
Redis 源码简洁剖析5—quicklist 和 listpack原创
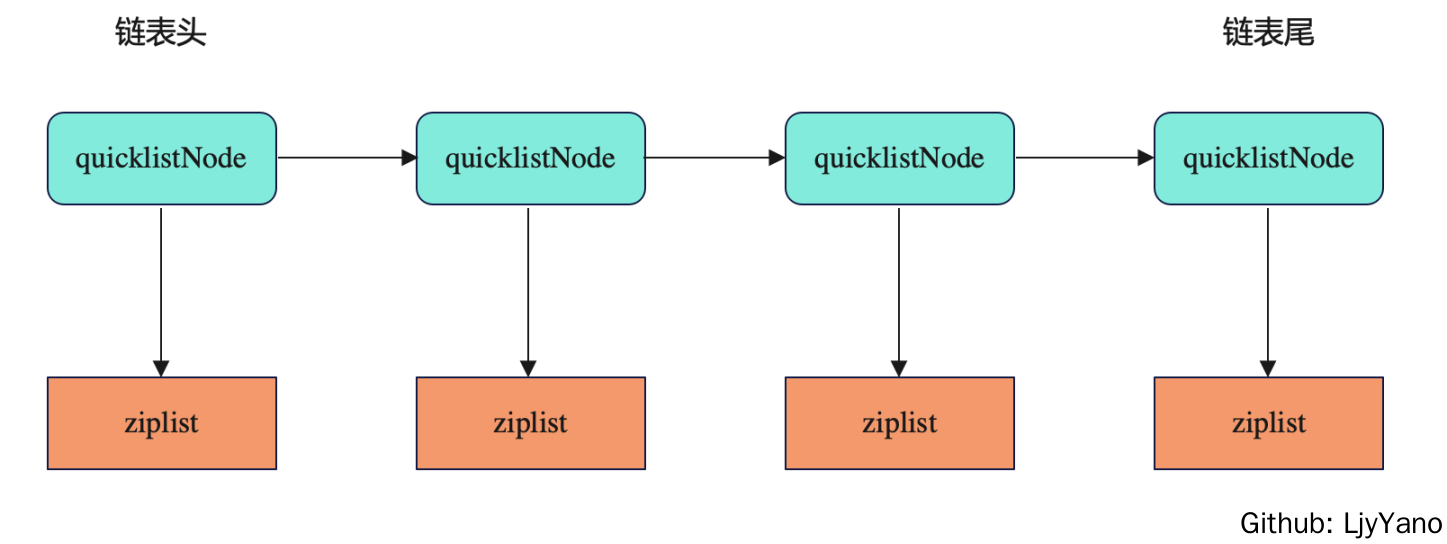
quicklist
为什么要设计 quicklist
ziplist 有两个问题,参考 Redis 源码简洁剖析 05 - ziplist 压缩列表:
- 不能保存过多的元素,否则访问性能会下降
- 不能保存过大的元素,否则容易导致内存重新分配,甚至引起连锁更新
特点
quicklist 的设计,其实是结合了链表和 ziplist 各自的优势。简单来说,一个 quicklist 就是一个链表,而链表中的每个元素又是一个 ziplist。
- 结构定义:quicklist.h
- 实现:quicklist.c
数据结构
quicklist 是一个链表,所以每个 quicklistNode 中,都包含了分别指向它前序和后序节点的指针* prev 和* next。同时,每个 quicklistNode 又是一个 ziplist,所以,在 quicklistNode 的结构体中,还有指向 ziplist 的指针* zl。
每个元素节点 quicklistNode 的定义如下:
typedef struct quicklistNode {
// 前一个 quicklistNode
struct quicklistNode *prev;
// 后一个 quicklistNode
struct quicklistNode *next;
// quicklistNode 指向的 ziplist
unsigned char *zl;
// ziplist 的字节大小
unsigned int sz;
// ziplist 的元素个数
unsigned int count: 16;
// 编码方式,『原生字节数组』或「压缩存储」
unsigned int encoding: 2;
// 存储方式,NONE==1 or ZIPLIST==2
unsigned int container: 2;
// 数据是否被压缩
unsigned int recompress: 1;
// 数据能否被压缩
unsigned int attempted_compress: 1;
// 预留的 bit 位
unsigned int extra: 10;
} quicklistNode;
quicklist 的结构体定义如下:
typedef struct quicklist {
// quicklist 的链表头
quicklistNode *head;
// quicklist 的链表尾
quicklistNode *tail;
// 所有 ziplist 中的总元素个数
unsigned long count;
// quicklistNodes 的个数
unsigned long len;
……
} quicklist;
typedef struct quicklistEntry {
const quicklist *quicklist;
quicklistNode *node;
unsigned char *zi;
