
RocketMQ 多副本前置篇:初探raft协议原创
Raft协议是分布式领域解决一致性的又一著名协议,主要包含Leader选举、日志复制两个部分。
温馨提示:本文根据raft官方给出的raft动画进行学习,其动画展示地址:
http://thesecretlivesofdata.com/raft/
本文的截图都来源于官网的动画,如果有涉及侵权,请联系作者将其删除。
1、Leader选举
1.1 单节点发起的投票
Raft协议中节点有3种状态(角色):
- Follower:跟随者。
- Candidate:候选者。
- Leader“领导者(Leader),通常我们所说的的主节点。
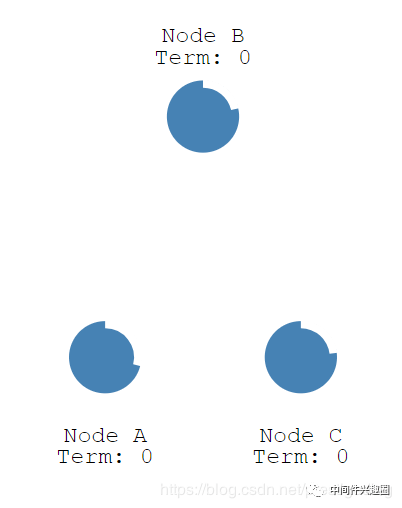
首先3个节点初始状态为 Follower,每个节点会有一个超时时间(计时器),其时间设置为150ms~300ms之间的随机值。当计时器到期后,节点状态从 Follower 变成 Candidate,如下图所示:
通常情况下,三个节点中会有一个节点的计时器率先到期,节点状态变为Candidate,候选者状态下的节点会发起选举投票。我们先来考虑只有一个节点变为Candidate时是如何进行选主的。
当节点状态为 Candidate,将发起一轮投票,由于是第一轮投票,设置本轮投票轮次为1,并首先为自己投上一票,正如上图所示的 NodeA 节点,Term 为1,Vote Count为1。
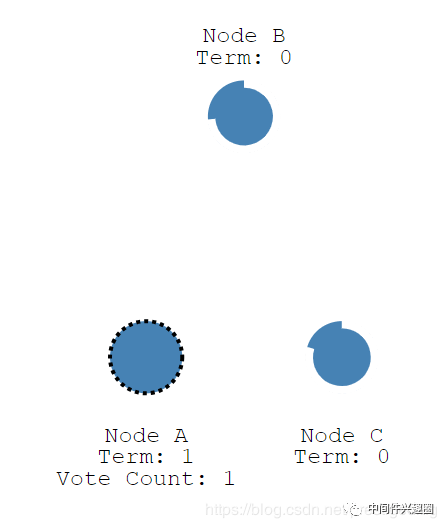

当一个节点的计时器超时后,首先为自己投上一票,然后向该组内其他的节点发起投票(用拉票更加合适),发送投票请求。
当集群内的节点收到投票请求后如果本轮未进行过投票,则赞同,否则反对,然后将结果返回,并重置计时器。
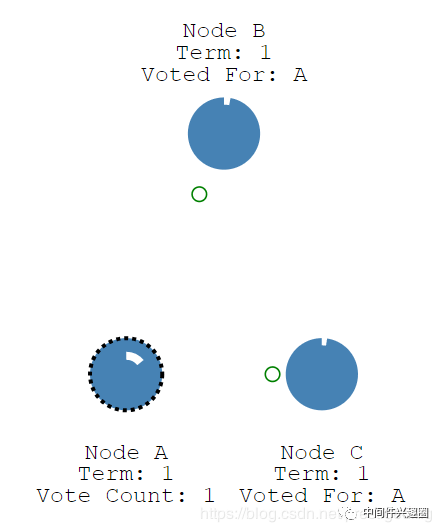
