
深入 Go 中各个高性能 JSON 解析库原创
其实本来我是没打算去看 JSON 库的性能问题的,但是最近我对我的项目做了一次 pprof,从下面的火焰图中可以发现在业务逻辑处理中,有一半多的性能消耗都是在 JSON 解析过程中,所以就有了这篇文章。
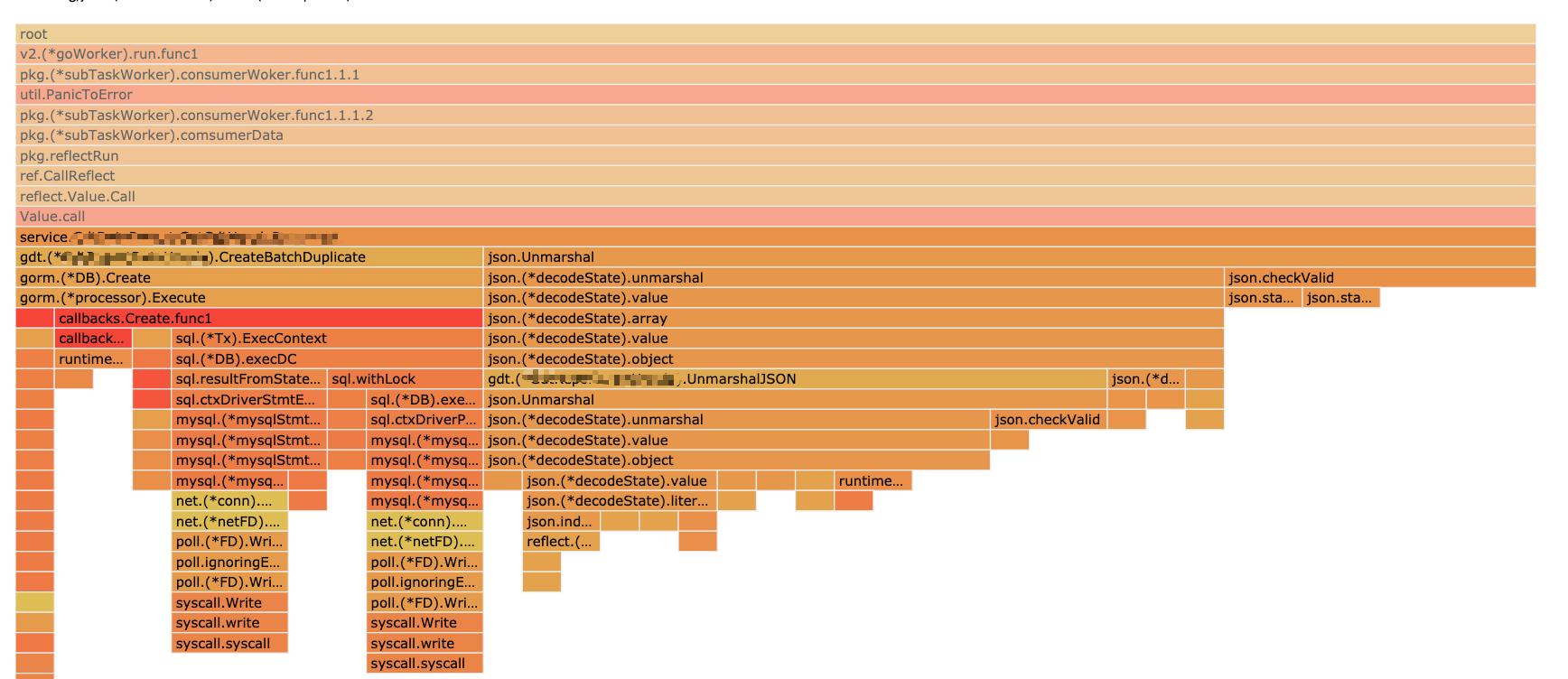
这篇文章深入源码分析一下在 Go 中标准库是如何解析 JSON 的,然后再看看有哪些比较流行的 Json 解析库,以及这些库都有什么特点,在什么场景下能更好的帮助我们进行开发。
主要介绍分析以下几个库:
| 库名 | Star |
|---|---|
| 标准库 JSON Unmarshal | |
| valyala/fastjson | 1.2 k |
| tidwall/gjson | 8.3 k |
| buger/jsonparser | 4 k |
json-iterator 库也是一个非常有名的库,但是我测了一下性能和标准库相差很小,相比之下还是标准库更值得使用;
Jeffail/gabs 库与 bitly/go-simplejson 直接用的标准库的 Unmarshal 来进行解析,所以性能上和标准库一致,本篇文章也不会提及;
easyjson这个库需要像 protobuf 一样为每一个结构体生成序列化的代码,具有强入侵性,我个人不是很喜欢,所以也没提及。
上面的这些库是我能搜到的 Star 数大于 1k 比较知名,并且仍然在迭代的 JSON 解析库,如果有遗漏的,可以联系我,我会补上。
标准库 JSON Unmarshal
分析
func Unmarshal(data []byte, v interface{})
官方的 JSON 解析库需要传两个参数,一个是需要被序列化的对象,另一个是表示这个对象的类型。
在真正执行 JSON 解析之前会调用 reflect.ValueOf来获取参数 v 的反射对象。然后会获取到传入的 data 对象的开头非空字符来界定该用哪种方式来进行解析。
func (d *decodeState) value(v reflect.Value) error {
switch d.opcode {
default:
panic(phasePanicMsg)
// 数组
case scanBeginArray:
...
// 结构体或map
case scanBeginObject:
...
// 字面量,包括 int、string、float 等
case scanBeginLiteral:
...
}
return nil
}
如果被解析的对象是以[开头,那么表示这是个数组对象会进入到 scanBeginArray 分支;如果是以{开头,表明被解析的对象是一个结构体或 map,那么进入到 scanBeginObject 分支 等等。
