
1 索引简介
1.1 什么是 MySQL 的索引
官方定义:索引是帮助 MySQL 高效获取数据的数据结构
从上面定义中我们可以分析出索引本质是一个数据结构,他的作用是帮助我们高效获取数据,在正式介绍索引前,我们先来了解一下基本的数据结构
2 索引数据结构
2.1 Hash 索引
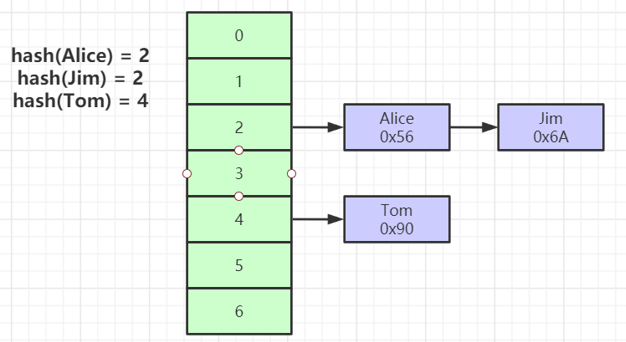
Hash 索引是比较常见的一种索引,他是通过计算出记录对应的 hash 值,然后根据计算结果,存储在对应位置。查询的时候也是根据 hash 值快速找到位置。他的单条记录查询的效率很高,时间复杂度为1。但是,Hash索引并不是最常用的数据库索引类型,尤其是我们常用的Mysql Innodb引擎就是不支持hash索引的。
hash 索引在等值查询时速度很快,但是有以下两个问题
- 不支持范围查询
- hash 冲突,当两条记录的 hash 值相同时,就产生了 hash 冲突,需要在后面用链表存储起来
2.2 二叉树
2.2.1 经典二叉树
1、一个节点只能有两个子节点
2、左子节点的值小于父亲节点值,右子节点的值大于父亲节点的值,采用二分查找,速度较快
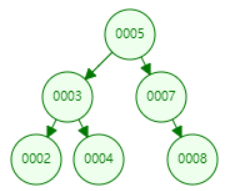
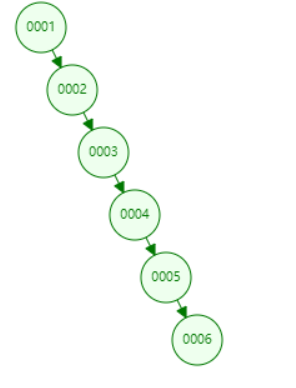
经典二叉树会出现一个极端例子,就是链表,节点数据越来越大。这种情况下,二叉树搜索性能就会降低
2.2.2 平衡二叉树
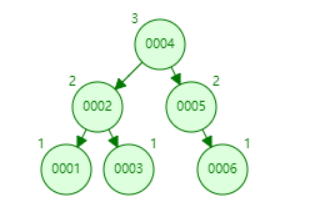
平衡二叉树又称AVL树。它可以是一颗空树,或者具有以下性质的二叉排序树:
- 它的左子树和右子树的高度之差(平衡因子)的绝对值不超过1
- 它的左子树和右子树都是一颗平衡二叉树。
数字 1-6 在平衡二叉树中图示如下:
2.3 B 树
B树属于多叉树又名平衡多路查找树,可以有多叉,有如下特点
(1)排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
(2)子节点数:非叶节点(根节点和枝节点)的子节点数 >1、且子节点数量<=M 、且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
(3)关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
(4)所有叶子节点均在同一层、叶子节点除了包含了关键字 和 关键字记录的指针外,也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子;
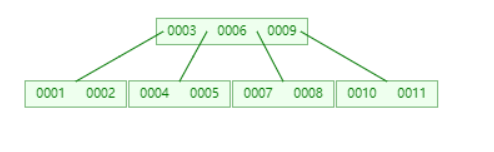
MySQL 中 B 树存储结构如下:
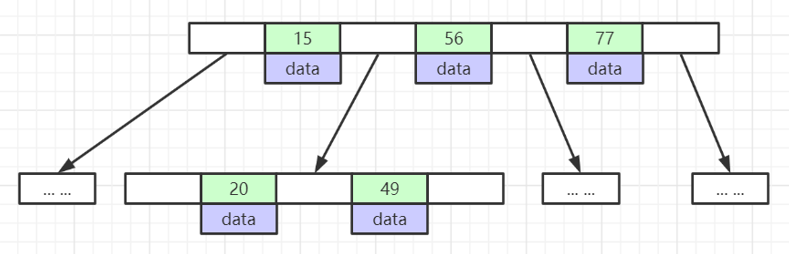
2.4 B+ 树
B+树是在B树的基础上又一次的改进,其主要对两个方面进行了提升,一方面是查询的稳定性,另外一方面是在数据排序方面更友好。MySQL 索引的底层数据结构采用的就是 B+ 树
(1)B+树的非叶子节点不保存具体的数据,而只保存关键字的索引,而所有的数据最终都会保存到叶子节点。因为所有数据必须要到叶子节点才能获取到,所以每次数据查询的次数都一样,这样一来B+树的查询速度也就会比较稳定,而B树的查找过程中,不同的关键字查找的次数很有可能都是不同的(有的数据可能在根节点,有的数据可能在最下层的叶节点),所以在数据库的应用层面,B+树就显得更合适。
(2)B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。因为叶子节点都是有序排列的,所以B+树对于数据的排序有着更好的支持。
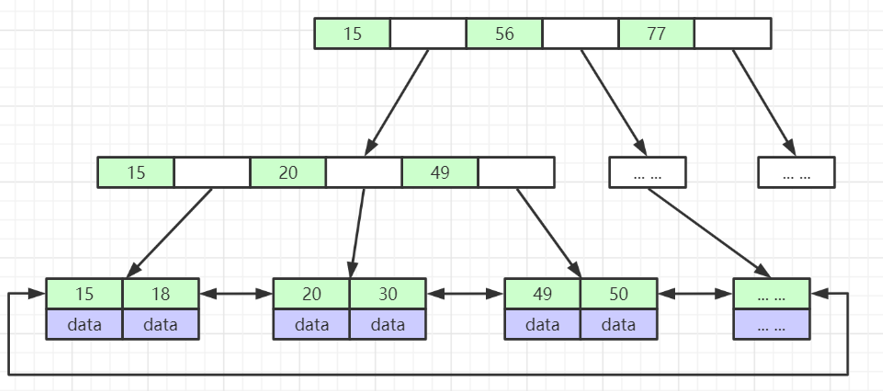
