
【译】Netty 在Java中处理上万并发连接时,必须遵守的六大原则转载
在今天的文章中,我将讨论如果我们想要构建一个可以处理数千个连接的可扩展应用程序需要遵循的常见原则。如果您想从应用程序和底层系统中获得一些见解,我将参考 Netty 框架、TCP 和 Socket 内部结构以及一些有用的工具。
免责声明:在内存方面我会有点迂腐,因为如果我们想将处理流乘以连接数(10 000>),那么一个连接处理管道中的每一千字节都会变得非常昂贵:)
原则 1:使您的应用程序非常适合 C10K 问题
如上所述,当我们需要以最少的上下文切换和低内存占用尽可能多地利用 CPU 时,您需要使进程中的线程数非常接近专用于给定处理器的数量应用。
牢记这一点,唯一可能的解决方案是选择一些非阻塞业务逻辑或具有非常高的 CPU/IO 处理时间比率的业务逻辑(但它已经变得有风险了)。
有时,在应用程序堆栈中识别这种行为并不容易。有时,您需要重新安排应用程序/代码,添加额外的外部队列 (RabbitMQ) 或主题 (Kafka) 来更改分布式系统,以便能够缓冲任务并能够将非阻塞代码从无法使用非阻塞技术轻松重新实现的代码(例如,使用 JDBC 驱动程序,目前没有官方的关系数据库非阻塞驱动程序——据我所知,ADBC 的工作——异步数据库访问 API——已经停)。
但是,根据我的经验,由于以下原因,值得重写我的代码并使其更加非阻塞:
-
我将我的应用程序分成两个不同的应用程序,它们很可能不共享相同的部署和设计策略,即使它们共享相同的“域”(例如,应用程序的一部分是可以使用线程池实现的 REST 端点-基于 HTTP 服务器,第二部分是来自队列/主题的消费者,它使用非阻塞驱动程序向 DB 写入内容)。
-
我能够以不同的方式扩展这两个部分的实例数量,因为负载/CPU/内存很可能是完全不同的。
什么可以表明我们正在为此类应用程序使用适当的工具:
-
我们将线程数保持在尽可能低的水平。不要忘记检查您的服务器线程以及应用程序的其他部分:队列/主题使用者、数据库驱动程序设置、日志记录设置(使用异步微批处理)。始终进行线程转储以查看在您的应用程序中创建了哪些线程以及有多少线程(不要忘记在负载下进行,否则您的线程池将无法完全初始化,其中很多线程都是懒惰地创建的)。我总是从线程池中命名我的自定义线程(找到受害者并调试你的代码要容易得多)。
-
请注意阻止对其他服务的 HTTP/DB 调用,我们可以使用响应式客户端自动为传入响应注册回调。考虑使用更适合service-2-service 通信的协议,例如 RSocket。
-
检查您的应用程序是否包含持续低数量的线程。它指的是您的应用程序是否具有有限的线程池并且能够承受给定的负载。
如果您的应用程序有多个处理流程,则始终验证其中哪些是阻塞的,哪些是非阻塞的。如果阻塞流的数量很大,那么您几乎需要在不同的线程(来自预定义的线程池)上处理每个请求(至少是使用阻塞调用的处理流的一部分)来释放事件循环线程下一个连接(更多信息在下一章)。
在这种情况下,考虑将基于线程池的 HTTP Server 与工作线程一起使用,其中所有请求都放在与非常大的线程池不同的线程上以增加吞吐量—— 如果我们无法摆脱阻塞,就没有其他方法了来电。
