
【译】SQL递归与CTE查询的原理和应用转载
介绍
在本文中,我们将了解 SQL Recursive WITH CTE(公用表表达式)查询的工作原理,以及我们如何应用它们来处理分层数据模型。
SQL的WITH 子句
在 SQL 中,WITH子句允许我们定义公用表表达式或 CTE来为临时查询结果集分配别名。
虽然我们可以使用 WITH 子句作为派生表或内联视图的替代方法,但 WITH 子句允许我们以递归方式构建结果集。
连续和
要了解 Recursive WITH 查询的工作原理,请考虑以下计算连续总和直到给定阈值的示例:
WITH RECURSIVE consecutive_number_sum (i, consecutive_sum) AS (
SELECT 0, 0
UNION ALL
SELECT i + 1, (i + 1) + consecutive_sum
FROM consecutive_number_sum
WHERE i < 5
)
SELECT i, consecutive_sum
FROM consecutive_number_sum
如果你使用的是 Oracle 或 SQL Server,请注意该
RECURSIVE关键字不受支持,因此你需要在编写递归 CTE 查询时省略它。
运行上面的递归 CTE 查询时,我们得到以下结果集:
| i | consecutive_sum ||---|-----------------|| 0 | 0 || 1 | 1 || 2 | 3 || 3 | 6 || 4 | 10 || 5 | 15 | |
那么它是怎样工作的?
第一行定义了递归 CTE 的名称和这个临时结果集的列,i在consecutive_sum我们的例子中:
WITH RECURSIVE consecutive_number_sum (i, consecutive_sum) AS (
SELECT 0, 0
UNION ALL
SELECT i + 1, (i + 1) + consecutive_sum
FROM consecutive_number_sum
WHERE i < 5
)
SELECT i, consecutive_sum
FROM consecutive_number_sum
第二行定义了递归 CTE 的锚点成员:
WITH RECURSIVE consecutive_number_sum (i, consecutive_sum) AS (
SELECT 0, 0
UNION ALL
SELECT i + 1, (i + 1) + consecutive_sum
FROM consecutive_number_sum
WHERE i < 5
)
SELECT i, consecutive_sum
FROM consecutive_number_sum
锚点成员负责产生递归 CTE 结果集的第一条记录:
| i | consecutive_sum ||---|-----------------|| 0 | 0 || 1 | 1 || 2 | 3 || 3 | 6 || 4 | 10 || 5 | 15 | |
使用UNION ALL运算符是因为我们需要使用关系代数来模拟递归。事实上,递归 CTE 结果集是迭代构建的,类似于过程编程语言中的 while 循环:
WITH RECURSIVE consecutive_number_sum (i, consecutive_sum) AS (
SELECT 0, 0
UNION ALL
SELECT i + 1, (i + 1) + consecutive_sum
FROM consecutive_number_sum
WHERE i < 5
)
SELECT i, consecutive_sum
FROM consecutive_number_sum
第 4 到 6 行定义递归成员,它是一个 SQL 查询,提供要在每次迭代中添加的记录。
WITH RECURSIVE consecutive_number_sum (i, consecutive_sum) AS (
SELECT 0, 0
UNION ALL
SELECT i + 1, (i + 1) + consecutive_sum
FROM consecutive_number_sum
WHERE i < 5
)
SELECT i, consecutive_sum
FROM consecutive_number_sum
因为FROM递归成员的子句是递归 CTE 本身,这意味着我们将在每次迭代时传递先前生成的记录。
第一次执行递归成员时,i和consecutive_sum列的值为 ,0因为它们是由锚成员提供的,并且第一次递归迭代产生的记录将是:
| i | consecutive_sum ||---|-----------------|| 0 | 0 || 1 | 1 || 2 | 3 || 3 | 6 || 4 | 10 || 5 | 15 | |
