
从linux源码看epoll原创
前言
在linux的高性能网络编程中,绕不开的就是epoll。和select、poll等系统调用相比,epoll在需要监视大量文件描述符并且其中只有少数活跃的时候,表现出无可比拟的优势。epoll能让内核记住所关注的描述符,并在对应的描述符事件就绪的时候,在epoll的就绪链表中添加这些就绪元素,并唤醒对应的epoll等待进程。
本文就是笔者在探究epoll源码过程中,对kernel将就绪描述符添加到epoll并唤醒对应进程的一次源码分析(基于linux-2.6.32内核版本)。由于篇幅所限,笔者聚焦于tcp协议下socket可读事件的源码分析。
简单的epoll例子
下面的例子,是从笔者本人用c语言写的dbproxy中的一段代码。由于细节过多,所以做了一些删减。
int init_reactor(int listen_fd,int worker_count){
......
// 创建多个epoll fd,以充分利用多核
for(i=0;i<worker_count;i++){
reactor->worker_fd = epoll_create(EPOLL_MAX_EVENTS);
}
/* epoll add listen_fd and accept */
// 将accept后的事件加入到对应的epoll fd中
int client_fd = accept(listen_fd,(struct sockaddr *)&client_addr,&client_len)));
// 将连接描述符注册到对应的worker里面
epoll_ctl(reactor->client_fd,EPOLL_CTL_ADD,epifd,&event);
}
// reactor的worker线程
static void* rw_thread_func(void* arg){
......
for(;;){
// epoll_wait等待事件触发
int retval = epoll_wait(epfd,events,EPOLL_MAX_EVENTS,500);
if(retval > 0){
for(j=0; j < retval; j++){
// 处理读事件
if(event & EPOLLIN){
handle_ready_read_connection(conn);
continue;
}
/* 处理其它事件 */
}
}
}
......
}
上述代码事实上就是实现了一个reactor模式中的accept与read/write处理线程,如下图所示:
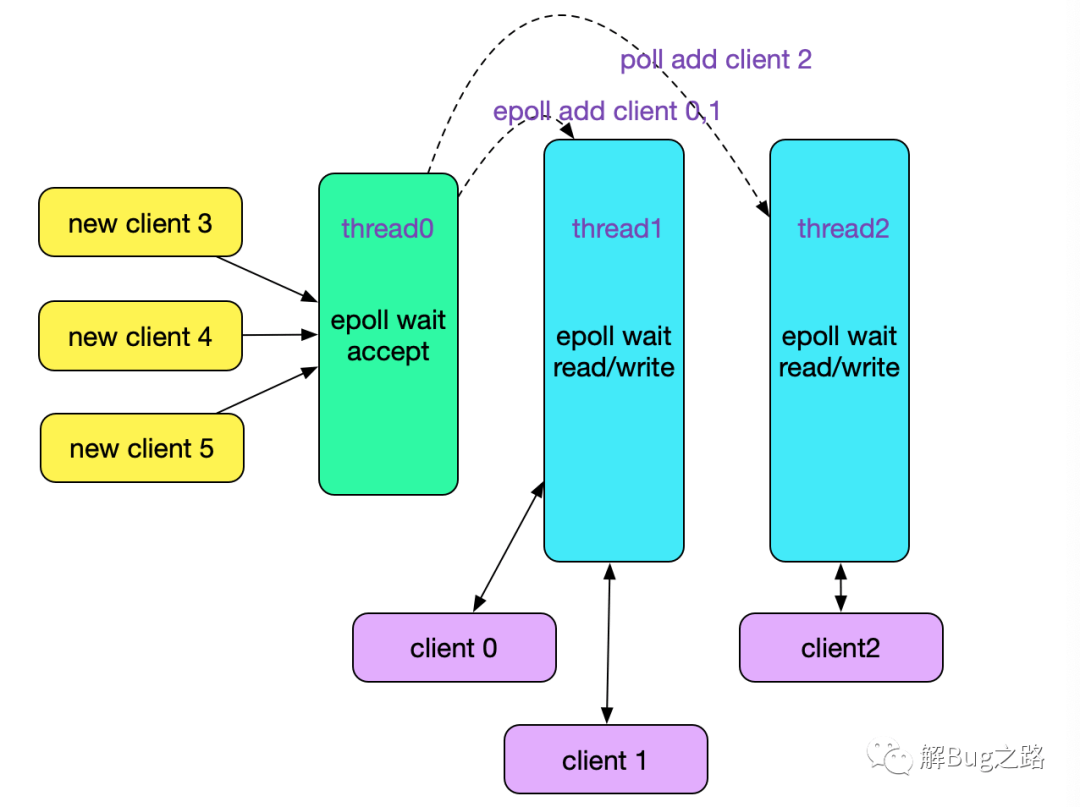
epoll_create
Unix的万物皆文件的思想在epoll里面也有体现,epoll_create调用返回一个文件描述符,此描述符挂载在anon_inode_fs(匿名inode文件系统)的根目录下面。让我们看下具体的epoll_create系统调用源码:
SYSCALL_DEFINE1(epoll_create, int, size)
{
if (size <= 0)
return -EINVAL;
return sys_epoll_create1(0);
}
由上述源码可见,epoll_create的参数是基本没有意义的,kernel简单的判断是否为0,然后就直接就调用了sys_epoll_create1。由于linux的系统调用是通过(SYSCALL_DEFINE1,SYSCALL_DEFINE2……SYSCALL_DEFINE6)定义的,那么sys_epoll_create1对应的源码即是SYSCALL_DEFINE(epoll_create1)。
(注:受限于寄存器数量的限制,(80x86下的)kernel限制系统调用最多有6个参数。据ulk3所述,这是由于32位80x86寄存器的限制)