以解析对象为例:
func (d *decodeState) object(v reflect.Value) error {
...
var fields structFields
// 检验这个对象的类型是 map 还是 结构体
switch v.Kind() {
case reflect.Map:
...
case reflect.Struct:
// 缓存结构体的字段到 fields 对象中
fields = cachedTypeFields(t)
// ok
default:
d.saveError(&UnmarshalTypeError{Value: "object", Type: t, Offset: int64(d.off)})
d.skip()
return nil
}
var mapElem reflect.Value
origErrorContext := d.errorContext
// 循环一个个解析JSON字符串中的 key value 值
for {
start := d.readIndex()
d.rescanLiteral()
item := d.data[start:d.readIndex()]
// 获取 key 值
key, ok := unquoteBytes(item)
if !ok {
panic(phasePanicMsg)
}
var subv reflect.Value
destring := false
...
// 根据 value 的类型反射设置 value 值
if destring {
// value 值是字面量会进入到这里
switch qv := d.valueQuoted().(type) {
case nil:
if err := d.literalStore(nullLiteral, subv, false); err != nil {
return err
}
case string:
if err := d.literalStore([]byte(qv), subv, true); err != nil {
return err
}
default:
d.saveError(fmt.Errorf("json: invalid use of ,string struct tag, trying to unmarshal unquoted value into %v", subv.Type()))
}
} else {
// 数组或对象会递归调用 value 方法
if err := d.value(subv); err != nil {
return err
}
}
...