2.5 B* 树
B树是B+树一种变形,它是在B+树的基础上,将索引层以指针连接起来(B+ 树只是将数据层用指针连接起来),使搜索取值更加快捷
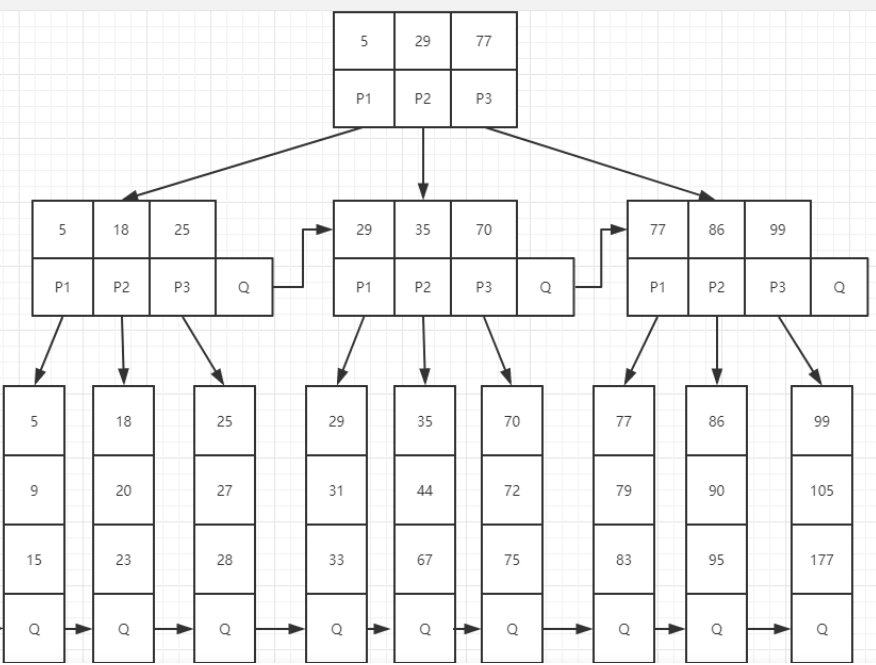
总结
分析了以上几种数据结构,MySQL 采用的是 B+ 树来存储索引,综合层面来说,这样查询效率最好。oracle 采用的是 B* 树
3 索引分类
MySQL 索引主要有以下几种
- 主键索引
- 唯一索引
- 普通索引
- 组合索引
- 全文索引
3.1 主键索引
主键索引是比较特殊的索引,一般在建表时会给表设置一个主键,MySQL 会默认给这个主键加上索引。主键索引叶子节点存储的是数据表的某一行数据。当表没有创建主键索引是,InnDB 会自动创建一个 ROWID 字段用于构建聚簇索引。规则如下:
- 在表上定义主键 PRIMARY KEY,InnoDB 将主键索引用作聚簇索引。
- 如果表没有定义主键,InnoDB 会选择第一个不为 NULL 的唯一索引列用作聚簇索引。
- 如果以上两个都没有,InnoDB 会使用一个 6 字节长整型的隐式字段 ROWID 字段构建聚簇索引。该 ROWID 字段会在插入新行时自动递增。
创建方式:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`name` varchar(255) NOT NULL ,
PRIMARY KEY (`id`)
);
为什么建表时没有指定主键,MySQL 会默认使用一个隐式字段 ROWID 字段构建聚簇索引?这个在后面我们会提到
3.2 唯一索引
与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
创建方式
CREATE UNIQUE INDEX indexName ON user(column)
或者
ALTER TABLE table_name ADD UNIQUE indexName ON (column)
3.3 普通索引
MySQL 基本的索引,没有什么限制
创建方式:
CREATE INDEX index_name ON user(column)
或者
ALTER TABLE user ADD INDEX index_name ON (column)
3.4 组合索引
组合索引,顾名思义,给 MySQL 多个字段同时加上索引,在使用时要遵循最左匹配原则
创建方式:
CREATE INDEX index_name ON user(column1,column2) -- 给 column1 和 column2 加上索引
3.5 全文索引
全文索引,主要用来查找文本中的关键字,不是直接与索引值相比较。与我们常见的搜索引擎(如elasticsearch、solr 等)功能相似。MySQL 全文索引性能一般,所以一般不用,作为了解即可
创建方式:
CREATE FULLTEXT INDEX index_column ON user(column)
或者
ALTER TABLE user ADD FULLTEXT index_column(column)
4 索引设计
4.1 三星索引
三星索引是我们设计 MySQL 索引时的一个规范,符合三星索引的索引设计通常是比较好的设计
一星:索引中查询相关的索引行是相邻的,或者至少相距足够靠近
二星:索引中数据列的顺序和查找中排序顺序相同
三星:索引中的列包含了查询中需要的全部列。索引包含查询所需要的数据列,不再进行全表查表,回表操作
下面举一个例子为大家介绍一下三星索引是什么样子的
现在有一张表,表结构如下
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`age` int(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