接下来,我们就看下epoll_create1的源码:
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
// kzalloc(sizeof(*ep), GFP_KERNEL),用的是内核空间
error = ep_alloc(&ep);
// 获取尚未被使用的文件描述符,即描述符数组的槽位
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
// 在匿名inode文件系统中分配一个inode,并得到其file结构体
// 且file->f_op = &eventpoll_fops
// 且file->private_data = ep;
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC));
// 将file填入到对应的文件描述符数组的槽里面
fd_install(fd,file);
ep->file = file;
return fd;
}
最后epoll_create生成的文件描述符如下图所示:
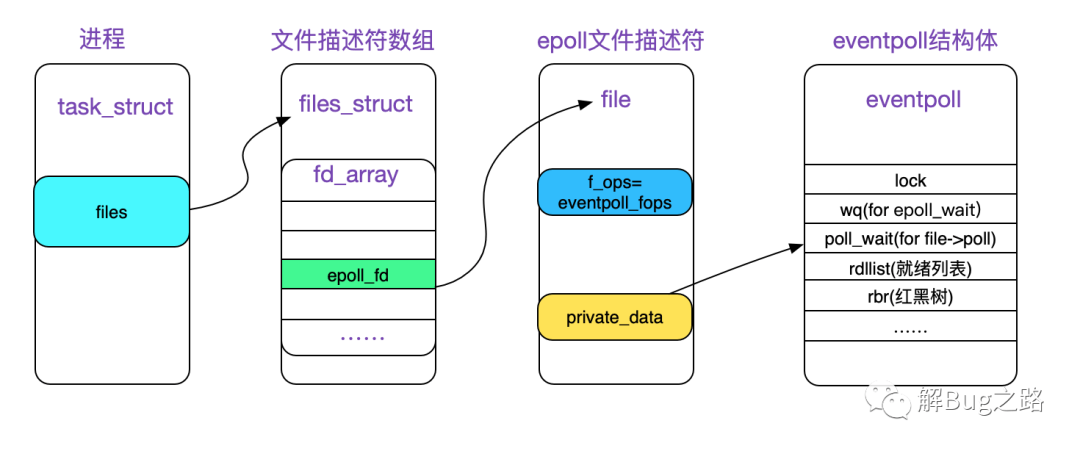
struct eventpoll
所有的epoll系统调用都是围绕eventpoll结构体做操作,现简要描述下其中的成员:
/*
* 此结构体存储在file->private_data中
*/
struct eventpoll {
// 自旋锁,在kernel内部用自旋锁加锁,就可以同时多线(进)程对此结构体进行操作
// 主要是保护ready_list
spinlock_t lock;
// 这个互斥锁是为了保证在eventloop使用对应的文件描述符的时候,文件描述符不会被移除掉
struct mutex mtx;
// epoll_wait使用的等待队列,和进程唤醒有关
wait_queue_head_t wq;
// file->poll使用的等待队列,和进程唤醒有关
wait_queue_head_t poll_wait;
// 就绪的描述符队列
struct list_head rdllist;
// 通过红黑树来组织当前epoll关注的文件描述符
struct rb_root rbr;
// 在向用户空间传输就绪事件的时候,将同时发生事件的文件描述符链入到这个链表里面
struct epitem *ovflist;
// 对应的user
struct user_struct *user;
// 对应的文件描述符
struct file *file;
// 下面两个是用于环路检测的优化
int visited;
struct list_head visited_list_link;
};
本文讲述的是kernel是如何将就绪事件传递给epoll并唤醒对应进程上,因此在这里主要聚焦于(wait_queue_head_t wq)等成员。
epoll_ctl(add)
我们看下epoll_ctl(EPOLL_CTL_ADD)是如何将对应的文件描述符插入到eventpoll中的。
借助于spin_lock(自旋锁)和mutex(互斥锁),epoll_ctl调用可以在多个KSE(内核调度实体,即进程/线程)中并发执行。
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
/* 校验epfd是否是epoll的描述符 */
// 此处的互斥锁是为了防止并发调用epoll_ctl,即保护内部数据结构
// 不会被并发的添加修改删除破坏
mutex_lock_nested(&ep->mtx, 0);
switch (op) {
case EPOLL_CTL_ADD:
...
// 插入到红黑树中
error = ep_insert(ep, &epds, tfile, fd);
...
break;
......
