
源码分析 RocketMQ DLedger(多副本) 之日志追加流程原创
上一篇我们详细分析了 源码分析RocketMQ多副本之Leader选主,本文将详细分析日志复制的实现。
有了前篇 源码分析 RocketMQ DLedger 多副本存储实现,本文将直接从 Leader 处理客户端请求入口开始,其入口为:DLedgerServer 的 handleAppend 方法开始讲起。
1、日志复制基本流程
在正式分析 RocketMQ DLedger 多副本复制之前,我们首先来了解客户端发送日志的请求协议字段,其类图如下所示:
我们先一一介绍各个字段的含义:
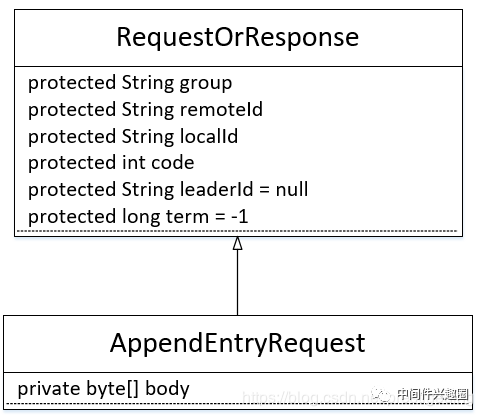
- String group
该集群所属组名。 - String remoteId
请求目的节点ID。 - String localId
节点ID。 - int code
请求响应字段,表示返回响应码。 - String leaderId = null
集群中的Leader Id。 - long term
集群当前的选举轮次。 - byte[] body
待发送的数据。
日志的请求处理处理入口为 DLedgerServer 的 handleAppend 方法。
DLedgerServer#handleAppend
1PreConditions.check(memberState.getSelfId().equals(request.getRemoteId()), DLedgerResponseCode.UNKNOWN_MEMBER, "%s != %s", request.getRemoteId(), memberState.getSelfId());
2reConditions.check(memberState.getGroup().equals(request.getGroup()), DLedgerResponseCode.UNKNOWN_GROUP, "%s != %s", request.getGroup(), memberState.getGroup());
3PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER);
Step1:首先验证请求的合理性:
如果请求的节点ID不是当前处理节点,则抛出异常。
如果请求的集群不是当前节点所在的集群,则抛出异常。
如果当前节点不是主节点,则抛出异常。
DLedgerServer#handleAppend
1long currTerm = memberState.currTerm();
2if (dLedgerEntryPusher.isPendingFull(currTerm)) { // @1
3 AppendEntryResponse appendEntryResponse = new AppendEntryResponse();
4 appendEntryResponse.setGroup(memberState.getGroup());
5 appendEntryResponse.setCode(DLedgerResponseCode.LEADER_PENDING_FULL.getCode());
6 appendEntryResponse.setTerm(currTerm);
7 appendEntryResponse.setLeaderId(memberState.getSelfId());
8 return AppendFuture.newCompletedFuture(-1, appendEntryResponse);
9} else { // @2
10 DLedgerEntry dLedgerEntry = new DLedgerEntry();
11 dLedgerEntry.setBody(request.getBody());
12 DLedgerEntry resEntry = dLedgerStore.appendAsLeader(dLedgerEntry);
13 return dLedgerEntryPusher.waitAck(resEntry);
14}
Step2:如果预处理队列已经满了,则拒绝客户端请求,返回 LEADER_PENDING_FULL 错误码;如果未满,将请求封装成 DledgerEntry,则调用 dLedgerStore 方法追加日志,并且通过使用 dLedgerEntryPusher 的 waitAck 方法同步等待副本节点的复制响应,并最终将结果返回给调用方法。
代码@1:如果 dLedgerEntryPusher 的 push 队列已满,则返回追加一次,其错误码为 LEADER_PENDING_FULL。
代码@2:追加消息到 Leader 服务器,并向从节点广播,在指定时间内如果未收到从节点的确认,则认为追加失败。
接下来就按照上述三个要点进行展开:
- 判断 Push 队列是否已满
- Leader 节点存储消息
- 主节点等待从节点复制 ACK
1.1 如何判断 Push 队列是否已满
DLedgerEntryPusher#isPendingFull
1public boolean isPendingFull(long currTerm) {
2 checkTermForPendingMap(currTerm, "isPendingFull"); // @1
3 return pendingAppendResponsesByTerm.get(currTerm).size() > dLedgerConfig.getMaxPendingRequestsNum(); // @2
