
如何保证mongodb和数据库双写数据一致性?原创
大家好,我是苏三,又跟大家见面了。
前言
最近在我的技术群里,有位小伙伴问了大家一个问题:如何保证Mongodb和数据库双写的数据一致性?
群友们针对这个技术点讨论的内容,引起了我的兴趣。
其实我在实际工作中的有些业务场景,也在使用Mongodb,也遇到过双写的数据一致性问题。
今天跟大家一起分享一下,这类问题的解决办法,希望对你会有所帮助。
1 常见误区
很多小伙伴看到双写数据一致性问题,首先会想到的是Redis和数据库的数据双写一致性问题。
有些小伙伴认为,Redis和数据库的数据双写一致性问题,跟Mongodb和数据库的数据双写一致性问题,是同一个问题。
但如果你仔细想想它们的使用场景,就会发现有一些差异。
1.1 我们是如何用缓存的?
Redis缓存能提升我们系统的性能。
一般情况下,如果有用户请求过来,先查缓存,如果缓存中存在数据,则直接返回。如果缓存中不存在,则再查数据库,如果数据库中存在,则将数据放入缓存,然后返回。如果数据库中也不存在,则直接返回失败。
流程图如下: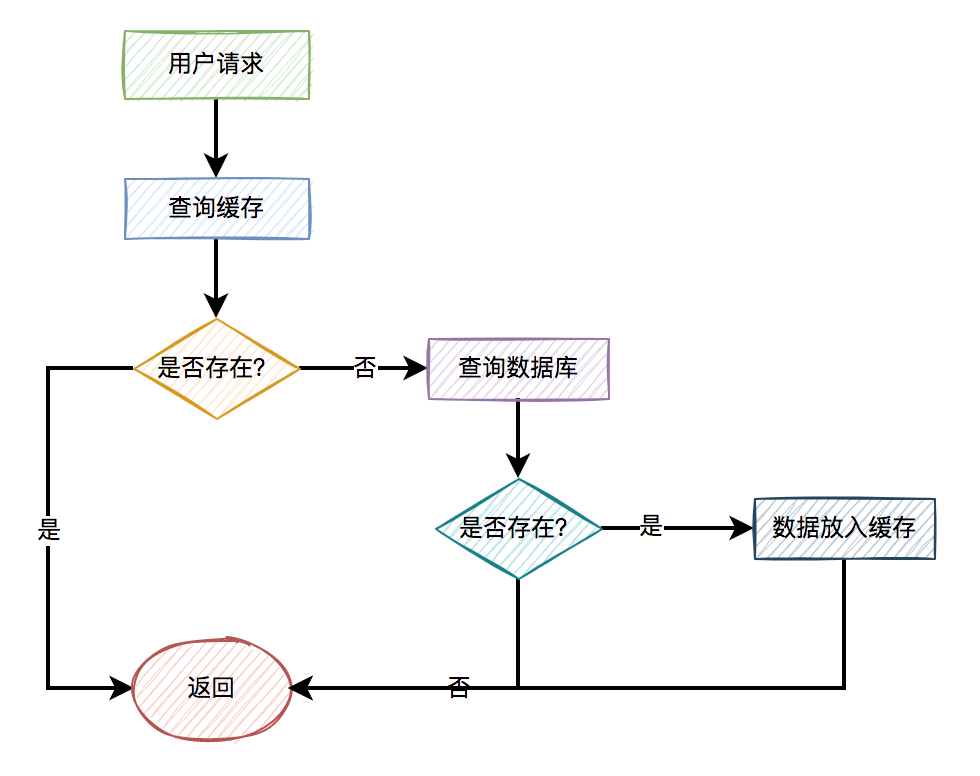
通常情况下,保证缓存和数据双写数据一致性,最常用的技术方案是:延迟双删。
感兴趣的小伙伴,可以看看我的另一篇文章《如何保证数据库和缓存双写一致性?》,里面有非常详细的介绍。
1.2 我们是如何用MongoDB的?