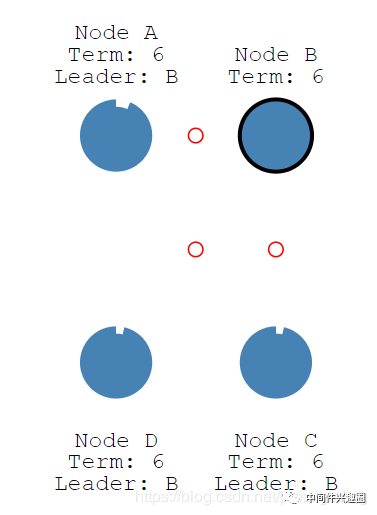
当节点A收到的赞同票大于一半时,则升级为该集群的 Leader,然后定时向集群内的其他节点发送心跳,以便确定自己的领导地位,正如下图所示。
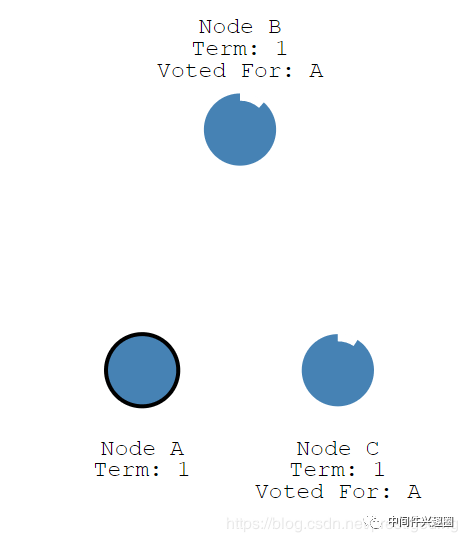
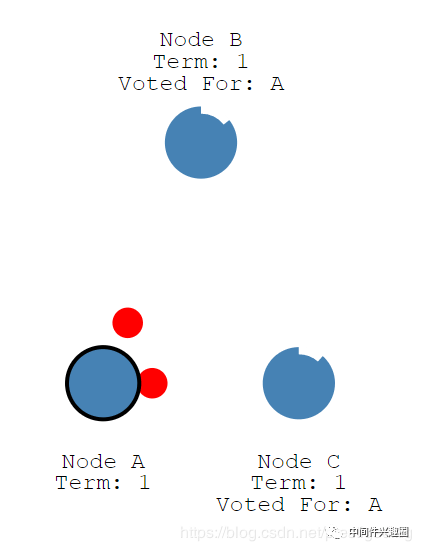
Node A,集群中的 Leader 正在向其他节点发送心跳包。
节点在收到 Leader 的心跳包后,返回响应结果,并重置自身的计时器,如果 Flower 状态的节点在计时时间超时内没有收到 Leader 的心跳包,就会从 Flower 节点变成 Candidate,该节点就会发起下一轮投票。
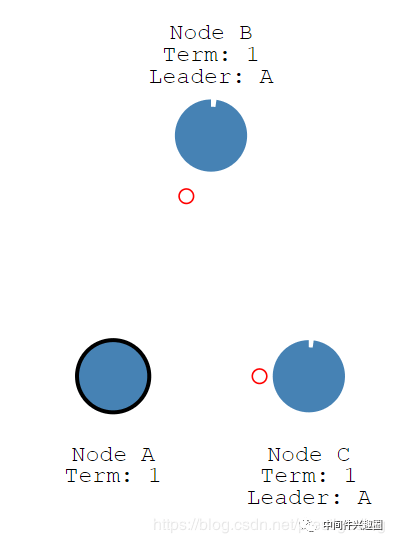
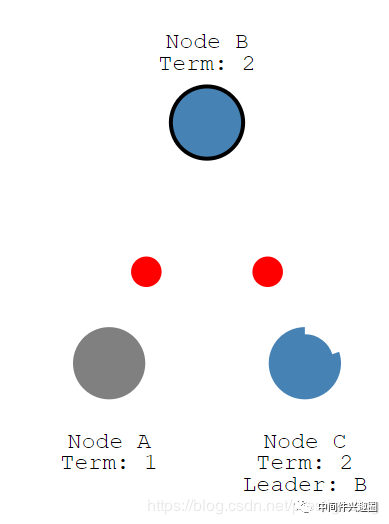
例如NodeA节点宕机,停止向它的从节点发送心跳,我们来看一下集群如何进行重新选主。
如果主节点宕机,则停止向集群内的节点发送心跳包。随着计时器的到期,节点B先于节点C变成 Candidate,则节点B向集群内的其他节点发起投票,如下图所示。
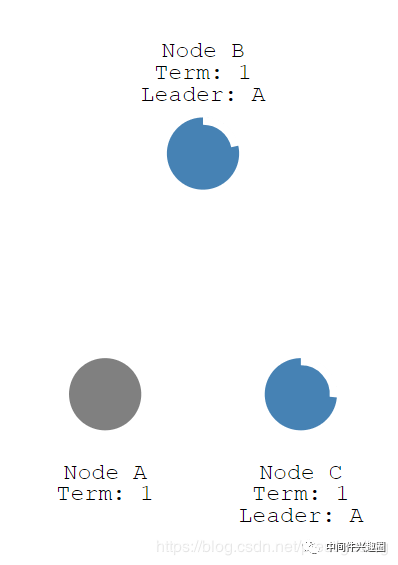
节点B,首先将投票轮次设置为2,然后首先为自己投上一篇,然后向其他节点发起投票请求。
节点C收到请求,由于其投票轮次大于自己的投票轮次,并该轮次并未投票,投出赞成票并返回结果,然后重置计时器。节点B将顺理成章的成为新的Leader并定时发送心跳包。
3个节点的选主就介绍到这里了,也许有网友会说,虽然各个节点的计时器是随机的,但也有可能同一时间,或一个节点在未收到另一个节点发起的投票请求之前变成 Candidate,即在一轮投票过程中,有大于1个的节点状态都是 Candidate,那该如何选主呢?
