
【译】如何使用JMeter对Kafka进行负载测试转载
在本文中,我们将了解如何使用JMeterTM加载分布式流媒体平台Kafka测试。首先,让我们研究一下Kafka是什么,并给出一些我们进一步工作所需的定义。
Kafka简述
在大型分布式系统中,通常有很多服务会产生不同的事件:日志、监控数据、可疑的用户操作等。
在Kafka,这些被称为生产者。另一方面,有些服务需要生成的数据。这些被称为消费者。
Kafka解决了它们之间的互动问题。它位于生产者和消费者之间,同时从生产者那里收集数据,将它们存储在分布式主题存储库中,并通过订阅向每个消费者提供数据。Kafka是一个由一个或多个服务器组成的集群,每个服务器都被称为代理。
换句话说,Kafka是分布式数据库和消息队列的混合体。它以其功能而广为人知,被许多大公司用于处理TB的信息。例如,inLinkedIn,Apache Kafka用于流式传输有关用户活动的数据,Netflix将其用于Elasticsearch、Amazon EMR、Mantis等下游系统的数据收集和缓冲。
让我们看看Kafka的一些对负载测试很重要的功能:
- 一条长消息存储时间-默认情况下为一周。
- 高性能,得益于顺序I/O。
- 方便的聚类。
- 由于能够在整个集群中复制和分发队列,因此数据可用性很高。
- 它不仅能够传输数据,还可以使用流媒体API进行处理。
通常,Kafka用于处理大量数据。因此,在负载测试期间应注意以下几个方面:
- 不断将数据写入磁盘将影响服务器的容量。如果不够,它将达到拒绝服务状态。
- 此外,部分的分配和经纪人的数量也影响了服务能力的使用。例如,经纪人可能根本没有足够的资源来处理数据流。因此,生产者将耗尽本地缓冲区来存储消息,部分消息可能会丢失。
- 当使用复制功能时,一切都变得更加复杂。这是因为其维护需要更多的资源,当经纪人拒绝接收消息时,情况变得更加可能。
如此大量处理的数据很容易丢失,即使大多数流程都是自动化的。因此,对这些服务的测试很重要,并且必须能够产生适当的负载。
为了演示负载测试Kafka,它将安装在Ubuntu上。我们还将使用Pepper-Box插件作为生产者。它有一个更方便的界面来处理消息生成感谢卡米。我们必须自己实现消费者,因为没有插件提供消费者实现,我们将使用JSR223采样器来做到这一点。
配置生产者:Pepper-Box
要安装插件,你需要编译此源代码或下载jar文件,然后将其放入lib/ext文件夹并重新启动JMeter。
此插件有3个元素:
- Pepper-Box PlainText Config允许根据指定的模板构建文本消息。
