
【译】对比多种MySQL高可用解决方案的优缺点转载
在这篇文章中,我们将对比研究各种MySQL高可用性解决方案,并尝试整理它们的优缺点。
高可用性环境为数据库的运行提供了巨大的好处:高可用性数据库环境将数据库放在多台机器上,其中任何一台机器都可以承担数据库的功能,这样,数据库就没有“单点故障”。
高可用(HA)策略的解决方案有很多,如何在众多选项中选择最佳解决方案?首先我们得问自己一个问题——你要解决的关键问题是什么? 是冗余、扩展还是高可用性?每一个问题的重心都不一样:
- 发生灾难时需要多个数据副本
- 需要增加读取和/或写入吞吐量
- 需要最小化停机时间

在规划数据库环境时,务必记住 CAP 定理适用。CAP 定理将问题分为三类:一致性、可用性和分区容错性。三者只能得其二!
- 一致性。所有节点同时看到相同的数据。
- 可用性。每个请求都会收到关于它是否成功的响应。
- 分区容差。尽管由于网络故障导致任意分区,系统仍继续运行。
无论你选择什么解决方案,它都应该最大限度地保持一致性。问题是,虽然MySQL复制很棒,但它本身并不能保证所有节点之间都一致。因为会始终存在数据不同步的可能性,在故障转移和其他原因期间事务可能会丢失。
而基于 Galera 的集群(例如Percona XtraDB Cluster)是基于认证的,可以防止这种情况发生!
数据丢失
你应该问自己的第一个问题是:我能承受丢失数据的后果吗?
这通常取决于应用程序。应用程序应检查事务的状态代码以确保它们已提交。许多人没有!在故障转移期间也可能丢失事务。在故障转移期间,简单的复制方案可能会丢失数据
不一致的节点是另一个问题。如果没有冲突检测和解决,不一致的节点是不可避免的。
一种解决方案是经常运行 pt-table-checksum 以检查复制节点之间的不一致数据。
另一种选择是使用基于 Galera 的分布式集群,例如Percona XtraDB Cluster和认证过程。

避免单点故障
什么在监视您的系统?或者有什么准备好干预失败?对于复制,请查看 MHA 和 MySQL Orchestrator。两者都是执行副本故障转移的好工具。还有其他的。
对于Percona XtraDB Cluster,故障转移通常要快得多,但它并不是在所有情况下都是完美的解决方案。
我可以承担丢失的交易吗?
许多 MySQL DBA 担心将innodb_flush_log_at_trx_commit设置为 1 以实现 ACID 合规性和 sync_binlog,但随后使用没有一致性检查的复制!这在逻辑上是一致的吗?Percona XtraDB Cluster通过认证保持一致性。
冲突检测和解决
所有解决方案都必须具有某种冲突检测和解决方法。Galera的认证过程遵循以下方法:
- 事务在节点上照常继续,直到它到达 COMMIT 阶段。
- 更改被收集到一个 writeset 中。
- Writeset 被发送到所有节点进行认证。
- PK 用于确定是否可以应用 writeset。
- 如果认证失败,则删除 writeset 并回滚事务。
- 如果成功,则事务提交并将写入集应用于所有节点。
- 所有节点将对每笔交易做出相同的决定,因此是确定性的。
我想要故障转移还是分布式系统?
另一个重要的考虑因素是您应该使用故障转移还是分布式系统。故障转移系统一次运行一个实例,并在出现问题时“故障转移”到另一个实例。分布式系统一次运行多个实例,所有实例都处理不同的数据。
- 故障转移陷阱:
- 故障转移系统有一个监视器,可以检测故障节点并将服务转移到其他地方(如果可用)
- 故障转移需要时间!
- 分布式系统:
- 分布式系统最小化故障转移时间