}
mutex_unlock(&ep->mtx);
}
上述过程如下图所示:
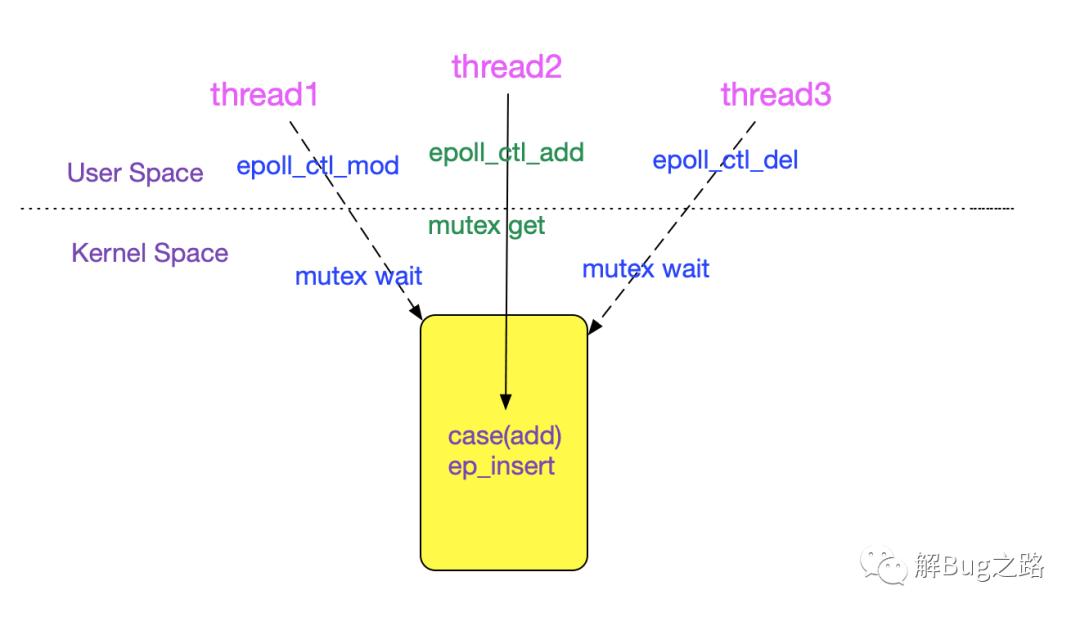
ep_insert
在ep_insert中初始化了epitem,然后初始化了本文关注的焦点,即事件就绪时候的回调函数,代码如下所示:
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
{
/* 初始化epitem */
// &epq.pt->qproc = ep_ptable_queue_proc
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
// 在这里将回调函数注入
revents = tfile->f_op->poll(tfile, &epq.pt);
// 如果当前有事件已经就绪,那么一开始就会被加入到ready list
// 例如可写事件
// 另外,在tcp内部ack之后调用tcp_check_space,最终调用sock_def_write_space来唤醒对应的epoll_wait下的进程
if ((revents & event->events) && !ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
// wake_up ep对应在epoll_wait下的进程
if (waitqueue_active(&ep->wq)){
wake_up_locked(&ep->wq);
}
......
}
// 将epitem插入红黑树
ep_rbtree_insert(ep, epi);
......
}
tfile->f_op->poll的实现
向kernel更底层注册回调函数的是tfile->f_op->poll(tfile, &epq.pt)这一句,我们来看一下对于对应的socket文件描述符,其fd=>file->f_op->poll的初始化过程:
// 将accept后的事件加入到对应的epoll fd中
int client_fd = accept(listen_fd,(struct sockaddr *)&client_addr,&client_len)));
// 将连接描述符注册到对应的worker里面
epoll_ctl(reactor->client_fd,EPOLL_CTL_ADD,epifd,&event);
回顾一下上述user space代码,fd即client_fd是由tcp的listen_fd通过accept调用而来,那么我们看下accept调用链的关键路径:
accept
|->accept4
|->sock_attach_fd(newsock, newfile, flags & O_NONBLOCK);
|->init_file(file,...,&socket_file_ops);
|->file->f_op = fop;
/* file->f_op = &socket_file_ops */
