
两个事务并发写,能保证数据唯一吗?原创
哟,又是我小白。最近有点高产了。
连我自己都害怕了。

直接进入正题吧。
两个事务并发写,能保证数据唯一吗?
我先来解释下标题讲的是个啥。
我们假设有这么一个用户注册的场景。用户并发请求注册新用户。
你有一张数据库表,也就是下面的user表。
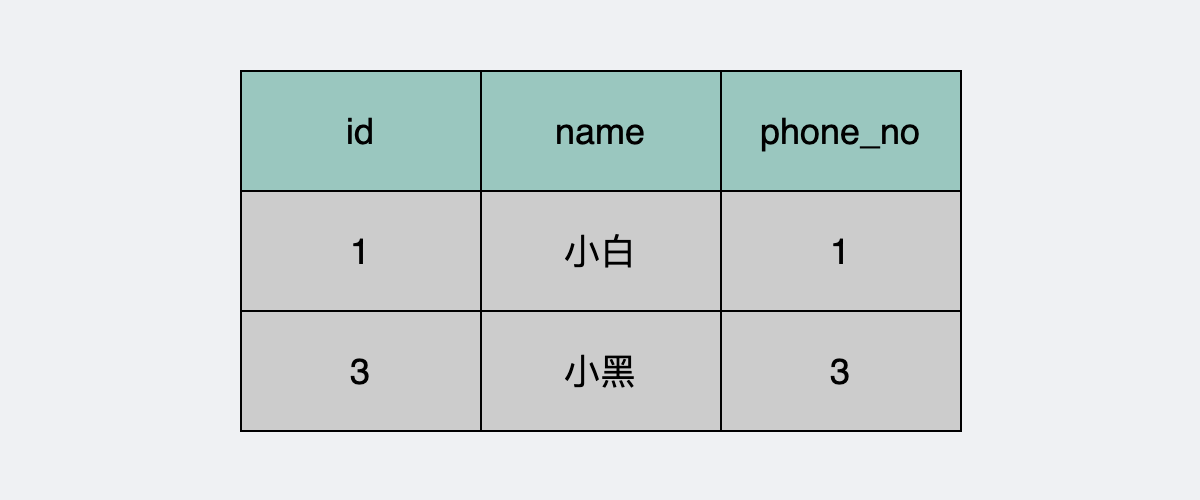
产品经理要求用户和用户之间,电话号码不能重复,为了保证这一点。我们想到了先查一下数据库,再判断一下,如果存在,就退出,否则插入一条数据。类似下面这样的伪代码。
select user where phone_no =2; // 查询sql
if (user 存在) {
return
} else {
insert user; // 插入sql
}
但这是两条sql语句,先执行查询sql,判断后再决定要不要执行插入sql。每次用户注册的时候都会执行这么一段逻辑。
那如果,此时有多个用户在做操作,就会并发执行这段逻辑。
如果都并发执行,第一条sql语句执行完之后,都会发现没有用户存在。此时都执行了插入,这样就出现了两条一样的数据才对。
所以,有人就想了,这两条sql语句逻辑应该是一个整体,不应该拆开,于是就想到了事务,通过事务把这两个sql作为一个整体,要么一起执行,要么都回滚。
这正是数据库ACID里的A(Atomicity),原子性的完美体现啊。

伪代码类似下面这样。
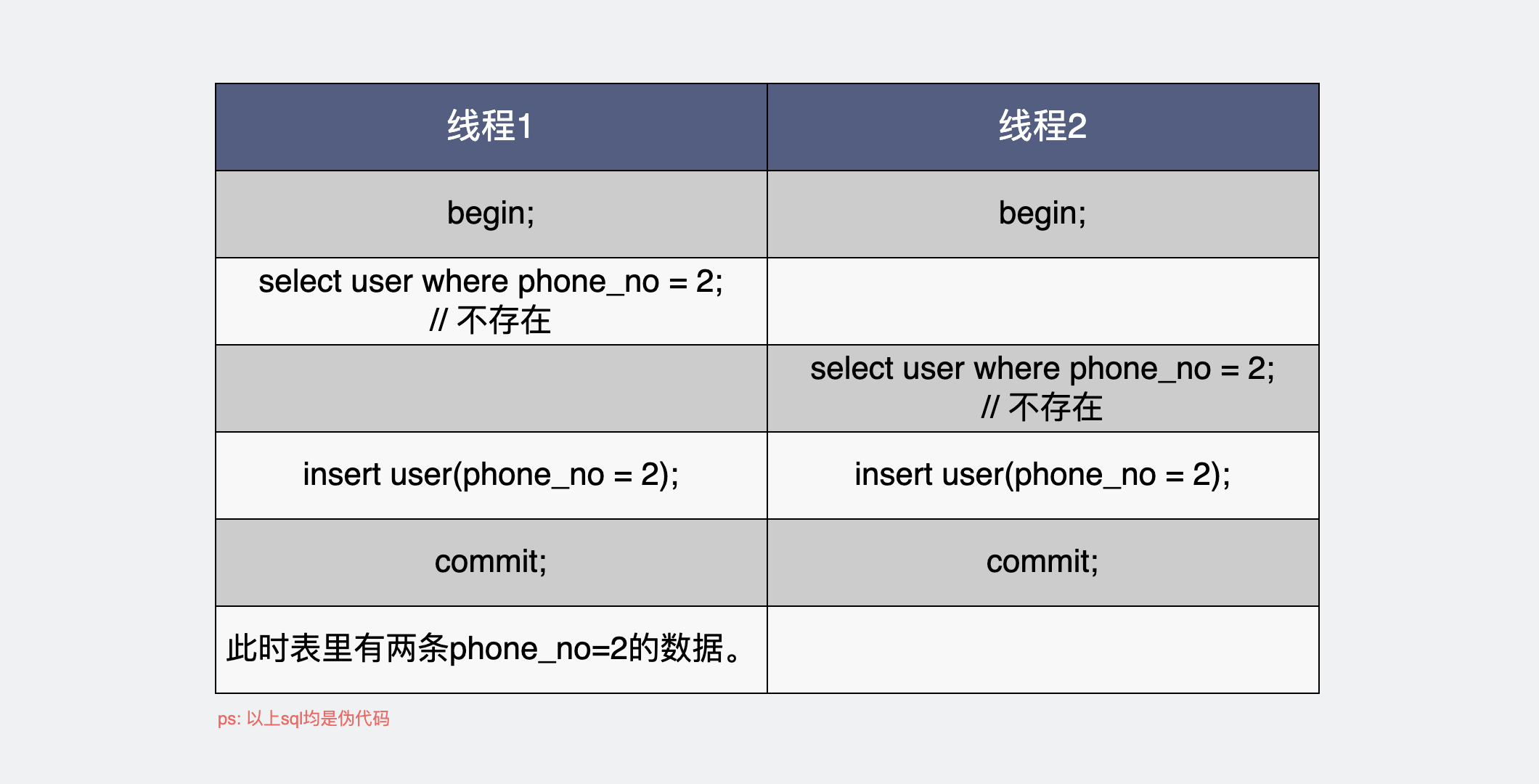
begin;
select user where phone_no =2; // 查询sql