4}
主要分两个步骤:
代码@1:检查当前投票轮次是否在 PendingMap 中,如果不在,则初始化,其结构为:Map< Long/* 投票轮次*/, ConcurrentMap>>。
代码@2:检测当前等待从节点返回结果的个数是否超过其最大请求数量,可通过maxPendingRequests
Num 配置,该值默认为:10000。
上述逻辑比较简单,但疑问随着而来,ConcurrentMap> 中的数据是从何而来的呢?我们不妨接着往下看。
1.2 Leader 节点存储数据
Leader 节点的数据存储主要由 DLedgerStore 的 appendAsLeader 方法实现。DLedger 分别实现了基于内存、基于文件的存储实现,本文重点关注基于文件的存储实现,其实现类为:DLedgerMmapFileStore。
下面重点来分析一下数据存储流程,其入口为DLedgerMmapFileStore 的 appendAsLeader 方法。
DLedgerMmapFileStore#appendAsLeader
1PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER);
2PreConditions.check(!isDiskFull, DLedgerResponseCode.DISK_FULL);
Step1:首先判断是否可以追加数据,其判断依据主要是如下两点:
当前节点的状态是否是 Leader,如果不是,则抛出异常。
当前磁盘是否已满,其判断依据是 DLedger 的根目录或数据文件目录的使用率超过了允许使用的最大值,默认值为85%。
1ByteBuffer dataBuffer = localEntryBuffer.get();
2ByteBuffer indexBuffer = localIndexBuffer.get();
Step2:从本地线程变量获取一个数据与索引 buffer。其中用于存储数据的 ByteBuffer,其容量固定为 4M ,索引的 ByteBuffer 为两个索引条目的长度,固定为64个字节。
1DLedgerEntryCoder.encode(entry, dataBuffer);
2public static void encode(DLedgerEntry entry, ByteBuffer byteBuffer) {
3 byteBuffer.clear();
4 int size = entry.computSizeInBytes();
5 //always put magic on the first position
6 byteBuffer.putInt(entry.getMagic());
7 byteBuffer.putInt(size);
8 byteBuffer.putLong(entry.getIndex());
9 byteBuffer.putLong(entry.getTerm());
10 byteBuffer.putLong(entry.getPos());
11 byteBuffer.putInt(entry.getChannel());
12 byteBuffer.putInt(entry.getChainCrc());
13 byteBuffer.putInt(entry.getBodyCrc());
14 byteBuffer.putInt(entry.getBody().length);
15 byteBuffer.put(entry.getBody());
16 byteBuffer.flip();
17}
Step3:将 DLedgerEntry,即将数据写入到 ByteBuffer中,从这里看出,每一次写入会调用 ByteBuffer 的 clear 方法,将数据清空,从这里可以看出,每一次数据追加,只能存储4M的数据。
DLedgerMmapFileStore#appendAsLeader
1synchronized (memberState) {
2 PreConditions.check(memberState.isLeader(), DLedgerResponseCode.NOT_LEADER, null);
3 // ... 省略代码
4}
Step4:锁定状态机,并再一次检测节点的状态是否是 Leader 节点。
DLedgerMmapFileStore#appendAsLeader
1long nextIndex = ledgerEndIndex + 1;
2entry.setIndex(nextIndex);
3entry.setTerm(memberState.currTerm());
4entry.setMagic(CURRENT_MAGIC);
5DLedgerEntryCoder.setIndexTerm(dataBuffer, nextIndex, memberState.currTerm(), CURRENT_MAGIC);
Step5:为当前日志条目设置序号,即 entryIndex 与 entryTerm (投票轮次)。并将魔数、entryIndex、entryTerm 等写入到 bytebuffer 中。
DLedgerMmapFileStore#appendAsLeader
1long prePos = dataFileList.preAppend(dataBuffer.remaining());
2entry.setPos(prePos);
3PreConditions.check(prePos != -1, DLedgerResponseCode.DISK_ERROR, null);
