Redis源码简洁剖析12—RDB 文件原创
RDB 是什么
Redis *.rdb 是内存的二进制文件,通过 *.rdb 能够完全回复 Redis 的运行状态。
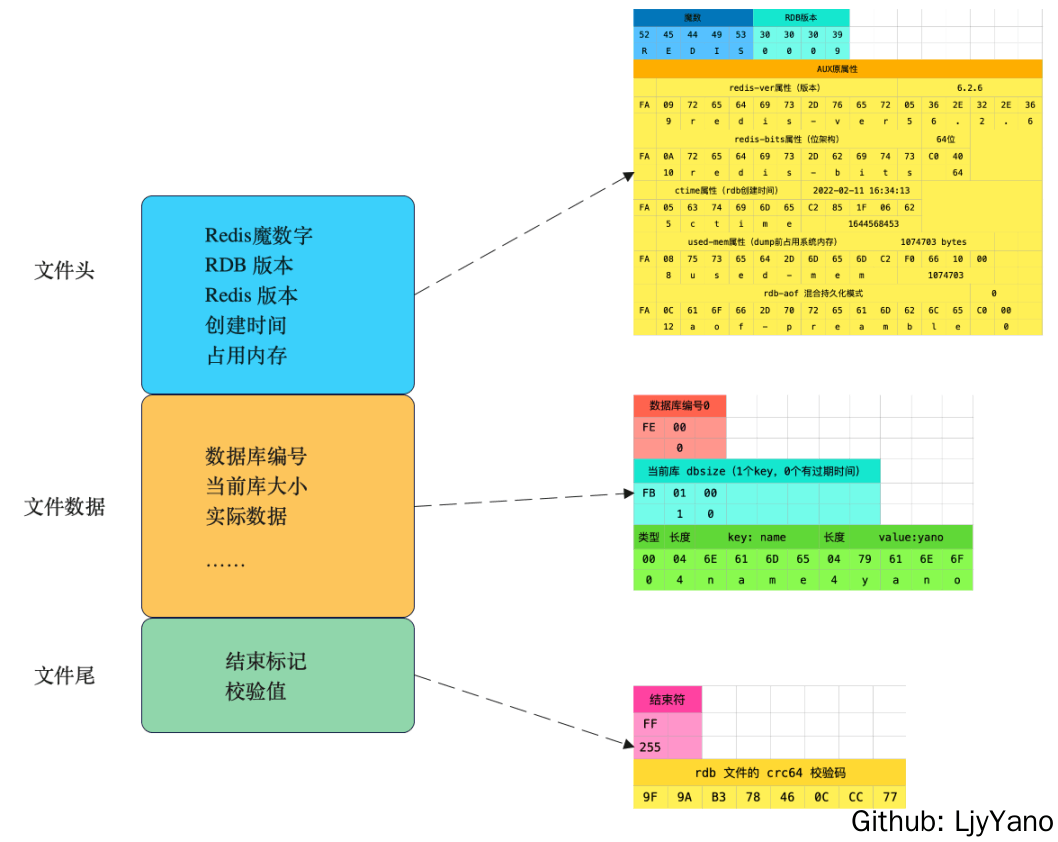
RDB 文件格式
详细信息可参考:Redis RDB Dump File Format。

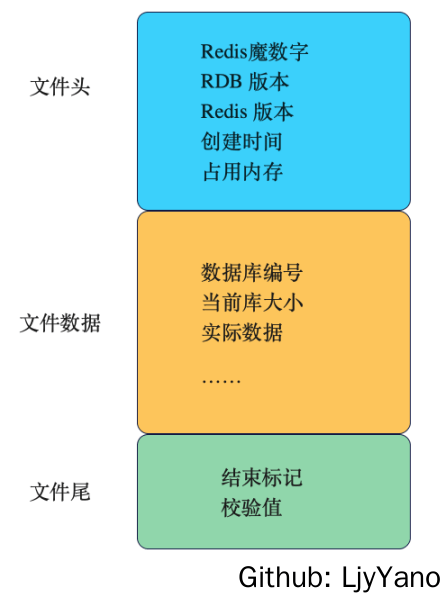
Header
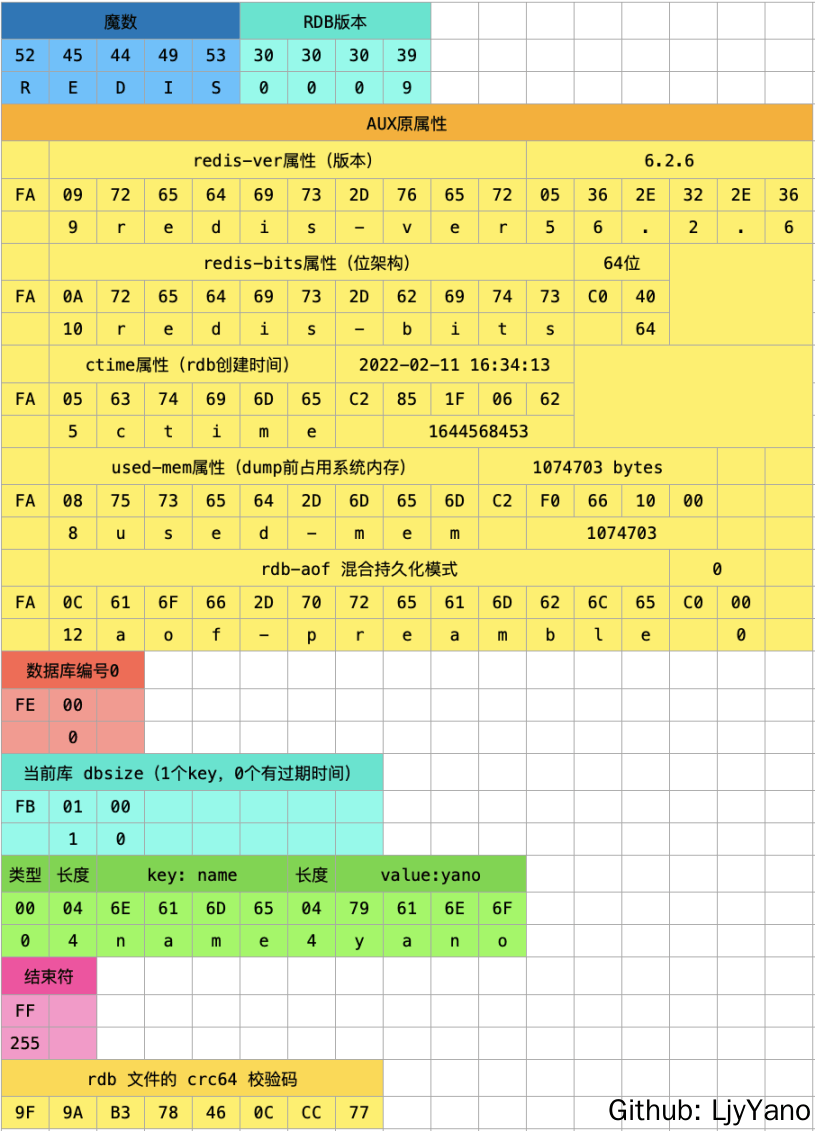
RDB 文件的头部占用 9bytes,前 5bytes 为 Magic String, 后 4bytes 为版本号;
52 45 44 49 53 #"REDIS", 就像 java 的 class 文件以 0xCAFEBABE 开头一样
30 30 30 36 #RDB 版本号,30 表示‘0’,版本号为 0006=6
注意:版本号是字符串而不是整型:
snprintf(magic,sizeof(magic),“REDIS%04d”,RDB_VERSION);
RDB_VERSION 详细信息可参考:Redis RDB Version History
Body
DB Selector
FE 开头表示后跟表示 DB Selector,例如:
FE 00 #FE 表明数据库的哪个 db,此处为 db0
注意:DB Selector 长度不固定,具体的编码方式请参见后文的 Length 编码。
AUX Fields
FA 开头表示后跟 AUX Fields, 记录生成 Dump 文件的 Redis 相关信息,例如 redis-ver、redis-bits、used-mem、aof-preamble 和 repl-id 等。这些信息采用 String 编码;
注意:redis3.0 版本的 RDB 版本号为 6,redis3.2 的版本号为 7;
Key-Value
key-value 有三种格式:
- expire 为 second
FD $unsigned int #失效时间(秒),4 个字节
$value-type #1 个字节,表明数据类型:set,map 等
$string-encoded-key #key 值,字符串类型
$encoded-value #value, 编码方式和类型有关
- expire 为 millisecond
FC $unsigned long #失效时间(毫秒),8 个字节
$value-type #数据类型,1 个字节
$string-encoded-key #key,字符串类型
$encoded-value #value, 编码方式和类型有关
- 无 expire
$value-type #数据类型,1 个字节