下面以4个节点的集群为例,来阐述上述这种情况情况下,如何进行选主。
1.2 多节点同时发起的投票
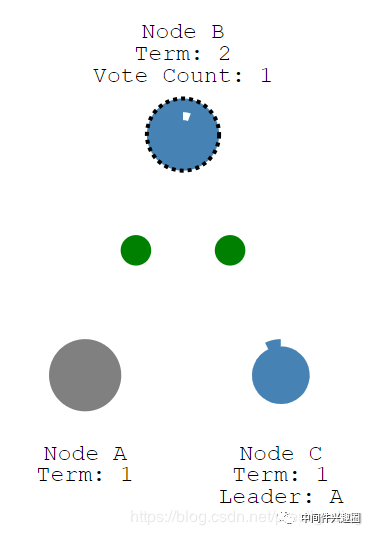
首先同时有两个节点进入Candidate状态,并开始新的一轮投票,当前投票编号为4,首先先为自己投上一票,然后向集群中的其他节点发起投票,如下图所示:
然后各个节点收到投票请求,如下所示,进行投票:
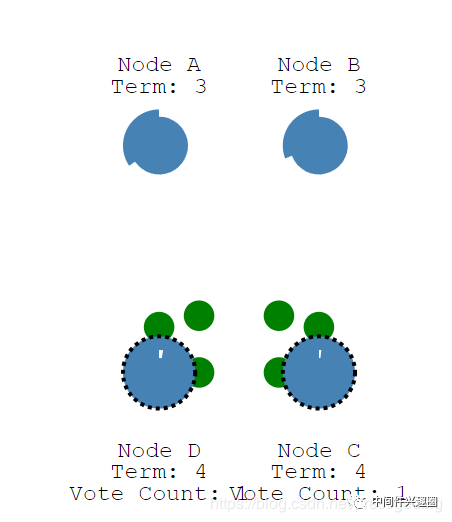
首先节点C、D在收到D、C节点的投票请求时,都会返回不同意,因为在本轮投票中,已经各自为自己投了一票,按照上图,节点A同意C节点、节点B同意D节点,那此时C、D都只获得两票,当然如果A,B都认为C或D成为主节点,则选择就可以结束了,上图显示,C、D都只获的2票,未超过半数,无法成为主节点,那接下来会发生什么呢?请看下图:
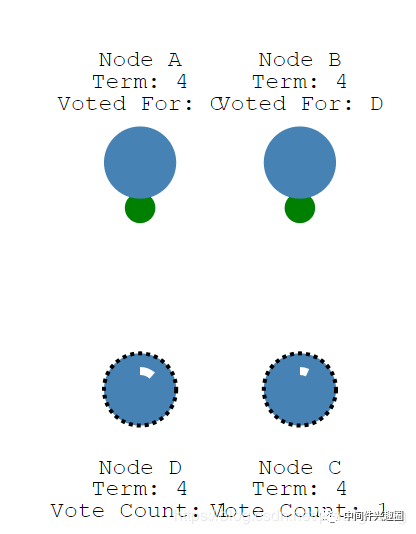
此时A,B,C,D的计时器各自在倒计时,当节点成为Candidate时,或自身状态本身是Candidate并且定时器触发后,发起一轮新的投票,图中是节点B、节点D同时发起了新的一轮投票。
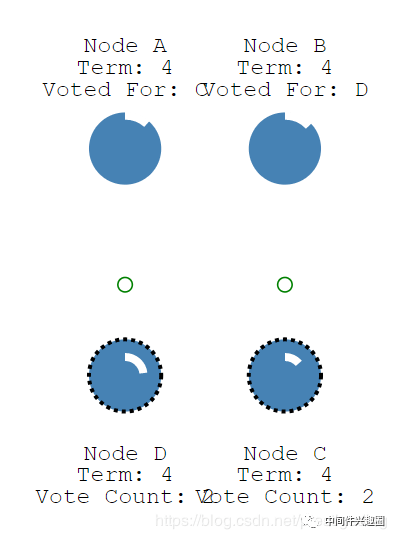
投票结果如下:节点A,节点C同意节点B成为leader,但由于BD都发起了第5轮投票,最终的投票轮次更新为6,如图所示:
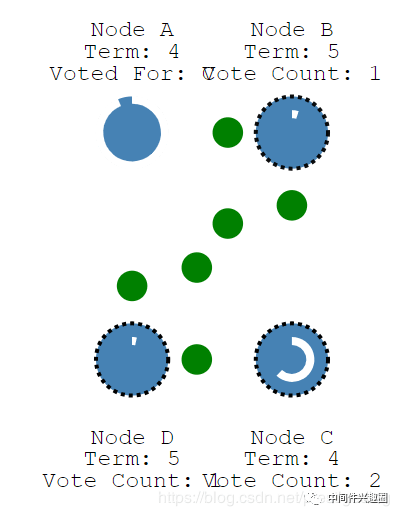
关于Raft协议的选主就介绍到这里了,接下来我们来思考一下,如果自己实现 Raf t协议,至少要考虑哪些问题,为下一篇源码阅读Dleger(RocketMQ多副本)模块提供一些思路。
