
【全网首发】万字图文 | 你写的代码是如何跑起来的?原创
大家好,我是飞哥!
今天我们来思考一个简单的问题,一个程序是如何在 Linux 上执行起来的?
我们就拿全宇宙最简单的 Hello World 程序来举例。
#include <stdio.h>
int main()
{
printf("Hello, World!\n");
return 0;
}
我们在写完代码后,进行简单的编译,然后在 shell 命令行下就可以把它启动起来。
# gcc main.c -o helloworld
# ./helloworld
Hello, World!
那么在编译启动运行的过程中都发生了哪些事情了呢?今天就让我们来深入地了解一下。
一、理解可执行文件格式
源代码在编译后会生成一个可执行程序文件,我们先来了解一下编译后的二进制文件是什么样子的。
我们首先使用 file 命令查看一下这个文件的格式。
# file helloworld
helloworld: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), ...
file 命令给出了这个二进制文件的概要信息,其中 ELF 64-bit LSB executable 表示这个文件是一个 ELF 格式的 64 位的可执行文件。x86-64 表示该可执行文件支持的 cpu 架构。
LSB 的全称是 Linux Standard Base,是 Linux 标准规范。其目的是制定一系列标准来增强 Linux 发行版的兼容性。
ELF 的全称是 Executable Linkable Format,是一种二进制文件格式。Linux 下的目标文件、可执行文件和 CoreDump 都按照该格式进行存储。
ELF 文件由四部分组成,分别是 ELF 文件头 (ELF header)、Program header table、Section 和 Section header table。
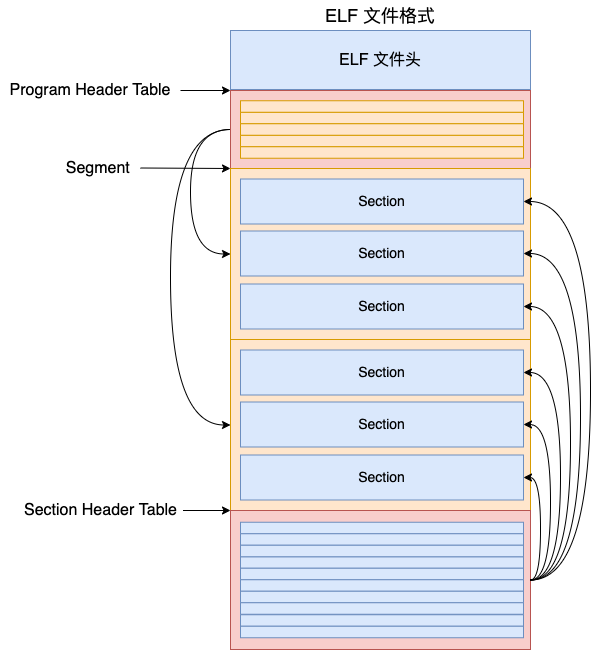
接下来我们分几个小节挨个介绍一下。
1.1 ELF 文件头
ELF 文件头记录了整个文件的属性信息。原始二进制非常不便于观察。不过我们有趁手的工具 - readelf,这个工具可以帮我们查看 ELF 文件中的各种信息。
我们先来看一下编译出来的可执行文件的 ELF 文件头,使用 --file-header (-h) 选项即可查看。
# readelf --file-header helloworld
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x401040
Start of program headers: 64 (bytes into file)
Start of section headers: 23264 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 11
Size of section headers: 64 (bytes)
Number of section headers: 30
Section header string table index: 29
ELF 文件头包含了当前可执行文件的概要信息,我把其中关键的几个拿出来给大家解释一下。
-
Magic:一串特殊的识别码,主要用于外部程序快速地对这个文件进行识别,快速地判断文件类型是不是 ELF -
Class:表示这是 ELF64 文件 -
Type:为 EXEC 表示是可执行文件,其它文件类型还有 REL(可重定位的目标文件)、DYN(动态链接库)、CORE(系统调试 coredump文件) -
Entry point address:程序入口地址,这里显示入口在 0x401040 位置处 -
Size of this header:ELF 文件头的大小,这里显示是占用了 64 字节
以上几个字段是 ELF 头中对 ELF 的整体描述。另外 ELF 头中还有关于 program headers 和 section headers 的描述信息。
-
Start of program headers:表示 Program header 的位置 -
Size of program headers:每一个 Program header 大小 -
Number of program headers:总共有多少个 Program header -
Start of section headers: 表示 Section header 的开始位置。 -
Size of section headers:每一个 Section header 的大小 -
Number of section headers: 总共有多少个 Section header
1.2 Program Header Table
在介绍 Program Header Table 之前我们展开介绍一下 ELF 文件中一对儿相近的概念 - Segment 和 Section。
ELF 文件内部最重要的组成单位是一个一个的 Section。每一个 Section 都是由编译链接器生成的,都有不同的用途。例如编译器会将我们写的代码编译后放到 .text Section 中,将全局变量放到 .data 或者是 .bss Section中。
但是对于操作系统来说,它不关注具体的 Section 是啥,它只关注这块内容应该以何种权限加载到内存中,例如读,写,执行等权限属性。因此相同权限的 Section 可以放在一起组成 Segment,以方便操作系统更快速地加载。

由于 Segment 和 Section 翻译成中文的话,意思太接近了,非常不利于理解。所以本文中我就直接使用 Segment 和 Section 原汁原味的概念,而不是将它们翻译成段或者是节,这样太容易让人混淆了。
Program headers table 就是作为所有 Segments 的头信息,用来描述所有的 Segments 的。。
使用 readelf 工具的 --program-headers(-l)选项可以解析查看到这块区域里存储的内容。
# readelf --program-headers helloworld
Elf file type is EXEC (Executable file)
Entry point 0x401040
There are 11 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x0000000000000268 0x0000000000000268 R 0x8
INTERP 0x00000000000002a8 0x00000000004002a8 0x00000000004002a8