$string-encoded-key #key,字符串类型
$encoded-value #value, 编码方式和类型有关
Footer
FF #RDB 文件的结束
8byte checksum #循环冗余校验码,Redis 采用 crc-64-jones 算法,初始值为 0
编码算法说明
Length 编码
长度采用 BigEndian 格式存储,为无符号整数
- 如果以"00"开头,那么接下来的 6 个 bit 表示长度;
- 如果以“01”开头,那么接下来的 14 个 bit 表示长度;
- 如果以"10"开头,该 byte 的剩余 6bit 废弃,接着读入 4 个 bytes 表示长度 (BigEndian);
- 如果以"11"开头,那么接下来的 6 个 bit 表示特殊的编码格式,一般用来存储数字:
- 0 表示用接下来的 1byte 表示长度
- 1 表示用接下来的 2bytes 表示长度;
- 2 表示用接下来的 4bytes 表示长度;
String 编码
该编码方式首先采用 Length 编码 进行解析:
-
从上面的Length 编码知道,如果以"00",“01”,"10"开头,首先读取长度;然后从接下来的内容中读取指定长度的字符;
-
如果以"11"开头,而且接下来的 6 个字节为“0”、“1”和“2”, 那么直接读取接下来的 1,2,4bytes 做为字符串的内容(实际上存储的是数字,只不过按照字符串的格式存储);
-
如果以“11”开头,而且接下来的 6 个字节为"3", 表明采用 LZF 压缩字符串格式:
LZF 编码的解析步骤为: -
首先采用Length 编码读取压缩后字符串的长度 clen;
-
接着采用Length 编码读取压缩前的字符串长度;
-
读取 clen 长度的字节,并采用 lzf 算法解压得到原始的字符串
Score 编码
- 读取 1 个字节,如果为 255,则返回负无穷;
- 如果为 254,返回正无穷;
- 如果为 253,返回非数字;
- 否则,将该字节的值做为长度,读取该长度的字节,将结果做为分值;
Value 编码
Redis 中的 value 编码包括如下类型:
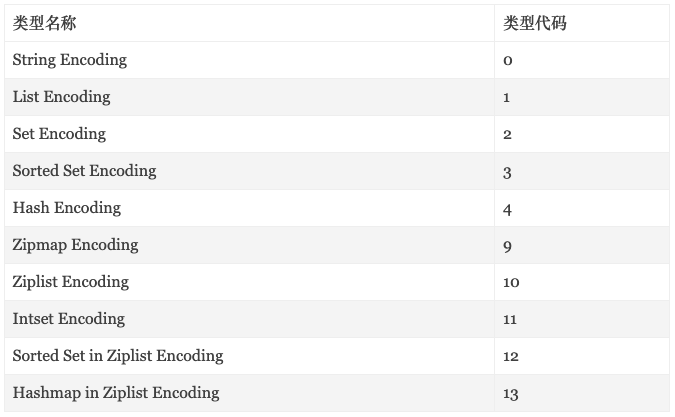
其中 String 编码在前面已经介绍过,接下来逐一介绍其他的 9 种编码方式;
List
首先用 Length 编码读取 List 的长度 lsize;
采用 String 编码读取 lsize 个字符串
Set
同 List
Sorted Set
首先用 Length 编码读取 Sorted Set 的长度 zsize;
采用 String 编码读取字符串,采用 Score 编码读取分值;
循环读取 zsize 次;
Hash
采用 Length 编码读取 Hash 的大小 hsize;