// 直到遇到 } 最后退出循环
if d.opcode == scanEndObject {
break
}
if d.opcode != scanObjectValue {
panic(phasePanicMsg)
}
}
return nil
}
- 首先会缓存结构体对象;
- 循环遍历结构体对象;
- 找到结构体中的 key 值之后再找到结构体中同名字段类型;
- 递归调用 value 方法反射设置结构体对应的值;
- 直到遍历到 JSON 中结尾
}结束循环。
小结
通过看 Unmarshal 源码中可以看到其中使用了大量的反射来获取字段值,如果是多层嵌套的 JSON 的话,那么还需要递归进行反射获取值,可想而知性能是非常差的了。
但是如果对性能不是那么看重的话,直接使用它其实是一个非常好的选择,功能完善的同时并且官方也一直在迭代优化,说不定在以后的版本中性能也会得到质的飞跃。
fastjson
库地址:https://github.com/valyala/fastjson
这个库的特点和它的名字一样就是快,它的介绍页是这么说的:
Fast. As usual, up to 15x faster than the standard encoding/json.
它的使用也是非常的简单,如下:
func main() {
var p fastjson.Parser
v, _ := p.Parse(`{
"str": "bar",
"int": 123,
"float": 1.23,
"bool": true,
"arr": [1, "foo", {}]
}`)
fmt.Printf("foo=%s\n", v.GetStringBytes("str"))
fmt.Printf("int=%d\n", v.GetInt("int"))
fmt.Printf("float=%f\n", v.GetFloat64("float"))
fmt.Printf("bool=%v\n", v.GetBool("bool"))
fmt.Printf("arr.1=%s\n", v.GetStringBytes("arr", "1"))
}
// Output:
// foo=bar
// int=123
// float=1.230000
// bool=true
// arr.1=foo
使用 fastjson 首先要将被解析的 JSON 串交给 Parser 解析器进行解析,然后通过 Parse 方法返回的对象来获取。如果是嵌套对象可以直接在 Get 方法传参的时候传入相应的父子 key 即可。
分析
fastjson 在设计上和标准库 Unmarshal 不同的是,它将 JSON 解析划分为两部分:Parse、Get。
Parse 负责将 JSON 串解析成为一个结构体并返回,然后通过返回的结构体来获取数据。在 Parse 解析的过程是无锁的,所以如果想要在并发地调用 Parse 进行解析需要使用 ParserPool