unsigned char *value;
long long longval;
unsigned int sz;
int offset;
} quicklistEntry;
quicklistCreate
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2;
quicklist->bookmark_count = 0;
return quicklist;
}
quicklistDelIndex
REDIS_STATIC int quicklistDelIndex(quicklist *quicklist, quicklistNode *node,
unsigned char **p) {
int gone = 0;
// 在该节点下的 ziplist 中删除
node->zl = ziplistDelete(node->zl, p);
// count-1
node->count--;
// ziplist 数量为空,直接删除该节点
if (node->count == 0) {
gone = 1;
__quicklistDelNode(quicklist, node);
} else {
quicklistNodeUpdateSz(node);
}
// 更新所有 ziplist 中的总元素个数
quicklist->count--;
return gone ? 1 : 0;
}
quicklistDelEntry
核心还是调用了 quicklistDelIndex,但是 quicklistDelEntry 要维护 quicklistNode 的节点,包括迭代器。
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry) {
quicklistNode *prev = entry->node->prev;
quicklistNode *next = entry->node->next;
int deleted_node = quicklistDelIndex((quicklist *)entry->quicklist,
entry->node, &entry->zi);
iter->zi = NULL;
// 如果当前节点被删除,更新 iterator
if (deleted_node) {
if (iter->direction == AL_START_HEAD) {
iter->current = next;
iter->offset = 0;
} else if (iter->direction == AL_START_TAIL) {
iter->current = prev;
iter->offset = -1;
}
}
}
quicklistInsertBefore, quicklistInsertAfter
插入分为两种:
void quicklistInsertAfter(quicklist *quicklist, quicklistEntry *node,
void *value, const size_t sz);
