
基于 raft 协议的 RocketMQ DLedger 多副本日志复制设计原理原创
前面已经用源码的手段对 RocketMQ 日志复制的实现细节做了一个详细的介绍,可能有不少读者朋友们觉得源码阅读较为枯燥,看的有点云里雾里,本篇将首先梳理一下 RocketMQ DLedger 多副本关于日志复制的三个核心流程图,然后再思考一下在异常情况下如何保证数据一致性。
1、RocketMQ DLedger 多副本日志复制流程图
1.1 RocketMQ DLedger 日志转发(append) 请求流程图
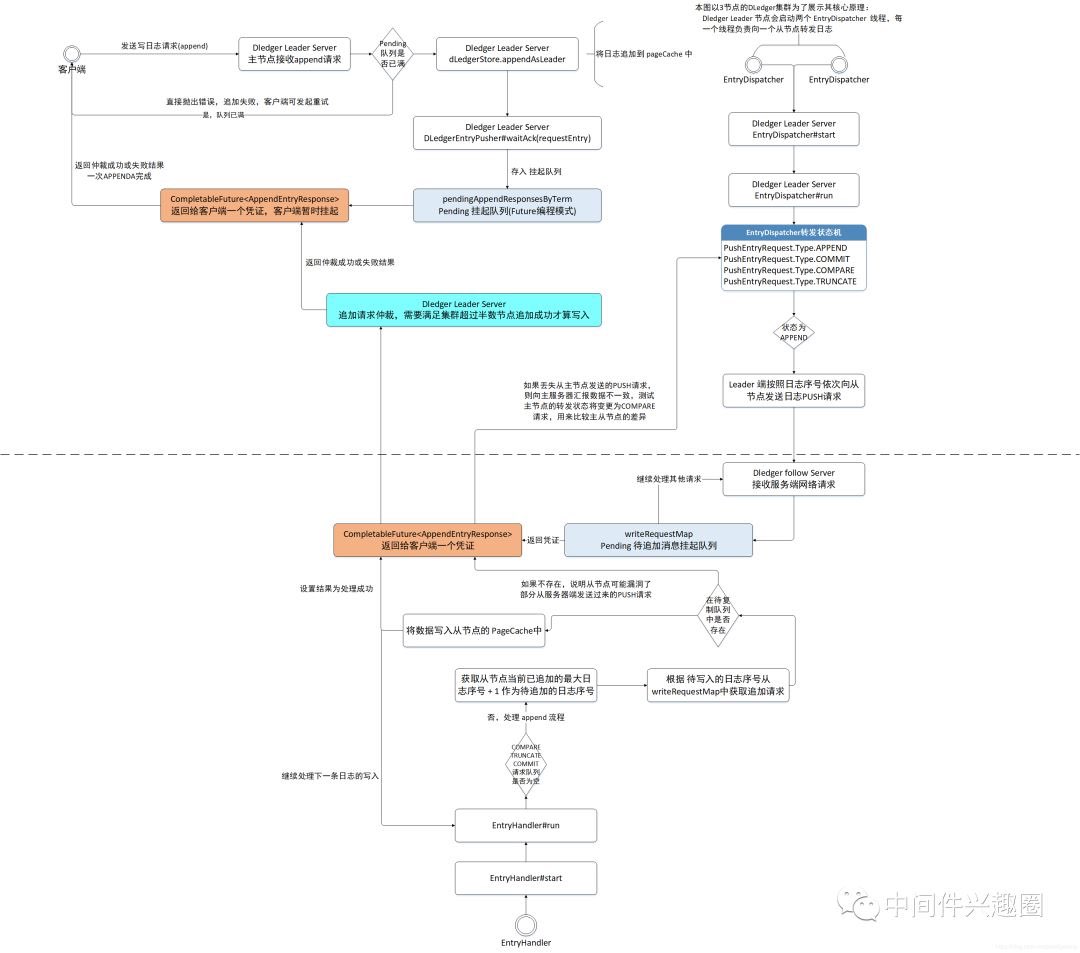
1.2 RocketMQ DLedger 日志仲裁流程图

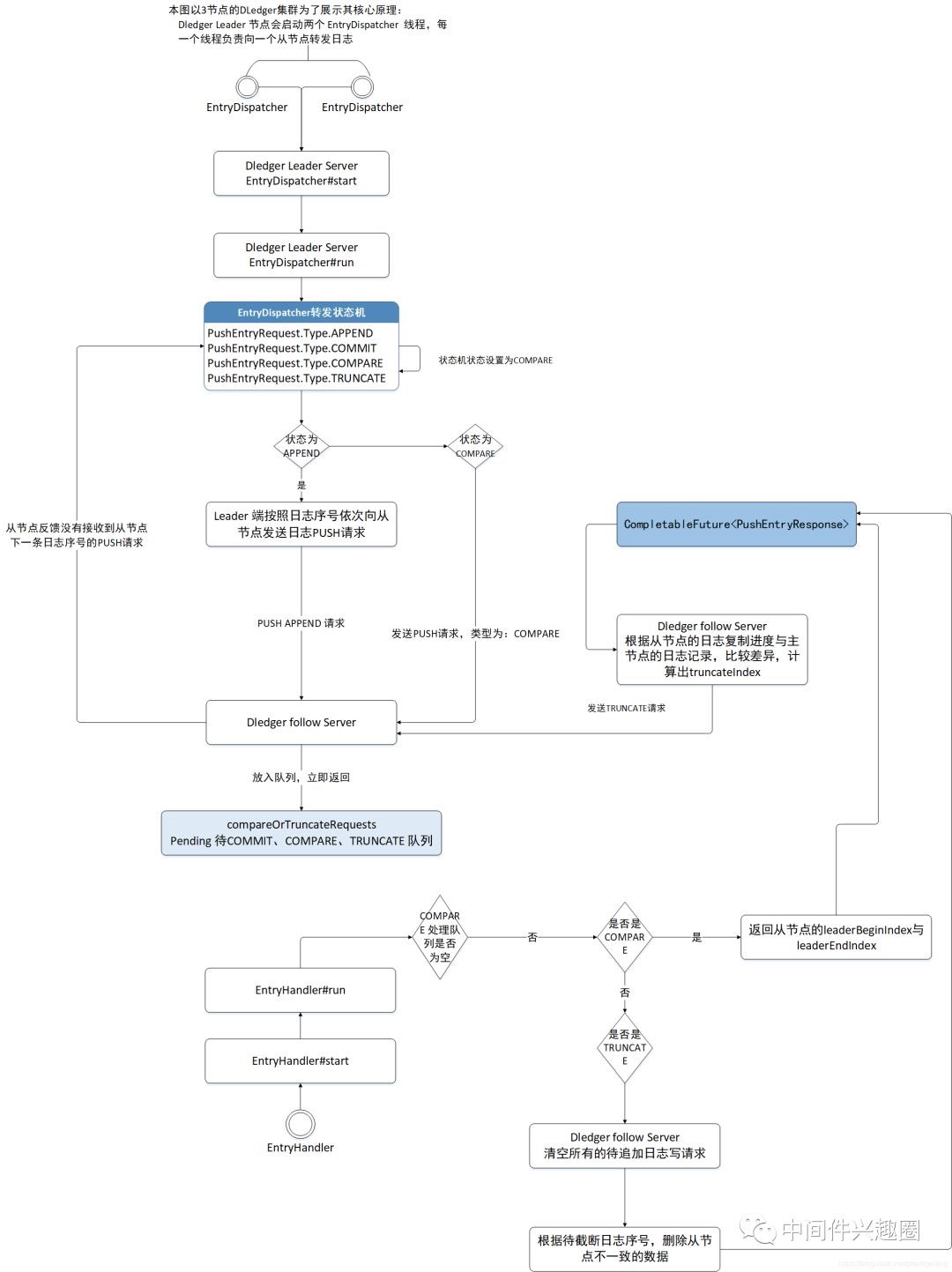
1.3 RocketMQ DLedger 从节点日志复制流程图
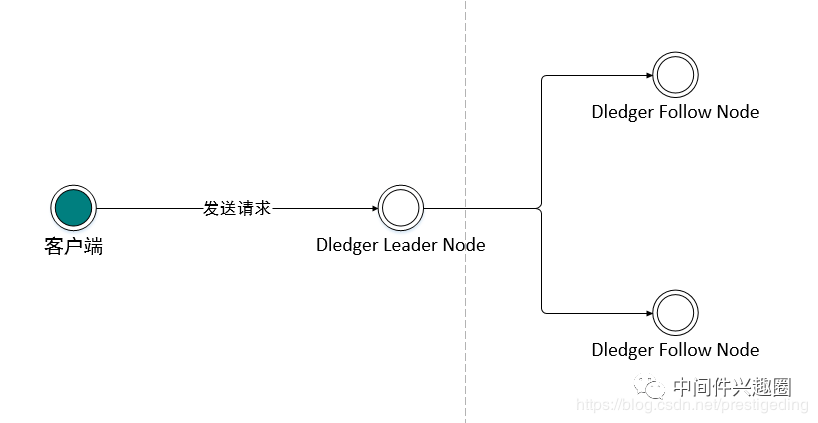
2、RocketMQ DLedger 多副本日志复制实现要点
上图是一个简易的日志复制的模型:图中客户端向 DLedger 集群发起一个写请求,集群中的 Leader 节点来处理写请求,首先数据先存入 Leader 节点,然后需要广播给它的所有从节点,从节点接收到 Leader 节点的数据推送对数据进行存储,然后向主节点汇报存储的结果,Leader 节点会对该日志的存储结果进行仲裁,如果超过集群数量的一半都成功存储了该数据,主节点则向客户端返回写入成功,否则向客户端写入写入失败。