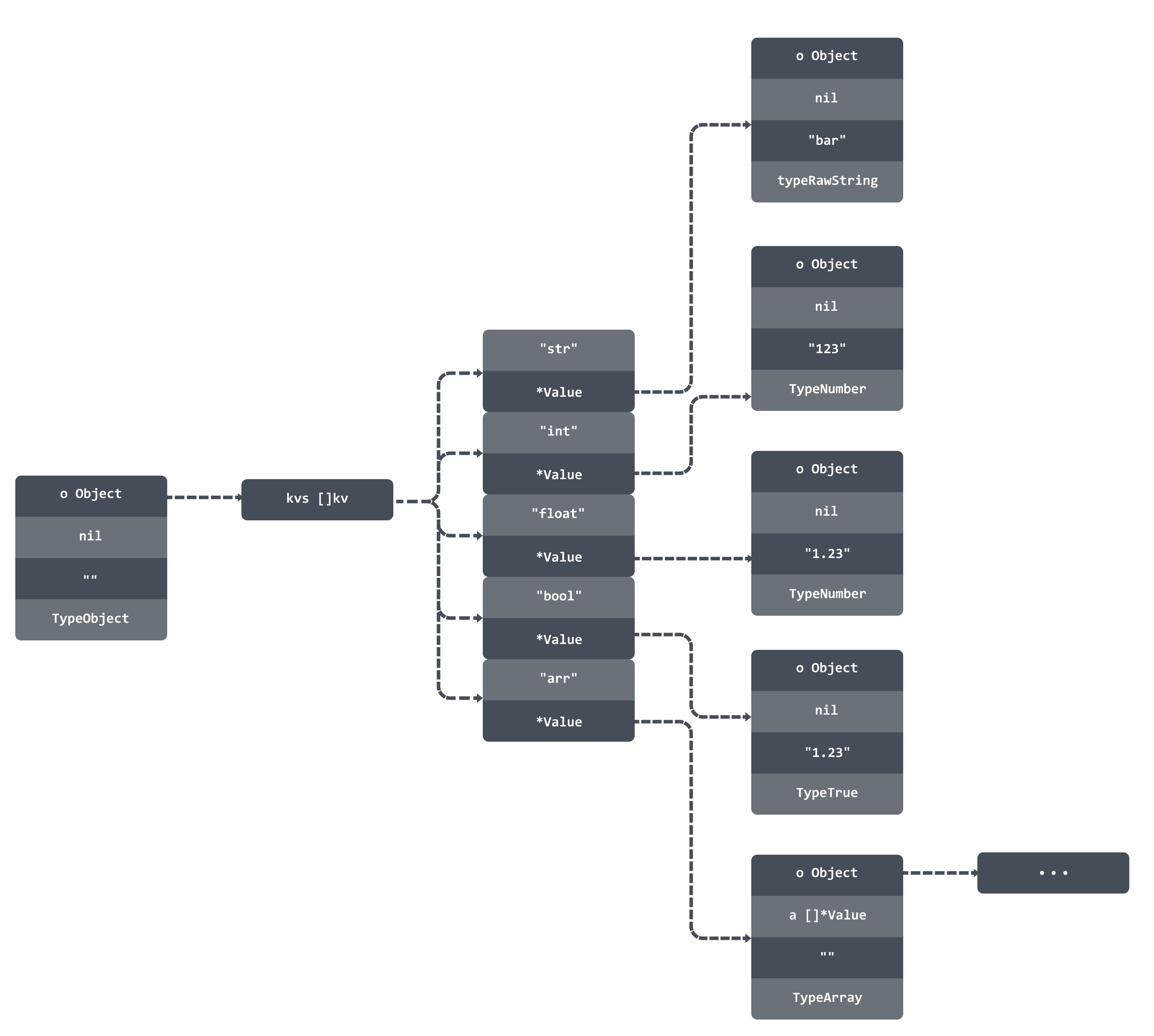
fastjson 是从上往下依次遍历 JSON ,然后解析好的数据存放在 Value 结构体中:
type Value struct {
o Object
a []*Value
s string
t Type
}
这个结构体非常简单:
o Object:表示被解析的结构是一个对象;a []*Value:表示表示被解析的结构是个数组;s string:如果被解析的结构不是对象也不是数组,那么其他类型的值会以字符串的形式存放在这个字段中;t Type:表示这个结构的类型,有 TypeObject、TypeArray、TypeString、TypeNumber等。
type Object struct {
kvs []kv
keysUnescaped bool
}
type kv struct {
k string
v *Value
}
这个结构存放对象的递归结构。如果把上面例子中的 JSON 串解析完毕之后就是这样一个结构:
代码
在代码实现上,由于没有了反射部分的代码,所以整个解析过程变得非常的清爽。我们直接看看主干部分的解析:
func parseValue(s string, c *cache, depth int) (*Value, string, error) {
if len(s) == 0 {
return nil, s, fmt.Errorf("cannot parse empty string")
}
depth++
// 最大深度的json串不能超过MaxDepth
if depth > MaxDepth {
return nil, s, fmt.Errorf("too big depth for the nested JSON; it exceeds %d", MaxDepth)
}
// 解析对象
if s[0] == '{' {
v, tail, err := parseObject(s[1:], c, depth)
if err != nil {
return nil, tail, fmt.Errorf("cannot parse object: %s", err)
}
return v, tail, nil
}
// 解析数组
if s[0] == '[' {
...
}
// 解析字符串
if s[0] == '"' {
...
}
...
return v, tail, nil
}
parseValue 会根据字符串的第一个非空字符来判断要解析的类型。这里用一个对象类型来做解析:
func parseObject(s string, c *cache, depth int) (*Value, string, error) {
...
o := c.getValue()
o.t = TypeObject
o.o.reset()
for {
var err error
// 获取Ojbect结构体中的 kv 对象
kv := o.o.getKV()
...