- Pepper-Box Serialized Config允许构建序列化Java对象的消息。
- PepperBoxKafkaSampler旨在发送由以前的元素构建的消息。
让我们看看他们中的每一个。
Pepper-Box PlainText配置
要添加此项目,请转到线程组->添加->配置元素->Pepper-Box PlainText配置
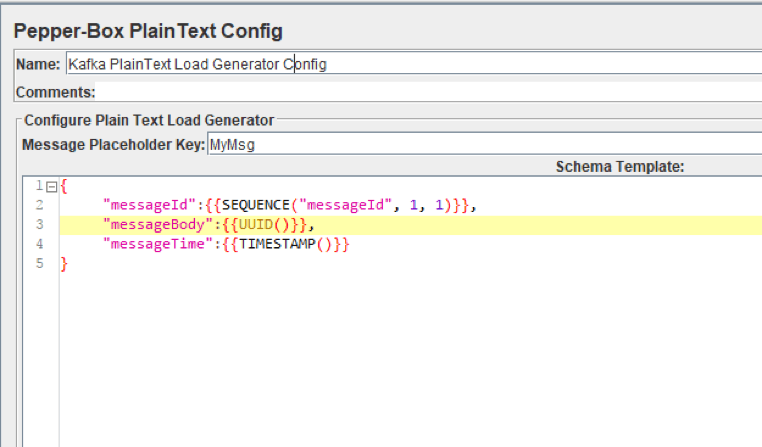
如上图所示,该元素有2个字段:
- 消息占位符密钥-需要在PepperBoxKafkaSampler中指定才能使用此元素的模板。
- 模式模板-一个消息模板,你可以在其中使用JMeter变量和函数,也可以使用插件函数。消息的结构可以是任何东西,从纯文本到JSON或XML。
例如,在上面的屏幕截图中,我们正在使用几个插件函数将JSON字符串作为消息传递:指定消息编号,指定标识符和发送时间戳。
Pepper-Box有序列号配置
要添加此元素,请转到线程组->添加->配置元素->Pepper-Box序列化配置
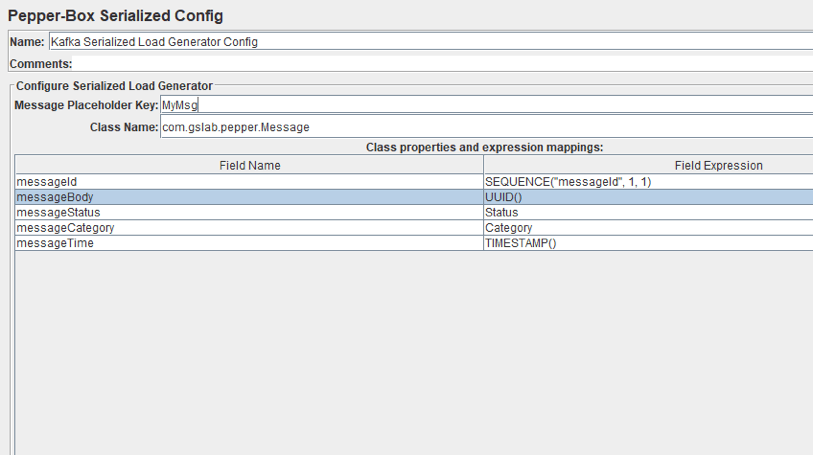
如上图所示,该元素有一个键字段和一个类名字段,用于指定Java类。带有类的jar文件必须放在lib/ext文件夹中。指定后,具有其属性的字段将显示在下面,你可以为它们分配所需的值。我们重复了最后一个元素的消息,但这次它将是一个Java对象。
PepperBox Kafka Sampler
要添加此元素,请转到线程组->添加->采样器->Java请求。然后,从下拉列表中选择com.gslab.pepper.sampler.PepperBoxKafkaSampler。
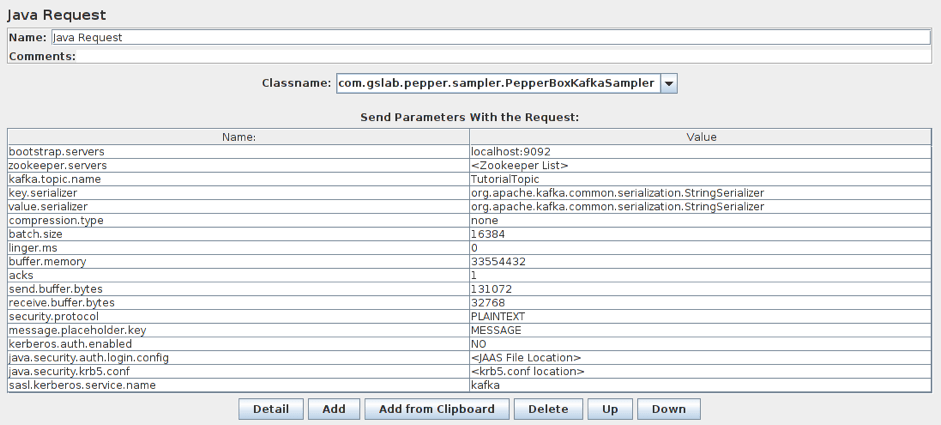
此元素具有以下设置:
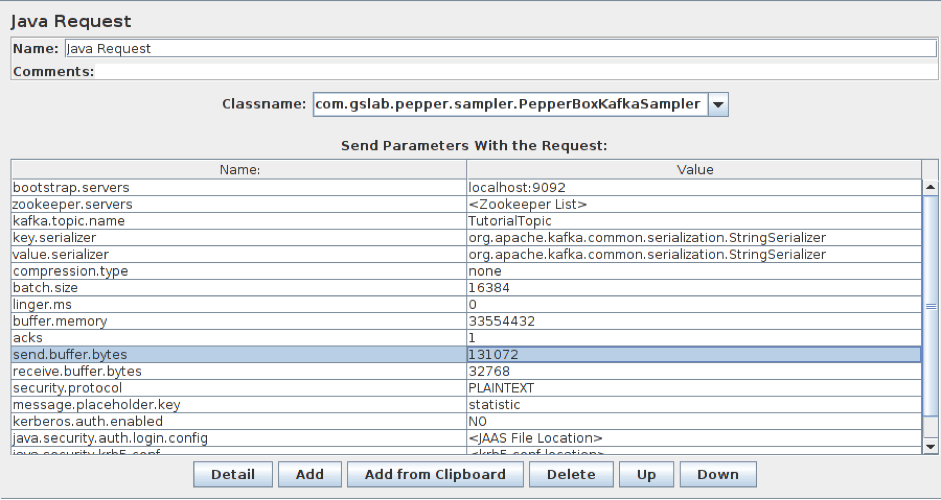
- bootstrap.servers/zookeeper.servers - brokers/zookeepers(动物园管理员是在不同经纪人之间分配生产者负载的接口)以经纪人-ip-1:端口、经纪人-ip-2:端口等格式的地址。
- kafka.topic.name - 是消息发布主题的名称。
- key.serializer - 是密钥序列化的类。如果消息中没有按键,请保持不变。
- value.serializer - 是消息序列化的类。对于一个简单的文本,字段保持不变。使用Pepper-Box Serialized Config时,你需要指定“com.gslab.pepper.input.serialized.ObjectSerializer”。