4DLedgerEntryCoder.setPos(dataBuffer, prePos);
Step6:计算新的消息的起始偏移量,关于 dataFileList 的 preAppend 后续详细介绍其实现,然后将该偏移量写入日志的 bytebuffer 中。
DLedgerMmapFileStore#appendAsLeader
1for (AppendHook writeHook : appendHooks) {
2 writeHook.doHook(entry, dataBuffer.slice(), DLedgerEntry.BODY_OFFSET);
3}
Step7:执行钩子函数。
DLedgerMmapFileStore#appendAsLeader
1long dataPos = dataFileList.append(dataBuffer.array(), 0, dataBuffer.remaining());
2PreConditions.check(dataPos != -1, DLedgerResponseCode.DISK_ERROR, null);
3PreConditions.check(dataPos == prePos, DLedgerResponseCode.DISK_ERROR, null);
Step8:将数据追加到 pagecache 中。该方法稍后详细介绍。
DLedgerMmapFileStore#appendAsLeader
1DLedgerEntryCoder.encodeIndex(dataPos, entrySize, CURRENT_MAGIC, nextIndex, memberState.currTerm(), indexBuffer);
2long indexPos = indexFileList.append(indexBuffer.array(), 0, indexBuffer.remaining(), false);
3PreConditions.check(indexPos == entry.getIndex() * INDEX_UNIT_SIZE, DLedgerResponseCode.DISK_ERROR, null);
Step9:构建条目索引并将索引数据追加到 pagecache。
DLedgerMmapFileStore#appendAsLeader
1ledgerEndIndex++;
2ledgerEndTerm = memberState.currTerm();
3if (ledgerBeginIndex == -1) {
4 ledgerBeginIndex = ledgerEndIndex;
5}
6updateLedgerEndIndexAndTerm();
Step10:ledgerEndeIndex 加一(下一个条目)的序号。并设置 leader 节点的状态机的 ledgerEndIndex 与 ledgerEndTerm。
Leader 节点数据追加就介绍到这里,稍后会重点介绍与存储相关方法的实现细节。
1.3 主节点等待从节点复制 ACK
其实现入口为 dLedgerEntryPusher 的 waitAck 方法。
DLedgerEntryPusher#waitAck
1public CompletableFuture<AppendEntryResponse> waitAck(DLedgerEntry entry) {
2 updatePeerWaterMark(entry.getTerm(), memberState.getSelfId(), entry.getIndex()); // @1
3 if (memberState.getPeerMap().size() == 1) { // @2
4 AppendEntryResponse response = new AppendEntryResponse();
5 response.setGroup(memberState.getGroup());
6 response.setLeaderId(memberState.getSelfId());
7 response.setIndex(entry.getIndex());
8 response.setTerm(entry.getTerm());
9 response.setPos(entry.getPos());
10 return AppendFuture.newCompletedFuture(entry.getPos(), response);
11 } else {
12 checkTermForPendingMap(entry.getTerm(), "waitAck");
13 AppendFuture<AppendEntryResponse> future = new AppendFuture<>(dLedgerConfig.getMaxWaitAckTimeMs()); // @3
14 future.setPos(entry.getPos());
15 CompletableFuture<AppendEntryResponse> old = pendingAppendResponsesByTerm.get(entry.getTerm()).put(entry.getIndex(), future); // @4
16 if (old != null) {
17 logger.warn("[MONITOR] get old wait at index={}", entry.getIndex());