// 解析 key 值
kv.k, s, err = parseRawKey(s[1:])
...
// 递归解析 value 值
kv.v, s, err = parseValue(s, c, depth)
...
// 遇到 ,号继续往下解析
if s[0] == ',' {
s = s[1:]
continue
}
// 解析完毕
if s[0] == '}' {
return o, s[1:], nil
}
return nil, s, fmt.Errorf("missing ',' after object value")
}
}
parseObject 函数也非常简单,在循环体中会获取 key 值,然后调用 parseValue 递归解析 value 值,从上往下依次解析 JSON 对象,直到最后遇到 }退出。
小结
通过上面的分析可以知道 fastjson 在实现上比标准库简单不少,性能也高上不少。使用 Parse 解析好 JSON 树之后可以多次反复使用,避免了需要反复解析进而提升性能。
但是它的功能是非常的简陋的,没有常用的如 JSON 转 Struct 或 JSON 转 map 的操作。如果只是想简单的获取 JSON 中的值,那么使用这个库是非常方便的,但是如果想要把 JSON 值转化成一个结构体就需要自己动手一个个设值了。
GJSON
库地址:https://github.com/tidwall/gjson
GJSON 在我的测试中,虽然性能是没有 fastjson 这么极致,但是功能是非常完善,性能也是相当 OK 的,下面先简单介绍一下 GJSON 的功能。
GJSON 的使用是和 fastjson 差不多的,也是非常的简单,只要在参数中传入 json 串以及需要获取的值即可:
json := `{"name":{"first":"li","last":"dj"},"age":18}`
lastName := gjson.Get(json, "name.last")
除了这个功能以外还可以进行简单的模糊匹配,支持在键中包含通配符*和?,*匹配任意多个字符,?匹配单个字符,如下:
json := `{
"name":{"first":"Tom", "last": "Anderson"},
"age": 37,
"children": ["Sara", "Alex", "Jack"]
}`
fmt.Println("third child*:", gjson.Get(json, "child*.2"))
fmt.Println("first c?ild:", gjson.Get(json, "c?ildren.0"))
child*.2:首先child*匹配children,.2读取第 3 个元素;c?ildren.0:c?ildren匹配到children,.0读取第一个元素;
除了模糊匹配以外还支持修饰符操作:
json := `{
"name":{"first":"Tom", "last": "Anderson"},
"age": 37,
"children": ["Sara", "Alex", "Jack"]
}`
fmt.Println("third child*:", gjson.Get(json, "children|@reverse"))
children|@reverse 先读取数组children,然后使用修饰符@reverse翻转之后返回,输出。
nestedJSON := `{"nested": ["one", "two", ["three", "four"]]}`
fmt.Println(gjson.Get(nestedJSON, "nested|@flatten"))
@flatten将数组nested的内层数组平摊到外层后返回:
["one","two","three", "four"]