1.3 思考如何实现Raft选主
节点状态
需要引入3种节点状态:Follower(跟随者)、Candidate(候选者),投票的触发点,Leader(主节点)。
进入投票状态的计时器
Follower、Candidate 两个状态时,需要维护一个计时器,每次定时时间从150ms-300ms之间进行随机,即每个节点的每次的计时过期不一样,Follower状态时,计时器到点后,触发一轮投票。节点在收到投票请求、Leader 的心跳请求并作出响应后需要重置定时器。
投票轮次Team
Candidate 状态的节点,每发起一轮投票,Term 加一;Term的存储。
投票机制
每一轮一个节点只能为一个节点投赞成票,例如节点A中维护的轮次为3,并且已经为节点B投了赞成票,如果收到其他节点,投票轮次为3,则会投反对票,如果收到轮次为4的节点,是又可以投赞成票的。
成为Leader的条件
必须得到集群中节点的大多数,即超过半数,例如如果集群中有3个节点,则必须得到两票,如果其中一台服务器宕机,剩下的两个节点,还能进行选主吗?答案是可以的,因为可以得到2票,超过初始集群中3的一半,所以通常集群中的机器各位尽量为奇数,因为4台的可用性与3台的一样。
温馨提示:上述结论只是我的一些思考,我们可以带着上述思考,进入到Dleger的学习中,下一篇将从源码分析的角度来学习大神是如何实现Raft协议的Leader选主的,让我们一起期待吧。
2、日志复制
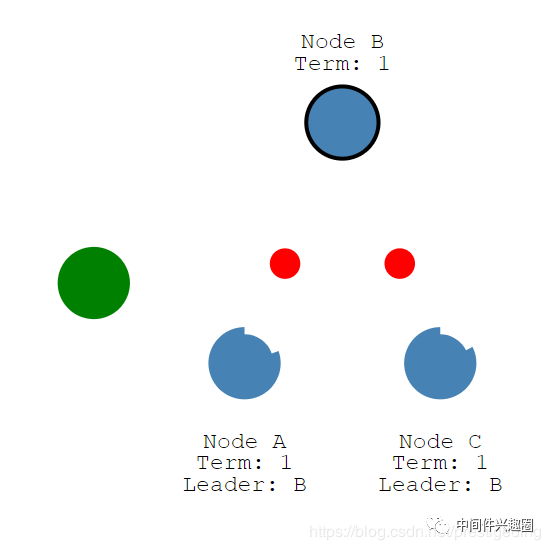
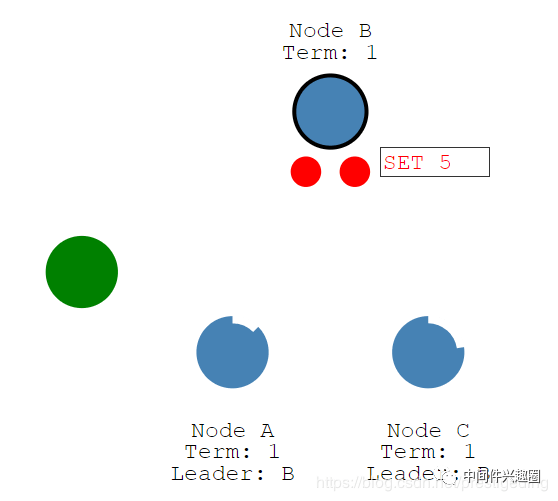