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x0000000000000438 0x0000000000000438 R 0x1000
LOAD 0x0000000000001000 0x0000000000401000 0x0000000000401000
0x00000000000001c5 0x00000000000001c5 R E 0x1000
LOAD 0x0000000000002000 0x0000000000402000 0x0000000000402000
0x0000000000000138 0x0000000000000138 R 0x1000
LOAD 0x0000000000002e10 0x0000000000403e10 0x0000000000403e10
0x0000000000000220 0x0000000000000228 RW 0x1000
DYNAMIC 0x0000000000002e20 0x0000000000403e20 0x0000000000403e20
0x00000000000001d0 0x00000000000001d0 RW 0x8
NOTE 0x00000000000002c4 0x00000000004002c4 0x00000000004002c4
0x0000000000000044 0x0000000000000044 R 0x4
GNU_EH_FRAME 0x0000000000002014 0x0000000000402014 0x0000000000402014
0x000000000000003c 0x000000000000003c R 0x4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0x10
GNU_RELRO 0x0000000000002e10 0x0000000000403e10 0x0000000000403e10
0x00000000000001f0 0x00000000000001f0 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt
03 .init .plt .text .fini
04 .rodata .eh_frame_hdr .eh_frame
05 .init_array .fini_array .dynamic .got .got.plt .data .bss
06 .dynamic
07 .note.gnu.build-id .note.ABI-tag
08 .eh_frame_hdr
09
10 .init_array .fini_array .dynamic .got
上面的结果显示总共有 11 个 program headers。
对于每一个段,输出了 Offset、VirtAddr 等描述当前段的信息。Offset 表示当前段在二进制文件中的开始位置,FileSiz 表示当前段的大小。Flag 表示当前的段的权限类型, R 表示可都、E 表示可执行、W 表示可写。
在最下面,还把每个段是由哪几个 Section 组成的给展示了出来,比如 03 号段是由“.init .plt .text .fini” 四个 Section 组成的。

1.3 Section Header Table
和 Program Header Table 不一样的是,Section header table 直接描述每一个 Section。这二者描述的其实都是各种 Section ,只不过目的不同,一个针对加载,一个针对链接。
使用 readelf 工具的 --section-headers (-S)选项可以解析查看到这块区域里存储的内容。
# readelf --section-headers helloworld
There are 30 section headers, starting at offset 0x5b10:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
......
[13] .text PROGBITS 0000000000401040 00001040
0000000000000175 0000000000000000 AX 0 0 16
......
[23] .data PROGBITS 0000000000404020 00003020
0000000000000010 0000000000000000 WA 0 0 8
[24] .bss NOBITS 0000000000404030 00003030
0000000000000008 0000000000000000 WA 0 0 1
......
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
结果显示,该文件总共有 30 个 Sections,每一个 Section 在二进制文件中的位置通过 Offset 列表示了出来。Section 的大小通过 Size 列体现。
在这 30 个Section中,每一个都有独特的作用。我们编写的代码在编译成二进制指令后都会放到 .text 这个 Section 中。另外我们看到 .text 段的 Address 列显示的地址是 0000000000401040。回忆前面我们在 ELF 文件头中看到 Entry point address 显示的入口地址为 0x401040。这说明,程序的入口地址就是 .text 段的地址。
另外还有两个值得关注的 Section 是 .data 和 .bss。代码中的全局变量数据在编译后将在在这两个 Section 中占据一些位置。如下简单代码所示。
//未初始化的内存区域位于 .bss 段
int data1 ;
//已经初始化的内存区域位于 .data 段
int data2 = 100 ;
//代码位于 .text 段
int main(void)
{
...
}
1.4 入口进一步查看
接下来,我们想再查看一下我们前面提到的程序入口 0x401040,看看它到底是啥。我们这次再借助 nm 命令来进一步查看一下可执行文件中的符号及其地址信息。-n 选项的作用是显示的符号以地址排序,而不是名称排序。
# nm -n helloworld
w __gmon_start__
U __libc_start_main@@GLIBC_2.2.5
U printf@@GLIBC_2.2.5
......
0000000000401040 T _start
......
0000000000401126 T main
通过以上输出可以看到,程序入口 0x401040 指向的是 _start 函数的地址,在这个函数执行一些初始化的操作之后,我们的入口函数 main 将会被调用到,它位于 0x401126 地址处。
二、用户进程的创建过程概述
在我们编写的代码编译完生成可执行程序之后,下一步就是使用 shell 把它加载起来并运行之。一般来说 shell 进程是通过fork+execve来加载并运行新进程的。一个简单加载 helloworld 命令的 shell 核心逻辑是如下这个过程。
// shell 代码示例
int main(int argc, char * argv[])
{
...
pid = fork();
if (pid==0){ // 如果是在子进程中
//使用 exec 系列函数加载并运行可执行文件
execve("helloworld", argv, envp);
} else {
...
}
...
}
shell 进程先通过 fork 系统调用创建一个进程出来。然后在子进程中调用 execve 将执行的程序文件加载起来,然后就可以调到程序文件的运行入口处运行这个程序了。
在上一篇文章《Linux进程是如何创建出来的?》中,我们详细介绍过了 fork 的工作过程。这里我们再简单过一下。
这个 fork 系统调用在内核入口是在 kernel/fork.c 下。
//file:kernel/fork.c
SYSCALL_DEFINE0(fork)
{
return do_fork(SIGCHLD, 0, 0, NULL, NULL);
}
在 do_fork 的实现中,核心是一个 copy_process 函数,它以拷贝父进程(线程)的方式来生成一个新的 task_struct 出来。
//file:kernel/fork.c
long do_fork(...)
{
//复制一个 task_struct 出来
struct task_struct *p;
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
//子任务加入到就绪队列中去,等待调度器调度
wake_up_new_task(p);
...
}
在 copy_process 函数中为新进程申请 task_struct,并用当前进程自己的地址空间、命名空间等对新进程进行初始化,并为其申请进程 pid。
//file:kernel/fork.c
static struct task_struct *copy_process(...)
{
//复制进程 task_struct 结构体
struct task_struct *p;
p = dup_task_struct(current);
...
//进程核心元素初始化
retval = copy_files(clone_flags, p);
retval = copy_fs(clone_flags, p);
retval = copy_mm(clone_flags, p);
retval = copy_namespaces(clone_flags, p);
...
//申请 pid && 设置进程号
pid = alloc_pid(p->nsproxy->pid_ns);
p->pid = pid_nr(pid);
p->tgid = p->pid;
......
}
执行完后,进入 wake_up_new_task 让新进程等待调度器调度。
不过 fork 系统调用只能是根据当的 shell 进程再复制一个新的进程出来。这个新进程里的代码、数据都还是和原来的 shell 进程的内容一模一样。
要想实现加载并运行另外一个程序,比如我们编译出来的 helloworld 程序,那还需要使用到 execve 系统调用。
三. Linux 可执行文件加载器
其实 Linux 不是写死只能加载 ELF 一种可执行文件格式的。它在启动的时候,会把自己支持的所有可执行文件的解析器都加载上。并使用一个 formats 双向链表来保存所有的解析器。其中 formats 双向链表在内存中的结构如下图所示。
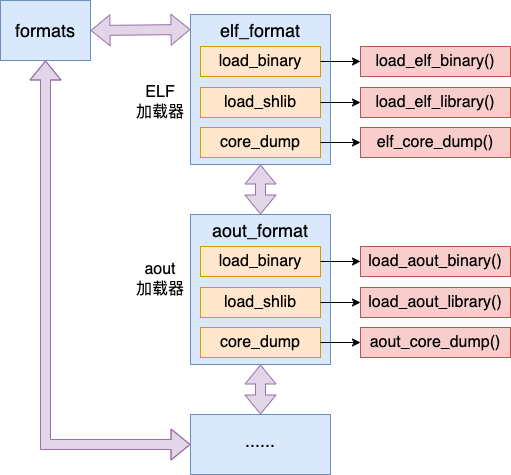
我们就以 ELF 的加载器 elf_format 为例,来看看这个加载器是如何注册的。在 Linux 中每一个加载器都用一个 linux_binfmt 结构来表示。其中规定了加载二进制可执行文件的 load_binary 函数指针,以及加载崩溃文件 的 core_dump 函数等。其完整定义如下
//file:include/linux/binfmts.h
struct linux_binfmt {
...
int (*load_binary)(struct linux_binprm *);
int (*load_shlib)(struct file *);
int (*core_dump)(struct coredump_params *cprm);
};
其中 ELF 的加载器 elf_format 中规定了具体的加载函数,例如 load_binary 成员指向的就是具体的 load_elf_binary 函数。这就是 ELF 加载的入口。
//file:fs/binfmt_elf.c
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library,
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
};
加载器 elf_format 会在初始化的时候通过 register_binfmt 进行注册。
//file:fs/binfmt_elf.c
static int __init init_elf_binfmt(void)
{
register_binfmt(&elf_format);
return 0;
}
而 register_binfmt 就是将加载器挂到全局加载器列表 - formats 全局链表中。
//file:fs/exec.c
static LIST_HEAD(formats);
void __register_binfmt(struct linux_binfmt * fmt, int insert)
{
...