等等还有一些其他有意思的功能,大家可以去查阅一下官方文档。
分析
GJSON 的 Get 方法参数是由两部分组成,一个是 JSON 串,另一个叫做 Path 表示需要获取的 JSON 值的匹配路径。
在 GJSON 中因为要满足很多的定义的解析场景,所以解析是分为两部分的,需要先解析好 Path 之后才去遍历解析 JSON 串。
在解析过程中如果遇到可以匹配上的值,那么会直接返回,不需要继续往下遍历,如果是匹配多个值,那么会一直遍历完整个 JSON 串。如果遇到某个 Path 在 JSON 串中匹配不到,那么也是需要遍历完整个 JSON 串。
在解析的过程中也不会像 fastjson 一样将解析的内容保存在一个结构体中,可以反复的利用。所以当调用 GetMany 想要返回多个值的时候,其实也是需要遍历 JSON 串多次,因此效率会比较低。
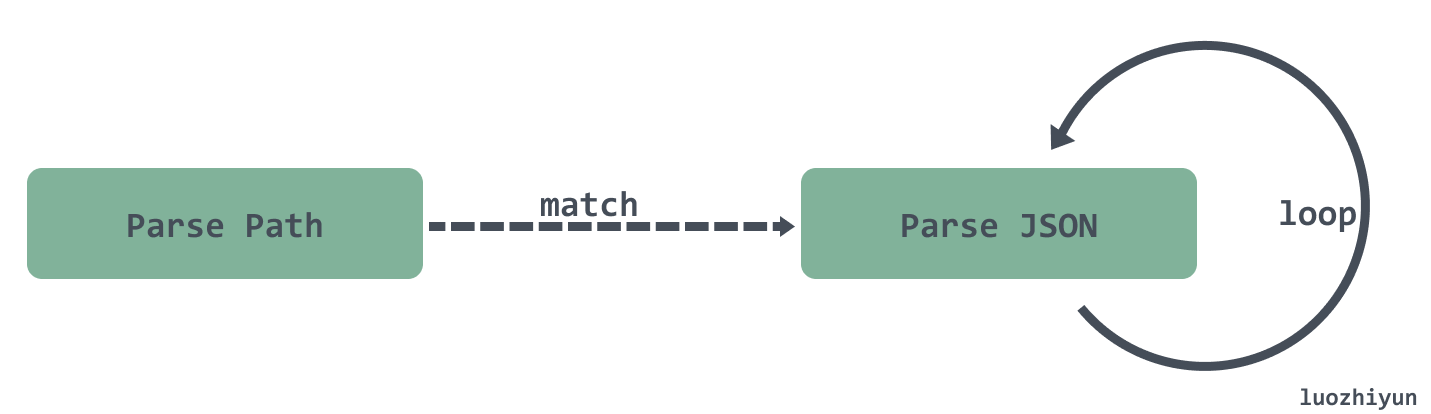
除此之外,在解析 JSON 的时候并不会对它进行校验,即使这个放入的字符串不是个 JSON 也会照样解析,所以需要用户自己去确保放入的是 JSON 。
代码
func Get(json, path string) Result {
// 解析 path
if len(path) > 1 {
...
}
var i int
var c = &parseContext{json: json}
if len(path) >= 2 && path[0] == '.' && path[1] == '.' {
c.lines = true
parseArray(c, 0, path[2:])
} else {
// 根据不同的对象进行解析,这里会一直循环,直到找到 '{' 或 '['
for ; i < len(c.json); i++ {
if c.json[i] == '{' {
i++
parseObject(c, i, path)
break
}
if c.json[i] == '[' {
i++
parseArray(c, i, path)
break
}
}
}
if c.piped {
res := c.value.Get(c.pipe)
res.Index = 0
return res
}
fillIndex(json, c)
return c.value
}
Get 方法里面可以看到有很长一串的代码是用来解析各种 Path,然后一个 for 循环一直遍历 JSON 直到找到 '{' 或 '[',然后才进行相应的逻辑进行处理。
func parseObject(c *parseContext, i int, path string) (int, bool) {
var pmatch, kesc, vesc, ok, hit bool
var key, val string
rp := parseObjectPath(path)
if !rp.more && rp.piped {
c.pipe = rp.pipe
c.piped = true
}
// 嵌套两个 for 循环 寻找 key 值
for i < len(c.json) {
for ; i < len(c.json); i++ {
if c.json[i] == '"' {
i++
var s = i
for ; i < len(c.json); i++ {
if c.json[i] > '\\' {
continue
}
// 找到 key 值跳转到 parse_key_string_done
if c.json[i] == '"' {
i, key, kesc, ok = i+1, c.json[s:i], false, true
goto parse_key_string_done
}
...