完成集群内的选主工作后,客户端向主节点发送请求,由主节点负责数据的复制,使集群内的数据保持一致性,初始状态如下图所示:
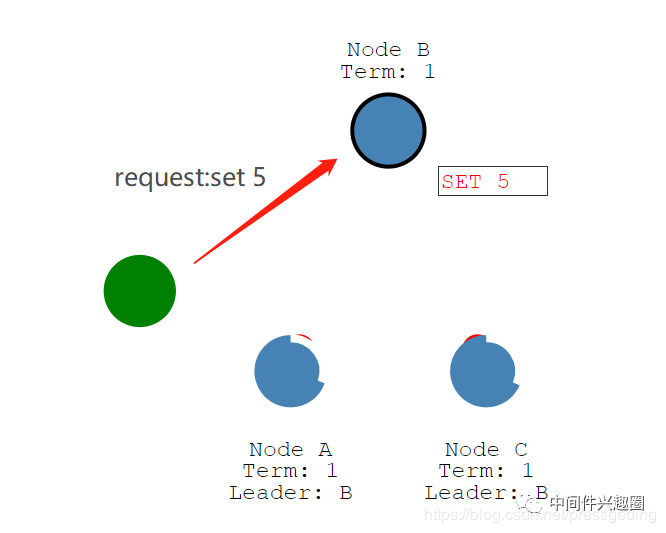
客户端向主节点发起请求,例如set 5,将数据更新为5,如下图所示:
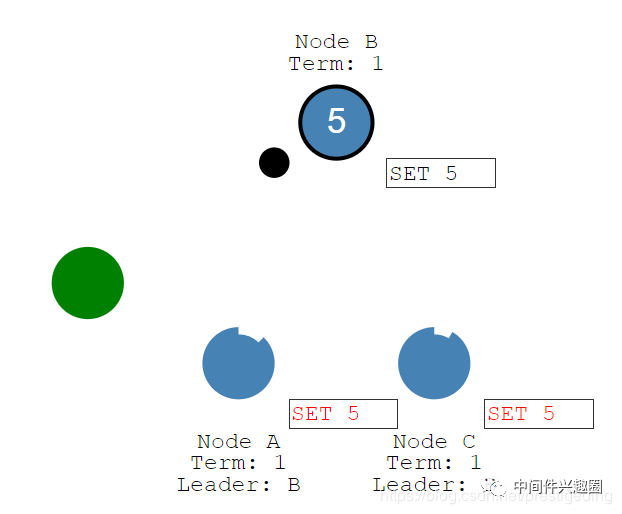
主节点收到客户端请求后,将数据追加到Leader的日志中(但未提交),然后在下一个心跳包中将日志转发到集群内从节点,如下图所示:
从节点收到Leader的日志后,追加到从节点的日志文件中,并返回确认ACK。Leader收到从节点的确认信息后,向客户端发送确认信息。
上述的日志复制比较简单,是由于只考虑正常的情况,如果中间发生异常,该如何保证数据一致性呢?
如果 Leader 节点向从节点广播日志时,其中某个从节点发送故障宕机,该如何处理呢?
日志在什么环节进行提交呢?Leader节点在收到客户端的数据变更请求后,首先追加到主节点的日志文件中,然后广播到从节点,从节点收到日志信息,是提交日志后返回ACK,还是什么时候提交呢?
日志如何保证唯一。
如何处理网络出现分区。
我相信读者朋友肯定还有更多的疑问,本文不打算来回答上述疑问,而是带着这些问题进入到 RocketMQ 多副本的学习中,通过源码分析 RocketMQ DLedger 的实现后,再来重新总结 raft 协议。
亲爱的读者们,读到这里了,烦请点在看,谢谢,下一篇将重点分析RocketMQ Dledger 多副本模块如何实现 raft 协议的选主。
更多文章请关注中间件兴趣圈公众号:



