
大家都在用MySQL count(*)统计总数,到底有什么问题?原创
在日常开发工作中,我经常会遇到需要统计总数的场景,比如:统计订单总数、统计用户总数等。一般我们会使用MySQL 的count函数进行统计,但是随着数据量逐渐增大,统计耗时也越来越长,最后竟然出现慢查询的情况,这究竟是什么原因呢?本篇文章带你一下学习一下。
1. MyISAM存储引擎计数为什么这么快?
我们总有个错觉,就是感觉MyISAM引擎的count计数要比InnoDB引擎更快,实际这不是错觉。
MyISAM引擎把表的总行数单独记录在磁盘上,查询的时候可以直接返回,不需要再累加统计。
但是当SQL查询中有where条件的时候,就无法再使用表的总行数了,还是需要乖乖的进行累加统计,查询性能也就跟InnoDB相差无几了。
为什么MyISAM引擎能够记录表的总行数,InnoDB引擎却不行?
因为MyISAM引擎不支持事务,只有表锁,所以记录的总行数是准确的。
而InnoDB引擎支持事务和行锁,存在并发修改的情况。又由于事务的隔离性,会出现不可重复读和幻读,记录的总行数无法保证是准确的。
2. 能不能手动实现统计总行数
既然InnoDB引擎没有帮我们记录总行数,我们能不能手动记录总行数,比如使用Redis。
其实也是不行的,使用Redis记录总行数,至少有下面3个问题:
- 无法实现事务之间的隔离
- 更新丢失,因为i++不是原子操作,当然可以使用Lua脚本实现原子操作,更复杂。
- Redis是非关系型缓存数据库,不能当作关系型持久化数据库使用,一般需要设置过期时间。

由上图中得知,虽然Redis计数加1操作放在了事务里面,但是不受事务控制的,在事务没有提交前,其他查询依然读到了最新的总行数,这就是脏读的情况。
3. InnoDB引擎能否实现快速计数
有一种办法,可以粗略估计表的总行数,就是使用MySQL命令:
show table status like 'user';

真实的总行数有100万行,预估有99万多行,误差在可接受的范围内。
部分场景适用,比如粗略估计网站的总用户数。
4. 四种计数方式的性能差别
常见的统计总行数的方式有以下四种:
count(*) 、 count(常量) 、 count(id) 、 count(字段)
InnoDB引擎对count计数做了优化,会选用数据量较小的非聚簇索引进行统计。
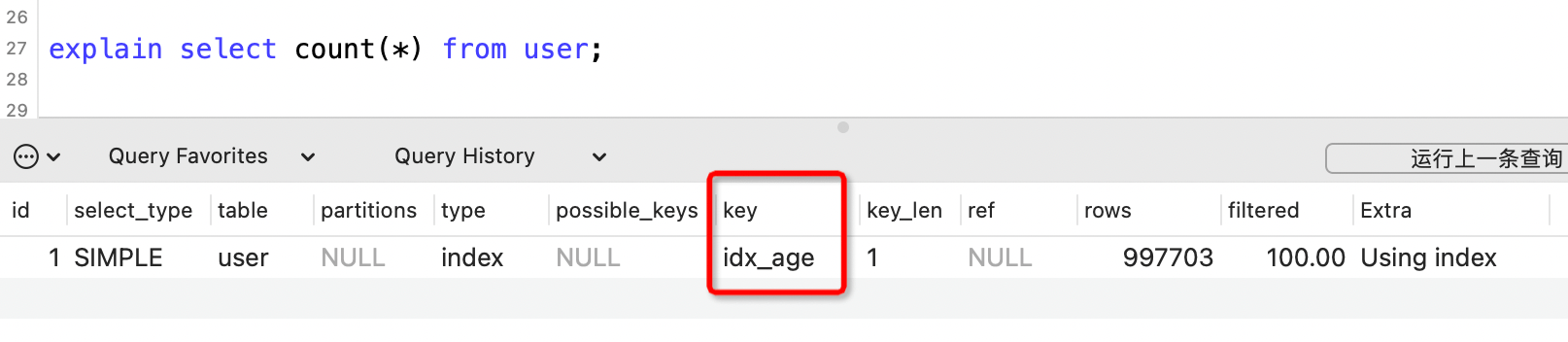
比如用户表中有三个索引,分别是主键索引、name索引和age索引,使用执行计划查看计数的时候用到了哪个索引?
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) DEFAULT NULL COMMENT '姓名',
`age` tinyint NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB COMMENT='用户表';
explain select count(*) from user;
用到了数据量较小的age索引。
count(*) 、 count(常量) 是直接统计表中的总行数,效率较高。而 count(id) 还需要把数据返回给MySQL Server端进行累加计数。最后 count(字段)需要筛选不为null字段,效率最差。
四种计数的查询性能从高到低,依次是:
count(*) ≈ count(常量) > count(id) > count(字段)
对于大多数情况,得到计数结果,还是老老实实使用count(*)
所以推荐使用select count(*),别跟**select *搞混了,不推荐使用select ***的。