|->fd_install(newfd, newfile); // 安装fd
那么,由accept获得的client_fd的结构如下图所示:
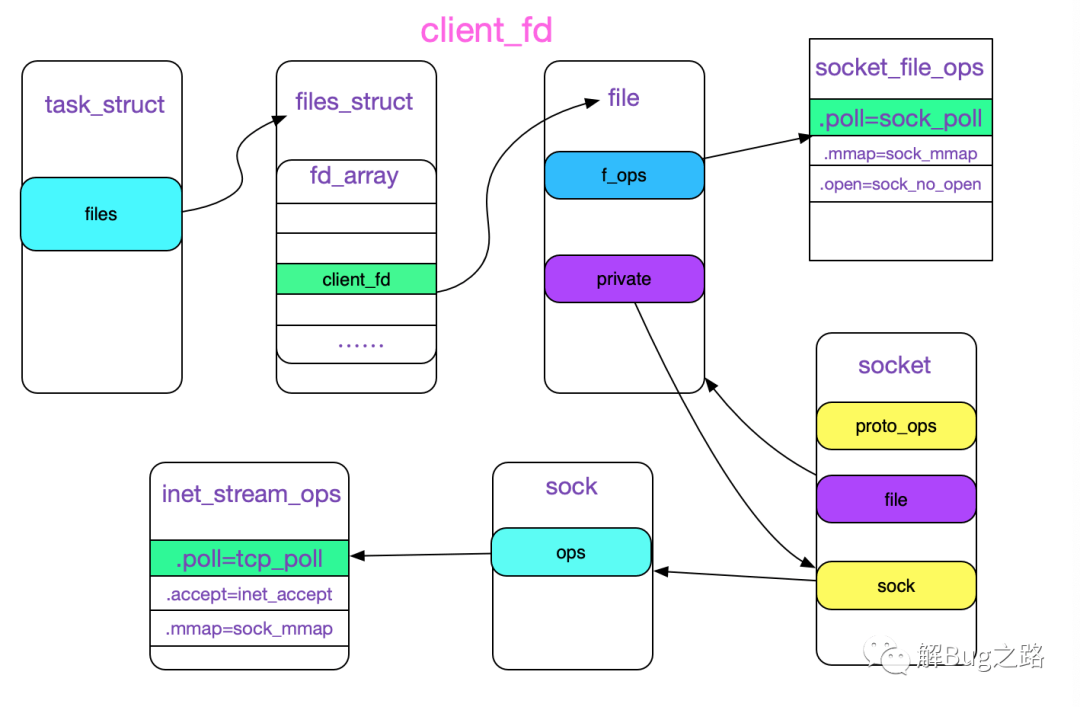
既然知道了tfile->f_op->poll的实现,我们就可以看下此poll是如何将安装回调函数的。
回调函数的安装
kernel的调用路径如下:
sock_poll /*tfile->f_op->poll(tfile, &epq.pt)*/;
|->sock->ops->poll
|->tcp_poll
/* 这边重要的是拿到了sk_sleep用于KSE(进程/线程)的唤醒 */
|->sock_poll_wait(file, sk->sk_sleep, wait);
|->poll_wait
|->p->qproc(filp, wait_address, p);
/* p为&epq.pt,而且&epq.pt->qproc= ep_ptable_queue_proc*/
|-> ep_ptable_queue_proc(filp,wait_address,p);
绕了一大圈之后,我们的回调函数的安装其实就是调用了eventpoll.c中的ep_ptable_queue_proc,而且向其中传递了sk->sk_sleep作为其waitqueue的head,其源码如下所示:
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
// 取出当前client_fd对应的epitem
struct epitem *epi = ep_item_from_epqueue(pt);
// &pwq->wait->func=ep_poll_callback,用于回调唤醒
// 注意,这边不是init_waitqueue_entry,即没有将当前KSE(current,当前进程/线程)写入到
// wait_queue当中,因为不一定是从当前安装的KSE唤醒,而应该是唤醒epoll\_wait的KSE
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
// 这边的whead是sk->sk_sleep,将当前的waitqueue链入到socket对应的sleep列表
add_wait_queue(whead, &pwq->wait);
}
这样client_fd的结构进一步完善,如下图所示:
ep_poll_callback函数是唤醒对应epoll_wait的地方,我们将在后面一起讲述。
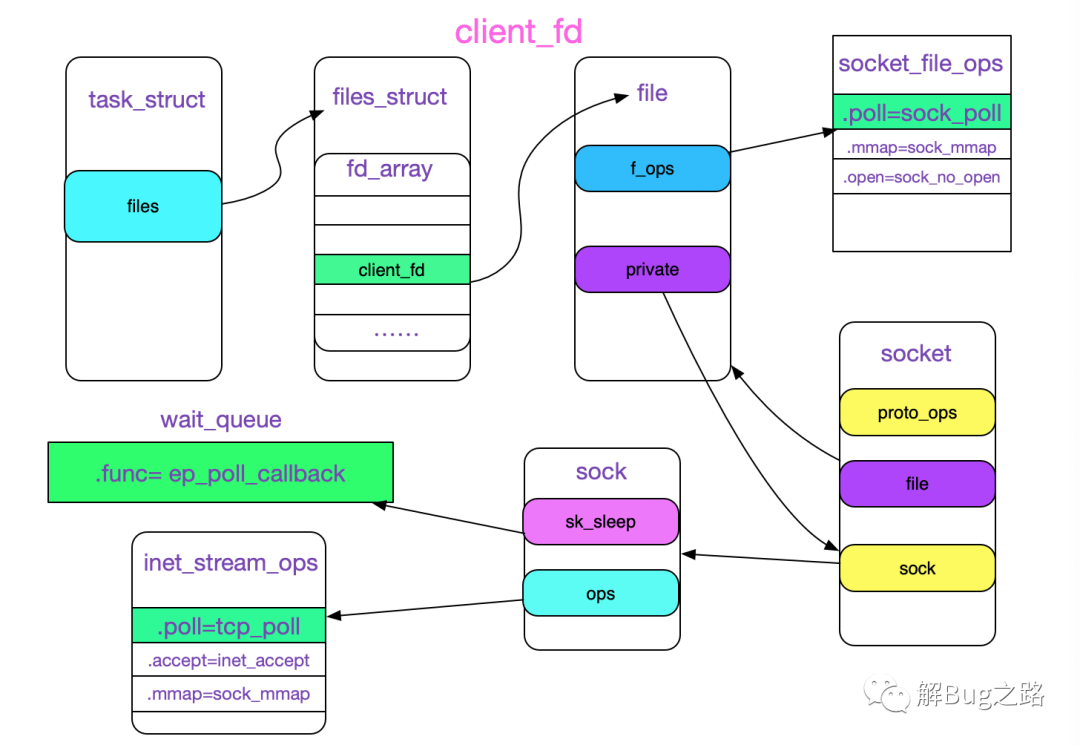
epoll_wait
epoll_wait主要是调用了ep_poll:
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
/* 检查epfd是否是epoll\_create创建的fd */
// 调用ep_poll
error = ep_poll(ep, events, maxevents, timeout);
...
