
SQL性能分析原创
监控有个全局监控的概念,通过全局监控能够知道目前集群或服务器的好坏情况,有了全局监控,再去考虑定点监控,对造成性能下降的具体原因进行分析,有可能是慢查询,也有可能是磁盘问题。
全局监控分为两大类:指标信息和日志信息,
指标信息
指标信息是指普通服务器上面所监控到的一些硬件指标:cpu、内存、磁盘的iops,针对mysql数据库而言,还有buffer pool(缓存命令率)、脏页的比率(比率过高,mysql数据库在更新或插入操作的时候效率可能会大打折扣,因为mysql数据库在进行插入或更新的时候,有一个刷脏页的操作,如果脏页过大的话,刷脏页所消耗的时间就会过长,就会降低插入或更新语句的性能)
日志信息
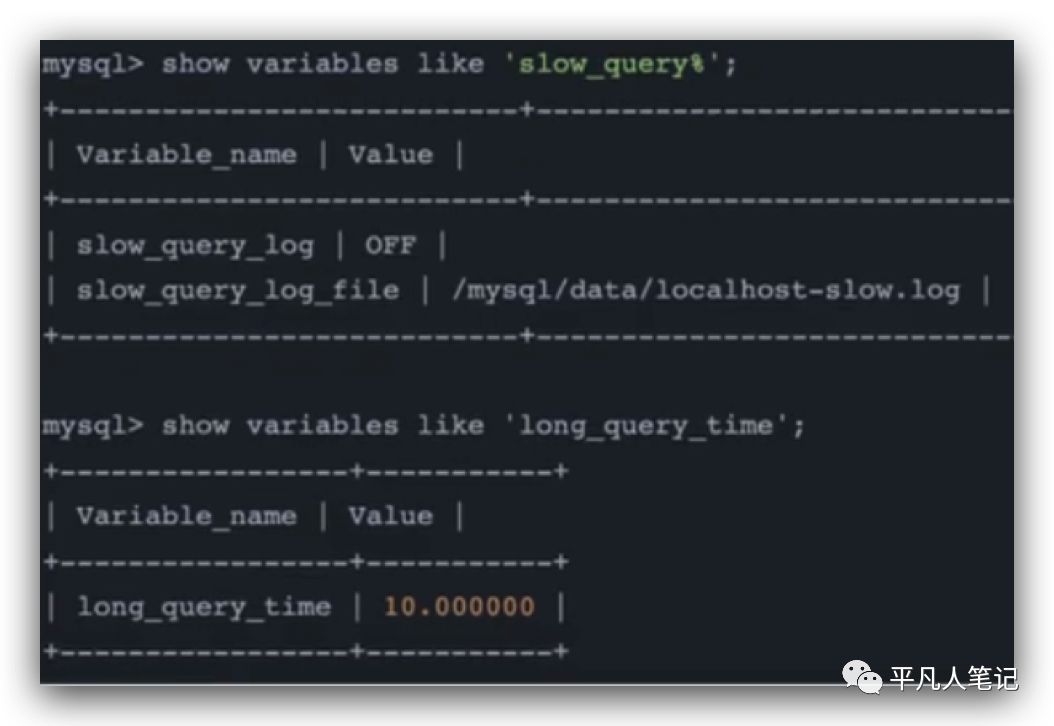
# 慢查询日志是否开启、慢查询日志路径、慢查询时间
show variables like 'show_query%';
show variables like 'long_query_time';
查看最近一次死锁的日志,
show engine innodb status;
如果想把所有的死锁日志保存下来,
show variables like 'innodb_print_all_deadlocks';