一星
我们现在给 age 加上索引
create index idx_age on user (age);
查询
select * from user where age in (10,20,35,43)
这条语句不一定符合一星,因为 age 是一个范围,数据可能比较分散
select * from user where age = 20;
这条语句是符合一星的,因为索引是按照 age 从小到大排序的,所以 age = 20 的数据肯定是在一起的
二星
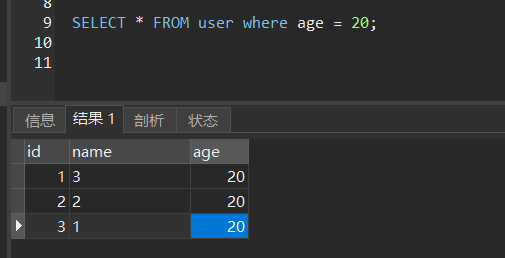
select * from user where age = 20 order by name;
这条语句符合一星,但不符合二星,因为数据列的顺序是按照 age 排序的,如果现在改成 name 排序,可能导致索引顺序与 order by 排序结果不同,结果如下:
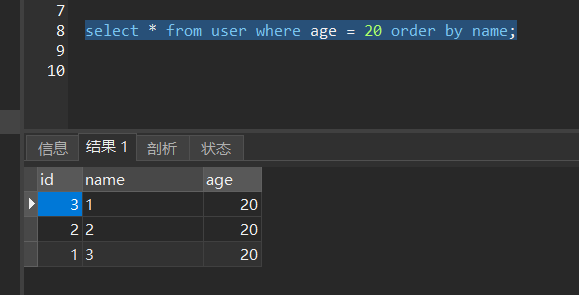
select * from user where age = 20 order by age
这条查询语句则符合一星和二星
三星
select * from user where age = 20
这条语句不符合三星,因为索引列中只有 id 和 age,没有 name
select age from user where age = 20
这条语句则符合三星,因为只查询了 age,age 在索引中存在,不需要回表
4.2 回表
上面三星索引提到了一个次回表,那么回表是什么?
简单点说,就是查询语句中需要的列,在索引中不包含,需要根据主键 id 再查询一次才能获取到。回表相当于多查询一次,再查询时我们要尽量避免回表查询。
因为普通索引中只包含了对应列和主键的值,比如 age 索引,那么 age 索引中包含的数据有 age,id。此时如果需要 name 的话,需要先通过 age 索引找到对应的 id,然后再去主键索引上找到 name,主键索引包含了一行所有记录的值。这里回答了上面的问题,为什么 MySQL 一定要有主键索引,因为主键索引子节点中包含了全部数据
4.3 索引覆盖
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`age` int(1) DEFAULT NULL,
`***` varchar(2) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;
select name,age from user where name = "张三"
-- 这条语句就使用了索引覆盖,因为 name 和 age 再 idx_name_age 索引中都有,不需要回表查询
select name,age,*** from user where name = "张三"
-- 如果加上了 ***,那么就需要回表查询了,因为索引中不存在 *** 字段
5 索引优化
5.1 慢查询
5.1.1 简介
慢查询日志是 MySQL 提供的日志记录,用来记录所有的慢 SQL 语句,我们可以通过设置慢查询的时间阈值 long_query_time,来定义什么样的 SQL 是慢 SQL。通过慢查询日志我们可以找出需要优化的 SQL,下一步就是进行 SQL 优化
5.1.2 慢查询配置
第一步:我们可以通过 show variables like 'slow_query_log' 语句查询慢查询是否开启,默认是关闭(OFF)
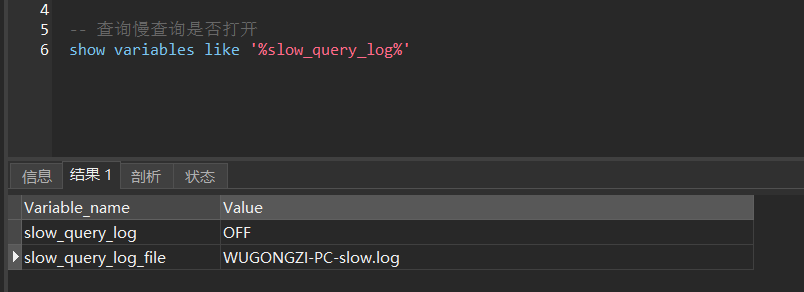
slow_query_log_file 是慢查询日志存放的位置,如果是 window 的话,通常在你的安装文件夹 Data 目录下