}
紧接着,我们看下ep_poll函数:
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
......
retry:
// 获取spinlock
spin_lock_irqsave(&ep->lock, flags);
// 将当前task_struct写入到waitqueue中以便唤醒
// wq_entry->func = default_wake_function;
init_waitqueue_entry(&wait, current);
// WQ_FLAG_EXCLUSIVE,排他性唤醒,配合SO_REUSEPORT从而解决accept惊群问题
wait.flags |= WQ_FLAG_EXCLUSIVE;
// 链入到ep的waitqueue中
__add_wait_queue(&ep->wq, &wait);
for (;;) {
// 设置当前进程状态为可打断
set_current_state(TASK_INTERRUPTIBLE);
// 检查当前线程是否有信号要处理,有则返回-EINTR
if (signal_pending(current)) {
res = -EINTR;
break;
}
spin_unlock_irqrestore(&ep->lock, flags);
// schedule调度,让出CPU
jtimeout = schedule_timeout(jtimeout);
spin_lock_irqsave(&ep->lock, flags);
}
// 到这里,表明超时或者有事件触发等动作导致进程重新调度
__remove_wait_queue(&ep->wq, &wait);
// 设置进程状态为running
set_current_state(TASK_RUNNING);
......
// 检查是否有可用事件
eavail = !list_empty(&ep->rdllist) || ep->ovflist != EP_UNACTIVE_PTR;
......
// 向用户空间拷贝就绪事件
ep_send_events(ep, events, maxevents)
}
上述逻辑如下图所示:
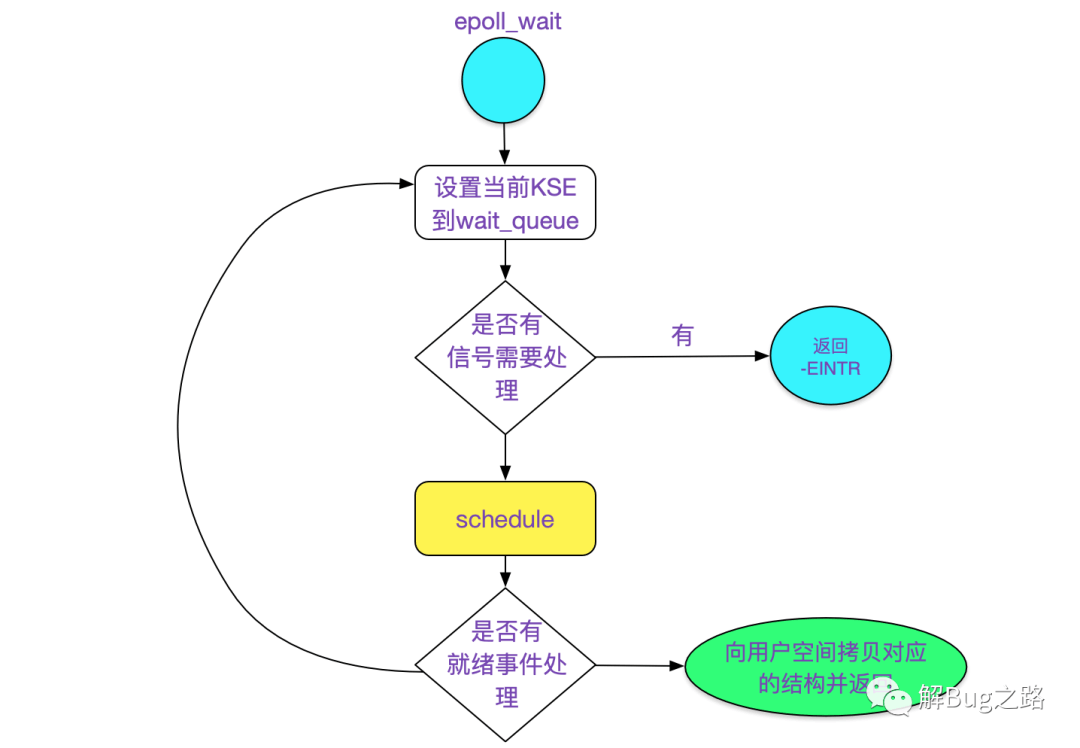
ep_send_events
ep_send_events函数主要就是调用了ep_scan_ready_list,顾名思义ep_scan_ready_list就是扫描就绪列表:
static int ep_scan_ready_list(struct eventpoll *ep,
int (*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv,
int depth)
{
...
// 将epfd的rdllist链入到txlist
list_splice_init(&ep->rdllist, &txlist);
...
/* sproc = ep_send_events_proc */
error = (*sproc)(ep, &txlist, priv);
...
// 处理ovflist,即在上面sproc过程中又到来的事件
...
