
源码分析kryo对java基础数据类型与Stirng类型的序列化反序列化机制原创
kryo序列化原理
用过dubbo的开发人员,在选取序列化时都会根据“经验”来选kryo为序列化,其原因是序列化协议非常高效,超过java原生序列化协议、hessian2协议,那kryo为什么高效呢?
序列化协议,所谓的高效,通常应该从两方面考虑:
- 序列化后的二进制序列大小。(核心)
- 序列化、反序列化的速率。
本节将重点探讨,kryo在减少序列化化二进制流上做的努力。
- 序列化:将各种数据类型(基本类型、包装类型、对象、数组、集合)等序列化为byte数组的过程。
- 反序列化:将byte数组转换为各种数据类型(基本类型、包装类型、对象、数组、集合)。
java中定义的数据类型所对应的序列化器在Kryo的构造函数中构造,其代码截图:
接下来将详细介绍java常用的数据类型的序列化机制,即Kryo是如何编码二进制流。

Kryo对各数据类型的序列化与反序列化实现都是通过DefaultSerializers的内部类实现的。
IntSerializer
int类型序列化。
1static public class IntSerializer extends Serializer<Integer> {
2 {
3 setImmutable(true);
4 }
5
6 public void write (Kryo kryo, Output output, Integer object) {
7 output.writeInt(object, false);
8 }
9
10 public Integer read (Kryo kryo, Input input, Class<Integer> type) {
11 return input.readInt(false);
12 }
13}
Integer序列化为byte[]
1Output#writeInt (int value, boolean optimizePositive)
2public int writeInt (int value, boolean optimizePositive) throws KryoException { // @1
3return writeVarInt(value, optimizePositive); // @2
4}
- 代码@1:boolean optimizePositive,是否优化绝对值。如果optimizePositive:false,则会对value进行移位运算,如果是正数,则存放的值为原值的两倍,如果是负数的话,存放的值为绝对值的两倍减去一,其算法为:value = (value << 1) ^ (value >> 31),在反序列化时,通过该算法恢复原值:((result >>> 1) ^ -(result & 1))。
- 代码@2:调用writeVarInt,采用变长编码来存储int而不是固定4字节。
Output#writeVarInt
1public int writeVarInt (int value, boolean optimizePositive) throws KryoException {
2 if (!optimizePositive) value = (value << 1) ^ (value >> 31);
3 if (value >>> 7 == 0) { // @1
4 require(1);
5 buffer[position++] = (byte)value;
6 return 1;
7 }
8 if (value >>> 14 == 0) { // @2
9 require(2);
10 buffer[position++] = (byte)((value & 0x7F) | 0x80);
11 buffer[position++] = (byte)(value >>> 7);
12 return 2;
13 }
14 if (value >>> 21 == 0) {
15 require(3);
16 buffer[position++] = (byte)((value & 0x7F) | 0x80);
17 buffer[position++] = (byte)(value >>> 7 | 0x80);
18 buffer[position++] = (byte)(value >>> 14);
19 return 3;
20 }
21 if (value >>> 28 == 0) {
22 require(4);
23 buffer[position++] = (byte)((value & 0x7F) | 0x80);
24 buffer[position++] = (byte)(value >>> 7 | 0x80);
25 buffer[position++] = (byte)(value >>> 14 | 0x80);
26 buffer[position++] = (byte)(value >>> 21);
27 return 4;
28 }
29 require(5);
30 buffer[position++] = (byte)((value & 0x7F) | 0x80);
31 buffer[position++] = (byte)(value >>> 7 | 0x80);
32 buffer[position++] = (byte)(value >>> 14 | 0x80);
33 buffer[position++] = (byte)(value >>> 21 | 0x80);
34 buffer[position++] = (byte)(value >>> 28);
35 return 5;
36 }
其思想是采取变长字节来存储int类型的数据,int在java是固定4字节,由于在应用中,一般使用的int数据都不会很大,4个字节中,存在高位字节全是存储0的情况,故kryo为了减少在序列化流中的大小,尽量按需分配,kryo采用1-5个字节来存储int数据,为什么int类型在JAVA中最多4个字节,为什么变长int可能需要5个字节才能存储呢?这与变长字节需要标志位有关,下文根据代码来推测kryo关于int序列化byte数组的编码规则。