原则 2:缓存连接,而不是线程
该原则与 HTTP Server 的编程模型主题密切相关。主要思想不是将连接绑定到单个线程,而是使用一些支持有点复杂但更有效的从 TCP 读取方法的库。
这并不意味着 TCP 连接是绝对免费的。最关键的部分是 TCP 握手。因此,您应该始终使用持久连接(keep-alive)。如果我们只使用一个 TCP 连接来发送一条消息,我们将支付 8 个 TCP 段的开销(连接和关闭连接 = 7 个段)。
接受新的 TCP 连接
如果我们处于无法使用持久连接的情况,那么我们很可能会在很短的时间内创建大量连接。这些创建的连接必须排队等待我们的应用程序接受。
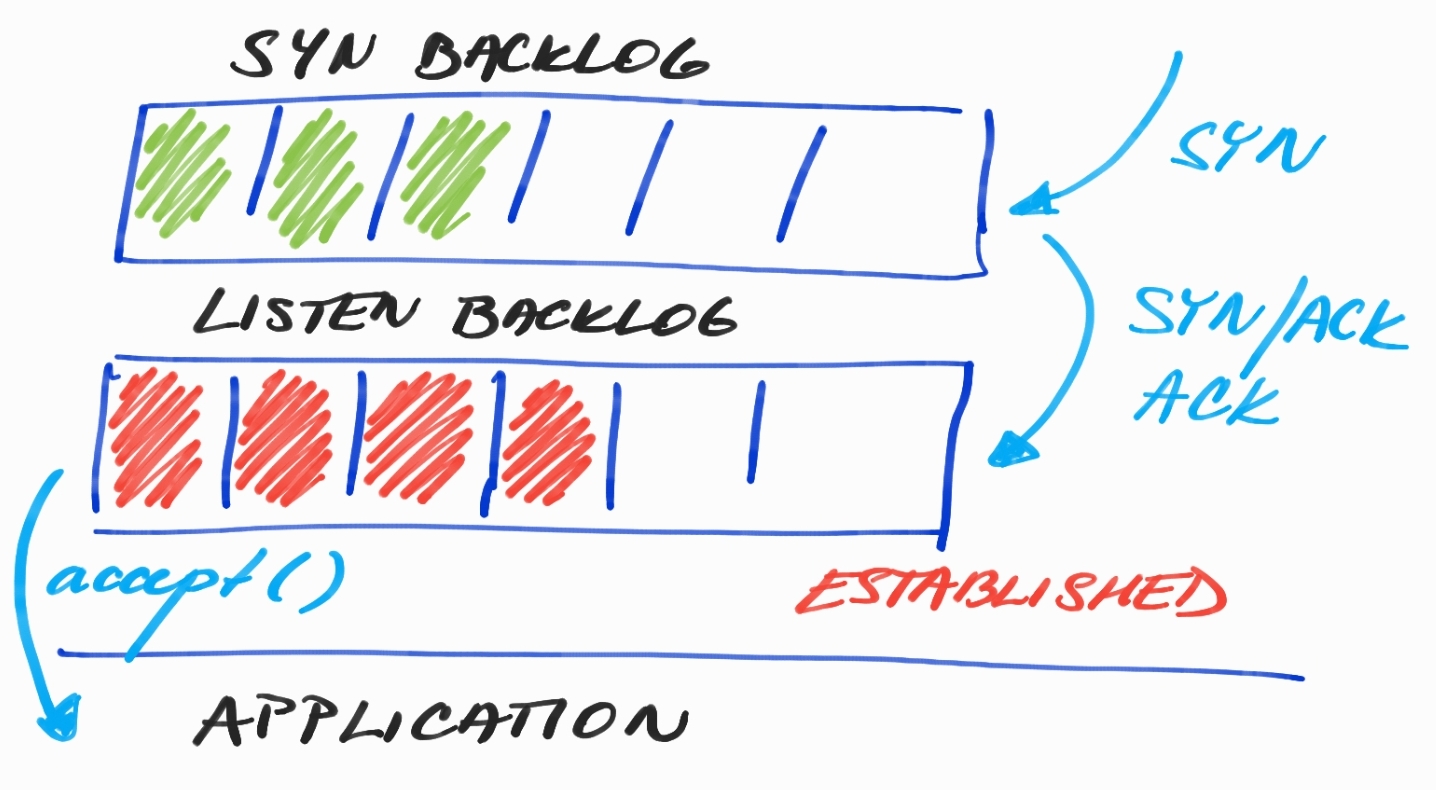
在上图中,我们可以看到积压的SYN和LISTEN。在 SYN Backlog 中, 我们可以找到正在等待使用TCP Handshake确认的连接。但是,在LISTEN Backlog 中, 我们已经完全初始化了连接,即使是TCP 发送/接收缓冲区也只是等待我们的应用程序接受。
如果您想了解更多为什么我们实际上需要两个积压工作,请 阅读SYN Flood DDoS 攻击。
实际上存在一个问题,如果我们处于负载之下并且有很多传入连接,我们负责接受连接的应用程序线程可能会忙于做一些其他工作——为已经连接的客户端做 IO。
var bossEventLoopGroup = new EpollEventLoopGroup(1);
var workerEventLoopGroup = new EpollEventLoopGroup();
new ServerBootstrap()
.channel(EpollServerSocketChannel.class)
.group(bossEventLoopGroup, workerEventLoopGroup)
.localAddress(8080)
.childOption(ChannelOption.SO_SNDBUF, 1024 * 1024)
.childOption(ChannelOption.SO_RCVBUF, 32 * 1024)
.childHandler(new CustomChannelInitializer());
bossEventLoopGroup 和 workerEventLoopGroup . While workerEventLoopGroup 默认使用 # of CPUs * 2 个线程/事件循环创建用于执行 IO 操作, bossEventLoopGroup 包含一个用于接受新连接的线程。Netty 允许两个操作只有一个组,但在这种情况下,接受新连接可能会因为在 ChannelHandlers.
如果我们遇到 LISTEN Backlog 满的问题,那么我们可以增加 bossEventLoopGroup. 我们可以很容易地测试我们的进程是否能够承受传入连接的负载。我修改了我们的测试应用程序Websocket-Broadcaster 以连接 20 000 个客户端并多次运行此命令:
-
Send-Q : LISTEN Backlog 的总大小
-