}
key, kesc, ok = c.json[s:], false, false
// 直接break
parse_key_string_done:
break
}
if c.json[i] == '}' {
return i + 1, false
}
}
if !ok {
return i, false
}
// 校验是否是模糊匹配
if rp.wild {
if kesc {
pmatch = match.Match(unescape(key), rp.part)
} else {
pmatch = match.Match(key, rp.part)
}
} else {
if kesc {
pmatch = rp.part == unescape(key)
} else {
pmatch = rp.part == key
}
}
// 解析 value
hit = pmatch && !rp.more
for ; i < len(c.json); i++ {
switch c.json[i] {
default:
continue
case '"':
i++
i, val, vesc, ok = parseString(c.json, i)
if !ok {
return i, false
}
if hit {
if vesc {
c.value.Str = unescape(val[1 : len(val)-1])
} else {
c.value.Str = val[1 : len(val)-1]
}
c.value.Raw = val
c.value.Type = String
return i, true
}
case '{':
if pmatch && !hit {
i, hit = parseObject(c, i+1, rp.path)
if hit {
return i, true
}
} else {
i, val = parseSquash(c.json, i)
if hit {
c.value.Raw = val
c.value.Type = JSON
return i, true
}
}
...
break
}
}
return i, false
}
在上面看 parseObject 这段代码的时候其实不是想让大家学习如何解析 JSON,以及遍历字符串,而是想要让大家看看一个 bad case 是怎样的。for 循环一层套一层,if 一个接一个看得我 San 值狂掉,这段代码大家是不是看起来很眼熟?是不是有点像工作中遇到的某个同事写的代码?
小结
优点:
- 性能相对标准库来说还算不错;
- 可玩性高,可以各种检索、自定义返回值,这点非常方便;
缺点:
- 不会校验 JSON 的正确性;
- 代码的 Code smell 很重。
需要注意的是,如果需要解析返回 JSON 的值的话,GetMany 函数会根据指定的 key 值来一次次遍历 JSON 字符串,解析为 map 可以减少遍历次数。
jsonparser
库地址:https://github.com/buger/jsonparser
这也是一个比较热门,并且号称高性能,能比标准库快十倍的解析速度。
分析
jsonparser 也是传入一个 JSON 的 byte 切片,以及可以通过传入多个 key 值来快速定位到相应的值,并返回。
和 GJSON 一样,在解析过程中是不会像 fastjson 一样有个数据结构缓存已解析过的 JSON字符串,但是遇到需要解析多个值的情况可以使用 EachKey 函数来解析多个值,只需要遍历一次 JSON字符串即可实现获取多个值的操作。
如果遇到可以匹配上的值,那么会直接返回,不需要继续往下遍历,如果是匹配多个值,那么会一直遍历完整个 JSON 串。如果遇到某个 Path 在 JSON 串中匹配不到,那么也是需要遍历完整个 JSON 串。
并且在遍历 JSON 串的时候通过循环的方式来减少递归的使用,减少了调用栈的深度,一定程度上也是可以提升性能。
在功能性上 ArrayEach、ObjectEach、EachKey 等三个函数都可以传入一个自定义的函数,通过函数来实现个性化的需求,使得实用性大大增强。
对于 jsonparser 来说,代码没什么可分析的,非常的清晰,感兴趣的可以自己去看看。
小结
对于 jsonparser 来说相对标准库比较而言性能如此高的原因可以总结为:
- 使用 for 循环来减少递归的使用;
- 相比标准库而言没有使用反射;
- 在查找相应的 key 值找到了便直接退出,可以不用继续往下递归;
- 所操作的 JSON 串都是已被传入的,不会去重新再去申请新的空间,减少了内存分配;
除此之外在 api 的设计上也是非常的实用,ArrayEach、ObjectEach、EachKey 等三个函数都可以传入一个自定义的函数在实际的业务开发中解决了不少问题。
缺点也是非常的明显,不能对 JSON 进行校验,即使这个 传入的不是 JSON。
性能对比
解析小 JSON 字符串
解析一个结构简单,大小约 190 bytes 的字符串
| 库名 | 操作 | 每次迭代耗时 | 占用内存数 | 分配内存次数 | 性能 |