可以修改这个环境变量,把值设置为1之后,每次发生死锁之后,系统就会将死锁的信息输入到错误日志中。
死锁日志的分析
死锁是两个事务都持有对方锁,等待锁造成的。
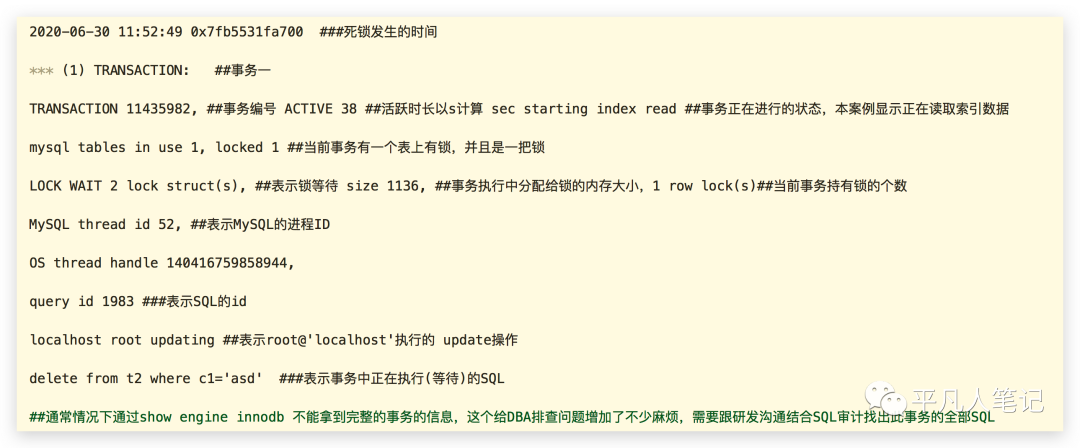
首先能够看到的是死锁发生的具体时间;(1)代表事务1,(2)代表事务2;事务1所在的表持有一把锁,着重看事务1所执行的sql语句(delete语句)。
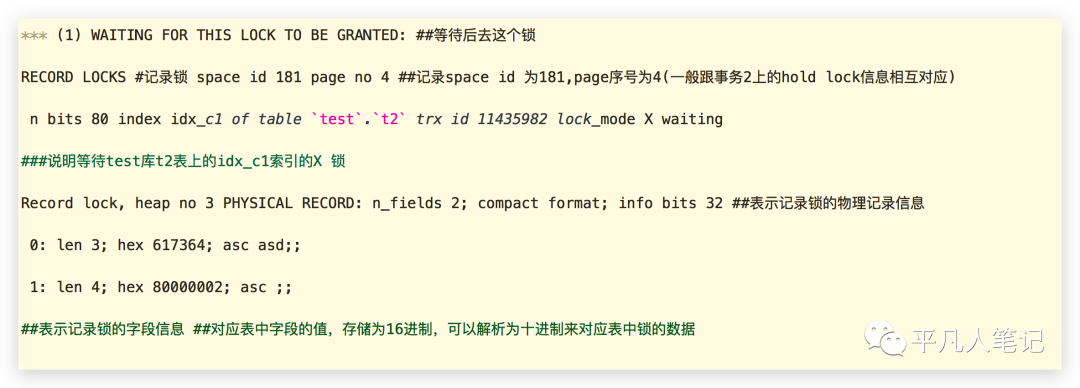
事务1等待这个锁,当其他事务解锁之后,事务1会得到这个记录锁。
在mysql中有记录锁和表锁的概念,记录锁在idx_c1这个索引上。表名也列出来了,锁的模式是X锁(写锁),
对数据库进行修改、增加、删除的操作,都会加上写锁。
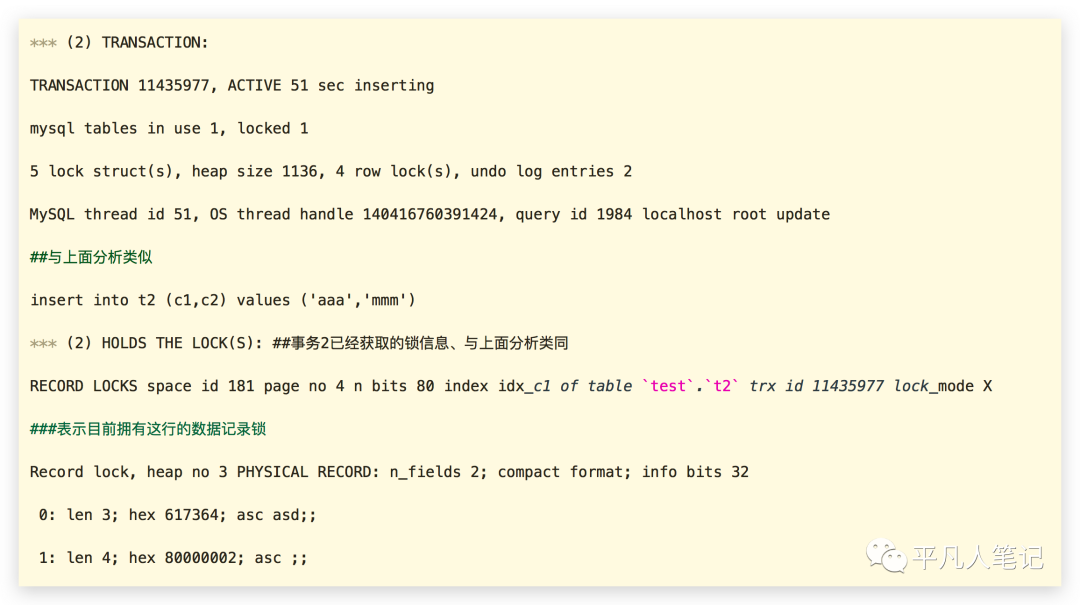
事务2也着重看下插入语句,能够看到它持有的锁,也是记录锁,在idx_c1上面同样是一个写锁,
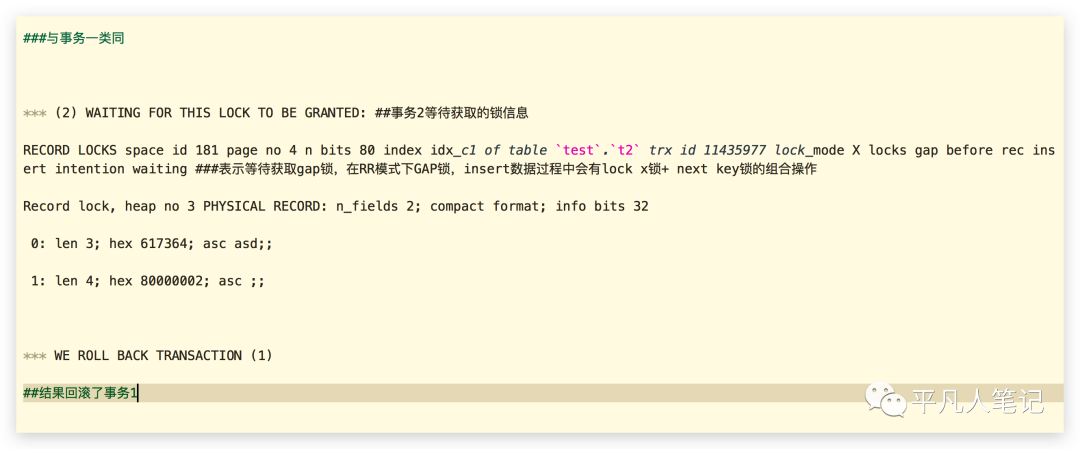
事务2等待的是事务1锁(gap间隙锁)持有的记录。