Recv-Q : LISTEN Backlog 中的当前连接数
# Current default size of LISTEN Backlog
# Feel free to change it and test SS command again
cat /proc/sys/net/core/somaxconn
128TCP 发送/接收缓冲区
但是,当您的连接准备好时,最贪婪的部分是TCP 发送/接收缓冲区 ,用于将应用程序写入的字节传输到底层网络堆栈。这些缓冲区的大小可以通过应用程序设置:
new ServerBootstrap()
.channel(EpollServerSocketChannel.class)
.group(bossEventLoopGroup, workerEventLoopGroup)
.localAddress(8080)
.childOption(ChannelOption.SO_SNDBUF, 1024 * 1024)
.childOption(ChannelOption.SO_RCVBUF, 32 * 1024)
.childHandler(new CustomChannelInitializer());在任何自定义大小之前阅读 TCP 缓冲区大小。较大的缓冲区会导致内存浪费,另一方面,较小的缓冲区会限制读取器或写入器的应用程序,因为没有任何空间可以将字节传输到网络堆栈或从网络堆栈传输字节。
为什么缓存线程是个坏主意?
如果我们使用每线程连接策略或更大的线程池来处理阻塞业务逻辑, 我们的“微”服务需要 多少内存 来处理数千个连接。
Java Thread 是一个非常昂贵的对象,因为它一对一地映射到内核线程(希望 Loom 项目能早日拯救我们)。在 Java 中,我们可以使用 默认设置为 1MB 的-Xss 选项来限制线程的堆栈大小。这意味着一个线程占用 1MB 的虚拟内存,但不占用已提交的内存。
真正的 RSS(Resident Set Size)等于栈的当前大小;内存在一开始就没有完全分配并映射到物理内存(它经常被误解,如这篇文章所示: Java 线程占用多少内存?)。通常(根据我的经验),如果我们真的不使用一些贪婪的框架或递归,线程的大小是数百千字节(200-300kB)。这种内存属于Native Memory;我们可以在 Native Memory Tracking中进行跟踪。
$ java -XX:+UnlockDiagnosticVMOptions -XX:NativeMemoryTracking=summary /
-XX:+PrintNMTStatistics -version
openjdk version "11.0.2" 2019-01-15
OpenJDK Runtime Environment AdoptOpenJDK (build 11.0.2+9)
OpenJDK 64-Bit Server VM AdoptOpenJDK (build 11.0.2+9, mixed mode)
Native Memory Tracking:
Total: reserved=6643041KB, committed=397465KB