}
其主要调用了ep_send_events_proc:
static int ep_send_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
for (eventcnt = 0, uevent = esed->events;
!list_empty(head) && eventcnt < esed->maxevents;) {
// 遍历ready list
epi = list_first_entry(head, struct epitem, rdllink);
list_del_init(&epi->rdllink);
// readylist只是表明当前epi有事件,具体的事件信息还是得调用对应file的poll
// 这边的poll即是tcp_poll,根据tcp本身的信息设置掩码(mask)等信息 & 上兴趣事件掩码,则可以得知当前事件是否是epoll_wait感兴趣的事件
revents = epi->ffd.file->f_op->poll(epi->ffd.file, NULL) &
epi->event.events;
if(revents){
/* 将event放入到用户空间 */
/* 处理ONESHOT逻辑 */
// 如果不是边缘触发,则将当前的epi重新加回到可用列表中,这样就可以下一次继续触发poll,如果下一次poll的revents不为0,那么用户空间依旧能感知 */
else if (!(epi->event.events & EPOLLET)){
list_add_tail(&epi->rdllink, &ep->rdllist);
}
/* 如果是边缘触发,那么就不加回可用列表,因此只能等到下一个可用事件触发的时候才会将对应的epi放到可用列表里面*/
eventcnt++
}
/* 如poll出来的revents事件epoll_wait不感兴趣(或者本来就没有事件),那么也不会加回到可用列表 */
......
}
return eventcnt;
}
上述代码逻辑如下所示:
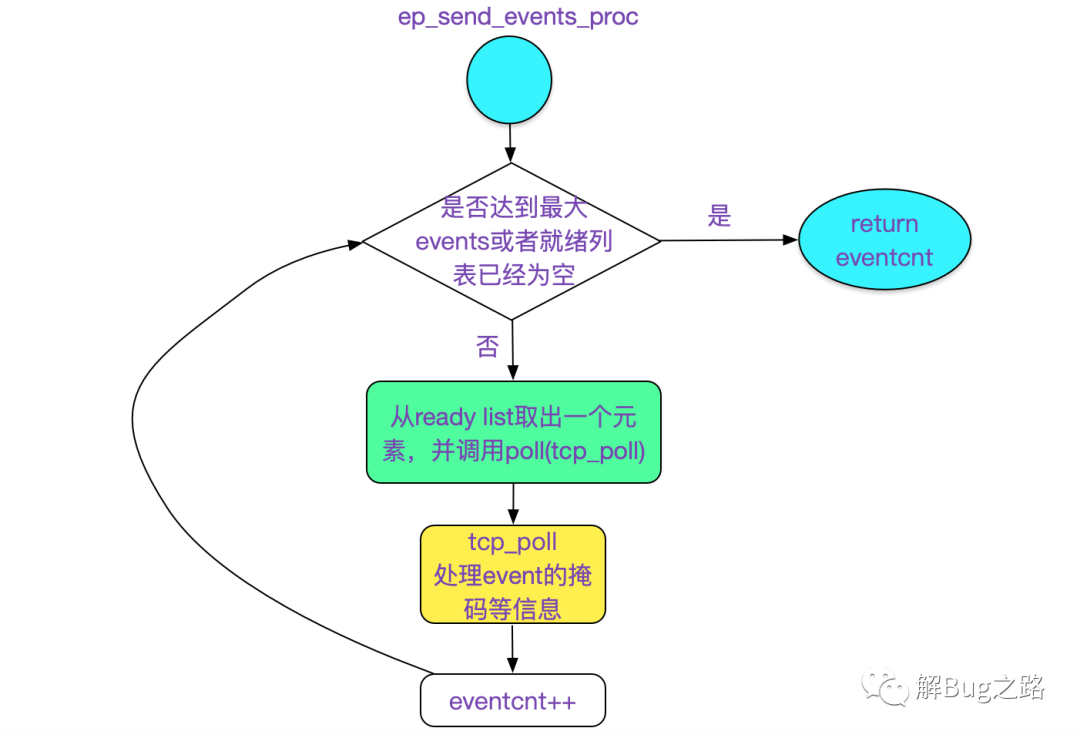
事件到来添加到epoll就绪队列(rdllist)的过程
经过上述章节的详述之后,我们终于可以阐述,tcp在数据到来时是怎么加入到epoll的就绪队列的了。
可读事件到来
首先我们看下tcp数据包从网卡驱动到kernel内部tcp协议处理调用链:
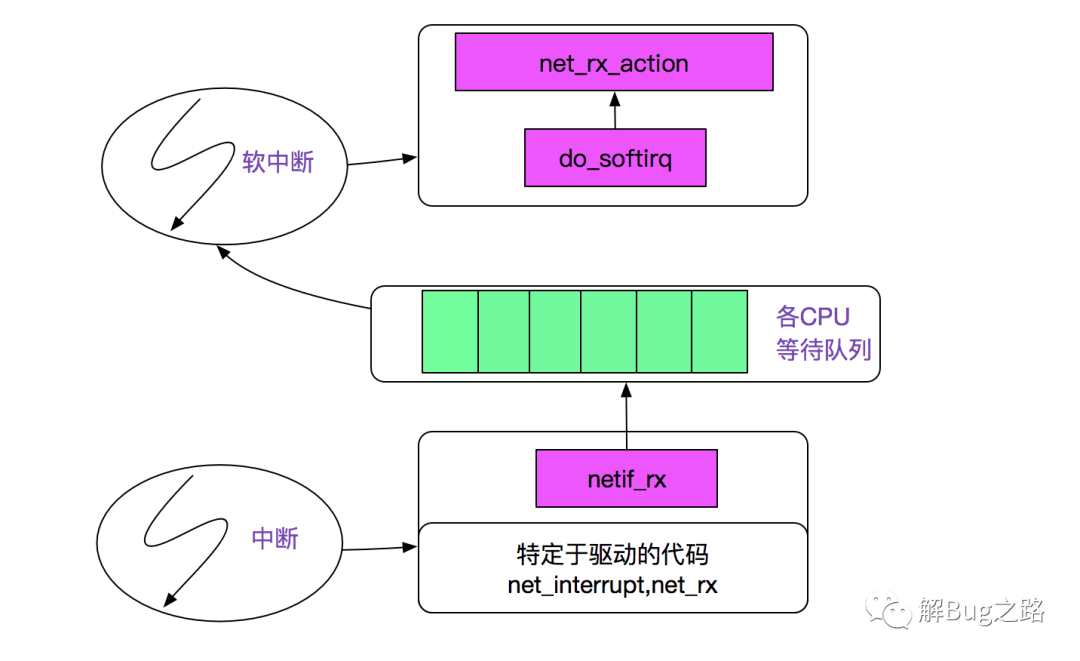
step1:
网络分组到来的内核路径,网卡发起中断后调用netif_rx将事件挂入CPU的等待队列,并唤起软中断(soft_irq),再通过linux的软中断机制调用net_rx_action,如下图所示:
注:上图来自PLKA(<<深入Linux内核架构>>)
step2:
紧接着跟踪next_rx_action
next_rx_action
|-process_backlog