一般拿到死锁日志之后,还要根据具体的业务代码进行分析,去调整执行sql语句的顺序来规避这种情况。
错误日志
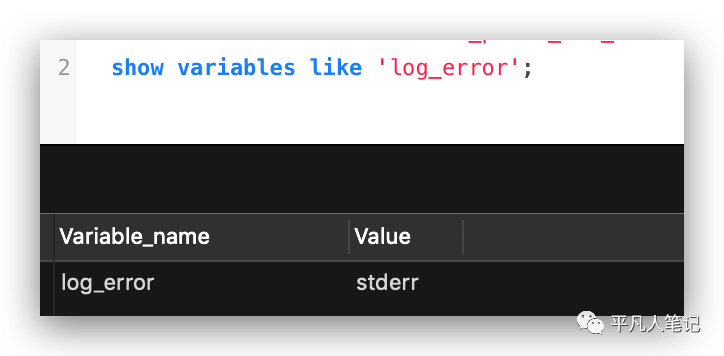
show variables like 'log_error';
系统日志
dmesg
or
/var/log/message
通过log_error变量看下错误日志是存在哪个文件,除了mysql自身提供的日志,还能去系统上面看系统日志。
有了这种全局监控,我们再具体分析一下 线上出现问题的时候该如何排查。
查看当前进程执行情况
show full processlist;
or
select id,db,user,host,command,time,state,info from information_schema.processlist where command != 'Sleep' order by time desc;
- id 表示进程id ,可以用kill id杀死一个进程
- db 数据库
- user 用户
- host 连接主机的ip
- commnad 当前执行的命令,比如常见的 Sleep、Query、Connect等
- time 消耗时间,单位秒