采用 String 编码读取 2*hsize 的字符串,按照 key,value 的方式组装成 Map
Zipmap
用于存储 hashmap,Redis2.6 之后,该编码被废弃,转而采用 Ziplist 编码;
采用 String 编码读取整个 zipmap 字符串,hashmap 字符串的格式为:
<zmlen><len>"foo"<len><free>"bar"<len>"hello"<len><free>"world"<zmend>
- zmlen: 一个字节,Zipmap 的大小;如果>=254, 意味着 zipmap 的大小无法直接获取到,必须要遍历整个 zipmap 才能得到大小;
- len: 字符串长度,1 或 5 个字节长度;如果第一个字节在 0~252 之间,那么长度为第一个字节;如果为 253, 那么接下来的 4 个字节表示长度;254 和 255 是无效值;
- free:1 字节,表明 value 空闲的字节数;
- zmend:0xff, 表示 Zipmap 的结尾;
Ziplist
采用 String 编码读取整个 ziplist 字符串,字符串的格式为:
<zlbytes><zltail><zllen><entry><entry><zlend>
- zlbytes:4 字节无符号整数,表示 ziplist 占用的总字节数;
- zltail:4 字节无符号整数 (little endian), 表示尾元素的偏移量;
- zllen:2 字节无符号整数 (little endian), 表示 ziplist 中的元素个数,当元素个数大于 65535 时,无法用 2 字节表示,需要遍历列表获取元素个数;
- entry:ziplist 中的元素;
- zlend: 常量 (0xff), 表示 ziplist 的结尾;
entry 的格式:
<length-prev-entry><encoding><content>
- lenth-prev-entry: 如果第一个字节<254, 则用 1bytes 表示长度;否则则用接下来的 4bytes(无符号整数)表示长度;
- encoding
- "00"开头:字符串,用接下来的 6bit 表示长度;
- "01"开头:字符串,用接下来的 14bit 表示长度;
- "10"开头:字符串,忽略本字节的 6bit, 用接下来的 32bit 表示长度;
- "11000000"开头:整数,内容为接下来的 16bit;
- "11010000"开头:整数,内容为接下来的 32bit;
- "11100000"开头:整数,内容为接下来的 64bit;
- "11110000"开头:整数,内容为接下来的 24bit;
- "11111110"开头:整数,内容为接下来的 8bit;