另一个问题是:你的故障转移应该是自动的还是手动的?
- 手动故障转移的优势
- 手动故障转移的主要优点是人们通常可以更好地决定是否需要故障转移。
- 系统很少能做到完美,但它们可以很接近!
- 自动故障转移的优势
- 由于停机时间最小化,更多的 Nines
- 无需等待 DBA 执行
最后,一个问题是故障转移必须以多快的速度发生?显然,它发生得越快,潜在数据丢失的时间就越少。
- 复制 / MHA / MMM
- 取决于在发生故障转移之前完成待处理的副本事务需要多长时间
- 通常大约 30 秒
- DRBD
- 通常在 15 到 30 秒之间
- XtraDB 集群/ MySQL 集群
- 非常快速的故障转移。通常少于 1 秒,具体取决于负载均衡器
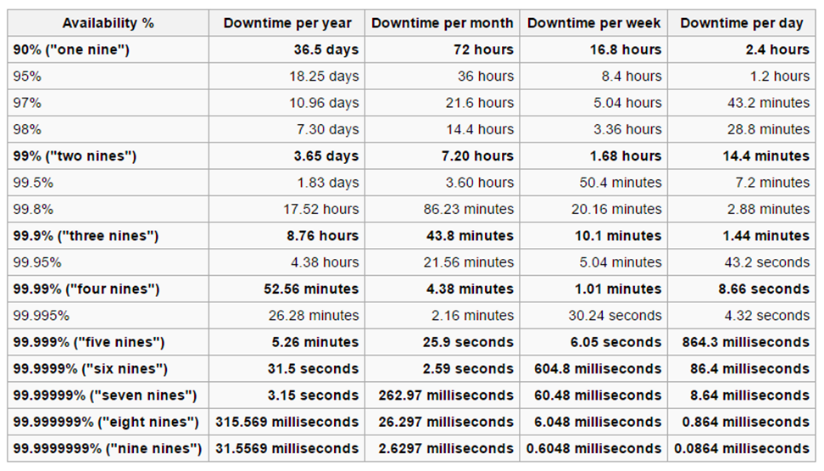
你真的需要多少个 9?
准确度的“9”衡量标准是衡量系统完美程度的标准。当谈到“多少个 9”时,每个 9 都更准确一个数量级。99.99 是四个 9,而 99.999 是五个 9。
每个经理对有多少个 9 的问题的回答总是“尽可能多”。这听起来不错,但现实情况是需要权衡取舍!许多应用程序可以容忍几分钟的停机时间而影响最小。下表显示了与每个“9”相关的停机时间:
我需要扩展读取和/或写入吗?
在查看您的环境时,了解您的工作负载很重要。您的工作量是读取、写入还是两者兼而有之?了解您是否需要扩展读取或写入对于选择 HA 解决方案很重要:
- 缩放读取
- 大多数解决方案提供从多个节点或副本读取的能力
- MHA、XtraDB 集群、MySQL 集群等非常适合这种情况
- 缩放写入
- 许多人错误地尝试通过写入XtraDB 集群中的多个节点来扩展写入,从而导致冲突
- 其他人尝试使用 Master-Master Replication 这也是有问题的
- 在这方面可能最好的解决方案是 MySQL Cluster
供应新节点怎么样?
- 复制
- 很大程度上,这是一个手动过程
- MySQL 实用程序使这比以往更容易
- 分布式集群
- XtraDB Cluster和 MySQL Cluster 让这一切变得更容易
- XtraDB Cluster使用状态传输(SST 或 IST)来自动化集群节点的过程