|---|---|---|---|---|---|
| 标准库 | 解析为map | 724 ns/op | 976 B/op | 51 allocs/op | 慢 |
| 解析为struct | 297 ns/op | 256 B/op | 5 allocs/op | 一般 | |
| fastjson | get | 68.2 ns/op | 0 B/op | 0 allocs/op | 最快 |
| parse | 35.1 ns/op | 0 B/op | 0 allocs/op | 最快 | |
| GJSON | 转map | 255 ns/op | 1009 B/op | 11 allocs/op | 一般 |
| get | 232 ns/op | 448 B/op | 1 allocs/op | 一般 | |
| jsonparser | get | 106 ns/op | 232 B/op | 3 allocs/op | 快 |
解析中等大小 JSON 字符串
解析一个具有一定复杂度,大小约 2.3KB 的字符串
| 库名 | 操作 | 每次迭代耗时 | 占用内存数 | 分配内存次数 | 性能 |
|---|---|---|---|---|---|
| 标准库 | 解析为map | 4263 ns/op | 10212 B/op | 208 allocs/op | 慢 |
| 解析为struct | 4789 ns/op | 9206 B/op | 259 allocs/op | 慢 | |
| fastjson | get | 285 ns/op | 0 B/op | 0 allocs/op | 最快 |
| parse | 302 ns/op | 0 B/op | 0 allocs/op | 最快 | |
| GJSON | 转map | 2571 ns/op | 8539 B/op | 83 allocs/op | 一般 |
| get | 1489 ns/op | 448 B/op | 1 allocs/op | 一般 | |
| jsonparser | get | 878 ns/op | 2728 B/op | 5 allocs/op | 快 |
解析大 JSON 字符串
解析复杂度比较高,大小约 2.2MB 的字符串
| 库名 | 操作 | 每次迭代耗时 | 占用内存数 | 分配内存次数 | 性能 |
|---|---|---|---|---|---|
| 标准库 | 解析为map | 2292959 ns/op | 5214009 B/op | 95402 allocs/op | 慢 |
| 解析为struct | 1165490 ns/op | 2023 B/op | 76 allocs/op | 一般 | |
| fastjson | get | 368056 ns/op | 0 B/op | 0 allocs/op | 快 |
| parse | 371397 ns/op | 0 B/op | 0 allocs/op | 快 | |
| GJSON | 转map | 1901727 ns/op | 4788894 B/op | 54372 allocs/op | 一般 |
| get | 1322167 ns/op | 448 B/op | 1 allocs/op | 一般 | |
| jsonparser | get | 233090 ns/op | 1788865 B/op | 376 allocs/op | 最快 |
总结
在这次的分享过程中,我找了很多 JSON 的解析库分别进行对比分析,可以发现这些高性能的解析库基本上都有一些共同的特点:
- 不使用反射;
- 通过遍历 JSON 字符串的字节来挨个解析;
- 尽量使用传入的 JSON 字符串来进行解析遍历,减少内存分配;
- 牺牲了一定的兼容性;
尽管如此,但是功能上,每个都有一定的特色 fastjson 的 api 操作最简单;GJSON 提供了模糊查找的功能,自定义程度最高;jsonparser 在实现高性能的解析过程中,还可以插入回调函数执行,提供了一定程度上的便利。
综上,回到文章的开头中,对于我自己的业务来说,业务也只是简单的解析 http 请求返回的 JSON 串的部分字段,并且字段都是确定的,无需搜索功能,但是有时候需要做一些自定义的操作,所以对我来说 jsonparser 是最合适的。
所以如果各位对性能有一定要求,不妨结合自己的业务情况来挑选一款 JSON 解析器。
Reference
- https://github.com/buger/jsonparser
- https://github.com/tidwall/gjson
- https://github.com/valyala/fastjson
- https://github.com/json-iterator/go
- https://github.com/mailru/easyjson
- https://github.com/Jeffail/gabs
- https://github.com/bitly/go-simplejson