- Java Heap (reserved=5079040KB, committed=317440KB)
(mmap: reserved=5079040KB, committed=317440KB)
- Class (reserved=1056864KB, committed=4576KB)
(classes #426)
( instance classes #364, array classes #62)
(malloc=96KB #455)
(mmap: reserved=1056768KB, committed=4480KB)
( Metadata: )
( reserved=8192KB, committed=4096KB)
( used=2849KB)
( free=1247KB)
( waste=0KB =0,00%)
( Class space:)
( reserved=1048576KB, committed=384KB)
( used=270KB)
( free=114KB)
( waste=0KB =0,00%)
- Thread (reserved=15461KB, committed=613KB)
(thread #15)
(stack: reserved=15392KB, committed=544KB)
(malloc=52KB #84)
(arena=18KB #28)
大量线程的另一个问题是巨大的 Root Set。例如,我们有 4 个 CPU 和 200 个线程。在这种情况下,我们仍然只能在给定时间运行 4 个线程,但是如果所有 200 个线程都已经忙于处理某个请求,我们会为已经在 Java Heap 上分配但无法生成任何对象的对象付出巨大的代价进度,因为给定线程等待 CPU 时间。所有已分配且仍在使用的对象都是 Live Set 的一部分(在垃圾收集周期中必须遍历且无法收集的可达对象)。
为什么根集如此重要?
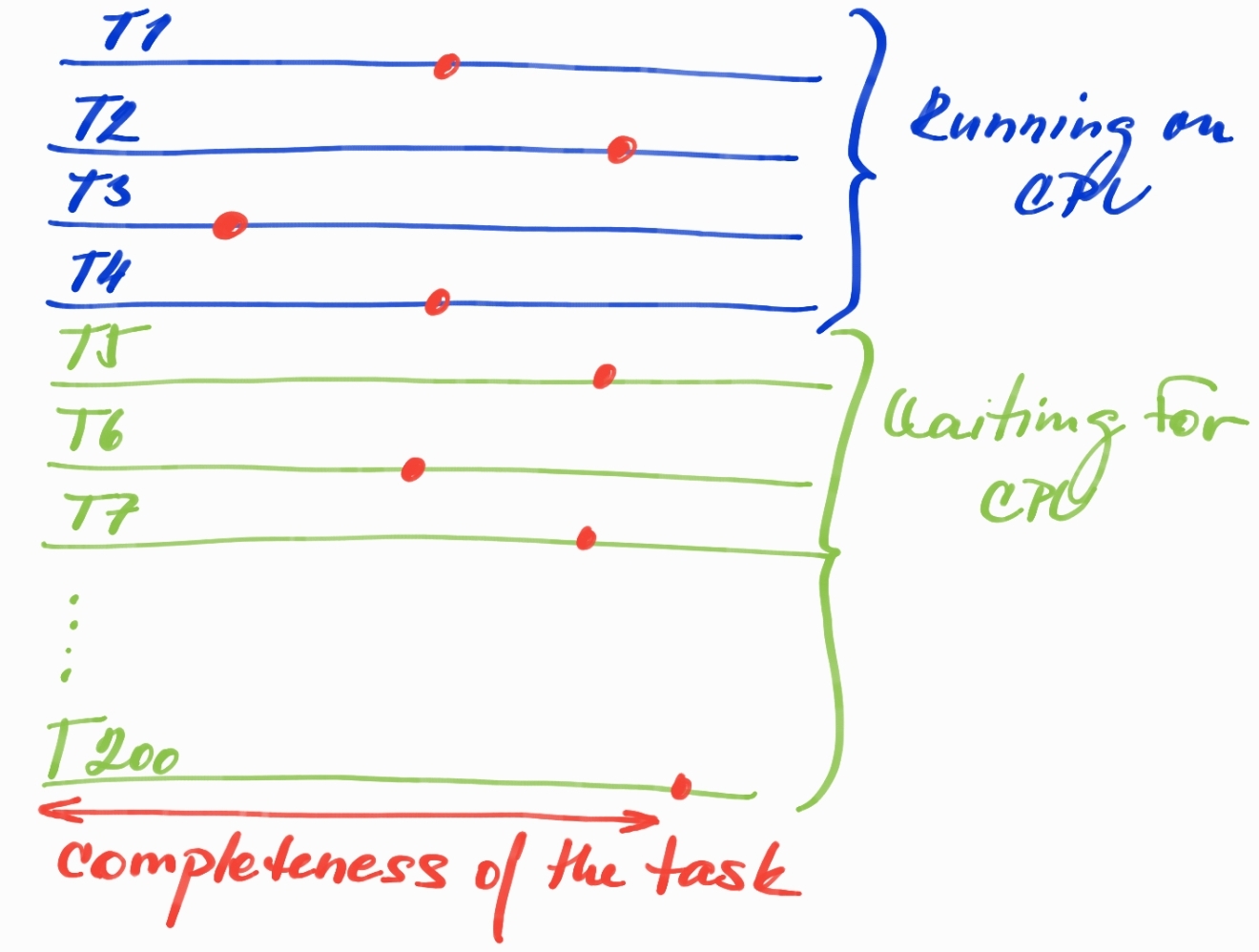
红点可以表示当前只有 4 个线程在 CPU 上运行而其余线程仅在 CPU Run Queue中等待的任何时间点。任务的完成并不意味着到目前为止分配的所有对象都还活着并且是 Live Set的一部分,它们已经可以变成垃圾,等待下一个 GC 周期被移除。这种情况有什么不好?
-
Too big Live Set:每个线程都在 Java Heap 上保留分配的活动对象,这些对象只是等待 CPU 取得一些进展。当我们以这种方式使用大量内存的堆大小时,我们需要牢记这一点 - 效率非常低 - 特别是如果我们想要设计处理大量请求的小型服务。
-
由于更大的根集,更大的 GC 暂停:更大的根集对我们的垃圾收集器 来说意味着一项复杂的工作。现代 GC 从识别 Root Set 开始(也称为Snapshot-at-the-beginning 或initial-mark,主要是活动线程将分配的可访问对象保持在堆外 - 但不仅仅是线程),然后并发遍历对象图/查找当前Live Set的参考资料。Root Set 越大,GC 识别和遍历它的工作就越多,而且,initial-mark通常是被称为Stop-the-world 的阶段阶段。并发遍历巨大的对象图也可能导致大的延迟和 GC 本身的更差的可预测性(GC 必须更早地启动并发阶段以使其在堆满之前达到,这也取决于分配率)。