对于递归成员的第二次迭代,产生的值i将是1 + 1,并且consecutive_sum将是(1 + 1) + 1:
| i | consecutive_sum ||---|-----------------|| 0 | 0 || 1 | 1 || 2 | 3 || 3 | 6 || 4 | 10 || 5 | 15 | |
递归成员查询一直执行到给定迭代没有生成任何记录为止,这在 的值i变为时发生5。
分层数据模型
假设我们有下post_comment表:
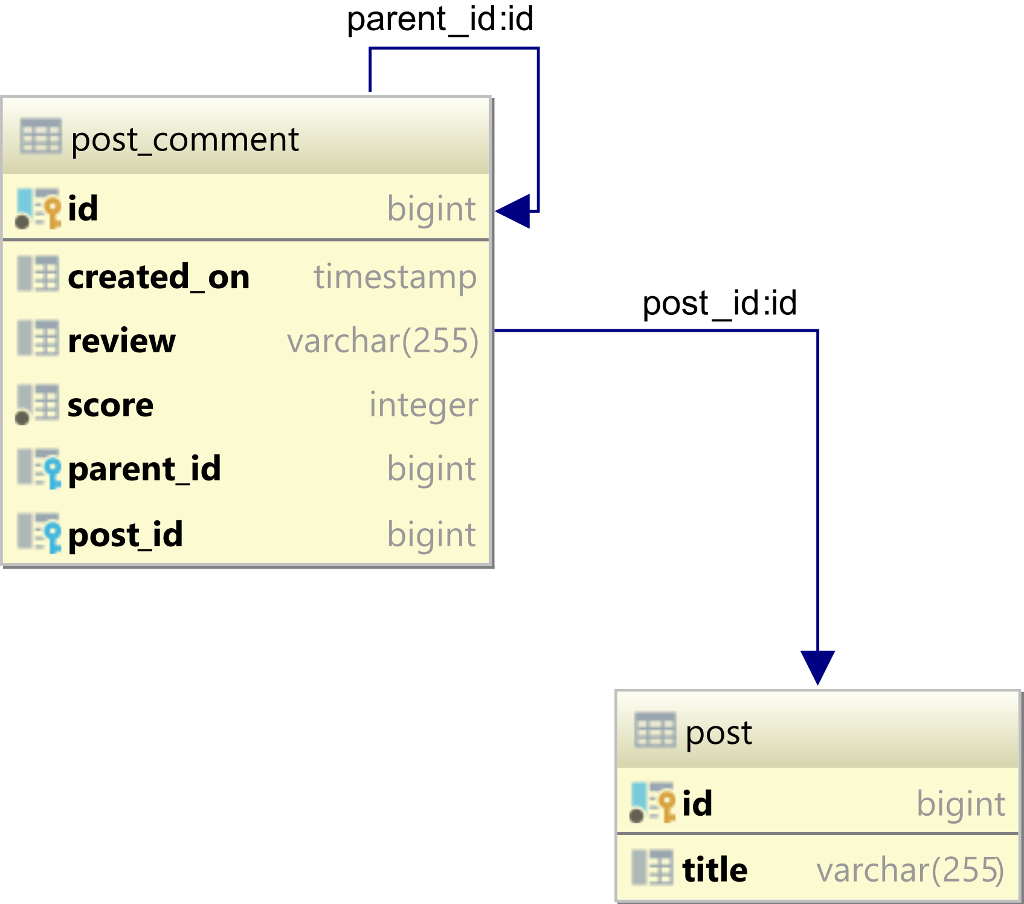
表中的parent_id列post_comment引用id同一个表中的列。所以,我们可以利用parent_id栏目来构建层次化的评论结构。
该post_comment表包含以下数据:
| id | parent_id | review | created_on | score ||----|-----------|---------------|---------------------|-------|| 1 | | Comment 1 | 2019-10-13 12:23:05 | 1 || 2 | 1 | Comment 1.1 | 2019-10-14 13:23:10 | 2 || 3 | 1 | Comment 1.2 | 2019-10-14 15:45:15 | 2 || 4 | 3 | Comment 1.2.1 | 2019-10-15 10:15:20 | 1 || 5 | | Comment 2 | 2019-10-13 15:23:25 | 1 || 6 | 5 | Comment 2.1 | 2019-10-14 11:23:30 | 1 || 7 | 5 | Comment 2.2 | 2019-10-14 14:45:35 | 1 || 8 | | Comment 3 | 2019-10-15 10:15:40 | 1 || 9 | 8 | Comment 3.1 | 2019-10-16 11:15:45 | 10 || 10 | 8 | Comment 3.2 | 2019-10-17 18:30:50 | -2 || 11 | | Comment 4 | 2019-10-19 21:43:55 | -5 || 12 | | Comment 5 | 2019-10-22 23:45:00 | 0 | |
我们现在要计算每个评论层次结构的总分。为此,我们需要一个列来定义给定层次结构root_id的最顶层标识符:post_comment
| id | parent_id | review | created_on | score | root_id ||----|-----------|---------------|---------------------|-------|---------|| 1 | | Comment 1 | 2019-10-13 12:23:05 | 1 | 1 || 2 | 1 | Comment 1.1 | 2019-10-14 13:23:10 | 2 | 1 || 3 | 1 | Comment 1.2 | 2019-10-14 15:45:15 | 2 | 1 || 4 | 3 | Comment 1.2.1 | 2019-10-15 10:15:20 | 1 | 1 || 5 | | Comment 2 | 2019-10-13 15:23:25 | 1 | 5 || 6 | 5 | Comment 2.1 | 2019-10-14 11:23:30 | 1 | 5 || 7 | 5 | Comment 2.2 | 2019-10-14 14:45:35 | 1 | 5 || 8 | | Comment 3 | 2019-10-15 10:15:40 | 1 | 8 || 9 | 8 | Comment 3.1 | 2019-10-16 11:15:45 | 10 | 8 || 10 | 8 | Comment 3.2 | 2019-10-17 18:30:50 | -2 | 8 || 11 | | Comment 4 | 2019-10-19 21:43:55 | -5 | 11 || 12 | | Comment 5 | 2019-10-22 23:45:00 | 0 | 12 | |
因为我们不应该创建可以简单地使用 SQL 派生的列,所以我们将root_id使用以下递归 WITH 公用表表达式 (CTE) 查询生成列:
WITH RECURSIVE post_comment_score(
id, root_id, post_id, parent_id, review, created_on, score) AS (
