
【译】为什么我的数据库很慢,10 个查询反而比 1 个查询更快?转载
在 Ufonia,我们最近解决了一个数据库性能问题,最后的解决方案在意料之外,但也在情理之中。
对于许多学习 UI、API 和数据模型的工程师来说,构建待办事项或 Twitter 克隆是一种通用办法。首先构建一个看起来像这样的 RESTful API:
GET /tweets
GET /tweets/id
POST /tweets
GET /users
GET /users/id
然后通过从 API 加载最新的 10 条推文来构建提要。最后决定要显示推文的作者,因此对于每条推文,你都请求获取作者。这里遇到了 N+1 的问题,对于 tweets 数组中的每个元素,都需要单独调用 API 来获取作者:
GET /tweets?orderBy=createdAt,DESC&limit=10
[
{
"id": 1,
"contents": "这是我第一篇文章!",
"authorId": 4
},
{
"id": 2,
"contents":
“hello world!”,
“ID”:7
}
...
]GET /users/4
{
"id": 4,
"firstName": "Mahatma",
"lastName": "Gandhi"
}GET /users/7
{
"id": 7,
"firstName": "Florence",
"lastName": "Nightingale"
}
然后,您会遇到通过将关系嵌入推文的原始表示来降低 API 的“纯度”的想法,因为你几乎总是需要这种关系:
GET /tweets?orderBy=createdAt,DESC&limit=10
[
{
"id": 1,
"contents": "这是我的第一篇文章!",
"author": {
"id": 4,
"firstName": "Mahatma" ,
"lastName": "Gandhi"
}
},
{
"id": 2,
"contents": "Hello world!",
"author": {
"id": 7,
"firstName": "Florence",
"lastName" :“夜莺”
}
}
...
]
现在只需要调用一次API,减少了前后端之间、后端和数据库之间的流量。后端可以使用 a 只进行一次查询,而不是进行 11 次数据库查询(10 条推文一个,然后每个作者 1 个),LEFT JOIN从而提高应用程序的性能:
SELECT * FROM Tweet
JOIN User ON User.id = Tweet.authorId
ORDER BY Tweet.createdAt DESC
LIMIT 10;这会从数据库中返回 10 行,其中作者在一行。如果每条推文有 3 个主题标签,您可以LEFT JOIN在主题标签表中包含另一个,给出 30 行。
读到这里的任何软件工程师都应该点头同意,认识到这些概念是如何被引入的。这意味着从这里到您将在工作中构建的应用程序有一条直线路径。但现实世界的应用程序比待办事项应用程序或 Twitter 克隆更复杂,并且具有更复杂的数据模型,而在数据库性能方面,这种差异确实很重要。你不能简单地继续应用你学到的技术。在某些时候,您会遇到像我们一样的问题……
我们的自动化临床助理Dora会在一周内的固定时间/天呼叫医院路径上的所有患者。我们创建一个CallList,这是我们本周为该路径安排的呼叫列表。每个ScheduledCall都有几个电话号码,我们可以尝试联系患者,当 a运行时,我们每次给患者打电话时CallList都会创建一个,并将其记录在. 在与患者通话期间,我们了解各种信息,例如他们的膝盖是否有疼痛。这些来自电话。所以我们有实体:CallScheduledCallSymptoms
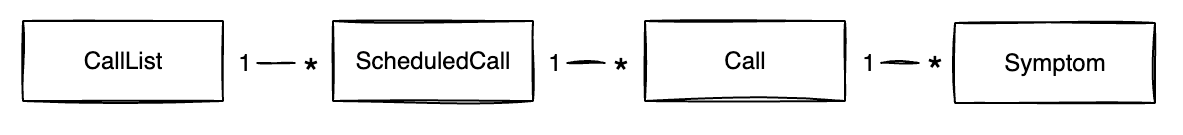
现在,如果在查看 时CallList,您想通过查看高级绿色/琥珀色/红色状态来一眼了解它的进展情况怎么办?我们对患者的了解程度是我们的核心指标,因此状态基于Symptoms我们成功收集的百分比:
≥ 95% = 绿色
95% 到 75% 之间 = 琥珀色
< 75% = 红色
要解决这个问题,您需要先加载CallList,然后加载所有相关ScheduledCalls,然后加载所有相关 ,再加载Calls所有相关Symptoms,检查有多少Symptom.value !== null,然后映射到 RAG 状态。如果我们给 100 个病人打电话,我们必须尝试平均给每个病人打电话 2 次才能让他们接电话,而对于这个路径,我们需要收集 15 个Symptoms,我们需要加载 100*2*15 = 3,000 条信息找出状态。
在构建软件应用程序时,工程师知道与内存操作相比,网络速度慢且不可靠,因此当面临需要加载 3,000 条信息时,您将寻找不涉及制作 3,000 数据库的解决方案查询。鉴于在A has many Bs领域模型中如此清晰的心智模型,aLEFT JOIN似乎是一个明智的选择(并且是像 TypeORM 这样的 ORM 会鼓励您使用关系做的事情)。所以加载数据的最佳方式似乎是使用以下查询:
SELECT * FROM CallList
LEFT JOIN ScheduledCall ON ScheduledCall.callListId = CallList.id LEFT JOIN Call ON Call.scheduledCallId = ScheduledCall.id
LEFT JOIN Symptom ON Symptom.callId = Call.id
WHERE CallList.id = 1;尽管查询似乎很长,但软件工程师会很高兴她只查询数据库一次(不是 3,000 次!),因此应该会看到出色的性能。这里的问题是,如果有两个以上JOINs(取决于数据量),数据库将变得非常慢,每个额外JOIN的查询响应时间都会增加。