-
对老一代的提升:更大的 Live Set 也会影响给定对象被视为活动对象的时间。这增加了该对象被提升为老年代(或至少为生存空间)的机会,即使保留该对象的线程大部分时间都在 CPU 之外。
原则 3:停止产生垃圾
如果您真的想编写一个将承受大负载的应用程序,那么您需要考虑所有对象的分配,并且不要让 JVM 浪费任何单个字节。这使我们 往返于ByteBuffers Netty ByteBuf 。这是非常先进的,因此非常简短。
ByteBuffers 是字节的 JDK 持有者。有两个选项HeapByteBuffer (在堆上分配的字节数组)和 DirectByteBuffer(堆外内存)。主要原因是DirectByteBuffers可以直接传递给本机 OS 函数来执行 I/O —— 换句话说,当你在 Java 中执行 I/O 时,你传递了一个引用DirectByteBuffer (带有偏移量和长度)。
这可以在许多用例中提供帮助。想象一下,您有 10k 个连接,并希望向所有连接广播相同的字符串值。没有理由传递字符串并导致相同的字符串将被映射到字节 10k 次(或者更糟糕的是,为每个客户端连接生成新的字符串对象并用相同的字节数组污染堆 - 并希望字符串去重机制将很快到位)。相反,我们可以生成自己的DirectByteBuffer 并将其提供给所有连接,让它们通过 JVM 将其传递给操作系统。
但是,有一个问题。DirectByteBuffer 分配起来非常昂贵。因此在 JDK 中,每个执行 I/O 的线程(而不是DirectByteBuffers 从我们的应用程序逻辑中消耗生成)都会缓存一个DirectByteBuffer 供内部使用。
但是,HeapByteBuffer 如果我们仍然需要将其转换为DirectByteBuffer 内部以便能够将其写入操作系统,为什么还需要呢?这是真的,但 HeapByteBuffer 在分配方面要便宜得多。如果我们考虑上面的例子,我们至少可以消除第一步——将字符串编码到字节数组中(而不是做 10k 次),然后我们可以依靠 DirectByteBuffer for each 的自动缓存机制JDK 中的线程 并且不必 DirectByteBuffer 为每个新的字符串消息分配新的代价,否则我们需要在我们的业务代码中开发自己的缓存机制。
哪个选项更好?我们什么时候想使用DirectByteBuffer而不使用缓存,什么时候使用 HeapByteBuffer并依靠自动缓存机制更好?我们需要试验和测量。
我提到ByteBuf 了 Netty 的机制。它实际上是这样的概念 ByteBuffer;但是,我们可以享受基于 2 个索引(一个用于读取,一个用于写入)的便捷 API。另一个区别是回收内存。DirectByteBuffer 基于 JDK Cleaner 类。
这意味着我们需要运行 GC,否则我们会耗尽本机内存。对于非常优化的应用程序来说,这可能是一个问题,不会在堆上分配,这意味着不会触发任何 GC。然后我们需要依靠显式 GC ( System#gc()) 来救援并为下一次本地分配回收足够的内存。