MongoDB是一个高可用、分布式的文档数据库,用于大容量数据存储。文档存储一般用类似json的格式存储,存储的内容是文档型的。
通常情况下,我们用来存储大数据或者json格式的数据。
用户写数据的请求,核心数据会被写入数据库,json格式的非核心数据,可能会写入MongoDB。
流程图如下: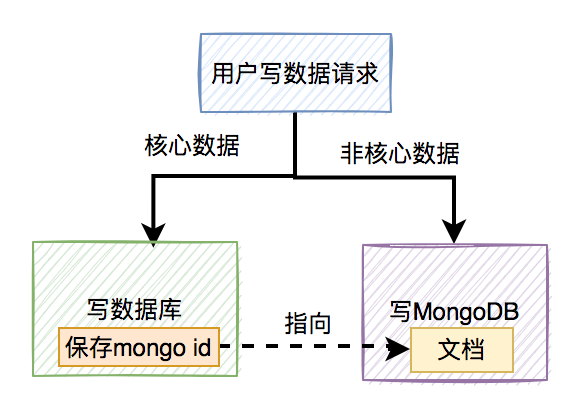
用户读数据的请求,会先读数据库中的数据,然后通过文档的id,读取MongoDB中的数据。
流程图如下: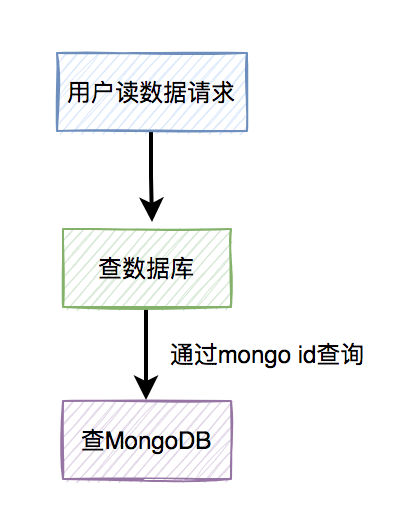
Redis和MongoDB在我们实际工作中的用途不一样,导致了它们双写数据一致性问题的解决方案是不一样的。
接下来我们一起看看,如何保证MongoDB和数据库的双写的数据一致性?
2 如何保证双写一致性?
目前双写MongoDB和数据库的数据,用的最多的就是下面这两种方案。
2.1 先写数据库,再写MongoDB
该方案最简单,先在数据库中写入核心数据,再在MongoDB中写入非核心数据。
流程图如下: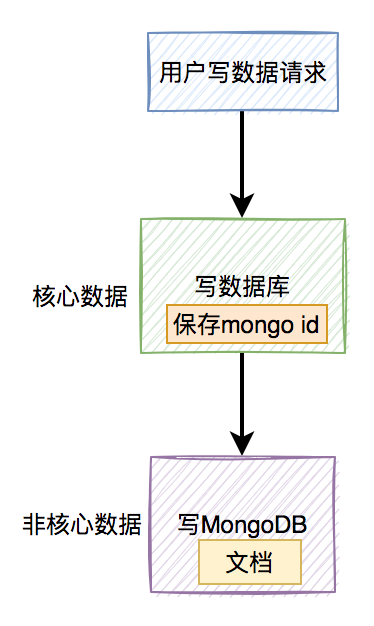
但如果有些业务场景,对数据完整性要求比较高,用这套方案可能会有问题。
当数据库刚保存了核心数据,此时网络出现异常,程序保存MongoDB的非核心数据时失败了。