insert ? list_add(&fmt->lh, &formats) :
list_add_tail(&fmt->lh, &formats);
}
Linux 中除了 elf 文件格式以外还支持其它格式,在源码目录中搜索 register_binfmt,可以搜索到所有 Linux 操作系统支持的格式的加载程序。
# grep -r "register_binfmt" *
fs/binfmt_flat.c: register_binfmt(&flat_format);
fs/binfmt_elf_fdpic.c: register_binfmt(&elf_fdpic_format);
fs/binfmt_som.c: register_binfmt(&som_format);
fs/binfmt_elf.c: register_binfmt(&elf_format);
fs/binfmt_aout.c: register_binfmt(&aout_format);
fs/binfmt_script.c: register_binfmt(&script_format);
fs/binfmt_em86.c: register_binfmt(&em86_format);
将来在 Linux 在加载二进制文件时会遍历 formats 链表,根据要加载的文件格式来查询合适的加载器。
四、execve 加载用户程序
具体加载可执行文件的工作是由 execve 系统调用来完成的。
该系统调用会读取用户输入的可执行文件名,参数列表以及环境变量等开始加载并运行用户指定的可执行文件。该系统调用的位置在 fs/exec.c 文件中。
//file:fs/exec.c
SYSCALL_DEFINE3(execve, const char __user *, filename, ...)
{
struct filename *path = getname(filename);
do_execve(path->name, argv, envp)
...
}
int do_execve(...)
{
...
return do_execve_common(filename, argv, envp);
}
execve 系统调用到了 do_execve_common 函数。我们来看这个函数的实现。
//file:fs/exec.c
static int do_execve_common(const char *filename, ...)
{
//linux_binprm 结构用于保存加载二进制文件时使用的参数
struct linux_binprm *bprm;
//1.申请并初始化 brm 对象值
bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
bprm->file = ...;
bprm->filename = ...;
bprm_mm_init(bprm)
bprm->argc = count(argv, MAX_ARG_STRINGS);
bprm->envc = count(envp, MAX_ARG_STRINGS);
prepare_binprm(bprm);
...
//2.遍历查找合适的二进制加载器
search_binary_handler(bprm);
}
这个函数中申请并初始化 brm 对象的具体工作可以用下图来表示。
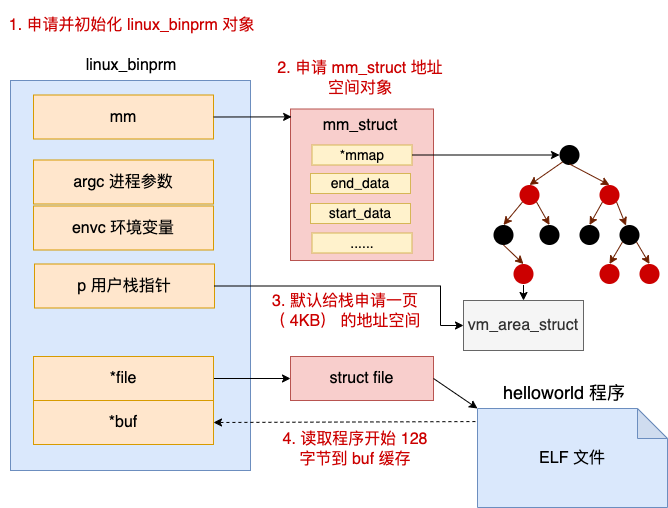
在这个函数中,完成了一下三块工作。
第一、使用 kzalloc 申请 linux_binprm 内核对象。该内核对象用于保存加载二进制文件时使用的参数。在申请完后,对该参数对象进行各种初始化。
第二、在 bprm_mm_init 中会申请一个全新的 mm_struct 对象,准备留着给新进程使用。
第三、给新进程的栈申请一页的虚拟内存空间,并将栈指针记录下来。
第四、读取二进制文件头 128 字节。
我们来看下初始化栈的相关代码。
//file:fs/exec.c
static int __bprm_mm_init(struct linux_binprm *bprm)
{
bprm->vma = vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
vma->vm_end = STACK_TOP_MAX;
vma->vm_start = vma->vm_end - PAGE_SIZE;
...
bprm->p = vma->vm_end - sizeof(void *);
}
在上面这个函数中申请了一个 vma 对象(表示虚拟地址空间里的一段范围),vm_end 指向了 STACK_TOP_MAX(地址空间的顶部附近的位置),vm_start 和 vm_end 之间留了一个 Page 大小。也就是说默认给栈申请了 4KB 的大小。最后把栈的指针记录到 bprm->p 中。
另外再看下 prepare_binprm,在这个函数中,从文件头部读取了 128 字节。之所以这么干,是为了读取二进制文件头为了方便后面判断其文件类型。
//file:include/uapi/linux/binfmts.h
#define BINPRM_BUF_SIZE 128
//file:fs/exec.c
int prepare_binprm(struct linux_binprm *bprm)
{
......