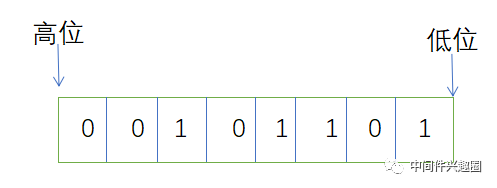
- 代码@1:value >>> 7 == 0 ,一个数字,无符号右移(高位补0)7位后为0,说明该数字只占一个字节,并且高两位必须为0,也就是该数字的范围在0-127(2^7 -1),对于字节的高位,低位的说明如下:
如果该值范围为0-127直接,则使用1个字节存储int即可。在操作缓存区时buffer[position++] = (byte)value,需要向Output的缓存区申请1个字节的空间,然后进行赋值,并返回本次申请的存储空间,对于require方法在Byte[]、String序列化时重点讲解,包含缓存区的扩容,Output与输出流结合使用时的相关机制。
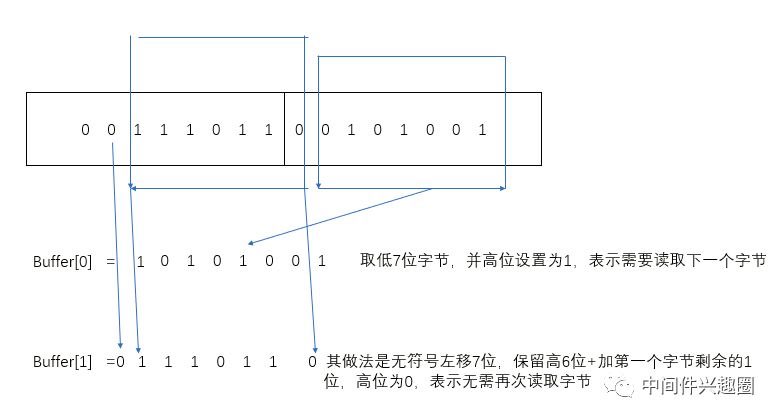
- 代码@2:value >>> 14 == 0,如果数字的范围在0到2^14-1范围之间,则需要两个字节存储,这里为什么是14,其主要原因是,对于一个字节中的8位,kryo需要将高位用来当标记位,用来标识是否还需要读取下一个字节。1:表示需要,0:表示不需要,也就是一个数据的结束。在变长int存储过中,一个字节8位kryo可用来存储数字有效位为7位 。
举例演示一下:
kryo两字节能存储的数据的特点是高字节中前两位为0,例如:
0011 1011 0 010 1001
其存储方式:
- buffer[0] = 先存储最后字节的低7位,010 1001 ,然后第一位之前,加1,表示还需要申请第二个字节来存储。此时buffer[0] = 1010 1001
- buffer[1] = 存储 011 1011 0(这个0是原第一个字节未存储的部分) ,此时buffer[1]的8位中的高位为0,表示存储结束。
下图展示了kryo用2个字节存储一个int类型的数据的示意图。
同理,用3个字节可以表示2^21 -1。
kryo使用变长字节(1-5)个字节来存储int类型(java中固定占4字节)。
int反序列化(byte[]->int)
反序列化就是根据上述编码规则,将byte[]序列化为int数字。
buffer[0] = 低位,buffer[1] 高位,具体解码实现为:
Input#readVarInt
1/** Reads a 1-5 byte int. It is guaranteed that a varible length encoding will be used. */
2 public int readVarInt (boolean optimizePositive) throws KryoException {
3 if (require(1) < 5) return readInt_slow(optimizePositive);
4 int b = buffer[position++];
5 int result = b & 0x7F;
6 if ((b & 0x80) != 0) {
7 byte[] buffer = this.buffer;
8 b = buffer[position++];
9 result |= (b & 0x7F) << 7;
10 if ((b & 0x80) != 0) {
11 b = buffer[position++];
12 result |= (b & 0x7F) << 14;
13 if ((b & 0x80) != 0) {
14 b = buffer[position++];
15 result |= (b & 0x7F) << 21;
16 if ((b & 0x80) != 0) {
17 b = buffer[position++];
18 result |= (b & 0x7F) << 28;
19 }
20 }
21 }
22 }
23 return optimizePositive ? result : ((result >>> 1) ^ -(result & 1));
24 }
Input#require(count)返回的是缓存区剩余字节数(可读)。其实现思路是,一个一个字节的读取,读到第一个字节后,首先提取有效存储位的数据,buffer[ 0 ] & 0x7F,然后判断高位是否为1,如果不为1,直接返回,如果为1,则继续读取第二位buffer[1],同样首先提取有效数据位(低7位),然后对这数据向左移7位,在与buffer[0] 进行或运算。也就是,varint的存放是小端序列,越先读到的位,在整个int序列中越靠近低位。
String序列化
其实现类StringSerializer,为DefaultSerializers的内部类。
1 static public class StringSerializer extends Serializer<String> {
2 {
3 setImmutable(true);
4 setAcceptsNull(true); // @1
5 }
6
7 public void write (Kryo kryo, Output output, String object) {
8 output.writeString(object);
9 }
10
11 public String read (Kryo kryo, Input input, Class<String> type) {
12 return input.readString();
13 }
14 }
- 代码@1:String位不可变、允许为空,也就是序列化时需要考虑String s = null的情况。
序列化 (String -> byte[])
Output#writeString
1public void writeString (String value) throws KryoException {
2 if (value == null) { // @1
3 writeByte(0x80); // 0 means null, bit 8 means UTF8.
