
【译】如果把MySQL当成Redis用,和Redis本身比性能如何?转载
这是我围绕UUID集缓存的“研究”的一部分。基准测试了Map Performance Java与Scala,二进制搜索而不是HashSet,甚至将Set缓存移动到Redis。现在是时候将MySQL作为此类缓存进行基准测试了。
我知道这是一个愚蠢的基准。但就整个情况而言:)希望我不会用它来衡量其他不成程序的东西。
不过,我还是想再测试一件与JDBC有关的事情,如果感兴趣的同学可以看一看!
我们在测试什么?
我的用例很简单——我有一大套内存UUID,大约100万个密钥。这就是我将其存储在MySQL中的方式:
CREATE TABLE set1m (
id BINARY(16) NOT NULL PRIMARY KEY
) ENGINE=InnoDB ROW_FORMAT=DYNAMIC;将UUID转换为BINARY(16)的代码(这只是JDBC中的字节数组):
public static byte[] toBytes(UUID value) {
byte[] array = new byte[16];
ByteBuffer bb = ByteBuffer.wrap(array);
bb.putLong(value.getMostSignificantBits());
bb.putLong(value.getLeastSignificantBits());
return array;
}基准
基准代码相对简单:N线程逐一获取UUID并进行简单的查询:
SELECT 1 FROM set1m WHERE id = ?我把一个线程的基准测试为10个线程。
调味!
一段时间以来,我一直在想连接池的开销。在Wix,我们不久前开始使用HikariCP。
我们和一位朋友讨论了这个问题,他声称在屏蔽环境中使用连接池是不明智的,你可以简单地使用具有连接和一些家政服务的线程本地人,这样会更有效率。
当然,这种方法存在一些问题:
- 如果Jetty(或任何其他servlet容器)使用池中的所有线程,那么我们将使用比实际应该使用更多的连接。
- 管家很棘手。此外,无法预热连接,或者至少不简单(启动时发出HTTP调用?)
无论如何,在基准测试中,这是一个很好的机会,可以实际检查它,而无需编写复杂的连接内部管理代码等。因此,这就是我所做的:将HikariCP与预热连接与存储在ThreadLocal中的预热连接进行了比较。
结果
中位查询时间并不真正取决于表的大小。然而,10M表略慢(几微秒):

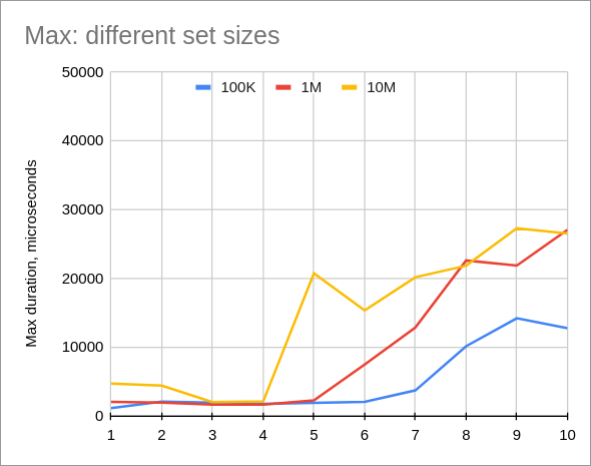
相反,最大查询时间似乎有点取决于表大小。我想知道为什么?我把innodb_buffer_pool_size设置为1G,这比表大小大。
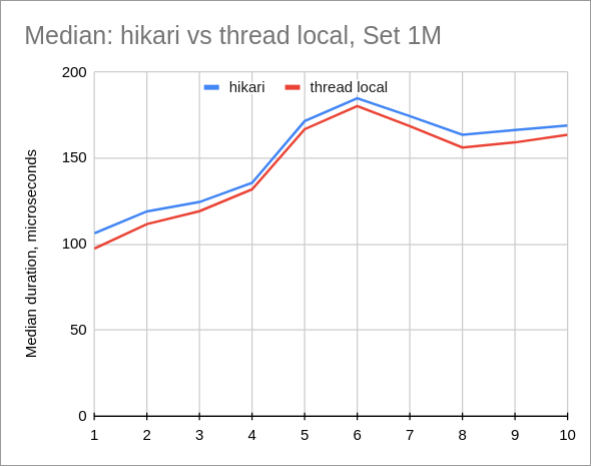
HikariCP vs Thread Local
线程本地的中位时间始终更好,相差3-8微秒。这对于查询本地主机来说大约是10%,但通常我们通过网络查询MySQL,因此它将是开销的1%或更少。不是很好,也不可怕。
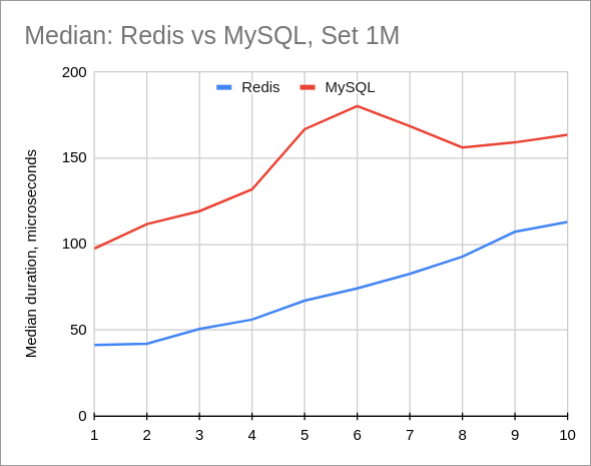
MySQL vs Redis
可以预见,Redis的性能优于MySQL。尽管MySQL中的数据集真的很小(数百兆字节),但SQL的开销似乎太重要了。
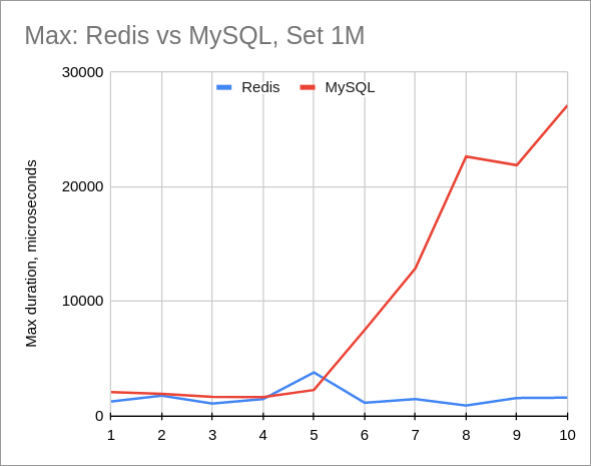
如果我们查看请求的最大持续时间,情况就更糟了。这意味着MySQL消耗的CPU比Redis多得多:
结论
当然,MySQL根本不适合这个用例。这很有道理,MySQL的优势不在于稳定性、复制、事务等。
对MySQL的不同方面进行基准测试很有趣(像往常一样)。我也很高兴我不需要为线程本地连接池编写家政代码来基准测试它(我想我的积压已经超过4年了),因为我宁愿探索对MySQL的异步访问,而不是阻止。
MySQL和MySQL与Redis的完整数据和图表。源代码在GitHub上。
原文作者:Dmitry Komanov