memset(bprm->buf, 0, BINPRM_BUF_SIZE);
return kernel_read(bprm->file, 0, bprm->buf, BINPRM_BUF_SIZE);
}
在申请并初始化 brm 对象值完后,最后使用 search_binary_handler 函数遍历系统中已注册的加载器,尝试对当前可执行文件进行解析并加载。
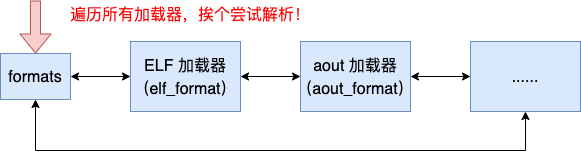
在 3.1 节我们介绍了系统所有的加载器都注册到了 formats 全局链表里了。函数 search_binary_handler 的工作过程就是遍历这个全局链表,根据二进制文件头中携带的文件类型数据查找解析器。找到后调用解析器的函数对二进制文件进行加载。
//file:fs/exec.c
int search_binary_handler(struct linux_binprm *bprm)
{
...
for (try=0; try<2; try++) {
list_for_each_entry(fmt, &formats, lh) {
int (*fn)(struct linux_binprm *) = fmt->load_binary;
...
retval = fn(bprm);
//加载成功的话就返回了
if (retval >= 0) {
...
return retval;
}
//加载失败继续循环以尝试加载
...
}
}
}
在上述代码中的 list_for_each_entry 是在遍历 formats 这个全局链表,遍历时判断每一个链表元素是否有 load_binary 函数。有的话就调用它尝试加载。
回忆一下 3.1 注册可执行文件加载程序,对于 ELF 文件加载器 elf_format 来说, load_binary 函数指针指向的是 load_elf_binary。
//file:fs/binfmt_elf.c
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
......
};
那么加载工作就会进入到 load_elf_binary 函数中来进行。这个函数很长,可以说所有的程序加载逻辑都在这个函数中体现了。我根据这个函数的主要工作,分成以下 5 个小部分来给大家介绍。
在介绍的过程中,为了表达清晰,我会稍微调一下源码的位置,可能和内核源码行数顺序会有所不同。
4.1 ELF 文件头读取
在 load_elf_binary 中首先会读取 ELF 文件头。
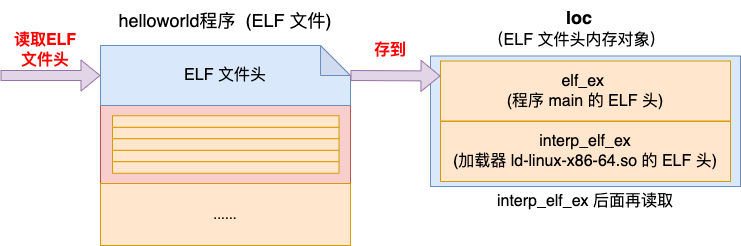
文件头中包含一些当前文件格式类型等数据,所以在读取完文件头后会进行一些合法性判断。如果不合法,则退出返回。
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//定义结构题并申请内存用来保存 ELF 文件头
struct {
struct elfhdr elf_ex;
struct elfhdr interp_elf_ex;
} *loc;
loc = kmalloc(sizeof(*loc), GFP_KERNEL);
//获取二进制头
loc->elf_ex = *((struct elfhdr *)bprm->buf);
//对头部进行一系列的合法性判断,不合法则直接退出
if (loc->elf_ex.e_type != ET_EXEC && ...){
goto out;
}
...
}
4.2 Program Header 读取
在 ELF 文件头中记录着 Program Header 的数量,而且在 ELF 头之后紧接着就是 Program Header Tables。所以内核接下来可以将所有的 Program Header 都读取出来。
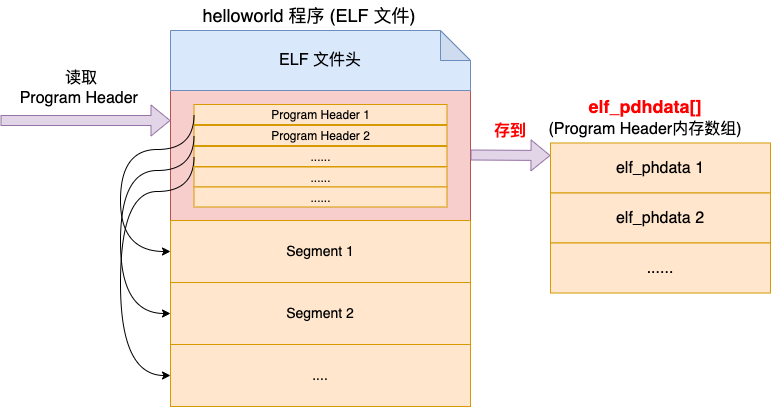
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//4.2 Program Header 读取
// elf_ex.e_phnum 中保存的是 Programe Header 数量
// 再根据 Program Header 大小 sizeof(struct elf_phdr)
// 一起计算出所有的 Program Header 大小,并读取进来
size = loc->elf_ex.e_phnum * sizeof(struct elf_phdr);
elf_phdata = kmalloc(size, GFP_KERNEL);
kernel_read(bprm->file, loc->elf_ex.e_phoff,
(char *)elf_phdata, size);
...