NettyByteBuf 可以创建两个版本:pooled和unpooled,本机内存的释放(或将缓冲区放回池)基于引用计数机制。这是某种额外的手动工作。当我们想减少引用计数器时需要写,但它解决了上面提到的问题。
原则 4:衡量您在高峰时段产生的负载类型
如果你想深入了解 TCP 层,那么我强烈推荐:
使用 bpftrace, 我们可以编写一个简单的程序来快速获得结果并能够调查问题。这是 socketio-pid.bt的示例,显示了基于 PID 粒度传输了多少字节。
#!/snap/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
printf("Socket READS/WRITES and transmitted bytes, PID: %u\n", $1);
}
kprobe:sock_read_iter,
kprobe:sock_write_iter
/$1 == 0 || ($1 != 0 && pid == $1)/
{
@kiocb[tid] = arg0;
}
kretprobe:sock_read_iter
/@kiocb[tid] && ($1 == 0 || ($1 != 0 && pid == $1))/
{
$file = ((struct kiocb *)@kiocb[tid])->ki_filp;
$name = $file->f_path.dentry->d_name.name;
@io[comm, pid, "read", str($name)] = count();
@bytes[comm, pid, "read", str($name)] = sum(retval > 0 ? retval : 0);
delete(@kiocb[tid]);
}
kretprobe:sock_write_iter
/@kiocb[tid] && ($1 == 0 || ($1 != 0 && pid == $1))/
{
$file = ((struct kiocb *)@kiocb[tid])->ki_filp;
$name = $file->f_path.dentry->d_name.name;
@io[comm, pid, "write", str($name)] = count();
@bytes[comm, pid, "write", str($name)] = sum(retval > 0 ? retval : 0);
delete(@kiocb[tid]);
}
END
{
clear(@kiocb);
}我可以看到五个名为server-io-x 的Netty 线程,每个线程代表一个event-loop。每个事件循环都有一个连接的客户端,应用程序使用 Websocket 协议向所有连接的客户端广播随机生成的字符串消息。
-
@bytes — 读/写字节的总和
-
@io — 总共有多个读/写操作(1 个读消息代表 Websocket 握手)
./socketio-pid.bt 27069
Attaching 6 probes...
