
CPU异常的分析定位原创
概述
12 月 30 号,天气晴,阳光明媚
今天下午项目就要上线了,我正在美滋滋的规划上线之后的生活。但是偏偏手贱,无意中打开了测试环境的服务器,发现了一个令人恐惧的事情,CPU 总利用率最高爆到了 150%。
宛如一道晴天霹雳击中我的天灵盖,瞬间冷汗直冒。明明昨天服务器还是正常的,没理由突然爆表啊?代码已经停止更新了呀,这不科学!
性能测试知识库
分析问题
下午就要上线了,这要是发到生产还得了?本着狗命要紧的态度,赶紧定位问题。
先看 top 的利用率分布
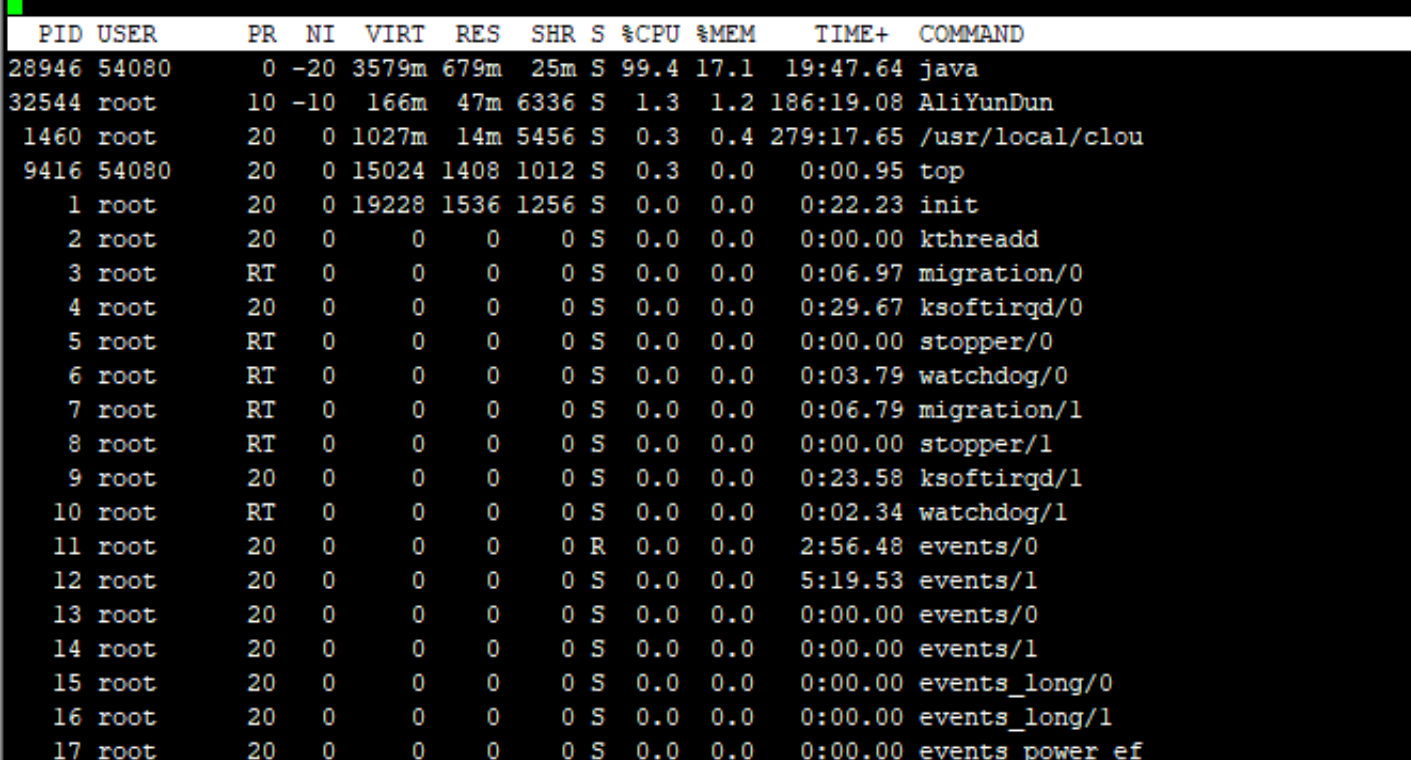
细看 CPU 单核的利用率,其实并不是很高,50% 左右。但是现在测试环境明明没有很多业务在执行。而且利用率几乎都分布在内核空间,这很明显不科学。
打印 cpu 热点
执行 perf top,看一下占用 cpu 最好的函数是什么
性能测试知识库
排名最高的是schedule,其次是system call after swapgs,第三是sched_yield。我们来分析一下这前三个排名的函数是做什么的
1.schedule:函数 schedule() 实现调度程序。它的任务是从运行队中找到一个进程,并随后将 CPU 分配给这个进程
2.system call after swapgs:这个函数是实现系统调用的。通常用户空间向内核空间发起请求时,必然会经历系统调用
3.sched_yield:在资源竞争情况很严重时,执行这个函数会主动放弃当前线程的 CPU 使用权,然后一个新的线程会占用 CPU