if (user 存在) {
return
} else {
insert user; // 插入sql
}
commit;
那么问题来了,这段逻辑,并发执行,能保证数据唯一?
当然是不能。
事务內的多条sql语句,确实是原子的,要么一起成功,要么一起失败,这没错,但跟这个场景没什么太大关系。事务是并发执行的,第一个事务执行查询用户,并不会阻塞另一个事务查询用户,所以都有可能查到用户不存在,此时两个事务逻辑都判断为用户不存在,然后插入数据库。事务内两条sql都执行成功了,于是就插入了两条一样的数据。
怎么保证数据唯一?
那么我们接下来聊聊,怎么保证上面这种场景下,插入的数据是唯一的。方法有很多种,但我们今天只讨论mysql内部的做法,不考虑其他外部中间件(比如redis分布式锁这些)。
唯一索引
通过下面的命令,可以为数据库user表的phone_no字段加入唯一索引。
ALTER TABLE `user` ADD unique(`phone_no`);
我们执行一条写操作时,比如下面这句,
INSERT INTO `user` (`user_name`, `phone_no`) VALUES('小红', 2);
第一次会插入成功,第二次再执行插入,则会出现报错。
Duplicate entry '2' for key 'phone_no'
含义是phone_no这个字段是唯一的,加两次phone_no=2会导致重复。
于是乎回到我们文章开头的场景里,就完美解决了重复插入的问题了。
那么问题来了。
为什么唯一索引能保证数据唯一?