第二步:打开慢查询
set global slow_query_log = 1;
第三步:设置慢查询阈值
什么样的查询叫做慢查询呢?1s,5s 还是 10s,这点 MySQL 不知道,所以需要我们通过配置去设置 long_query_time 参数
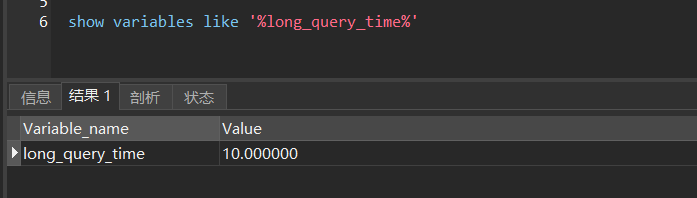
通过命令 show variables like '%long_query_time%' 查看慢查询时间,默认是 10 s
如果需要修改,可以通过命令 set global long_query_time = 5 来设置
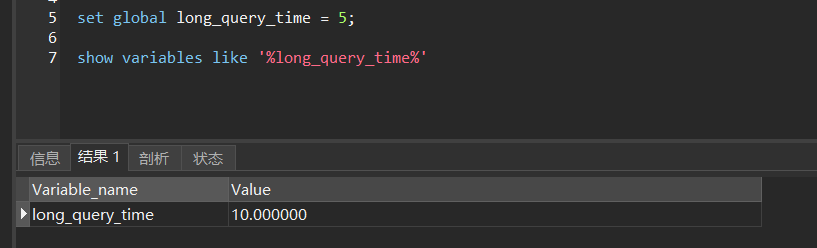
注意:这里通过 set global long_query_time = 5 设置完慢查询时间后,再次查询发现慢查询时间依然是 10s,难道是设置没生效?
使用此命令修改后,需要重新连接或者新开启一个会话就可以看到修改后的配置
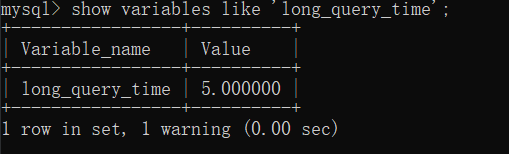
或者通过 show global variables like '%long_query_time%' 命令查看
5.1.3 慢查询日志分析
我们刚才已经将慢查询阈值设置为 5s,现在我们执行一条这样的 sql 语句
select sleep(6);
这条语句执行时间为 6s,我们打开慢查询日志可以发现增加了一些数据
# Time: 2022-10-02T09:16:23.194396Z
# User@Host: root[root] @ localhost [::1] Id: 6
# Query_time: 6.011569 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
SET timestamp=1664675770;
select sleep(6);
我们来逐个分析一下每行代表什么含义:
User@Host:执行该 SQL 的用户和慢查询 IP 地址
Query_time:语句执行时长
Lock_time:获取锁的时长
Rows_sent:MySQL 返回给客户端的行数
Rows_examined:MySQL 扫描行数
timestamp:表示慢 SQL 记录时的时间戳
select sleep(6):则是慢查询 SQL
下面我们来分析一条真实的慢查询 SQL,之前测试时的一条 SQL 语句
# Time: 2022-07-27T09:26:44.440318Z
# User@Host: root[root] @ localhost [127.0.0.1] Id: 249
# Query_time: 68.461112 Lock_time: 0.000938 Rows_sent: 877281 Rows_examined: 877303
SET timestamp=1658914004;
SELECT id,prd_line_id,shift_name,shift_id,app_id,weight,upload_time,operator,status,prd_line_name FROM prd_weight
WHERE (upload_time > '2022-07-27 00:00' AND upload_time < '2022-07-27 17:24');
Query_time:总查询时长 68.461112s
Lock_time:0.000938s
Rows_examined:扫描行 877281
Rows_sent:返回了 877303
当然了,这是测试用的,生产上一般不会出现这么离谱的 SQL 语句
5.1.4 注意事项
- 在 MySQL 中,慢查询日志中默认不记录管理语句,如:
alter table,,****yze table,check table 等。不过可通过以下属性进行设置:
set global log_slow_admin_statements = "ON" - 在 MySQL 中,还可以设置将未走索引的 SQL 语句记录在慢日志查询文件中(默认为关闭状态)。通过下述属性即可进行设置:
set global log_queries_not_using_indexes = "ON" - 在 MySQL 中,日志输出格式有支持:FILE(默认),TABLE 两种,可进行组合使用。如下所示:
set global log_output = "FILE,TABLE"
这样设置会同时在 FILE, MySQL 库中的 slow_log 表中同时写入。但是日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件。
5.2 Explain 执行计划
通过上面的慢查询日志分析,我们可以知道有哪些慢 SQL 语句。但是这些 SQL 具体慢在哪里,需要如何优化,我们还需要更详细的分析计划,这里 MySQL 给我们提供了 Explain 关键字,通过该关键字我们可以分析出 SQL 语句的详细执行信息。
5.2.1 Explain 使用
我们在数据库中创建一张 user 表用于测试
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`password` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`***` varchar(2) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`phone` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`dept_id` int(10) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_name`(`name`) USING BTREE,
INDEX `idx_dept_id`(`dept_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 6 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (1, '张三', '123', '男', '12323432', 1);
INSERT INTO `user` VALUES (2, '李四', '456', '男', '178873937', 1);
INSERT INTO `user` VALUES (3, '小花', '123', '女', '1988334554', 2);
INSERT INTO `user` VALUES (4, '小芳', '334', '女', '18765287937', 2);
INSERT INTO `user` VALUES (5, NULL, '122', NULL, NULL, NULL);
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`dept_name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of dept
-- ----------------------------
INSERT INTO `dept` VALUES (1, '开发部');
INSERT INTO `dept` VALUES (2, '销售部');
explain 使用也很简单,直接在查询语句前面加上 explain 关键字即可:
EXPLAIN SELECT * FROM user where id = 1;