- state 执行状态 比如 Sending data、Sorting for group、Create tmp table、Locked等
- info 执行的SQL语句
比如mysql数据库出现了大量的超时的情况,可能是由于大事务造成的,大事务拥有大量的资源会导致其他sql的执行效率下降,通过show full processlist找到耗时比较严重的事务,kill掉这个事务。可能数据库就会马上恢复正常,这个也是紧急解决mysql数据库性能下降的一个手段。
performance_schema
通过mysql提供的performance_schema,开启这个配置会有10%的性能损耗,但还好,因为通过监控对mysql进行分析,从而发现程序设计上不合理的地方,不应该把更多的压力放在数据库层,相比发现mysql性能问题发现程序设计问题会更加重要一些。
show variables like 'performance_schema';
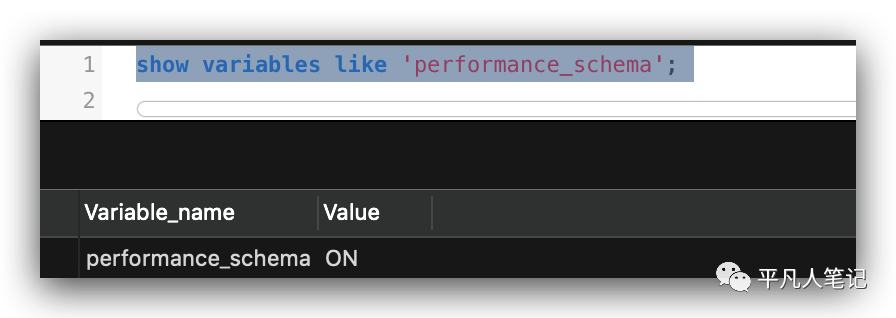
开启这个环境变量,在启动时生效,如果mysql正在运行,这个时候去开启这个变量,不会生效。
查看当前事务锁等待
select * from sys.innodb_lock_waits \G;