18 }
19 wakeUpDispatchers(); // @5
20 return future;
21 }
22}
代码@1:更新当前节点的 push 水位线。
代码@2:如果集群的节点个数为1,无需转发,直接返回成功结果。
代码@3:构建 append 响应 Future 并设置超时时间,默认值为:2500 ms,可以通过 maxWaitAckTimeMs 配置改变其默认值。
代码@4:将构建的 Future 放入等待结果集合中。
代码@5:唤醒 Entry 转发线程,即将主节点中的数据 push 到各个从节点。
接下来分别对上述几个关键点进行解读。
1.3.1 updatePeerWaterMark 方法
DLedgerEntryPusher#updatePeerWaterMark
1private void updatePeerWaterMark(long term, String peerId, long index) { // 代码@1
2 synchronized (peerWaterMarksByTerm) {
3 checkTermForWaterMark(term, "updatePeerWaterMark"); // 代码@2
4 if (peerWaterMarksByTerm.get(term).get(peerId) < index) { // 代码@3
5 peerWaterMarksByTerm.get(term).put(peerId, index);
6 }
7 }
8}
代码@1:先来简单介绍该方法的两个参数:
- long term
当前的投票轮次。 - String peerId
当前节点的ID。 - long index
当前追加数据的序号。
代码@2:初始化 peerWaterMarksByTerm 数据结构,其结果为 < Long /** term /, Map< String /* peerId /, Long /* entry index*/>。
代码@3:如果 peerWaterMarksByTerm 存储的 index 小于当前数据的 index,则更新。
1.3.2 wakeUpDispatchers 详解
DLedgerEntryPusher#updatePeerWaterMark
1public void wakeUpDispatchers() {
2 for (EntryDispatcher dispatcher : dispatcherMap.values()) {
3 dispatcher.wakeup();
4 }
5}
该方法主要就是遍历转发器并唤醒。本方法的核心关键就是 EntryDispatcher,在详细介绍它之前我们先来看一下该集合的初始化。
DLedgerEntryPusher 构造方法
1for (String peer : memberState.getPeerMap().keySet()) {
2 if (!peer.equals(memberState.getSelfId())) {
3 dispatcherMap.put(peer, new EntryDispatcher(peer, logger));
4 }
5}
原来在构建 DLedgerEntryPusher 时会为每一个从节点创建一个 EntryDispatcher 对象。
显然,日志的复制由 DLedgerEntryPusher 来实现。由于篇幅的原因,该部分内容将在下篇文章中继续。
上面在讲解 Leader 追加日志时并没有详细分析存储相关的实现,为了知识体系的完备,接下来我们来分析一下其核心实现。
2、日志存储实现详情
主要对 MmapFileList 的 preAppend 与 append 方法进行详细讲解。
存储部分的设计请查阅笔者的博客:源码分析RocketMQ DLedger 多副本存储实现,MmapFileList 对标 RocketMQ 的MappedFileQueue。
2.1 MmapFileList 的 preAppend 详解
该方法最终会调用两个参数的preAppend方法,故我们直接来看两个参数的 preAppend 方法。
MmapFileList#preAppend
1public long preAppend(int len, boolean useBlank) { // @1
2 MmapFile mappedFile = getLastMappedFile(); // @2 start
3 if (null == mappedFile || mappedFile.isFull()) {
4 mappedFile = getLastMappedFile(0);
5 }
6 if (null == mappedFile) {
7 logger.error("Create mapped file for {}", storePath);
8 return -1;
9 } // @2 end
10 int blank = useBlank ? MIN_BLANK_LEN : 0;
11 if (len + blank > mappedFile.getFileSize() - mappedFile.getWrotePosition()) { // @3
12 if (blank < MIN_BLANK_LEN) {
13 logger.error("Blank {} should ge {}", blank, MIN_BLANK_LEN);
14 return -1;
15 } else {