Socket READS/WRITES and transmitted bytes, PID: 27069
^C
@bytes[server-io-3, 27069, read, TCPv6]: 292
@bytes[server-io-4, 27069, read, TCPv6]: 292
@bytes[server-io-0, 27069, read, TCPv6]: 292
@bytes[server-io-2, 27069, read, TCPv6]: 292
@bytes[server-io-1, 27069, read, TCPv6]: 292
@bytes[server-io-3, 27069, write, TCPv6]: 1252746
@bytes[server-io-1, 27069, write, TCPv6]: 1252746
@bytes[server-io-0, 27069, write, TCPv6]: 1252746
@bytes[server-io-4, 27069, write, TCPv6]: 1252746
@bytes[server-io-2, 27069, write, TCPv6]: 1252746
@io[server-io-3, 27069, read, TCPv6]: 1
@io[server-io-4, 27069, read, TCPv6]: 1
@io[server-io-0, 27069, read, TCPv6]: 1
@io[server-io-2, 27069, read, TCPv6]: 1
@io[server-io-1, 27069, read, TCPv6]: 1
@io[server-io-3, 27069, write, TCPv6]: 1371
@io[server-io-1, 27069, write, TCPv6]: 1371
@io[server-io-0, 27069, write, TCPv6]: 1371
@io[server-io-4, 27069, write, TCPv6]: 1371
@io[server-io-2, 27069, write, TCPv6]: 1371
原则 5:吞吐量和延迟之间的平衡
如果您考虑应用程序性能,您很可能最终会在吞吐量和延迟之间进行权衡。这种权衡涉及到所有编程领域,JVM 领域的一个著名示例是垃圾收集器:您是想在某些批处理应用程序中使用 ParallelGC 专注于吞吐量,还是需要低延迟大多数并发 GC,例如雪兰多GC还是ZGC?
但是,在这一部分中,我将关注一种不同类型的权衡,它可以由我们基于 Netty 的应用程序或框架驱动。假设我们有将消息推送到连接的客户端的 WebSocket 服务器。我们真的需要尽快发送特定消息吗?或者可以等待更长的时间,然后创建一批 5 条消息并将它们一起发送?
Netty 实际上支持完美覆盖这个用例的刷新机制。假设我们决定使用批处理将系统调用摊销到 20% 并牺牲延迟以支持整体吞吐量。
请查看我的JFR Netty Socket 示例,进行以下更改:
pbouda.jfr.sockets.netty.server.SlowConsumerDisconnectHandler:- we need to comment out flushing of every message and use simple write instead- write method does not automatically write data into the socket, it waits for a flush context.writeAndFlush(obj) -> context.write(obj)pbouda.jfr.sockets.netty.Start#main
如果您安装了包含 Java Flight Recorder Streaming 功能的 Java 14,那么您可以看到 Netty 在这种情况下实际做了什么。
Broadcaster-Server 2020-01-14 22:12:00,937 [client-nioEventLoopGroup-0] INFO p.j.s.n.c.WebSocketClientHandler - Received message: my-message (10 bytes)
Broadcaster-Server 2020-01-14 22:12:00,937 [client-nioEventLoopGroup-0] INFO p.j.s.n.c.WebSocketClientHandler - Received message: my-message (10 bytes)
Broadcaster-Server 2020-01-14 22:12:00,938 [client-nioEventLoopGroup-0] INFO p.j.s.n.c.WebSocketClientHandler - Received message: my-message (10 bytes)
Broadcaster-Server 2020-01-14 22:12:00,938 [client-nioEventLoopGroup-0] INFO p.j.s.n.c.WebSocketClientHandler - Received message: my-message (10 bytes)
Broadcaster-Server 2020-01-14 22:12:00,939 [client-nioEventLoopGroup-0] INFO p.j.s.n.c.WebSocketClientHandler - Received message: my-message (10 bytes)
jdk.SocketWrite {
startTime = 22:12:01.603
duration = 2.23 ms
host = ""
address = "127.0.0.1"
port = 42556
bytesWritten = 60 bytes
eventThread = "server-nioEventLoopGroup-1" (javaThreadId = 27)
stackTrace = [
sun.nio.ch.SocketChannelImpl.write(ByteBuffer[], int, int) line: 167
io.netty.channel.socket.nio.NioSocketChannel.doWrite(ChannelOutboundBuffer) line: 420
io.netty.channel.AbstractChannel$AbstractUnsafe.flush0() line: 931
io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.flush0() line: 354
io.netty.channel.AbstractChannel$AbstractUnsafe.flush() line: 898
...