void quicklistInsertBefore(quicklist *quicklist, quicklistEntry *node,
void *value, const size_t sz);
其底层都调用了_quicklistInsert 函数:
void quicklistInsertBefore(quicklist *quicklist, quicklistEntry *entry,
void *value, const size_t sz) {
_quicklistInsert(quicklist, entry, value, sz, 0);
}
void quicklistInsertAfter(quicklist *quicklist, quicklistEntry *entry,
void *value, const size_t sz) {
_quicklistInsert(quicklist, entry, value, sz, 1);
}
_quicklistInsert 函数比较长,但是逻辑很简单,就是判断应该在哪里插入新元素:
在后面插入
- 当前 entry 的 ziplist 未满:直接插入
- 当前 entry 的 ziplist 已满:
- entry->next 的 ziplist 未满:在其头部插入
- entry->next 的 ziplist 已满:拆分当前 entry
在前面插入
- 当前 entry 的 ziplist 未满:直接插入
- 当前 entry 的 ziplist 已满:
- entry->prev 的 ziplist 未满:在其尾部插入
- entry->prev 的 ziplist 已满:拆分当前 entry
REDIS_STATIC void _quicklistInsert(quicklist *quicklist, quicklistEntry *entry,
void *value, const size_t sz, int after) {
int full = 0, at_tail = 0, at_head = 0, full_next = 0, full_prev = 0;
int fill = quicklist->fill;
quicklistNode *node = entry->node;
quicklistNode *new_node = NULL;
assert(sz < UINT32_MAX); /* TODO: add support for quicklist nodes that are sds encoded (not zipped) */
……
/* Populate accounting flags for easier boolean checks later */
if (!_quicklistNodeAllowInsert(node, fill, sz)) {
full = 1;
}
// 在后面插入 && 当前 entry 的 ziplist 已满
if (after && (entry->offset == node->count)) {
at_tail = 1;