但MongoDB并没有抛出异常,数据库中已经保存的数据没法回滚,这样会出现数据库中保存了数据,而MongoDB中没保存数据的情况,从而导致MongoDB中的非核心数据丢失的问题。
所以这套方案,在实际工作中使用不多。
2.2 先写MongoDB,再写数据库
在该方案中,先在MongoDB中写入非核心数据,再在数据库中写入核心数据。
流程图如下: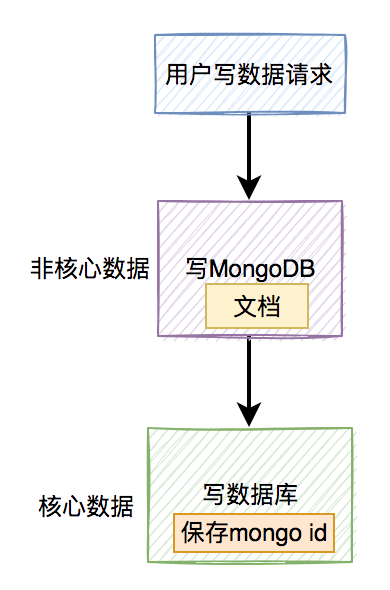
这时候MongoDB中非核心数据不会回滚,可能存在MongoDB中保存了数据,而数据库中没保存数据的问题,同样会出现数据不一致的问题。
答:我们忘了一个前提,查询MongoDB文档中的数据,必须通过数据库的表中保存的mongo id。但如果这个mongo id在数据库中都没有保存成功,那么,在MongoDB文档中的数据是永远都查询不到的。
也就是说,这种情况下MongoDB文档中保存的是垃圾数据,但对实际业务并没有影响。
这套方案可以解决双写数据一致性问题,但它同时也带来了两个新问题:
-
用户修改操作如何保存数据? -
如何清理垃圾数据?
3 用户修改操作如何保存数据?
我之前聊的先写MongoDB,再写数据库,这套方案中的流程图,其实主要说的是新增数据的场景。
但如果在用户修改数据的操作中,用户先修改MongoDB文档中的数据,再修改数据库表中的数据。
流程图如下: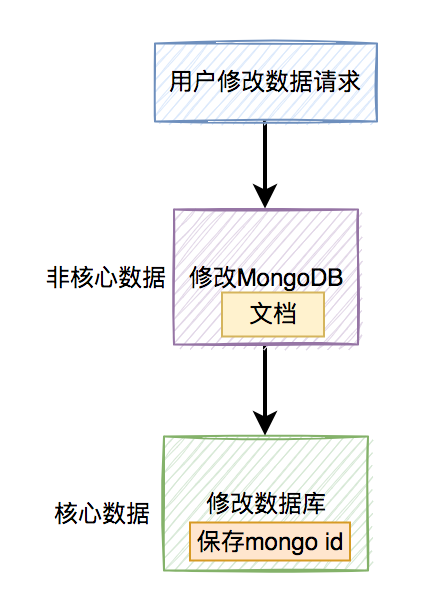
那么,用户修改操作时如何保存数据呢?