- "1111"开头 :整数,内容为接下来的 4bit 的值减去 1;
- content
entry 内容,它的长度通过前面的 encoding 确定;
注意:元素长度、内容长度等都是采用 Little Endian 编码;
Intset
Intset 是一个整数组成的二叉树;当 set 的所有元素都是整形的时候,Redis 会采用该编码进行存储;Inset 最大可以支持 64bit 的整数,做为优化,如果整数可以用更少的字节数表示,Redis 可能会用 16~32bit 来表示;注意的是当插入一个长度不一样的整数时,有可能会引起整个存储结构的变化;
由于 Intset 是一个二叉树,因此它的元素都是排序过的;
采用 String 编码读取整个 intset 字符串,字符串的格式为:
<encoding><length-of-contents><contents>
- encoding:32bit 的无符号整数;可选值包括 2、4 和 8;表示 inset 中的每个整数占用的字节数;
- length-of-contents:32bit 无符号整数,表示 Intset 中包含的整数个数;
- contents: 整数数组,长度由 length-of-contents 决定;
Sorted Set in Ziplist Encoding
采用 Ziplist 编码,区别在于用两个 entry 分别表示元素和分值;
Hashmap in Ziplist Encoding
采用 Ziplist 编码,区别在于用两个 entry 分别表示 key 和 value;
实际例子
本篇文章在本地安装并启动 Redis 服务,保存一个 string 类型的字符串,save 之后查看保存的 rdb 文件的二进制。
-
安装、启动 Redis
-
下载见:Redis Download
-
启动 Redis server:
src/redis-server&
- 启动一个 Redis client:
src/redis-cli
- 保存字符串
127.0.0.1:6379> set name yano
OK
- 保存 RDB 文件
127.0.0.1:6379> save
80277:M 15 Feb 2022 10:51:07.308 * DB saved on disk
OK
在刚执行 redis-cli 的目录下,就生成了 rdb 文件,文件名是 dump.rdb。
分析 RDB 文件
使用 hexedit 命令分析 dump.rdb 文件:
hexedit dump.rdb
dump.rdb 文件内容如下:

本篇文章只是分析 rdb 文件的基本结构和格式,只保存了一个最基础的 string。(图画了一个小时😁)RDB 这块的 Redis 源码就不分析了,基本上都是按照这个结构来的。