......
|->packet_type->func 在这里我们考虑ip_rcv
|->ipprot->handler 在这里ipprot重载为tcp_protocol
(handler 即为tcp_v4_rcv)
我们再看下对应的tcp_v4_rcv
tcp_v4_rcv
|->tcp_v4_do_rcv
|->tcp_rcv_state_process
|->tcp_data_queue
|-> sk->sk_data_ready(sock_def_readable)
|->wake_up_interruptible_sync_poll(sk->sleep,...)
|->__wake_up
|->__wake_up_common
|->curr->func
/* 这里已经被ep_insert添加为ep_poll_callback,而且设定了排它标识WQ_FLAG_EXCLUSIVE*/
|->ep_poll_callback
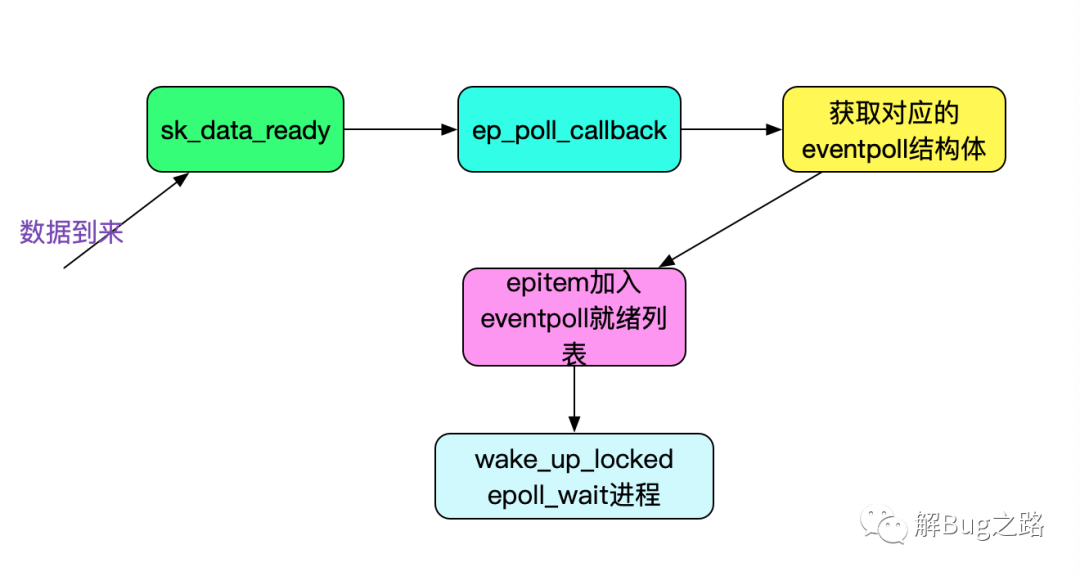
这样,我们就看下最终唤醒epoll_wait的ep_poll_callback函数:
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
// 获取wait对应的epitem
struct epitem *epi = ep_item_from_wait(wait);
// epitem对应的eventpoll结构体
struct eventpoll *ep = epi->ep;
// 获取自旋锁,保护ready_list等结构
spin_lock_irqsave(&ep->lock, flags);
// 如果当前epi没有被链入ep的ready list,则链入
// 这样,就把当前的可用事件加入到epoll的可用列表了
if (!ep_is_linked(&epi->rdllink))
list_add_tail(&epi->rdllink, &ep->rdllist);
// 如果有epoll_wait在等待的话,则唤醒这个epoll_wait进程
// 对应的&ep->wq是在epoll_wait调用的时候通过init_waitqueue_entry(&wait, current)而生成的
// 其中的current即是对应调用epoll_wait的进程信息task_struct
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
}
上述过程如下图所示:
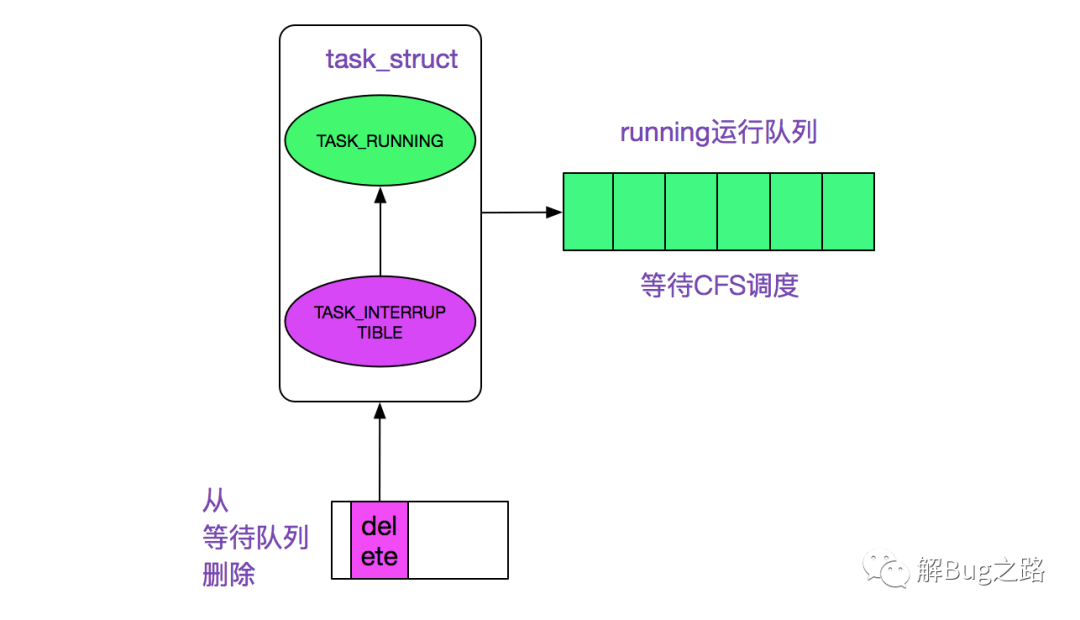
最后wake_up_locked调用__wake_up_common,然后调用了在init_waitqueue_entry注册的default_wake_function,调用路径为:
wake_up_locked
|->__wake_up_common
|->default_wake_function