]
}
jdk.SocketRead {
startTime = 22:12:01.605
duration = 0.0757 ms
host = ""
address = "127.0.0.1"
port = 8080
timeout = 0 s
bytesRead = 60 bytes
endOfStream = false
eventThread = "client-nioEventLoopGroup-0" (javaThreadId = 26)
stackTrace = [
sun.nio.ch.SocketChannelImpl.read(ByteBuffer) line: 73
io.netty.buffer.PooledByteBuf.setBytes(int, ScatteringByteChannel, int) line: 247
io.netty.buffer.AbstractByteBuf.writeBytes(ScatteringByteChannel, int) line: 1147
io.netty.channel.socket.nio.NioSocketChannel.doReadBytes(ByteBuf) line: 347
io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read() line: 148
...
]
}
连接的客户端收到了 5 条消息,但我们只能看到一个 socket-read 和 socket-write 并且都包含整批消息的所有字节。
如果您想了解有关 Java Flight Recorder 的更多信息,请阅读我的文章 Digging Into Sockets With Java Flight Recorder。
原则 6:紧跟新趋势并不断尝试
在这一部分中,我想非常简要地介绍两个目前正在被讨论并成为处理大量客户端/请求的重要选项的概念,即使它们与解决 C10K 问题没有明确的联系,但它绝对可以提供帮助您使用单节点应用程序的整体架构或处理更大负载的一组服务。
GraalVM Native-Image 以节省资源
GraalVM 目前在提前编译器上工作,该编译器能够与新增长的SubstrateVM一起运行可执行文件。简而言之,这意味着在构建时使用 Graal Compiler 来生成机器代码,而无需任何分析数据。你可以问:如果我们生成的机器代码的效率肯定低于使用即时编译器生成的机器代码,这如何帮助我们解决 C10K 问题?答案是不!不会帮你的!
但是,它将生成一个自包含的简约二进制文件,没有任何未使用的类/方法、JIT 数据结构等内部结构、无分析、动态代码缓存、更简单的 GC 以及 GC 和结构。
上面的这些优化确保我们能够以低得多的占用空间运行我们的应用程序,即使应用程序的代码效率较低,与 JIT 的情况相比,我们最终可以在消耗的内存和处理的请求总数之间获得更好的比率. 这意味着我们能够部署此应用程序的多个实例,并且它可能会以更少的资源提供更好的吞吐量。
这只是一个想法,我们总是需要衡量。本机映像的目标平台是无服务器提供商,我们需要在其中部署占用空间较小且启动时间非常短的小型应用程序。
Project Loom 来消除我们因阻塞呼叫而产生的痛苦
你可能听说过纤维/绿色线程/goroutines。所有这些术语都代表一个概念。他们希望避免在内核空间中进行线程调度,并将此责任至少部分转移到用户空间。一个典型的例子是我们有很多阻塞调用,我们对应用程序的每个请求都以 JDBC/HTTP/.. 调用结束,我们需要阻塞当前的 java 线程(即一对一映射到内核线程)并等待直到响应返回。
这些应用程序最终必须使用大量线程来扩展请求处理,而我们已经讨论过的方式根本没有效率。但是,我们可以使用Project Loom中的 Fibers 。它确保阻塞调用实际上不会阻塞 java 线程,而只会阻塞当前纤程。因此,我们可以在当前运行的 java 上调度一个新的纤程,然后在阻塞调用完成后回到原来的纤程。这样做的结果是,即使 Java 线程数量非常有限,我们也能够处理所有请求,因为发射纤维“几乎”是免费的(数百字节来处理执行上下文和非常快速的初始化),至少与一个真正的 Java 线程。
这仍在进行中,Fibers 尚未合并到主线,但它是修复充满 JDBC 调用的遗留代码的一个非常有前途的功能。
概括
试图击败 C10K 问题主要是关于资源效率。当我们开始接受数千个并发连接时,对于数十/数百个并行用户来说绝对没问题的代码可能会非常严重地失败。
可以肯定地说,此应用程序不适合为如此大量的连接而开发,我们可以避免高级功能的复杂性,以节省内存中的每个字节。但是,如果我们需要处理大量客户端,那么了解它并从头开始设计我们的高吞吐量应用程序总是好的。
感谢您阅读我的文章,请在下方发表评论。如果您想收到有关新帖子的通知,请开始在 Twitter 上关注我!


