,以上就是关于缓存异常的整理。跟缓存雪崩、缓存击穿这两类问题相比,缓存穿透的影响更大一些,需要重点关注一下。