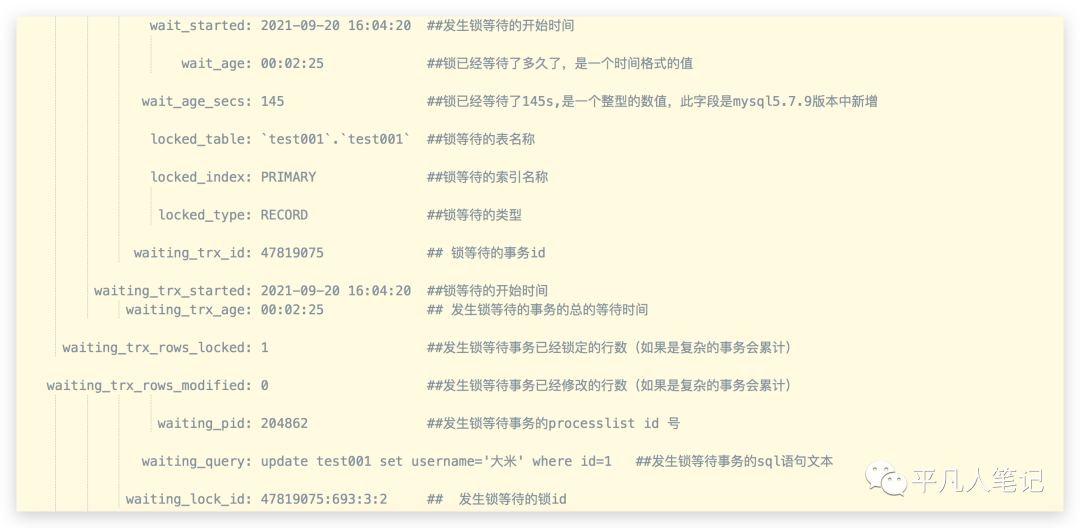
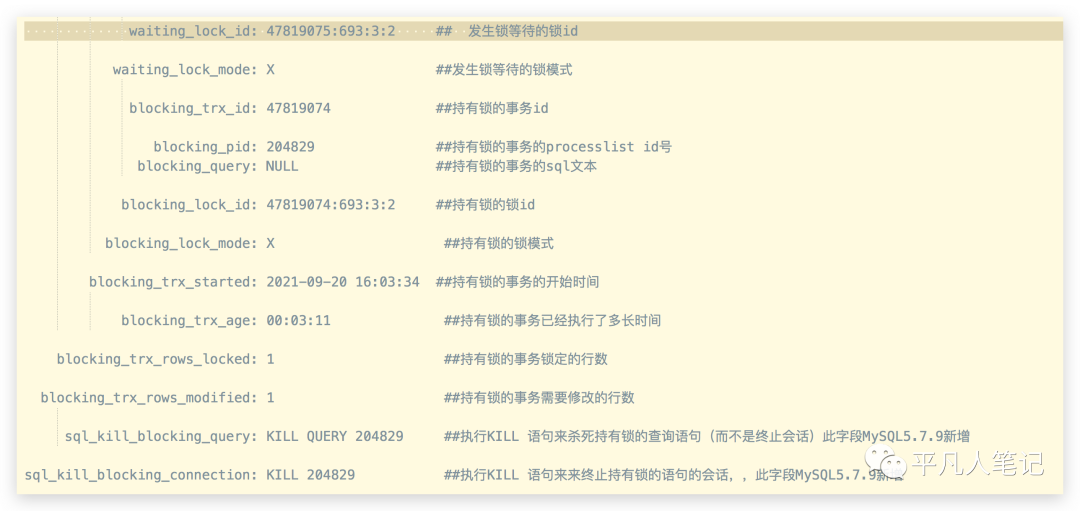
通过这个变量能够去看当前事务锁等待的情况,能够把执行sql等待时长按照从大到小排列,甚至把kill命令也列了出来,通过kill命令可以杀掉这种锁等待较长的sql。
查看MDL锁等待
MDL锁是元数据锁 ,元数据是描述表结构的一些数据,当我们进行dml(update或insert)语句与ddl语句(比如修改列名)操作同一个元数据的时候,就会上MDL锁。
使用了文件索引的sql
# 查看哪些sql使用了文件索引
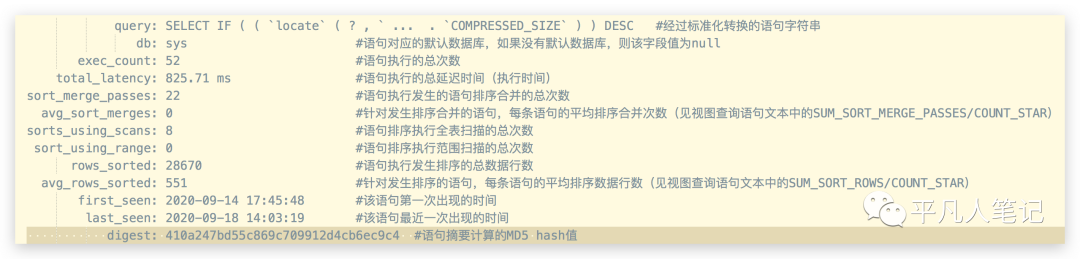
select * from sys.statements_with_sorting;
可以看到更加详细的信息,像全表扫描的次数、范围扫描总次数。
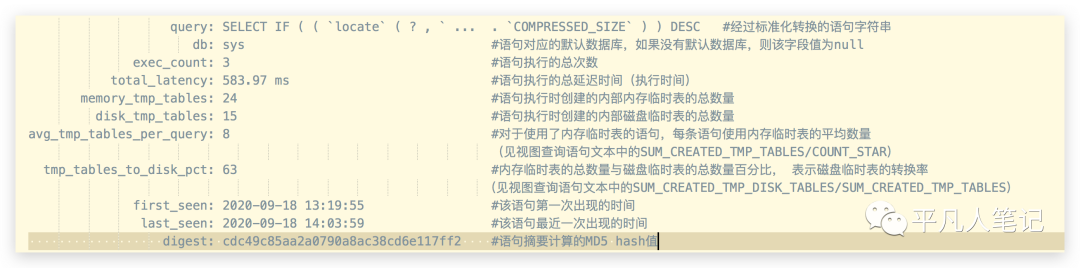
哪些sql使用了临时表
select * from sys.statements_with_temp_tables limit 1;
explain