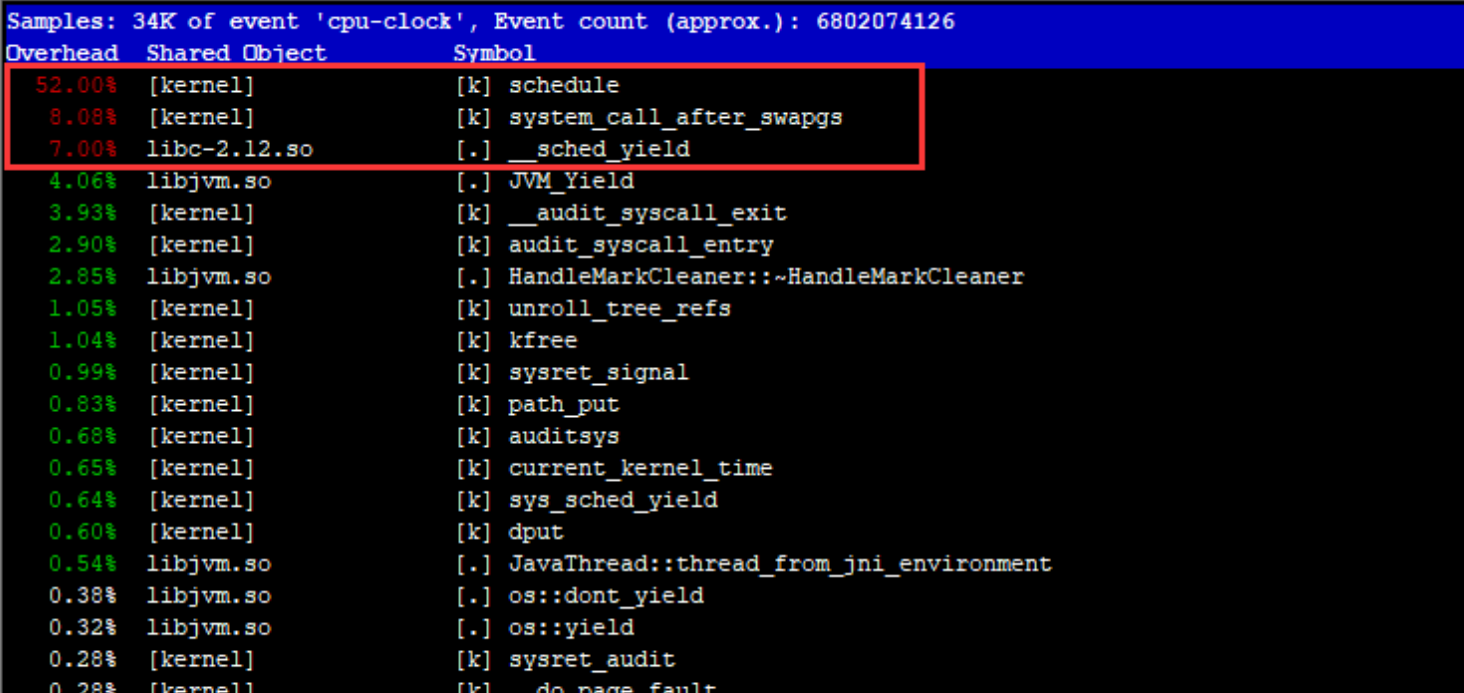
综上所述,可以大致猜测出问题的原因。一定是有大批量的任务在向内核请求系统调度,但是资源已经不足了,然后好死不死的又偏偏调用了 sched_yield 这个自毁函数,导致 cpu 的使用权被让出来。cpu 通过 schedule 函数玩命的调度切换。于是 cpu 就炸了。
性能测试知识库
定位问题
为了验证刚刚的猜测,这里做两步操作。
第一步:打印内核日志。结果发现内核里面全部在执行 sched_yield,放弃 cpu。
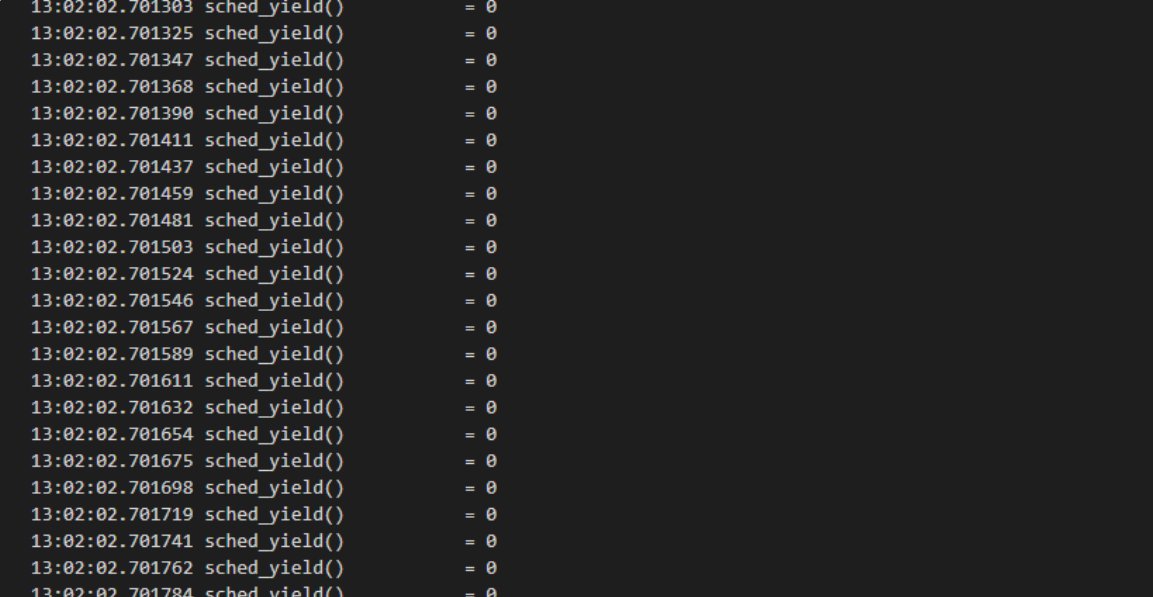
稍加思索之后,觉得应该改一个配置 ** /proc/sys/kernel/sched_compat_yield**
把这个配置从 0 改成 1,可以让 sched_yield() 系统调用更加有效,让它使用更少的 cpu。美滋滋的改完之后发现,cpu 利用率一点也没降下来。稍加思索之后想明白了,我的目的是阻断 cpu 调用 sched_yield() 而自爆,而不是让他调用的更加丝滑啊!这个方法行不通
第二步:打印线程堆栈
性能测试知识库
线程堆栈里面打印结果如下:
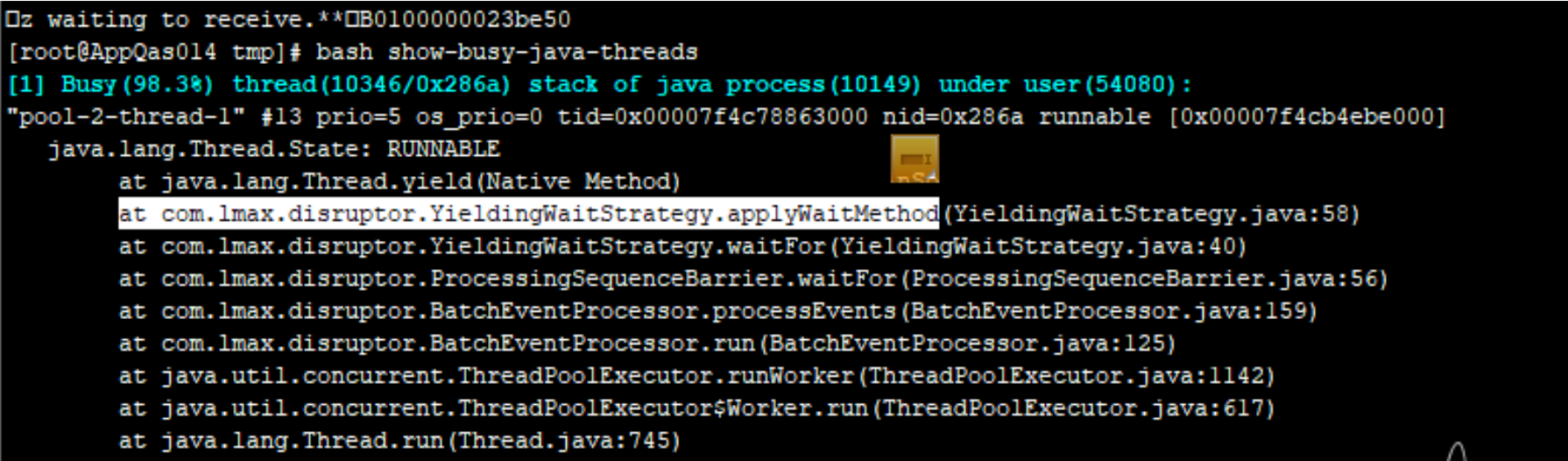
java.lang.Thread.State: RUNNABLE
at java.lang.Thread.yield(Native Method)