我们看看一句写操作,会经历什么。
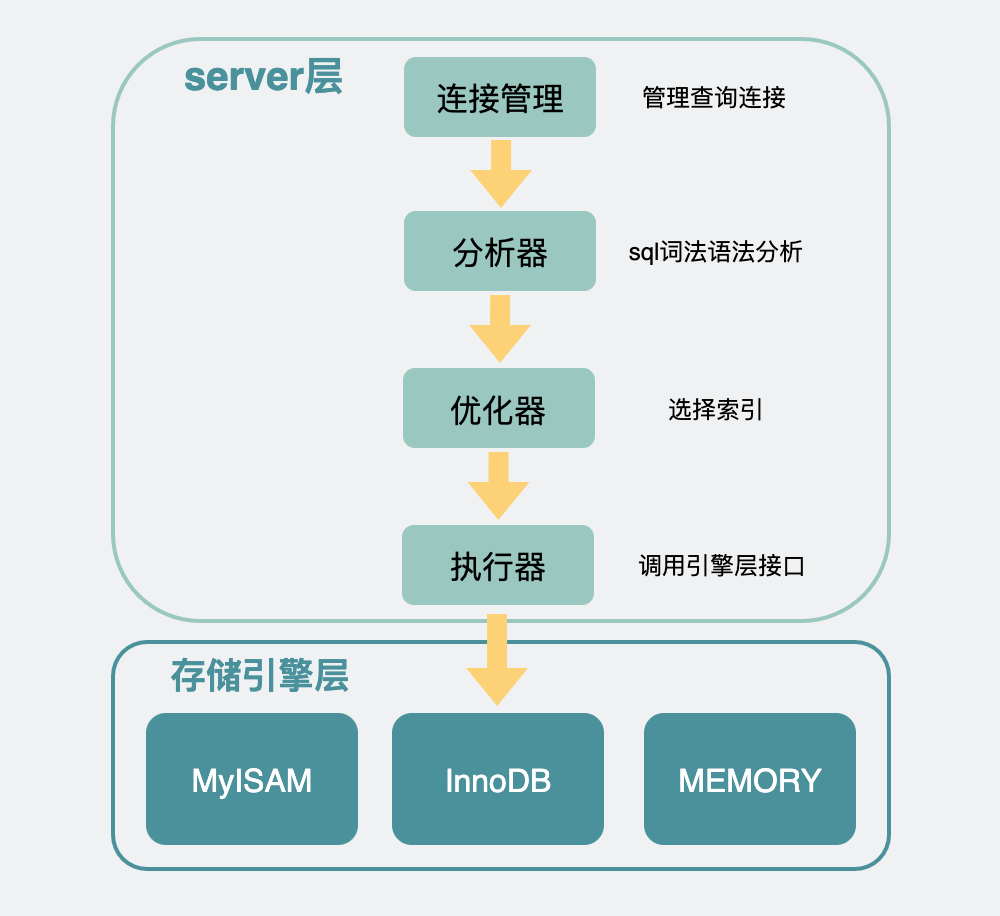
首先,mysql作为一个数据库,内部主要分为两层,一层是server层,一层是存储引擎层(一般是innodb)。
server层主要管的是数据库链接,权限校验,以及sql语句校验和优化之类的工作。请求打到存储引擎层,才是真正的查询和更新数据的操作。
大家都知道数据库是持久化存储,且最后都是把数据存到磁盘上的。
那数据库读写是直接读写磁盘数据吗?