当发现这些sql出现问题或者出现慢查询sql之后,可以通过explain对慢查询sql进行分析,看下究竟使用了哪些索引或者有没有使用临时表和文件排序这种耗性能的操作,一般情况下,临时表和排序操作都是应该避免的。

字段含义:
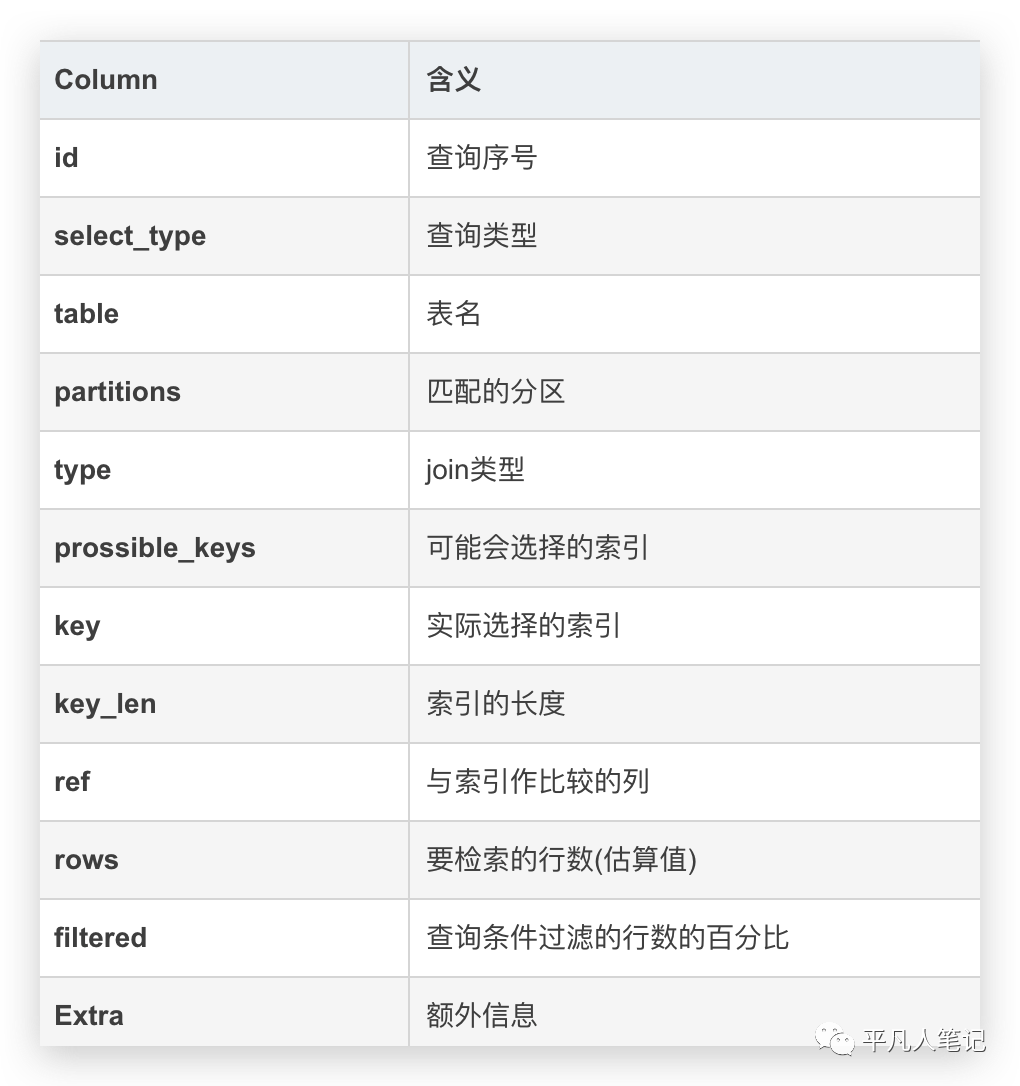
type类型:

扫描方式由快到慢 :system > const > eq_ref > ref > range > index > ALL。
explain的局限性
执行计划预估语句使用到了索引possible_keys,但是数据库最终执行的时候,查询哪些数据,通过explain是不能分析出来的,并且explain不能看各个阶段的耗时情况。
mysql中有两种方式解决这个问题,
开启mysql的trace分析,开启之后,可以看到这个sql的索引是如何被选择的,并且最终选择的哪条索引。
调大trace的容量
set session optimizer_trace_max_mem_size=10485760;
开启optimizer_trace
set session optimizer_trace="enabled=on"
查看trace
select trace from information_schema.optimizer_trace