SELECT id, id, post_id, parent_id, review, created_on, score
FROM post_comment
WHERE post_id = 1 AND parent_id IS NULL
UNION ALL
SELECT pc.id, pcs.root_id, pc.post_id, pc.parent_id, pc.review,
pc.created_on, pc.score
FROM post_comment pc
INNER JOIN post_comment_score pcs ON pc.parent_id = pcs.id
)
SELECT id, parent_id, review, created_on, score, root_id
FROM post_comment_score
ORDER BY id
而且,因为我们现在有了该列,我们可以使用它来使用Window Functionroot_id计算每个层次结构的分数:SUM
WITH RECURSIVE post_comment_score(
id, root_id, post_id, parent_id, review, created_on, score) AS (
SELECT id, id, post_id, parent_id, review, created_on, score
FROM post_comment
WHERE post_id = 1 AND parent_id IS NULL
UNION ALL
SELECT pc.id, pcs.root_id, pc.post_id, pc.parent_id, pc.review,
pc.created_on, pc.score
FROM post_comment pc
INNER JOIN post_comment_score pcs ON pc.parent_id = pcs.id
)
SELECT id, parent_id, review, created_on, score,
SUM(score) OVER (PARTITION BY root_id) AS total_score
FROM post_comment_score
ORDER BY id
并且,我们将得到预期的结果集:
| id | parent_id | review | created_on | score | total_score ||----|-----------|---------------|----------------------------|-------|-------------|| 1 | | Comment 1 | 2019-10-13 12:23:05.000000 | 1 | 6 || 2 | 1 | Comment 1.1 | 2019-10-14 13:23:10.000000 | 2 | 6 || 3 | 1 | Comment 1.2 | 2019-10-14 15:45:15.000000 | 2 | 6 || 4 | 3 | Comment 1.2.1 | 2019-10-15 10:15:20.000000 | 1 | 6 || 5 | | Comment 2 | 2019-10-13 15:23:25.000000 | 1 | 3 || 6 | 5 | Comment 2.1 | 2019-10-14 11:23:30.000000 | 1 | 3 || 7 | 5 | Comment 2.2 | 2019-10-14 14:45:35.000000 | 1 | 3 || 8 | | Comment 3 | 2019-10-15 10:15:40.000000 | 1 | 9 || 9 | 8 | Comment 3.1 | 2019-10-16 11:15:45.000000 | 10 | 9 || 10 | 8 | Comment 3.2 | 2019-10-17 18:30:50.000000 | -2 | 9 || 11 | | Comment 4 | 2019-10-19 21:43:55.000000 | -5 |-5 || 12 | | Comment 5 | 2019-10-22 23:45:00.000000 | 0 | 0 | |
结论
SQL Recursive WITH CTE (Common Table Expression) 允许我们迭代地构建结果集,这在处理分层数据模型时非常有用。
自以下版本以来,所有最常用的关系数据库都支持 Recursive WITH 子句:
- 甲骨文 9i R2
- SQL Server 2005
- PostgreSQL 8.4
- MySQL 8.0.1
- 玛丽亚数据库 10.2.2
因此,如果你使用的是这些关系数据库的较新版本,那么你绝对可以从这项出色的 SQL 功能中受益。
原文作者:Vlad Mihalcea