// 判断 next 节点是否可插入
if (!_quicklistNodeAllowInsert(node->next, fill, sz)) {
full_next = 1;
}
}
// 在前面插入 && 在头部
if (!after && (entry->offset == 0)) {
at_head = 1;
if (!_quicklistNodeAllowInsert(node->prev, fill, sz)) {
full_prev = 1;
}
}
/* Now determine where and how to insert the new element */
// 在尾部插入 && 当前节点能插入
if (!full && after) {
D("Not full, inserting after current position.");
quicklistDecompressNodeForUse(node);
unsigned char *next = ziplistNext(node->zl, entry->zi);
if (next == NULL) {
node->zl = ziplistPush(node->zl, value, sz, ZIPLIST_TAIL);
} else {
node->zl = ziplistInsert(node->zl, next, value, sz);
}
node->count++;
quicklistNodeUpdateSz(node);
quicklistRecompressOnly(quicklist, node);
} else if (!full && !after) {
// 在前面插入 && 当前节点能插入
// 直接在当前节点插入即可
D("Not full, inserting before current position.");
quicklistDecompressNodeForUse(node);
node->zl = ziplistInsert(node->zl, entry->zi, value, sz);
node->count++;
quicklistNodeUpdateSz(node);
quicklistRecompressOnly(quicklist, node);
} else if (full && at_tail && node->next && !full_next && after) {
// 在后面插入 && 在 ziplist 尾部插入 && 当前节点不能插入 && next 节点能插入
// 在 next 节点的头部插入
D("Full and tail, but next isn't full; inserting next node head");
new_node = node->next;
quicklistDecompressNodeForUse(new_node);
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_HEAD);
new_node->count++;