接下来我们来探讨日志复制的核心设计要点。
2.1 日志编号
为了方便对日志进行管理与辨别,raft 协议为一条一条的消息进行编号,每一条消息达到主节点时会生成一个全局唯一的递增号,这样可以根据日志序号来快速的判断数据在主从复制过程中数据是否一致,在 DLedger 的实现中对应 DLedgerMemoryStore 中的 ledgerBeginIndex、ledgerEndIndex,分别表示当前节点最小的日志序号与最大的日志序号,下一条日志的序号为 ledgerEndIndex + 1 。
与日志序号还与一个概念绑定的比较紧密,即当前的投票轮次。
2.2 追加与提交机制
请思考如下问题,Leader 节点收到客户端的数据写入请求后,通过解析请求,提取数据部分,构建日志对象,并生成日志序号,用 seq 表示,然后存储到 Leader 节点中,然后将日志广播(推送)到其从节点,由于这个过程中存在网络时延,如果此时客户端向主节点查询 seq 的日志,由于日志已经存储在 Leader 节点中了,如果直接返回给客户端显然是有问题的,那该如何来避免这种情况的发生呢?
为了解决上述问题,DLedger 的实现(应该也是 raft 协议的一部分)引入了已提交指针(committedIndex)。即当主节点收到客户端请求时,首先先将数据存储,但此时数据是未提交的,此过程可以称之为追加,此时客户端无法访问,只有当集群内超过半数的节点都将日志追加完成后,才会更新 committedIndex 指针,只有已提交的数据才能被客户端访问。