4 return;
5 }
6 int charCount = value.length();
7 if (charCount == 0) { // @2
8 writeByte(1 | 0x80); // 1 means empty string, bit 8 means UTF8.
9 return;
10 }
11 // Detect ASCII.
12 boolean ascii = false;
13 if (charCount > 1 && charCount < 64) { // @3
14 ascii = true;
15 for (int i = 0; i < charCount; i++) {
16 int c = value.charAt(i);
17 if (c > 127) {
18 ascii = false;
19 break;
20 }
21 }
22 }
23 if (ascii) { // @4
24 if (capacity - position < charCount)
25 writeAscii_slow(value, charCount);
26 else {
27 value.getBytes(0, charCount, buffer, position);
28 position += charCount;
29 }
30 buffer[position - 1] |= 0x80;
31 } else {
32 writeUtf8Length(charCount + 1); // @5
33 int charIndex = 0;
34 if (capacity - position >= charCount) { // @6
35 // Try to write 8 bit chars.
36 byte[] buffer = this.buffer;
37 int position = this.position;
38 for (; charIndex < charCount; charIndex++) {
39 int c = value.charAt(charIndex);
40 if (c > 127) break;
41 buffer[position++] = (byte)c;
42 }
43 this.position = position;
44 }
45 if (charIndex < charCount) writeString_slow(value, charCount, charIndex); // @7
46 }
47 }
首先对字符串编码成字节序列,通常采用的编码方式为length:具体内容,通常的做法,表示字符串序列长度为固定字节,例如4位,那kryo是如何来表示的呢?请看下文分析。
- 代码@1:如果字符串为null,采用一个字节来表示长度,长度为0,并且该字节的高位填充1,表示字符串使用UTF-8编码,null字符串的最终表示为:1000 0000。
- 代码@2:空字符串表示,长度用1来表示,同样高位使用1填充表示字符串使用UTF-8编码,空字符串最终表示为:1000 0001。注:长度为1表示空字符串。
- 代码@3:如果字符长度大于1并且小于64,依次检查字符,如果其ascii小于127,则认为可以用ascii来表示单个字符,不能超过127的原因是,其中字节的高一位需要表示编码,0表示ascii,当用ascii编码来表示字符串是,第高2位需要用来表示是否结束标记。
- 代码@4:如果使用ascii编码,则单个字符,使用一个字节表示,高1位表示编码标记为,高2位表示是否结束标记。
- 代码@5:按照UTF-8编码,写入其长度,用变长int(varint)写入字符串长度,具体实现如下:
Output#writeUtf8Length
1private void writeUtf8Length (int value) {
2 if (value >>> 6 == 0) {
3 require(1);
4 buffer[position++] = (byte)(value | 0x80); // Set bit 8.
5 } else if (value >>> 13 == 0) {
6 require(2);
7 byte[] buffer = this.buffer;
8 buffer[position++] = (byte)(value | 0x40 | 0x80); // Set bit 7 and 8.
9 buffer[position++] = (byte)(value >>> 6);
10 } else if (value >>> 20 == 0) {
11 require(3);
12 byte[] buffer = this.buffer;
13 buffer[position++] = (byte)(value | 0x40 | 0x80); // Set bit 7 and 8.