quicklistNodeUpdateSz(new_node);
quicklistRecompressOnly(quicklist, new_node);
} else if (full && at_head && node->prev && !full_prev && !after) {
// 在前面插入 && 在 ziplist 头部插入 && 当前节点不能插入 && prev 节点能插入
// 在 prev 节点的尾部插入
D("Full and head, but prev isn't full, inserting prev node tail");
new_node = node->prev;
quicklistDecompressNodeForUse(new_node);
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_TAIL);
new_node->count++;
quicklistNodeUpdateSz(new_node);
quicklistRecompressOnly(quicklist, new_node);
} else if (full && ((at_tail && node->next && full_next && after) ||
(at_head && node->prev && full_prev && !after))) {
// 当前节点不能插入 && 不能在前后节点插入
// 创建新节点
D("\tprovisioning new node...");
new_node = quicklistCreateNode();
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
new_node->count++;
quicklistNodeUpdateSz(new_node);
__quicklistInsertNode(quicklist, node, new_node, after);
} else if (full) {
// 节点是满的,需要将当前节点的 ziplist 拆分
D("\tsplitting node...");
quicklistDecompressNodeForUse(node);
new_node = _quicklistSplitNode(node, entry->offset, after);
new_node->zl = ziplistPush(new_node->zl, value, sz,
after ? ZIPLIST_HEAD : ZIPLIST_TAIL);
new_node->count++;
quicklistNodeUpdateSz(new_node);
__quicklistInsertNode(quicklist, node, new_node, after);
_quicklistMergeNodes(quicklist, node);
}
quicklist->count++;
}
其余方法就不一一展开了,大同小异。