这个问题的解决方案是(违反直觉)进行多个数据库查询。这个想法是,您可以将在代码中轻松遍历属性与在数据库中查找主键的速度结合起来。Typescript 之间计算工作量的差异:
callList.scheduledCalls;
和 SQL:
左加入 ScheduledCall ON ScheduledCall.id = CallList.id
意味着通过对每个实体类型执行一个新查询来帮助数据库遍历实体图是有意义的:
async function getCallListAndStatusRelations(id: string): Promise<CallList> {
const callList = await entityManager.findOne(CallList, id);
const scheduledCalls = await entityManager.find(ScheduledCall, {
where: {
callListId: callList.id
}
});
const calls = await entityManager.find(Call, {
where: {
scheduledCallId: In(scheduledCalls.map(sc => sc.id)
}
});
const symptoms = await entityManager.find(Symptom, {
where: {
callId: In(calls.map(c => c.id)
}
});
// ...
}这会产生 4 个 SQL 查询:
SELECT * FROM CallList WHERE id = '1';
SELECT * FROM ScheduledCall WHERE callListId IN ('1');
SELECT * FROM Call WHERE scheduledCallId IN ('some', 'ids');
SELECT * FROM Symptom WHERE callId IN ('lots', 'more', 'identifiers');这些中的每一个都非常简单且执行起来很便宜,因为它们只是查询每个表的主键。
难题的最后一部分是如何在内存中将实体图重新连接在一起,因为我们有 4 个彼此不知道的查询结果。
async function getCallListAndStatusRelations(id: string): Promise<CallList> {
// ...
calls.forEach(c =>
c.symptoms = symptoms.filter(s => s.callId === c.id)
);
scheduledCalls.forEach(sc =>
sc.calls = calls.filter(c => c.scheduledCallId === sc.id)
);
callList.scheduledCalls = scheduledCalls;
return callList;
}在这里,我们得到的结果与创建LEFT JOINs. (这也将显着减少 RAM 占用;事实上,OutOfMemory 异常向我们表明LEFT JOIN查询存在问题)。
要点:
- 真实世界的数据模型比待办事项应用程序或 Twitter 克隆更丰富、更复杂
- JOIN 只能在一定程度上提高性能(从那时起,情况会变得更糟)
- 软件运行时和数据库引擎擅长不同的事情,你应该利用它来发挥自己的优势
这是完整的方法:
async function getCallListAndStatusRelations(id: string): Promise<CallList> {
const callList = await entityManager.findOne(CallList, id);
const scheduledCalls = await entityManager.find(ScheduledCall, {
where: {
callListId: callList.id
}
});
const calls = await entityManager.find(Call, {
where: {
scheduledCallId: In(scheduledCalls.map(sc => sc.id)
}
});
const symptoms = await entityManager.find(Symptom, {
where: {
callId: In(calls.map(c => c.id)
}
});
calls.forEach(c =>
c.symptoms = symptoms.filter(s => s.callId === c.id)
);
scheduledCalls.forEach(sc =>
sc.calls = calls.filter(c => c.scheduledCallId === sc.id)
);
callList.scheduledCalls = scheduledCalls;
return callList;
}注 1:此示例有些简化,因此读者可能会认为 SQL 查询中的聚合函数是最佳选择。这在此处是正确的,但 a 的状态CallList不仅仅取决于,因此内存中需要、、、和其他几个表Symptoms的整个实体。CallListScheduledCallsCallsSymptoms
注意 2:TypeORM 最近在0.3.0 版本relationLoadStrategy中引入了一个选项,它在内部采用了类似的方法。这不是很好的路标,并且存在重大问题,因此您可能可以使用内置选项,但了解基本原理将为您提供非面包和黄油场景中的逃生舱口。
原文链接:https://medium.com/ufonia/why-is-my-database-slow-when-10-queries-are-faster-than-1-76712dca9c34