一条日志要能被提交的充分必要条件是日志得到了集群内超过半数节点成功追加,才能被认为已提交。
2.3 日志一致性如何保证
从上文得知,一个拥有3个节点的 DLedger 集群,只要主节点和其中一个从节点成功追加日志,则认为已提交,客户端即可通过主节点访问。由于部分数据存在延迟,在 DLedger 的实现中,读写请求都将由 Leader 节点来负责。那落后的从节点如何再次跟上集群的步骤呢?
要重新跟上主节点的日志记录,首先要知道的是如何判断从节点已丢失数据呢?
DLedger 的实现思路是,DLedger 会按照日志序号向从节点源源不断的转发日志,从节点接收后将这些待追加的数据放入一个待写队列中。关键中的关键:从节点并不是从挂起队列中处理一个一个的追加请求,而是首先查阅从节点当前已追加的最大日志序号,用 ledgerEndIndex 表示,然后尝试追加 (ledgerEndIndex + 1)的日志,用该序号从代写队列中查找,如果该队列不为空,并且没有 (ledgerEndIndex + 1)的日志条目,说明从节点未接收到这条日志,发生了数据缺失。然后从节点在响应主节点 append 的请求时会告知数据不一致,然后主节点的日志转发线程其状态会变更为COMPARE,将向该从节点发送COMPARE命令,用来比较主从节点的数据差异,根据比较的差异重新从主节点同步数据或删除从节点上多余的数据,最终达到一致。于此同时,主节点也会对PUSH超时推送的消息发起重推,尽最大可能帮助从节点及时更新到主节点的数据。
更多问题,欢迎大家留言与我一起探讨。如果觉得文章对自己有些用处的话,麻烦帮忙点【在看】,谢谢。