listpack
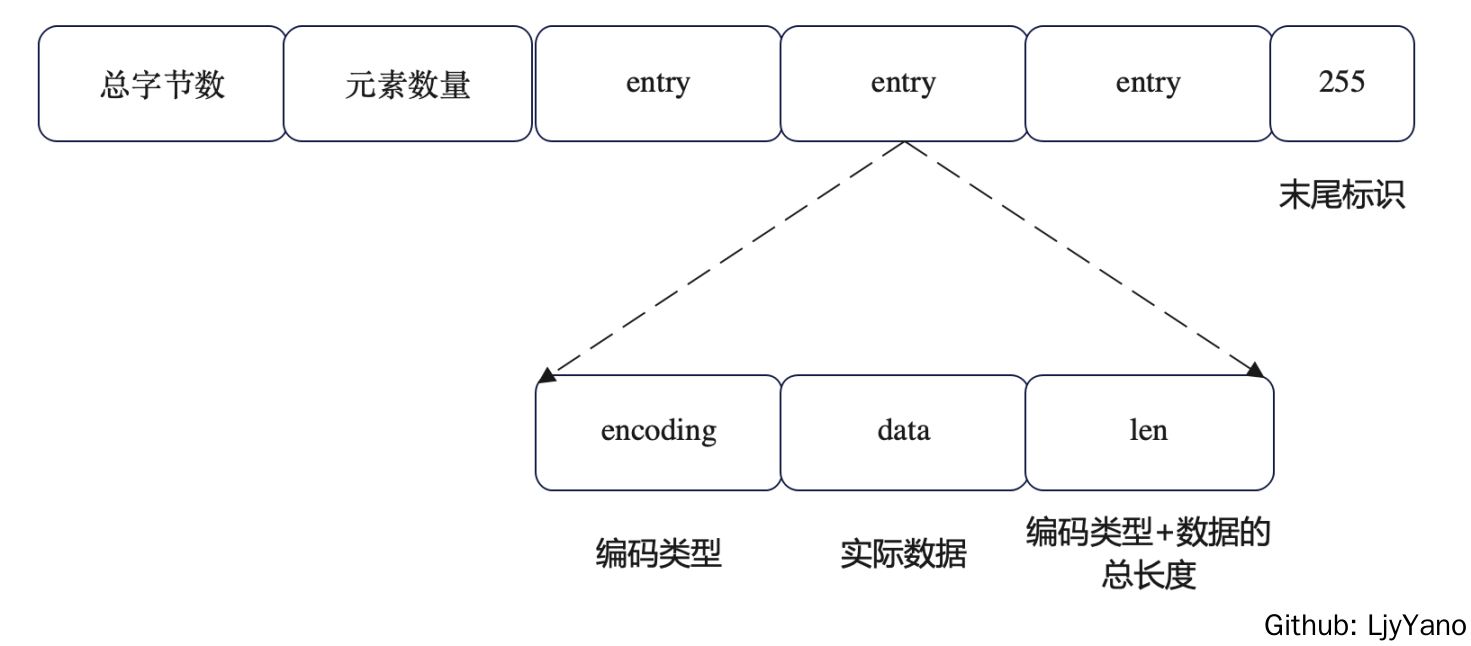
是什么
紧凑列表,用一块连续的内存空间来紧凑保存数据,同时使用多种编码方式,表示不同长度的数据(字符串、整数)。
结构定义:listpack.h
实现:listpack.c
数据结构
编码类型
在 listpack.c 文件中,有大量的 LP_ENCODING__XX_BIT_INT 和 LP_ENCODING__XX_BIT_STR 的宏定义:
#define LP_ENCODING_7BIT_UINT 0
#define LP_ENCODING_7BIT_UINT_MASK 0x80
#define LP_ENCODING_IS_7BIT_UINT(byte) (((byte)&LP_ENCODING_7BIT_UINT_MASK)==LP_ENCODING_7BIT_UINT)
#define LP_ENCODING_6BIT_STR 0x80
#define LP_ENCODING_6BIT_STR_MASK 0xC0
#define LP_ENCODING_IS_6BIT_STR(byte) (((byte)&LP_ENCODING_6BIT_STR_MASK)==LP_ENCODING_6BIT_STR)
……
listpack 元素会对不同长度的整数和字符串进行编码。
整数编码
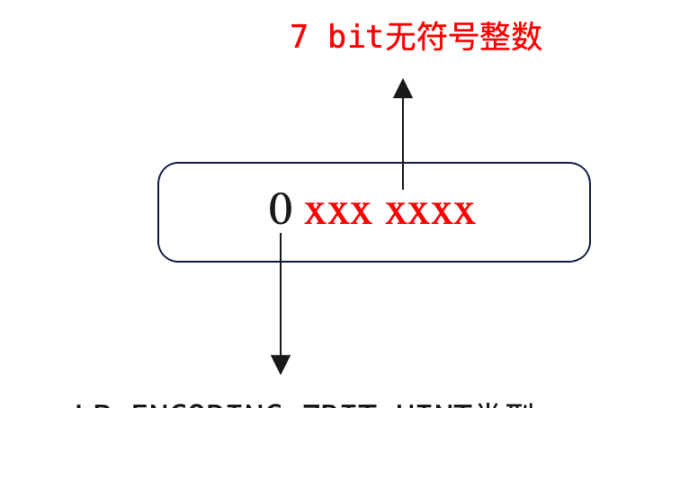
以 LP_ENCODING_7BIT_UINT 为例,元素的实际数据是一个 7 bit 的无符号整数。
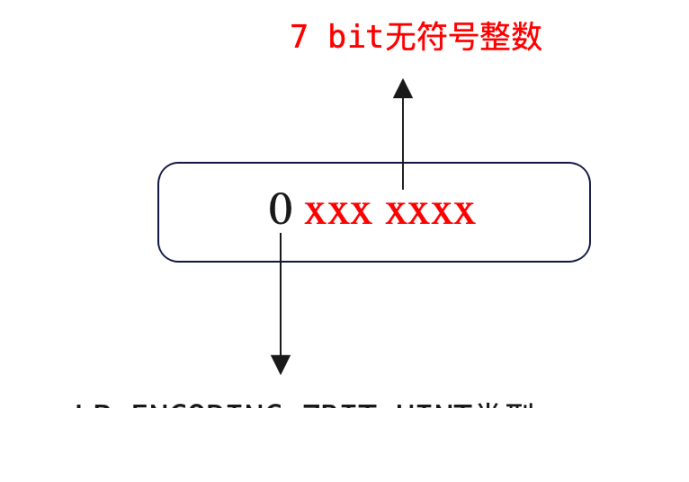
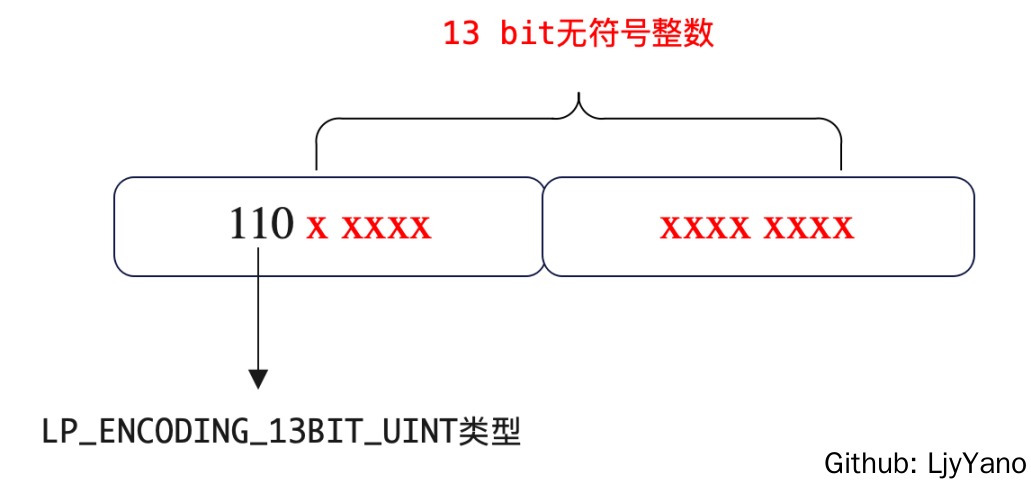
对于 LP_ENCODING_13BIT_INT,元素实际数据的表示位数是 13 位,最高 3 位是 110,表示当前的编码类型。
#define LP_ENCODING_13BIT_INT 0xC0
#define LP_ENCODING_13BIT_INT_MASK 0xE0
#define LP_ENCODING_IS_13BIT_INT(byte) (((byte)&LP_ENCODING_13BIT_INT_MASK)==LP_ENCODING_13BIT_INT)
整数其余的编码方式有:
- LP_ENCODING_16BIT_INT
- LP_ENCODING_24BIT_INT
- LP_ENCODING_32BIT_INT
- LP_ENCODING_64BIT_INT
字符串编码
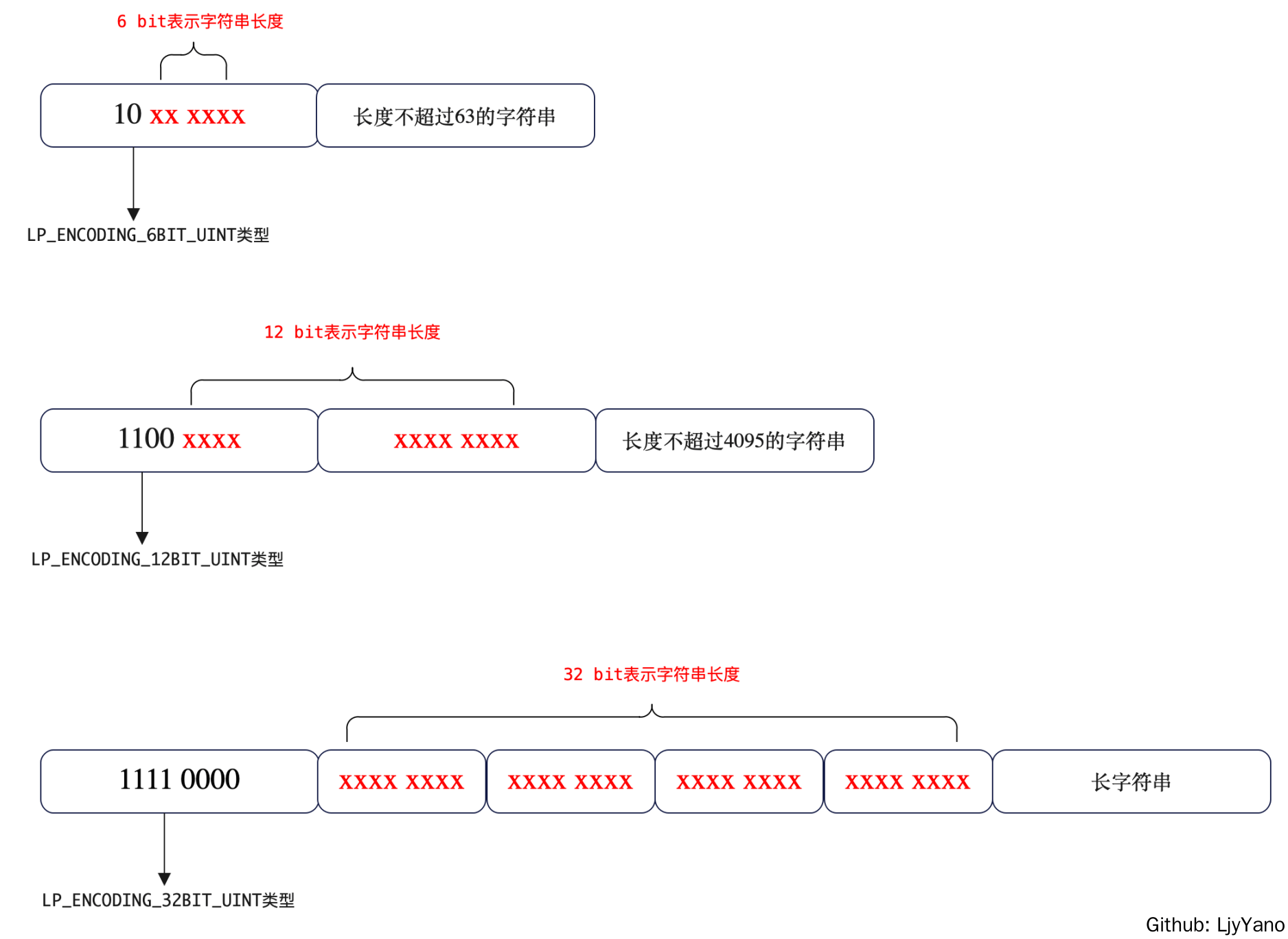
3 种类型:
- LP_ENCODING_6BIT_STR
- LP_ENCODING_12BIT_STR
- LP_ENCODING_32BIT_STR
以编码类型 LP_ENCODING_6BIT_STR 为例,编码类型占 1 个字节。这 1 个字节包括两个部分:
- 宏定义 2 位,标识编码类型
- 后 6 位保存字符串长度
如何避免连锁更新?