14 buffer[position++] = (byte)((value >>> 6) | 0x80); // Set bit 8.
15 buffer[position++] = (byte)(value >>> 13);
16 } else if (value >>> 27 == 0) {
17 require(4);
18 byte[] buffer = this.buffer;
19 buffer[position++] = (byte)(value | 0x40 | 0x80); // Set bit 7 and 8.
20 buffer[position++] = (byte)((value >>> 6) | 0x80); // Set bit 8.
21 buffer[position++] = (byte)((value >>> 13) | 0x80); // Set bit 8.
22 buffer[position++] = (byte)(value >>> 20);
23 } else {
24 require(5);
25 byte[] buffer = this.buffer;
26 buffer[position++] = (byte)(value | 0x40 | 0x80); // Set bit 7 and 8.
27 buffer[position++] = (byte)((value >>> 6) | 0x80); // Set bit 8.
28 buffer[position++] = (byte)((value >>> 13) | 0x80); // Set bit 8.
29 buffer[position++] = (byte)((value >>> 20) | 0x80); // Set bit 8.
30 buffer[position++] = (byte)(value >>> 27);
31 }
32 }
用来表示字符串长度的编码规则(int),第8位(高位)表示字符串的编码,第7位(高位)表示是否还需要读取下一个字节,也就是结束标记,1表示未结束,0表示结束。一个字节共8位,只有低6位用来存放数据, varint采取的是小端序列。
- 代码@6:如果当前缓存区有足够的空间,先尝试将字符串中单字节数据写入到buffer中,碰到第一个非单字节字符时,结束。
- 代码@7:将剩余空间写入缓存区。
Output#writeString_slow
1private void writeString_slow (CharSequence value, int charCount, int charIndex) {
2 for (; charIndex < charCount; charIndex++) { // @1
3 if (position == capacity) require(Math.min(, charCount - charIndex)); // @2
4 int c = value.charAt(charIndex); // @3
5 if (c <= 0x007F) { // @4
6 buffer[position++] = (byte)c;
7 } else if (c > 0x07FF) { // @5
8 buffer[position++] = (byte)(0xE0 | c >> 12 & 0x0F);
9 require(2);
10 buffer[position++] = (byte)(0x80 | c >> 6 & 0x3F);
11 buffer[position++] = (byte)(0x80 | c & 0x3F);
12 } else { // @6
13 buffer[position++] = (byte)(0xC0 | c >> 6 & 0x1F);
14 require(1);
15 buffer[position++] = (byte)(0x80 | c & 0x3F);
16 }
17 }
18 }
- 代码@1:循环遍历字符的字符。
- 代码@2:如果当前缓存区已经写满,尝试申请(capacity 与 charCount - charIndex)的最小值,这里无需担心字符不是单字节申请charCount - charIndex空间不足的问题,后面我们会详细分析require方法,字节不够时会触发缓存区扩容或刷写到流中,再重复利用缓存区。
- 代码@3:int c = value.charAt(charIndex); 将字符类型转换为int类型,一个中文字符对应一个 int数字,这是因为java使用unicode编码,每个字符占用2个字节,char向int类型转换,就是将2字节的字节编码,转换成对应的二进制,然后用10进制表示的数字。
- 代码@4:如果值小于等0x7F(127),直接存储在1个字节中,此时高位4个字节的范围在(0-7)
- 代码@5:如果值大于0x07FF(二进制 0000 0111 1111 1111),第一个大于0x7F的值为(0000 1000 0000 0000),即2^12,数据有效位至少12位,使用3字节来存储,具体存储方式为:
1)buffer[0]:buffer[position++] = (byte)(0xE0 | c >> 12 & 0x0F); 首先将c右移12位再与0x0F进行与操作,其意义就是先提取c的第16-13(4位的值),并与0xE0取或,最终的值为 0xE (16-13)位的值,从Input读取字符串可以看出,是根据0xE0作为存储该字符需要3个字节的依据,并且只取16-13位的值作为其高位的有效位,也就是说字符编码的值,不会超过0XFFFF,也就是两个字节(正好与java unicode编码吻合)。
2)buffer[1]:存储第12-7(共6位),c >> 6 & 0x3F,然后与0X80进行或,高位设置为1,表示UTF-8编码,其实再反序列化时,这个高位设置为1,未有实际作用。