从图中我们看到 MySQL 返回了一行记录,下面我们一起来分析每个字段代表什么含义
| 字段 | 含义 |
|---|---|
| id | 一次查询过程中该条 select 语句的唯一标识 |
| select_type | 查询类型,共包含四种 simple、primary、subquery、derived |
| table | 查询的是哪张表 |
| partitions | 表的分区信息 |
| type | 访问类型,分析性能主要通过该字段 |
| possible_keys | 可能会用到的索引 |
| key | 实际用到的索引 |
| key_len | 索引里使用的字节数 |
| ref | 这一列显示了在key列记录的索引中,表查找值所用到的列或常量 |
| rows | MySQL 预估的扫描行 |
| filtered | MySQL 过滤后,满足条件记录数的比例 |
| Extra | 展示了一些额外信息 |
5.2.2 Explain 详解
1、id
id 是查询语句中的唯一标识,id 的值越大,该 id 对应的 sql 语句越先执行
explain select * from dept where id = (select dept_id from user where id = 1);

从执行计划来看,select dept_id from user where id = 1 这条语句先执行,因为外层查询需要借助这条查询语句的结果
2、select_type
查询类型,共包含四种
simple:简单查询。查询不包含子查询和union

primary:复杂查询中最外层的 select

subquery:包含在 select 中的子查询(不在 from 子句中)

derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
3、table
查询的是哪张表,比较好理解
4、partitions
查询时匹配到的分区信息,对于非分区表值为 NULL,当查询的是分区表时,partitions 显示分区表命中的分区情况。
5、type
type:查询使用了何种类型,它在 SQL优化中是一个非常重要的指标,以下性能从好到坏依次是:system > const > eq_ref > ref > ref_or_null > range > index > ALL
-
system 是 const 的特例,也就是当表中只存在一条记录时,type 为 system
-
const,常量查询,id 是主键,通过 id 可以查询到所有信息
-
eq_ref,连接查询中,primary key 或 unique key 索引的所有部分被连接使用

注意:这里 dept 的 id 和 user 的 id 并无关联关系,只是为了演示该查询类型

user 的 id 和 dept 的 id 都是主键,在连接查询中,两个主键都被使用到
- ref,不使用唯一索引,使用普通索引或者唯一索引,可能会找到多个条件的值,idx_name 是普通索引

- ref_of_null,和 ref 功能类似,区别在于会额外搜索索引包含 NULL 的值,name 字段是普通索引,且数据库中存在 name 为 null 的数据