- compression.type - 是一种消息压缩(无/gzip/snappy/lz4)。
- batch.size - 是最大的消息大小。
- linger.ms - 是消息等待时间。
- buffer.memory - 是生产者的缓冲区大小。
- acks-是服务质量(-1/0/1-不能保证交付/消息肯定会发送/消息将传递一次)。
- receive.buffer.bytes/send.buffer.bytes - TCP发送/接收缓冲区的大小。-1 - 使用默认操作系统值。
- security.protocol - 是加密协议(PLAINTEXT/SSL/SASL_PLAINTEXT/ SASL_SSL)。
- message.placeholder.key - 是消息密钥,在之前的元素中指定。
- kerberos.auth.enabled、java.security.auth.login.config、java.security.krb5.conf、sasl.kerberos.service.name - 是一个负责身份验证的字段组。
此外,如有必要,你可以使用名称前面的前缀_添加其他参数,例如_ssl.key.password。
配置消费者
现在让我们转向消费者。虽然是生产者在服务器上创建了最大的负载,但该服务也必须传递消息。因此,我们还应该添加消费者来更准确地重现情况。它们还可用于检查所有消费者消息是否已发送。
例如,让我们采取以下源代码,并简要介绍其步骤:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
} 1.执行连接配置。
2.将指定一个主题,并对其进行订阅。
3.消息在本主题的周期中收到,并被带到控制台。
此代码经过一些修改后,将添加到JMeter中的JSR223采样器中。
在JMeter中构建负载测试Apache Kafka场景
现在我们已经研究了创建负载的所有必要元素,让我们尝试将几条消息发布到我们的Kafka服务的主题中。让我们想象一下,我们有一个资源来收集其活动的数据。这些信息将作为XML文档发送。
1.添加Pepper-Box PlainText配置并创建一个模板。消息的结构如下:消息编号、消息ID、从中收集统计数据的项目ID、统计数据、发送日期戳。下面的屏幕截图显示了消息模板。
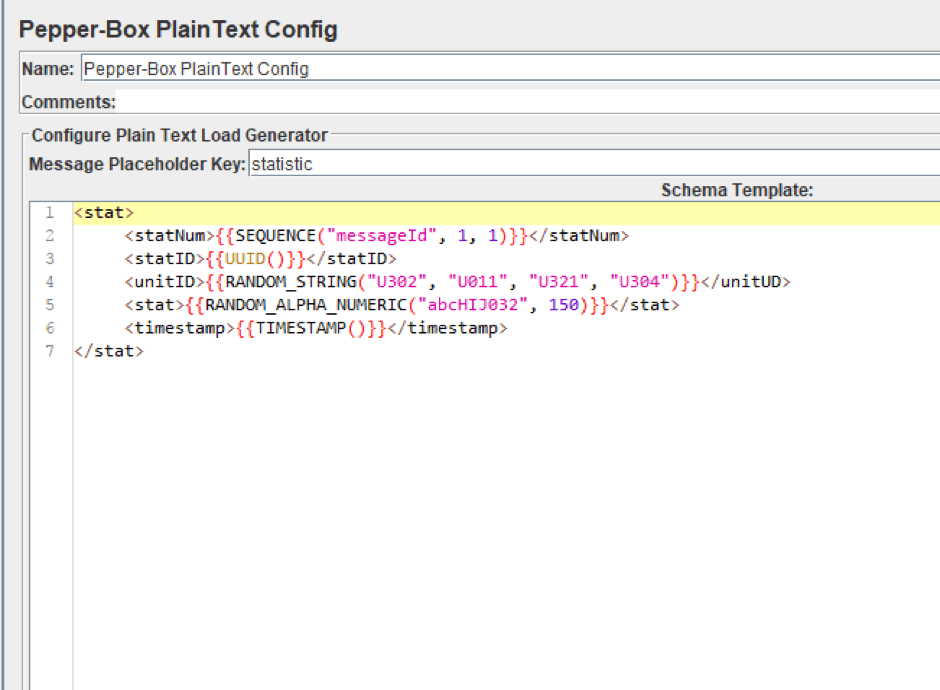