每个列表项都只记录自己的长度,不会像 ziplist 的列表项会记录前一项的长度。所以在 listpack 中新增或修改元素,只会涉及到列表项自身的操作,不会影响后续列表项的长度变化,进而避免连锁更新。
lpNew
unsigned char *lpNew(size_t capacity) {
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
// 设置 listpack 的大小
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
// 设置 listpack 的元素个数,初始是 0
lpSetNumElements(lp,0);
// 设置 listpack 的结尾标识符 LP_EOF,值是 255
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}
#define lpSetTotalBytes(p,v) do { \
(p)[0] = (v)&0xff; \
(p)[1] = ((v)>>8)&0xff; \
(p)[2] = ((v)>>16)&0xff; \
(p)[3] = ((v)>>24)&0xff; \
} while(0)
#define lpSetNumElements(p,v) do { \
(p)[4] = (v)&0xff; \
(p)[5] = ((v)>>8)&0xff; \
} while(0)
lpFirst
获取 listpack 的第一个元素。
/* Return a pointer to the first element of the listpack, or NULL if the
* listpack has no elements. */
unsigned char *lpFirst(unsigned char *lp) {
// 跳过 listpack 的头部 6 字节
unsigned char *p = lp + LP_HDR_SIZE; /* Skip the header. */
// 若是末尾结束字节,返回 NULL
if (p[0] == LP_EOF) return NULL;
lpAssertValidEntry(lp, lpBytes(lp), p);
return p;
}
lpNext
/* If 'p' points to an element of the listpack, calling lpNext() will return
* the pointer to the next element (the one on the right), or NULL if 'p'
* already pointed to the last element of the listpack. */
unsigned char *lpNext(unsigned char *lp, unsigned char *p) {
……
// 偏移指针指向下一个列表项
p = lpSkip(p);
if (p[0] == LP_EOF) return NULL;
……
return p;
}
核心是调用了 lpSkip 函数:
unsigned char *lpSkip(unsigned char *p) {
// 计算当前 entry 编码类型和实际数据的总长度
unsigned long entrylen = lpCurrentEncodedSizeUnsafe(p);
entrylen += lpEncodeBacklen(NULL,entrylen);
// 偏移指针
p += entrylen;
return p;
}
lpSkip 核心是调用了 lpCurrentEncodedSizeUnsafe 函数获取当前 entry 的总长度:
uint32_t lpCurrentEncodedSizeUnsafe(unsigned char *p) {
// LP_ENCODING_IS_7BIT_UINT,编码类型和整数数值都在同一个字节,所以返回 1
if (LP_ENCODING_IS_7BIT_UINT(p[0])) return 1;
// LP_ENCODING_IS_6BIT_STR,1 字节表示编码类型和字符串长度,该字节后 6 位表示字符串长度
if (LP_ENCODING_IS_6BIT_STR(p[0])) return 1+LP_ENCODING_6BIT_STR_LEN(p);
if (LP_ENCODING_IS_13BIT_INT(p[0])) return 2;
if (LP_ENCODING_IS_16BIT_INT(p[0])) return 3;
if (LP_ENCODING_IS_24BIT_INT(p[0])) return 4;
if (LP_ENCODING_IS_32BIT_INT(p[0])) return 5;
if (LP_ENCODING_IS_64BIT_INT(p[0])) return 9;
if (LP_ENCODING_IS_12BIT_STR(p[0])) return 2+LP_ENCODING_12BIT_STR_LEN(p);
if (LP_ENCODING_IS_32BIT_STR(p[0])) return 5+LP_ENCODING_32BIT_STR_LEN(p);