通过trace分析能够完全明白sql执行过程的路径是怎样的,从这个表可以看到执行过的sql trace命令。
show profiles
看sql执行的耗时,当sql执行耗时过长的时候,通过explain分析它使用了什么样的索引,可能并没有办法知道它耗时最长的地方在哪里,这时候用profile可以很好的解决这个问题。
show VARIABLES like '%profil%'
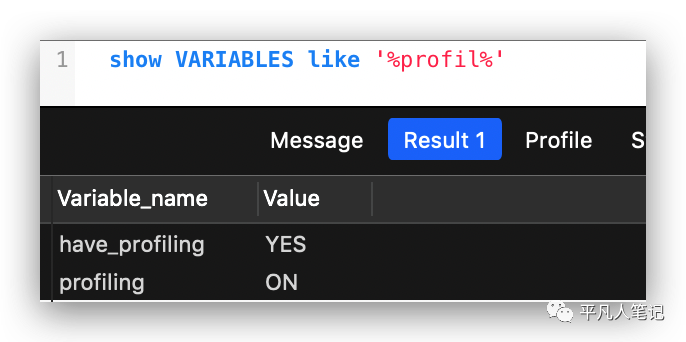
开启会话级别的profile
set profiling=1;
查看当前session所有已经产生的profile
show PROFILES;
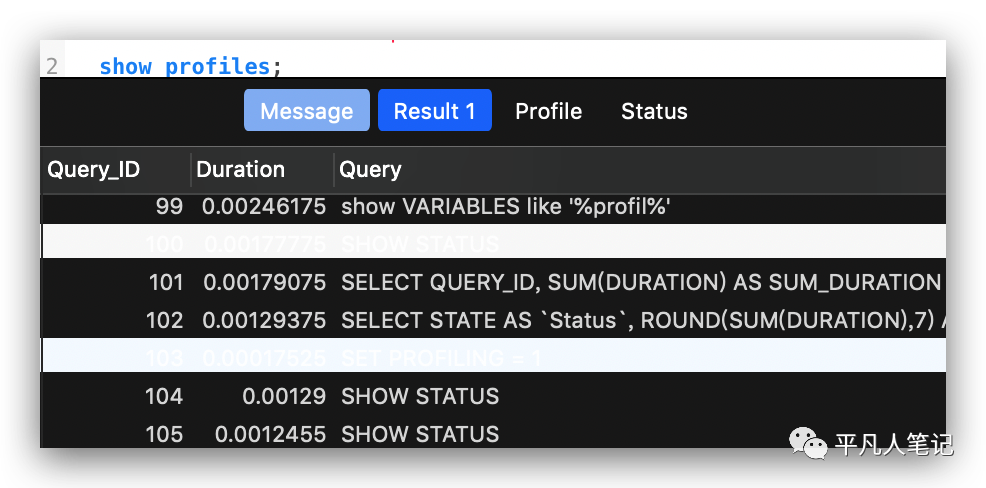
可以看到所有产生的profile。
展示特定查询的profile,
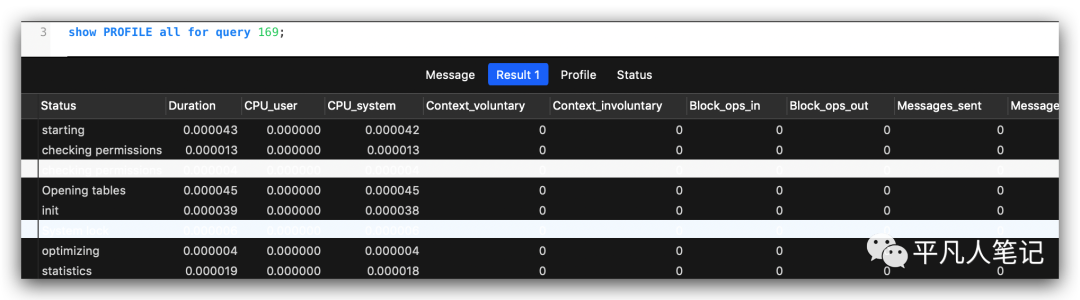
可以看到具体queryid的耗时情况。
把整个sql分成很多个阶段,每个阶段的耗时情况包括cpu的使用率、上下文的切换次数等都可以看到。
当发现一条sql执行很慢的时候,除了通过explain还能通过show profile去真正的看到底sql慢在了哪里。