这就需要把流程调整一下,在修改MongoDB文档时,还是新增一条数据,不直接修改,生成一个新的mongo id。然后在修改数据库表中的数据时,同时更新mongo id字段为这个新值。
流程图如下: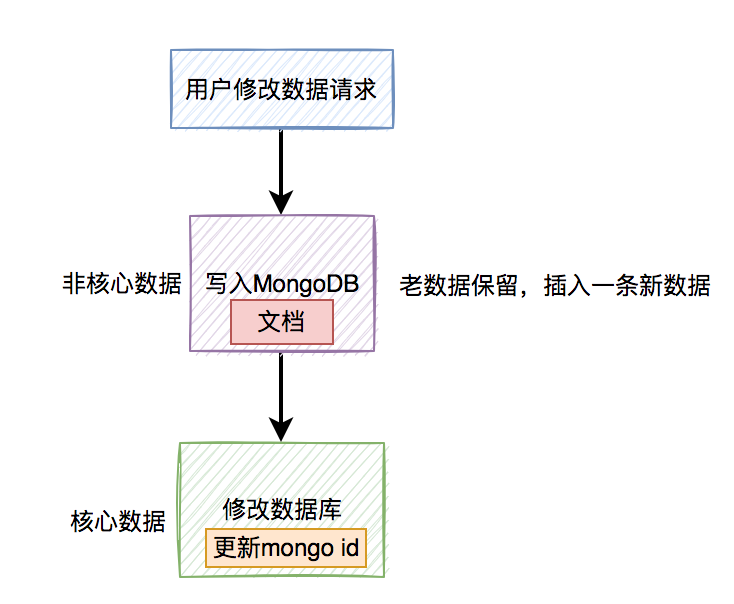
使用该方案能够解决修改数据时,数据一致性问题,但同样会存在垃圾数据。
其实这个垃圾数据是可以即使删除的,具体流程图如下: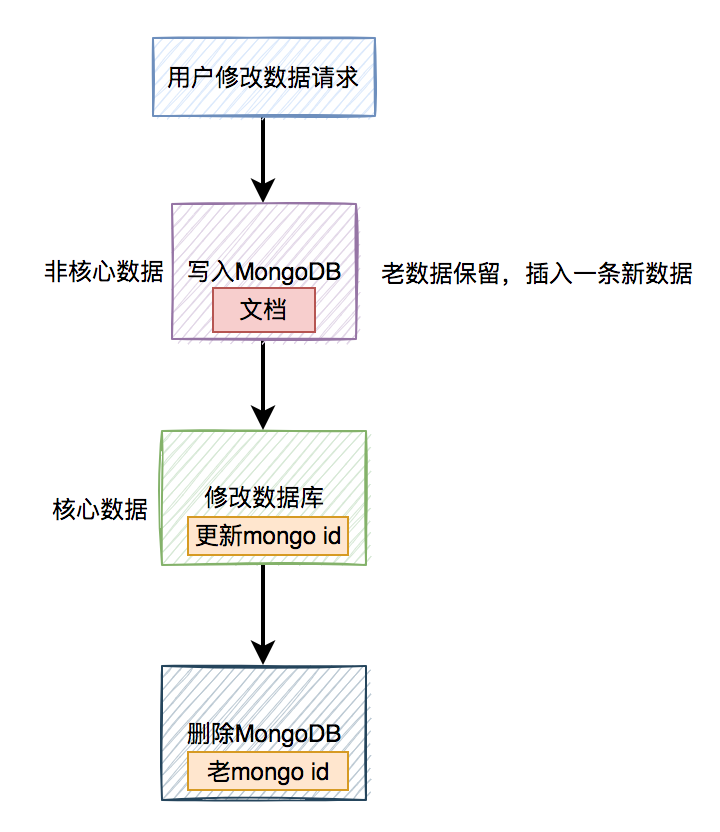
该方案可以解决用户修改操作中,99%的的垃圾数据,但还有那1%的情况,即如果最后删除失败该怎么办?