|->try_wake_up (wake up a thread)
|->activate_task
|->enqueue_task running
将epoll_wait进程推入可运行队列,等待内核重新调度进程,然后epoll_wait对应的这个进程重新运行后,就从schedule恢复,继续下面的ep_send_events(向用户空间拷贝事件并返回)。
wake_up过程如下图所示:
可写事件到来
可写事件的运行过程和可读事件大同小异:
- 首先,在epoll_ctl_add的时候预先会调用一次对应文件描述符的poll,如果返回事件里有可写掩码的时候直接调用wake_up_locked以唤醒对应的epoll_wait进程。
- 然后,在tcp在底层驱动有数据到来的时候可能携带了ack从而可以释放部分已经被对端接收的数据,于是触发可写事件,这一部分的调用链为:
tcp_input.c
tcp_v4_rcv
|-tcp_v4_do_rcv
|-tcp_rcv_state_process
|-tcp_data_snd_check
|->tcp_check_space
|->tcp_new_space
|->sk->sk_write_space
/* tcp下即是sk_stream_write_space*/
最后在此函数里面sk_stream_write_space唤醒对应的epoll_wait进程
void sk_stream_write_space(struct sock *sk)
{
// 即有1/3可写空间的时候才触发可写事件
if (sk_stream_wspace(sk) >= sk_stream_min_wspace(sk) && sock) {
clear_bit(SOCK_NOSPACE, &sock->flags);
if (sk->sk_sleep && waitqueue_active(sk->sk_sleep))
wake_up_interruptible_poll(sk->sk_sleep, POLLOUT |
POLLWRNORM | POLLWRBAND)
......
}
}
关闭描述符(close fd)
值得注意的是,我们在close对应的文件描述符的时候,会自动调用eventpoll_release将对应的file从其关联的epoll_fd中删除,kernel关键路径如下:
close fd
|->filp_close
|->fput
|->__fput
|->eventpoll_release
|->ep_remove
所以我们在关闭对应的文件描述符后,并不需要通过epoll_ctl_del来删掉对应epoll中相应的描述符。
学习Linux kernel源码组好的莫过于ULK3 《深入理解Linux内核》
总结
epoll作为linux下非常优秀的事件触发机制得到了广泛的运用。其源码还是比较复杂的,本文只是阐述了epoll读写事件的触发机制,探究linux kernel源码的过程非常快乐^_^