三分法则
使用XtraDB Cluster,尝试拥有三样东西。如果您跨越一个数据中心,则拥有三个数据中心。如果您的节点位于交换机上,请尝试使用三个交换机。
XtraDB Cluster至少需要集群中的三个节点。出于投票原因,首选奇数。忘记在只有两个数据中心的故障期间尝试保持集群活动。您最好将其设为 DR 站点。忘记自定义权重以尝试在两个数据中心上获得成功。无论如何,51% 的规则会让你受益!
我有多少个数据中心?
了解您的环境中涉及多少个数据中心是一个关键因素。运行多个数据中心会对您采用的 HA 解决方案产生影响。
如果我只有一个数据中心怎么办?您可以获得针对单个或更多故障节点的保护,具体取决于集群大小。如果您有两个数据中心,您可能应该考虑将第二个数据中心作为灾难恢复解决方案。在使用基于 Galera 的集群(例如XtraDB Cluster )时,拥有三个或更多数据中心是最强大的解决方案。
如何规划灾难恢复?
灾难恢复计划在您的 HA 环境中至关重要。确保 DR 节点可以处理流量,即使是在最低性能级别。
- 从XtraDB 集群复制到 DR 站点
- 从 XtraDB 集群到单个节点的异步复制
- 从 XtraDB 集群到复制拓扑的异步复制
- 从 XtraDB 集群到另一个 XtraDB 集群的异步复制
我需要什么存储引擎?
尤其是现在,有大量可用于数据库环境的存储引擎。您的 HA 解决方案应该使用哪一种?您的解决方案将有助于确定您可以使用哪种存储引擎。
- 不依赖于存储引擎。适用于所有存储引擎
- XtraDB 集群。需要 InnoDB。对 MyISAM 的支持是实验性的,不应在生产中使用
- MySQL 集群。需要 NDB 存储引擎

负载均衡器的选择
负载均衡器提供了一种在环境资源之间分配工作负载的方法,以免在任何特定点造成瓶颈。以下是一些负载平衡选项:
- HAProxy
- 开源软件解决方案
- 无法拆分读取和写入。如果这是一个要求,应用程序将需要这样做!
- F5 大IP
- 典型的硬件解决方案
- 最大比例
- 可以做读/写拆分
- 弹性负载均衡器 (ELB)
如果集群重新启动会发生什么?
某些更改需要重新启动集群才能应用更改。例如,更改参数组中的参数值仅在集群重启后应用到集群。集群也可能由于电源中断或其他技术故障而重新启动。
- 单个数据中心的停电可能会导致问题
- XtraDB 集群可以配置为自动引导
- 当所有节点同时断电时,可能并不总是有效。服务器运行时,grastate.dat 文件显示 -1 表示 seqno
- 在重启中幸存
- 如果系统管理员关闭节点以进行重新启动或其他此类过程,则很有帮助
- 正常关机正确设置 seqno
写完后我需要能够读取吗?
异步复制不保证跨节点的数据视图一致。XtraDB Cluster提供因果读取。副本将在处理其他查询之前等待事件被应用,从而保证跨节点的一致读取状态。
如果我进行大量数据加载怎么办?
在最近的过去,在XtraDB Cluster的此类场景中使用复制是一种传统观念。如果数据分布在多个模式上,但 MTS 并不适合所有情况,MTS 确实会有所帮助。XtraDB Cluster 现在是一个可行的选择,因为我们在 Galera 中发现了一个错误,它没有正确拆分大型事务。
我是否采取了预防脑裂的预防措施?
当一个集群的节点彼此分裂时,就会发生裂脑,这通常是由于网络故障,并且节点形成了两个或多个新的独立(因此是不同的)集群。XtraDB Cluster配置为进入非主状态并拒绝接收流量。XtraDB Cluster 的较新设置将允许对非主节点进行脏读
我的应用程序需要高并发吗?
较新的复制方法允许并行线程(XtraDB Cluster从一开始就有这个),例如多线程从属 (MTS)。MTS 允许一个副本拥有多个 SQL 线程,它们都有自己的中继日志。由于无法信任 SHOW SLAVE STATUS 来获取中继日志位置,它使 GTID 能够通过 Percona XTRABackup 进行更安全的备份。
我的内存受限吗?
一些分布式解决方案(例如 MySQL Cluster)需要大量 RAM,即使使用基于文件的表也是如此。一定要做好适当的计划。XtraDB Cluster 更像是一个独立节点。
我的网络有多稳定?
网络从来都不是真正 100% 可靠的。一些“网络问题”是由外部因素造成的,例如系统资源争用(尤其是在虚拟机上)。网络问题会导致不适当的故障转移问题。将 LAN 段与XtraDB Cluster一起使用以最小化 WAN 上的网络流量。
结论
做出正确的选择取决于:
- 知道你真正需要什么!
- 了解你的选择。
- 知道你的限制!
- 了解每种解决方案的优缺点
- 正确设定期望!
原文作者:Michael Patrick