答:这就需要加重试机制了。
我们可以使用job或者mq进行重试,优先推荐使用mq增加重试功能。特别是想RocketMQ,自带了失败重试机制,有专门的重试队列,我们可以设置重试次数。
流程图优化如下: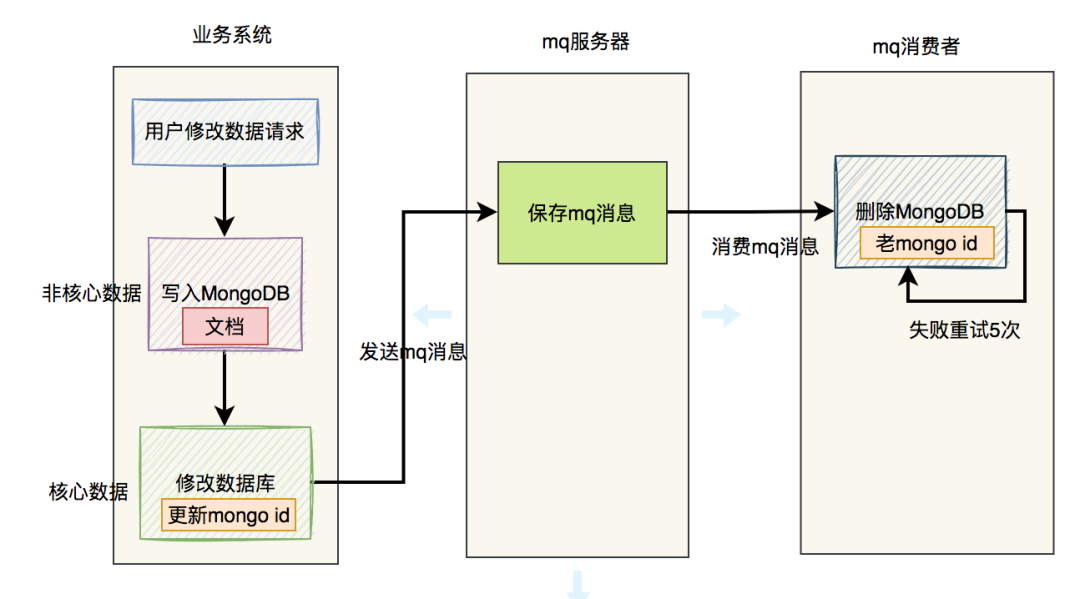
死信队列中。
然后专门有个程序监控死信队列中的数据,如果发现有数据,则发报警邮件。
这样基本可以解决修改删除垃圾数据失败的问题。
4 如何清理新增的垃圾数据?
还有一种垃圾数据还没处理,即在用户新增数据时,如果写入MongoDB文档成功了,但写入数据库表失败了。由于MongoDB不会回滚数据,这时候MongoDB文档就保存了垃圾数据,那么这种数据该如何清理呢?
4.1 定时删除
我们可以使用job定时扫描,比如:每天扫描一次MongoDB文档,将mongo id取出来,到数据库查询数据,如果能查出数据,则保留MongoDB文档中的数据。
如果在数据库中该mongo id不存在,则删除MongoDB文档中的数据。
如果MongoDB文档中的数据量不多,是可以这样处理的。但如果数据量太大,这样处理会有性能问题。
这就需要做优化,常见的做法是:缩小扫描数据的范围。
比如:扫描MongoDB文档数据时,根据创建时间,只查最近24小时的数据,查出来之后,用mongo id去数据库查询数据。
如果直接查最近24小时的数据,会有问题,会把刚写入MongoDB文档,但还没来得及写入数据库的数据也查出来,这种数据可能会被误删。
可以把时间再整体提前一小时,例如:
in_time < 当前时间-1 and in_time >= 当前时间-25
获取25小时前到1小时前的数据。
这样可以解决大部分系统中,因为数据量过多,在一个定时任务的执行周期内,job处理不完的问题。
但如果根据时间缩小范围之后,数据量还是太大,job还是处理不完该怎么办?
答:我们可以在job用多线程删除数据。
当然我们还可以将job的执行时间缩短,根据实际情况而定,比如每隔12小时,查询创建时间是13小时前到1小时前的数据。
或者每隔6小时,查询创建时间是7小时前到1小时前的数据。
或者每隔1小时,查询创建时间是2小时前到1小时前的数据等等。
4.2 随机删除
其实删除垃圾数据还有另外一种思路。
不知道你了解过Redis删除数据的策略吗?它在处理大批量数据时,为了防止使用过多的CPU资源,用了一种随机删除的策略。
我们在这里可以借鉴一下。
有另外一个job,每隔500ms随机获取10条数据进行批量处理,当然获取的数据也是根据时间缩小范围的。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,请一键三连:点赞、转发、评论~
关注公众号:【苏三说技术】,在公众号中回复:面试、代码神器、开发手册、时间管理有超赞的粉丝福利