}
4.3 清空父进程继承来的资源
在 fork 系统调用创建出来的进程中,包含了不少原进程的信息,如老的地址空间,信号表等等。这些在新的程序运行时并没有什么用,所以需要清空处理一下。
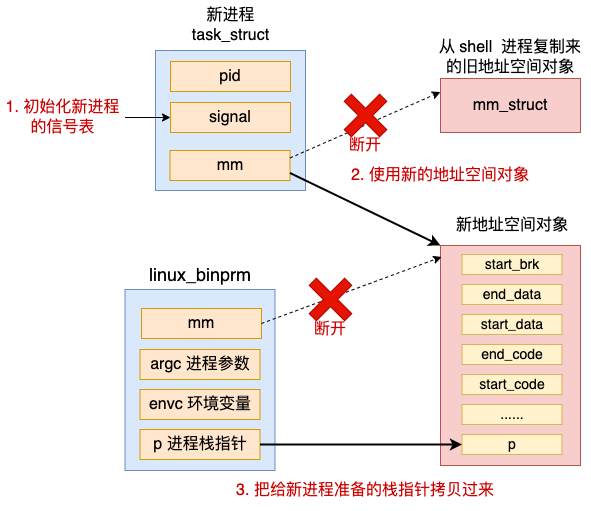
具体工作包括初始化新进程的信号表,应用新的地址空间对象等。
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//4.2 Program Header 读取
//4.3 清空父进程继承来的资源
retval = flush_old_exec(bprm);
...
current->mm->start_stack = bprm->p;
}
在清空完父进程继承来的资源后(当然也就使用上了新的 mm_struct 对象),这之后,直接将前面准备的进程栈的地址空间指针设置到了 mm 对象上。这样将来栈就可以被使用了。
4.4 执行 Segment 加载
接下来,加载器会将 ELF 文件中的 LOAD 类型的 Segment 都加载到内存里来。使用 elf_map 在虚拟地址空间中为其分配虚拟内存。最后合适地设置虚拟地址空间 mm_struct 中的 start_code、end_code、start_data、end_data 等各个地址空间相关指针。
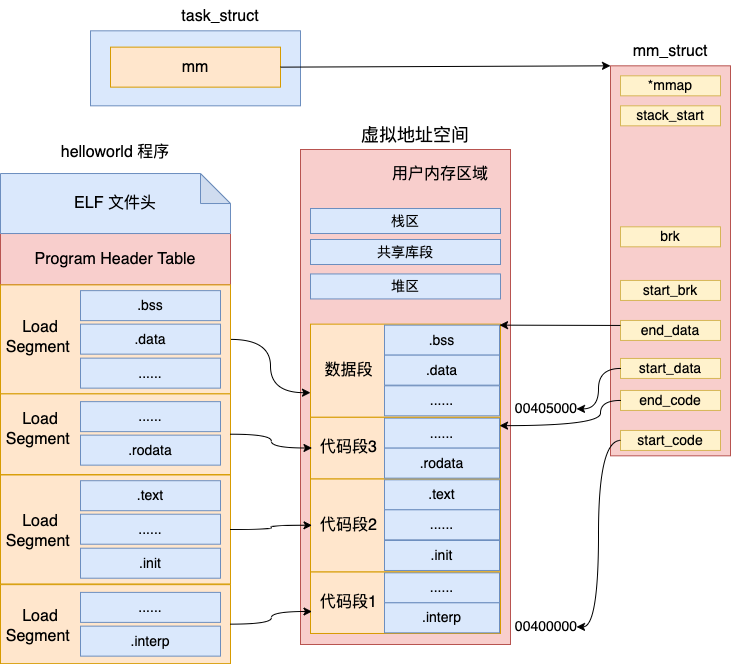
我们来看下具体的代码:
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//4.2 Program Header 读取
//4.3 清空父进程继承来的资源
//4.4 执行 Segment 加载过程
//遍历可执行文件的 Program Header
for(i = 0, elf_ppnt = elf_phdata;
i < loc->elf_ex.e_phnum; i++, elf_ppnt++) {
//只加载类型为 LOAD 的 Segment,否则跳过
if (elf_ppnt->p_type != PT_LOAD)
continue;
...
//为 Segment 建立内存 mmap, 将程序文件中的内容映射到虚拟内存空间中
//这样将来程序中的代码、数据就都可以被访问了
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, 0);
//计算 mm_struct 所需要的各个成员地址
start_code = ...;
start_data = ...
end_code = ...;
end_data = ...;
...
}
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
...
}
其中 load_bias 是 Segment 要加载到内存里的基地址。这个参数有这么几种可能
-
值为 0,就是直接按照 ELF 文件中的地址在内存中进行映射 -
值为对齐到整数页的开始,物理文件中可能为了可执行文件的大小足够紧凑,而不考虑对齐的问题。但是操作系统在加载的时候为了运行效率,需要将 Segment 加载到整数页的开始位置处。
4.5 数据内存申请&堆初始化
因为进程的数据段需要写权限,所以需要使用 set_brk 系统调用专门为数据段申请虚拟内存。
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//4.2 Program Header 读取
//4.3 清空父进程继承来的资源
//4.4 执行 Segment 加载过程
//4.5 数据内存申请&堆初始化
retval = set_brk(elf_bss, elf_brk);
......