at com.lmax.disruptor.YieldingWaitStrategy.applyWaitMethod(YieldingWaitStrategy.java:58)
at com.lmax.disruptor.YieldingWaitStrategy.waitFor(YieldingWaitStrategy.java:40)
at com.lmax.disruptor.ProcessingSequenceBarrier.waitFor(ProcessingSequenceBarrier.java:56)
at com.lmax.disruptor.BatchEventProcessor.processEvents(BatchEventProcessor.java:159)
at com.lmax.disruptor.BatchEventProcessor.run(BatchEventProcessor.java:125)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
中间那个lmax和YieldingWaitStrategy服务是个什么玩意?在脑海里面检索了五分钟也没想到到底是个什么服务。然后百度了一下,百度给出了下面这个结论
性能测试知识库
com.lmax.disruptor是个高效的的消息队列,YieldingWaitStrategy 是它的三种策略之一。哪三种策略?如下所述
-
com.lmax.disruptor.BlockingWaitStrategy
最低效的策略,但其对 CPU 的消耗最小,并且在各种部署环境中能提供更加一致的性能表现; -
com.lmax.disruptor.SleepingWaitStrategy
性能表现和 com.lmax.disruptor.BlockingWaitStrategy 差不多,对 CPU 的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景; -
com.lmax.disruptor.YieldingWaitStrategy
性能最好,适合用于低延迟的系统;在要求极高性能且事件处理线程数小于 CPU 逻辑核心树的场景中,推荐使用此策略;
but,这个消息中间件完全脱离了产品需求,从测试到产品没人知道有这么一回事。。。
由此可以判断出,开发应该是偷偷加了一个消息中间件,并且选用了第三种看起来性能最好的策略。但是忽略了一点,这种策略对 cpu 的压榨极高,尤其是 cpu 性能不好的时候,几乎能把 cpu 榨的一滴不剩。官网描述如下

中间那个 thread.yield 就可以解释我们之前在内核空间看到的 sched_yield() 函数调用。因为资源不够,所以调用这个函数去反复循环排队,导致死循环。
最后让开发先把代码注释掉了,自己本地慢慢调试策略吧。
性能测试知识库
结尾
这件事给了我们几个教训
1:直到上线前一分钟,都要对开发的一举一动保持高度警惕
2:开发同学不要自作聪明往代码里面加一些未经验证的小发明创造,然后美滋滋的等上线。上了就炸
3:性能测试人员要学会抽丝剥茧,保留证据,同时做好和开发死磕的准备