不是,如果直接读写磁盘的话,那就太慢了,为了提升速度。
它在磁盘前面加了一层内存,叫buffer pool。它里面有很多细节,但最主要的就是个双向链表,里面放的是一个个数据页,每个数据页的大小默认是 16kb,数据页里面放的就是磁盘的数据。

于是有了这层buffer pool内存,mysql的读和写操作都可以先操作这部分内存,如果想要读写的数据页不在buffer pool里,再跑到磁盘里去捞。由于读写内存的速度比读写磁盘快得多。
所以引擎读写都快多了。
但这还不够,很多时候写操作,我的诉求就是把xx更新为xx,或插入xx,数据库光知道这一点就够了,我根本不需要知道数据页原来长什么样子。
有点抽象?举个例子吧。
比方说我想要把id=1的这条数据的phone_no字段更新为100,数据库知道这一点就够了,至于这条数据原来phone_no究竟是等于20,还是30,这根本不重要,反正最后都会变成我想要的phone_no=100。
也就是说,如果有那么一块内存,记录下我准备把数据改成什么样子,然后后续异步慢慢更新到磁盘数据上。那我甚至到不需要在一开始就把这块数据从磁盘读到buffer pool中,按照这个思路,change buffer就来了。
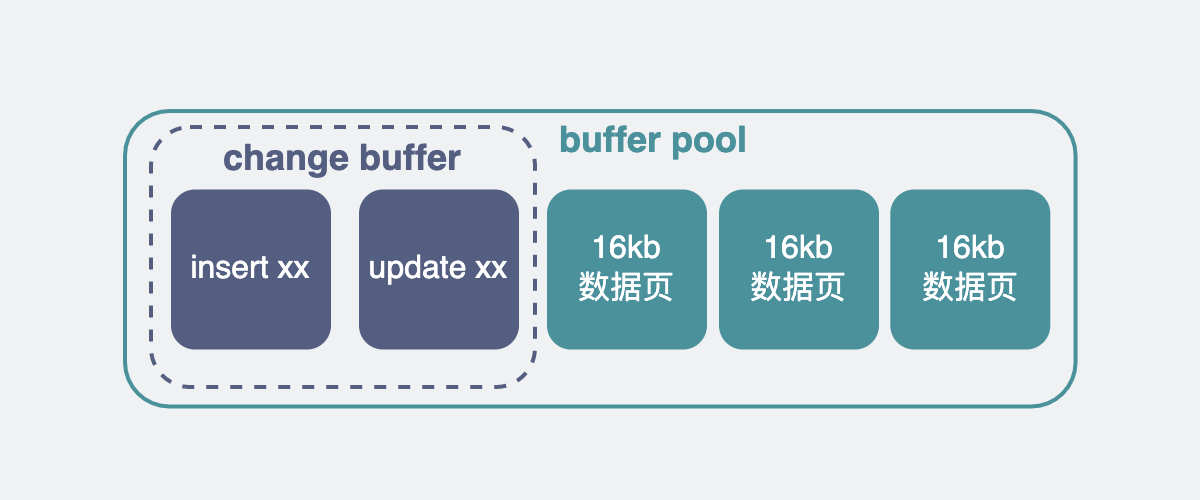
于是乎,写加了普通索引的数据,它只要把想要写的内容写到change buffer上,就立马结束返回了。后面innodb引擎拿着这个change buffer,再异步读入磁盘数据到内存,将change buffer的数据修改到数据页中,再写回磁盘,这速度就上来了,秒啊。
但这个change buffer,放在唯一索引这里就不管用了,毕竟,它得保证数据真的只有一条,那就得去看下数据库里,是不是真的有这条数据。
所以,对于insert场景,普通索引把需求扔到change buffer就完事返回了,而唯一索引需要真的把数据从磁盘读到内存来,看下是不是有重复的,没重复的再插入数据。
这唯一索引,在性能上就输了一截了。
所以回到唯一索引为什么能保证数据唯一的问题上,一句话概括就是,唯一索引会绕过change buffer,确保把磁盘数据读到内存后再判断数据是否存在,不存在才能插入数据,否则报错,以此来保证数据是唯一的。
总结
- 加唯一索引可以保证数据并发写入时数据唯一,而且最省事省心。
- 数据库通过引入一层buffer pool内存来提升读写速度,普通索引可以利用change buffer提高数据插入的性能。
- 唯一索引会绕过change buffer,确保把磁盘数据读到内存后再判断数据是否存在,不存在才能插入数据,否则报错,以此来保证数据是唯一的。
给大家留个问题呗,前面也提到了,innodb中,利用了change buffer,为普通索引做了加速。有没有哪些场景下,change buffer不仅不能给普通索引加速,还起到反作用的呢?
最后
大家也别笑,文章开头提到的通过开事务来保证数据唯一性的错误操作,其实很容易犯,而且我曾经也遇到过不止一次这样的事情。
做这个操作的人,还会信誓旦旦,言之凿凿的说出他的理解,在我解释了几遍发现无果之后,我选择低头假装思考,然后说:“你说的有点道理,我再回去好好想想”,然后默默的为数据表加上唯一索引…
我相信对方肯定已经理解了。那一刻,我感觉我写的不是代码,我写的是人情世故。

如果文章对你有帮助,欢迎…
算了。
别说了,一起在知识的海洋里呛水吧
点击下方名片,关注公众号:【小白debug】