}
在 set_brk 函数中做了两件事情:第一是为数据段申请虚拟内存,第二是将进程堆的开始指针和结束指针初始化一下。
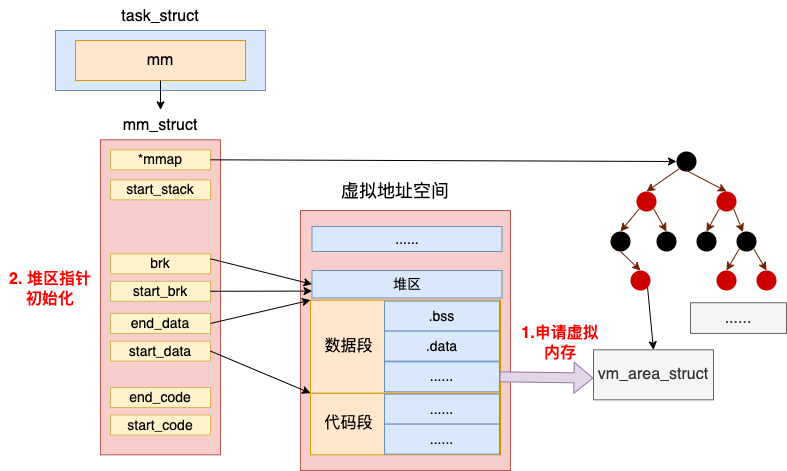
//file:fs/binfmt_elf.c
static int set_brk(unsigned long start, unsigned long end)
{
//1.为数据段申请虚拟内存
start = ELF_PAGEALIGN(start);
end = ELF_PAGEALIGN(end);
if (end > start) {
unsigned long addr;
addr = vm_brk(start, end - start);
}
//2.初始化堆的指针
current->mm->start_brk = current->mm->brk = end;
return 0;
}
因为程序初始化的时候,堆上还是空的。所以堆指针初始化的时候,堆的开始地址 start_brk 和结束地址 brk 都设置成了同一个值。
4.6 跳转到程序入口执行
在 ELF 文件头中记录了程序的入口地址。如果是非动态链接加载的情况,入口地址就是这个。
但是如果是动态链接,也就是说存在 INTERP 类型的 Segment,由这个动态链接器先来加载运行,然后再调回到程序的代码入口地址。
# readelf --program-headers helloworld
......
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
INTERP 0x00000000000002a8 0x00000000004002a8 0x00000000004002a8
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
对于是动态加载器类型的,需要先将动态加载器(本文示例中是 ld-linux-x86-64.so.2 文件)加载到地址空间中来。
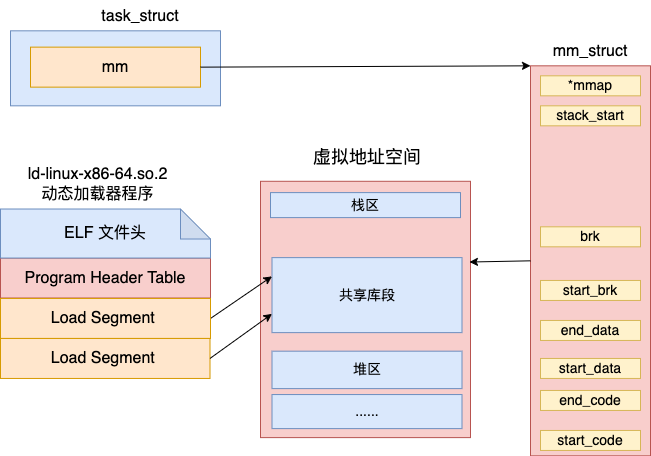
加载完成后再计算动态加载器的入口地址。这段代码我展示在下面了,没有耐心的同学可以跳过。反正只要知道这里是计算了一个程序的入口地址就可以了。
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
//4.1 ELF 文件头解析
//4.2 Program Header 读取
//4.3 清空父进程继承来的资源
//4.4 执行 Segment 加载
//4.5 数据内存申请&堆初始化
//4.6 跳转到程序入口执行
//第一次遍历 program header table
//只针对 PT_INTERP 类型的 segment 做个预处理
//这个 segment 中保存着动态加载器在文件系统中的路径信息
for (i = 0; i < loc->elf_ex.e_phnum; i++) {
...
}
//第二次遍历 program header table, 做些特殊处理
elf_ppnt = elf_phdata;
for (i = 0; i < loc->elf_ex.e_phnum; i++, elf_ppnt++){
...
}
//如果程序中指定了动态链接器,就把动态链接器程序读出来
if (elf_interpreter) {
//加载并返回动态链接器代码段地址
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias);
//计算动态链接器入口地址
elf_entry += loc->interp_elf_ex.e_entry;
} else {
elf_entry = loc->elf_ex.e_entry;
}
//跳转到入口开始执行
start_thread(regs, elf_entry, bprm->p);
...