16 ByteBuffer byteBuffer = ByteBuffer.allocate(mappedFile.getFileSize() - mappedFile.getWrotePosition()); // @4
17 byteBuffer.putInt(BLANK_MAGIC_CODE); // @5
18 byteBuffer.putInt(mappedFile.getFileSize() - mappedFile.getWrotePosition()); // @6
19 if (mappedFile.appendMessage(byteBuffer.array())) { // @7
20 //need to set the wrote position
21 mappedFile.setWrotePosition(mappedFile.getFileSize());
22 } else {
23 logger.error("Append blank error for {}", storePath);
24 return -1;
25 }
26 mappedFile = getLastMappedFile(0);
27 if (null == mappedFile) {
28 logger.error("Create mapped file for {}", storePath);
29 return -1;
30 }
31 }
32 }
33 return mappedFile.getFileFromOffset() + mappedFile.getWrotePosition();// @8
34}
代码@1:首先介绍其参数的含义:
- int len 需要申请的长度。
- boolean useBlank 是否需要填充,默认为true。
代码@2:获取最后一个文件,即获取当前正在写的文件。
代码@3:如果需要申请的资源超过了当前文件可写字节时,需要处理的逻辑。代码@4-@7都是其处理逻辑。
代码@4:申请一个当前文件剩余字节的大小的bytebuffer。
代码@5:先写入魔数。
代码@6:写入字节长度,等于当前文件剩余的总大小。
代码@7:写入空字节,代码@4-@7的用意就是写一条空Entry,填入魔数与 size,方便解析。
代码@8:如果当前文件足以容纳待写入的日志,则直接返回其物理偏移量。
经过上述代码解读,我们很容易得出该方法的作用,就是返回待写入日志的起始物理偏移量。
2.2 MmapFileList 的 append 详解
最终会调用4个参数的 append 方法,其代码如下:
MmapFileList#append
1public long append(byte[] data, int pos, int len, boolean useBlank) { // @1
2 if (preAppend(len, useBlank) == -1) {
3 return -1;
4 }
5 MmapFile mappedFile = getLastMappedFile(); // @2
6 long currPosition = mappedFile.getFileFromOffset() + mappedFile.getWrotePosition(); // @3
7 if (!mappedFile.appendMessage(data, pos, len)) { // @4
8 logger.error("Append error for {}", storePath);
9 return -1;
10 }
11 return currPosition;
12}
代码@1:首先介绍一下各个参数:
- byte[] data
待写入的数据,即待追加的日志。 - int pos
从 data 字节数组哪个位置开始读取。 - int len
待写入的字节数量。 - boolean useBlank
是否使用填充,默认为 true。
代码@2:获取最后一个文件,即当前可写的文件。
代码@3:获取当前写入指针。
代码@4:追加消息。
最后我们再来看一下 appendMessage,具体的消息追加实现逻辑。
DefaultMmapFile#appendMessage
1public boolean appendMessage(final byte[] data, final int offset, final int length) {
2 int currentPos = this.wrotePosition.get();
3
4 if ((currentPos + length) <= this.fileSize) {
5 ByteBuffer byteBuffer = this.mappedByteBuffer.slice(); // @1
6 byteBuffer.position(currentPos);
7 byteBuffer.put(data, offset, length);
8 this.wrotePosition.addAndGet(length);
9 return true;
10 }
11 return false;
12}
该方法主要突出一下写入的方式是 mappedByteBuffer,是通过 FileChannel 的 map方法创建,即我们常说的 PageCache,即消息追加首先是写入到 pageCache 中。
本文详细介绍了 Leader 节点处理客户端消息追加请求的前面两个步骤,即 判断 Push 队列是否已满 与 Leader 节点存储消息。考虑到篇幅的问题,各个节点的数据同步将在下一篇文章中详细介绍。