2.添加PepperBoxKafkaSampler。在其中,从我们的Kafka服务中指定bootstrap.servers和kafka.topic.name的地址。在我们的案例中,经纪人的地址是localhost:9092,演示的主题是教程主题。我们还将从上一步的模板元素中指定占位符.key。
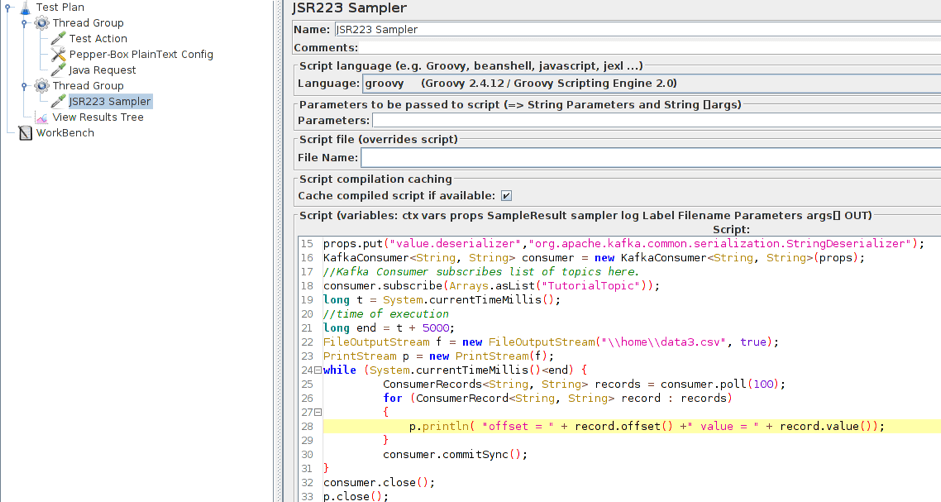
3.将带有消费者代码的JSR223采样器添加到单独的线程组中。要让它工作,你还需要一个kafka-clients-x.x.x.x.jar文件,其中包含使用Kafka的类。你可以在Kafka目录-/kafka/lib中找到它。
在这里,我们修改了部分脚本,现在它将数据保存到文件中,而不是在控制台中显示。这样做是为了更方便地分析结果。我们还添加了设置消费者执行时间所需的部分。对于演示,它被设置为5秒。
更新部件:
long t = System.currentTimeMillis();
long end = t + 5000;
f = new FileOutputStream(".\\data.csv", true);
p = new PrintStream(f);
while (System.currentTimeMillis()<end)
{
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
{
p.println( "offset = " + record.offset() +" value = " + record.value());
}
consumer.commitSync();
}
consumer.close();
p.close();
f.close();现在脚本的结构如下。两个线程同时工作。制作人开始向指定主题发布消息。消费者连接到主题,并等待来自卡夫卡的消息。当消费者收到消息时,它会将消息写入文件。
4.运行脚本并查看结果。
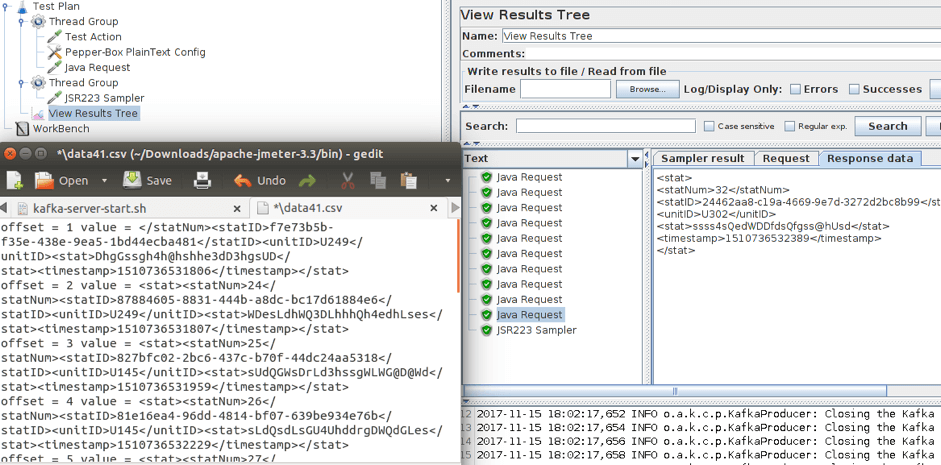
如上图所示,发送了十条消息。你可以在打开的文件中看到收到的消息。之后,你只需要调整消费者和生产者的数量来增加负载。
值得提醒的是,Apache Kafka专为大量连接而设计,因此你只需达到网络负载生成器的容量限制即可。在这种情况下,JMeter保持分布式测试的功能。
我还想指出,在测试期间使用随机数据进行消息是没有意义的,因为它们的大小可能与当前数据有很大差异,而且这种差异可能会影响测试结果。请认真对待测试数据。
就这样!拜了个拜!
原文作者:Roman Aladev