if (p[0] == LP_EOF) return 1;
return 0;
}
大同小异,这里只介绍下 LP_ENCODING_IS_6BIT_STR,1 字节表示编码类型和字符串长度,该字节后 6 位表示字符串长度。使用 LP_ENCODING_6BIT_STR_LEN 宏定义计算后 6 位的数值。
#define LP_ENCODING_6BIT_STR_LEN(p) ((p)[0] & 0x3F)
lpSkip 函数还调用了 lpEncodeBacklen 函数,计算 entry 最后一部分 len 的长度(即下图中的 len)。
unsigned long lpEncodeBacklen(unsigned char *buf, uint64_t l) {
//编码类型和实际数据的总长度小于等于 127,entry-len 长度为 1 字节
if (l <= 127) {
...
return 1;
} else if (l < 16383) { //编码类型和实际数据的总长度大于 127 但小于 16383,entry-len 长度为 2 字节
...
return 2;
} else if (l < 2097151) {//编码类型和实际数据的总长度大于 16383 但小于 2097151,entry-len 长度为 3 字节
...
return 3;
} else if (l < 268435455) { //编码类型和实际数据的总长度大于 2097151 但小于 268435455,entry-len 长度为 4 字节
...
return 4;
} else { //否则,entry-len 长度为 5 字节
...
return 5;
}
}
lpPrev
unsigned char *lpPrev(unsigned char *lp, unsigned char *p) {
assert(p);
// 如果是第一项,直接返回 NULL
if (p-lp == LP_HDR_SIZE) return NULL;
p--; /* Seek the first backlen byte of the last element. */
uint64_t prevlen = lpDecodeBacklen(p);
prevlen += lpEncodeBacklen(NULL,prevlen);
p -= prevlen-1; /* Seek the first byte of the previous entry. */
lpAssertValidEntry(lp, lpBytes(lp), p);
return p;
}
lpGet
就是按照编码类型,然后解析出实际数据所占字节数,进而获取对应数值。
unsigned char *lpGet(unsigned char *p, int64_t *count, unsigned char *intbuf) {
int64_t val;
uint64_t uval, negstart, negmax;
assert(p); /* assertion for valgrind (avoid NPD) */
if (LP_ENCODING_IS_7BIT_UINT(p[0])) {
negstart = UINT64_MAX; /* 7 bit ints are always positive. */
negmax = 0;
uval = p[0] & 0x7f;
} else if (LP_ENCODING_IS_6BIT_STR(p[0])) {
*count = LP_ENCODING_6BIT_STR_LEN(p);
return p+1;
} else if (LP_ENCODING_IS_13BIT_INT(p[0])) {
……
} else if (LP_ENCODING_IS_16BIT_INT(p[0])) {
……
} else if (LP_ENCODING_IS_24BIT_INT(p[0])) {
……
} else if (LP_ENCODING_IS_32BIT_INT(p[0])) {
……
} else if (LP_ENCODING_IS_64BIT_INT(p[0])) {
……
} else if (LP_ENCODING_IS_12BIT_STR(p[0])) {
……
} else if (LP_ENCODING_IS_32BIT_STR(p[0])) {
……
} else {
……
}
/* We reach this code path only for integer encodings.
* Convert the unsigned value to the signed one using two's complement
* rule. */
if (uval >= negstart) {
/* This three steps conversion should avoid undefined behaviors
* in the unsigned -> signed conversion. */
uval = negmax-uval;
val = uval;
val = -val-1;
} else {
val = uval;
}
……
}