- range,在索引字段上使用范围查询,常见的有 >、<、in、like 等查询
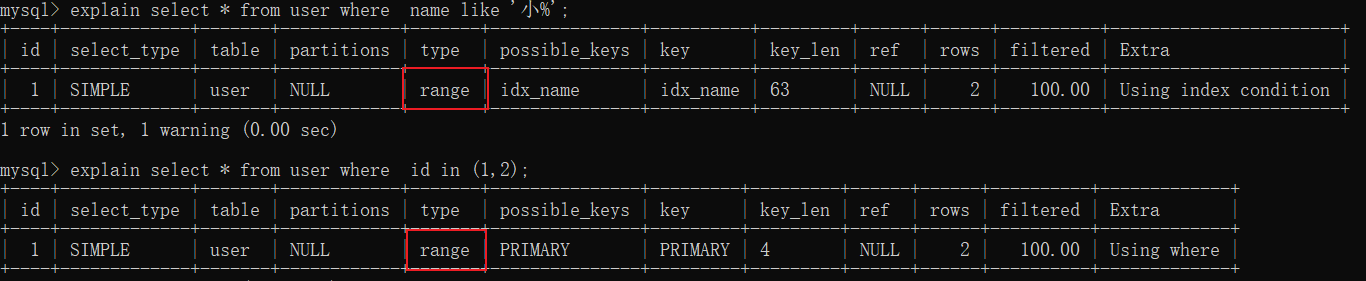
- index,通过索引树进行全表扫描

- ALL,全表扫描,不通过索引树,因为这次是 select * 查询

6、possible_keys
MySQL 分析此次查询可能会用到的索引,但是实际查询中不一定会用到

分析可能会用到 idx_name 这个索引,实际查询中没有用到索引,走的全表扫描
7、key
查询时真正用到的 key

查询中实际上用到了 idx_name 这个索引
8、ken_len
表示查询用到的索引列长度

我们用这个索引来分析,key_len 为 63 是怎么来的?

创建 user 表的时候,不知道大家有没有注意到,name 的字符集为 utf8
MySQL 5.0 版本以上,utf8 字符集下每个字符占用 3 个字节,varchar(20) 则占用 60 个字节,同时因为 varchar 是变长字符串,需要额外地字节存放字符长度,共两个字节,此外,name 字段可以为 null 值,null 值单独占用一个字节,加在一起一共 63 个字节
9、ref
当使用索引列等值匹配的条件去执行查询时,也就是在访问方法是const、eq_ref、ref、ref_or_null、unique_subquery、index_subquery其中之一时,ref列展示的就是与索引列作等值匹配的具体信息,比如只是一个常数或者是某个列。

10、rows
预计需要扫描的函数
11、filtered
filtered 这个是一个百分比的值,表里符合条件的记录数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例。
12、Extra
Extra是用来说明一些额信息的,从而帮助我们更加准确的理解查询
5.3高性能 的索引使用策略
5.3.1 不要在索引列上做任何操作
explain select * from user where left(name,2) = '小芳';

这段 sql 对 name 字段做了函数操作,导致索引失效
5.3.2 最左前缀法则
在使用联合索引查询时,应该遵循最左前缀原则,指的是查询从索引的最左前列开始并且不跳过索引中的列。
创建一张 goods 表,有一个联合索引包含了 name,price、mark 三个字段
DROP TABLE IF EXISTS `goods`;
CREATE TABLE `goods` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`price` int(10) NULL DEFAULT NULL,
`mark` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_all`(`name`, `price`, `mark`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of goods
-- ----------------------------
INSERT INTO `goods` VALUES (1, '手机', 5678, '华为手机');
INSERT INTO `goods` VALUES (2, '电脑', 9888, '苹果电脑');
INSERT INTO `goods` VALUES (3, '衣服', 199, '好看的衣服');
执行下面的查询语句:
explain select * from goods where name = '手机' and price = 5678 and mark = '华为手机';

从上图可以看到 type 为 ref。
现在我们不从最左侧开始查询,直接跳过 name 字段
explain select * from goods where price = 5678 and mark = '华为手机';

type 从 ref 变成了 index,这是因为 MySQL 建立索引时是按照组合索引中的字段顺序来排序的,如果跳过中间某个字段,则不一定是有序的了。
5.3.3 尽量使用覆盖索引
覆盖索引,需要查询的字段全部包含在索引列中,不需要回表查询