3)buffer[2]:存储第6-1(共6位),0x80 | c & 0x3F,同样高位置1。
字符串反序列化 (byte[] -> String)
在讲解反序列化时,总结一下String序列化的编码规则
String序列化规则:
String序列化的整体结构为length + 内容,注意,这里的length不是内容字节的长度,而是String字符的长度。
- 如果是null,则用1个字节表示,其二进制为 1000 0000。
- 如果是""空字符串,则用1个字节表示,其二进制为1000 0001。
- 如果字符长度大于1·且小于64,并且字符全是ascii字符(小等于127),则每个字符用一个字节表示,最后一个字节的高位置1,表示String字符的结束。【优化点,如果是ascii字符,编码时不需要使用length+内容的方式,而是直接写入内容】
- 如果不满足上述条件,则需要使用length + 内容的方式。
- 用一个变长int写入字符的长度,每一字节,高两位分别为 编码标记(1:utf8)、是否结束标记(1:否;0:结束)
- 将内容用utf-8编码写入字节序列中,utf8,用变长字节(1-3)个字节表示一个字符(英文、中文)。每一个字节,使用6位,高两位为标志位。【16位】
- 3字节的存储为【4位】+【6位】+【6位】,根据第一个字节高4位判断得出需要几个字节来存储一个字符。
其反序列化的入口为Input#readString,就是按照上述规则进行解析即可,就不深入探讨了,有兴趣的话,可以自己去指定地方查阅。
boolean类型序列化
其实现类:BooleanSerializer。
序列化:使用1个字节存储boolean类型,如果为true,则写入1,否则写入0。
byte类型序列化
其实现类为:ByteSerializer
序列化:直接将byte写入字节流中即可。
char类型序列化
其实现类:CharSerializer。
Output#writeChar
1/** Writes a 2 byte char. Uses BIG_ENDIAN byte order. */
2 public void writeChar (char value) throws KryoException {
3 require(2);
4 buffer[position++] = (byte)(value >>> 8);
5 buffer[position++] = (byte)value;
6 }
序列化:char在java中使用2字节存储(unicode),kryo在序列化时,按大端字节的顺序,将char写入字节流。
short类型序列化
其实现类:ShortSerializer。
Output#writeShort
1/** Writes a 2 byte short. Uses BIG_ENDIAN byte order. */
2 public void writeShort (int value) throws KryoException {
3 require(2);
4 buffer[position++] = (byte)(value >>> 8);
5 buffer[position++] = (byte)value;
6 }
序列化:与char类型序列化一样,采用大端字节顺序存储。
long类型序列化
其实现类:LongSerializer。
Output#writeLong
1public int writeLong (long value, boolean optimizePositive) throws KryoException {
2 return writeVarLong(value, optimizePositive);
3}
序列化:采取变长字节(1-9)位来存储long,其编码规则与int变长类型一致,每个字节的高位用来表示是否结束,1:表示还需要继续读取下一个字节,0:表示结束。
float类型序列化
其实现类:FloatSerializer。
1/** Writes a 4 byte float. */
2public void writeFloat (float value) throws KryoException {
3 writeInt(Float.floatToIntBits(value));
4}
5/** Writes a 4 byte int. Uses BIG_ENDIAN byte order. */
6public void writeInt (int value) throws KryoException {
7 require(4);
8 byte[] buffer = this.buffer;
9 buffer[position++] = (byte)(value >> 24);
10 buffer[position++] = (byte)(value >> 16);
11 buffer[position++] = (byte)(value >> 8);
12 buffer[position++] = (byte)value;
13}
序列化:首先将float按照IEEE 754编码标准,转换为int类型,然后按大端序列,使用固定长度4字节来存储float,这里之所以不使用变长字节来存储float,是因为,使用Float.floatToIntBits(value)产生的值,比较大,基本都需要使用4字才能存储,如果使用变长字节,则需要5字节,反而消耗的存储空间更大。
double类型序列化
其实现类:DoubleSerializer。
Output#writeDouble序列化:首先将Double按照IEEE 754编码标准转换为Long,然后才去固定8字节存储。
到目前为止,介绍了8种基本类型(boolean、byte、char、short、int、float、long、double与String类型的序列化与反序列化。