}
五、总结
看起来简简单单的一行 helloworld 代码,但是要想把它运行过程理解清楚可却需要非常深厚的内功的。
本文首先带领大家认识和理解了二进制可运行 ELF 文件格式。在 ELF 文件中是由四部分组成,分别是 ELF 文件头 (ELF header)、Program header table、Section 和 Section header table。
Linux 在初始化的时候,会将所有支持的加载器都注册到一个全局链表中。对于 ELF 文件来说,它的加载器在内核中的定义为 elf_format,其二进制加载入口是 load_elf_binary 函数。
一般来说 shell 进程是通过 fork + execve 来加载并运行新进程的。执行 fork 系统调用的作用是创建一个新进程出来。不过 fork 创建出来的新进程的代码、数据都还是和原来的 shell 进程的内容一模一样。要想实现加载并运行另外一个程序,那还需要使用到 execve 系统调用。
在 execve 系统调用中,首先会申请一个 linux_binprm 对象。在初始化 linux_binprm 的过程中,会申请一个全新的 mm_struct 对象,准备留着给新进程使用。还会给新进程的栈准备一页(4KB)的虚拟内存。还会读取可执行文件的前 128 字节。
接下来就是调用 ELF 加载器的 load_elf_binary 函数进行实际的加载。大致会执行如下几个步骤:
-
ELF 文件头解析 -
Program Header 读取 -
清空父进程继承来的资源,使用新的 mm_struct 以及新的栈 -
执行 Segment 加载,将 ELF 文件中的 LOAD 类型的 Segment 都加载到虚拟内存中 -
为数据 Segment 申请内存,并将堆的起始指针进行初始化 -
最后计算并跳转到程序入口执行
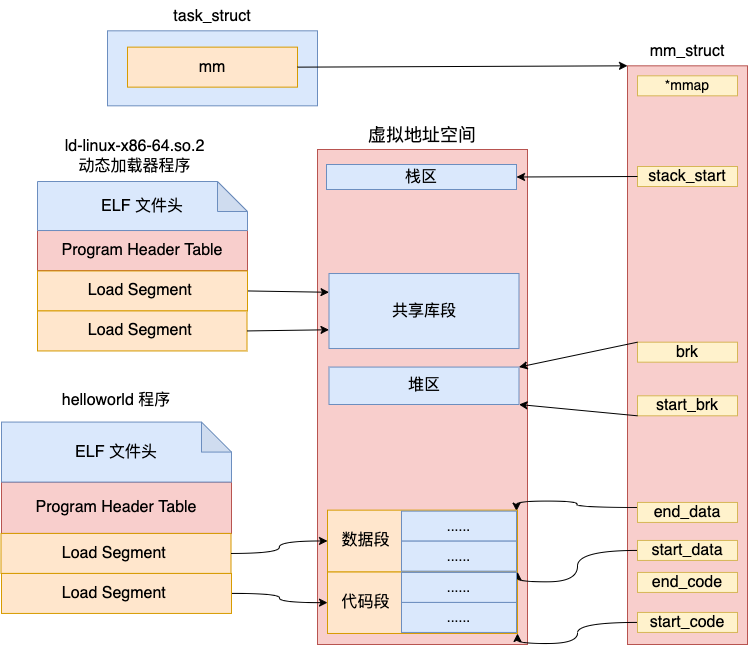
当用户进程启动起来以后,我们可以通过 proc 伪文件来查看进程中的各个 Segment。
# cat /proc/46276/maps
00400000-00401000 r--p 00000000 fd:01 396999 /root/work_temp/helloworld
00401000-00402000 r-xp 00001000 fd:01 396999 /root/work_temp/helloworld
00402000-00403000 r--p 00002000 fd:01 396999 /root/work_temp/helloworld
00403000-00404000 r--p 00002000 fd:01 396999 /root/work_temp/helloworld
00404000-00405000 rw-p 00003000 fd:01 396999 /root/work_temp/helloworld
01dc9000-01dea000 rw-p 00000000 00:00 0 [heap]
7f0122fbf000-7f0122fc1000 rw-p 00000000 00:00 0
7f0122fc1000-7f0122fe7000 r--p 00000000 fd:01 1182071 /usr/lib64/libc-2.32.so
7f0122fe7000-7f0123136000 r-xp 00026000 fd:01 1182071 /usr/lib64/libc-2.32.so
......
7f01231c0000-7f01231c1000 r--p 0002a000 fd:01 1182554 /usr/lib64/ld-2.32.so
7f01231c1000-7f01231c3000 rw-p 0002b000 fd:01 1182554 /usr/lib64/ld-2.32.so
7ffdf0590000-7ffdf05b1000 rw-p 00000000 00:00 0 [stack]
......
虽然本文非常的长,但仍然其实只把大体的加载启动过程串了一下。如果你日后在工作学习中遇到想搞清楚的问题,可以顺着本文的思路去到源码中寻找具体的问题,进而帮助你找到工作中的问题的解。
最后提一下,细心的读者可能发现了,本文的实例中加载新程序运行的过程中其实有一些浪费,fork 系统调用首先将父进程的很多信息拷贝了一遍,而 execve 加载可执行程序的时候又是重新赋值的。所以在实际的 shell 程序中,一般使用的是 vfork。其工作原理基本和 fork 一致,但区别是会少拷贝一些在 execve 系统调用中用不到的信息,进而提高加载性能。

