
覆盖索引是提高 SQL 性能的优化之一。
要了解覆盖索引,需要了解 MySQL 中索引的物理结构。
📌 B+树
InnoDB 索引是 B+Tree 数据结构,空间索引除外。
(InnoDB 是 MySQL 中的通用存储引擎。)
B+Tree是B-Tree的扩展;允许搜索、顺序访问、插入和删除的自平衡树数据结构。
(仅供参考。在树数据结构中,每个数据块称为节点或页面。)
B+Tree 和 B-Tree 的区别在于下面列出的两件事。
1.只有叶子节点存储实际数据
与所有节点都存储键和数据的 B-Tree 相比,在 B+Tree 中,只有叶节点具有这些键和数据。根节点和内部节点(顶部和中间节点)只保存密钥,它指向存储实际数据的节点的地址。
2.所有兄弟节点都链接在一个链表中
同级节点知道前一个节点和下一个节点在哪里,持有它们的地址指针。当 InnoDB 执行全扫描时,可以快速搜索以通过线性扫描找到特定块。
📌 聚集索引 VS 非聚集索引
InnoDB 中有两种类型的索引;聚集索引和非聚集索引。
聚集索引
一个数据库表总是有一个聚集索引树。
创建表时,您将设置主键 (PK)。当您在列上创建主键时,将默认创建聚集索引。
但是,如果您不设置 PK,它将使用唯一键创建聚集索引。Unique Keys 不是偶数个,所以 InnoDB 内部会生成一个 6 字节的隐藏键,并用它来组织聚集索引树。
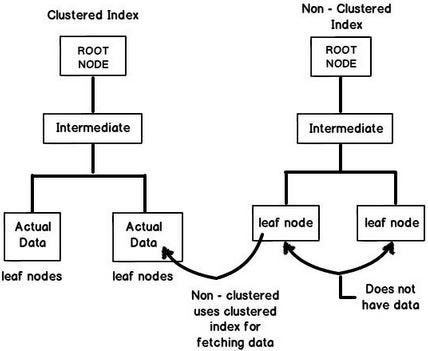
聚集索引最关键的特性是叶节点保存实际数据。如上图所示,它可以直接查找数据。
非聚集索引
一个数据库表可以有一个或多个非聚集索引。
当您创建唯一键或公共索引约束时,将生成需要额外磁盘空间的非聚集索引。
非聚集索引没有实际数据,而是包含指向存储在聚集索引中的数据的指针。
📌 覆盖指数
覆盖索引仅访问索引而不访问实际数据块。因为不需要访问磁盘 I/O,它可以优化搜索查询。
然后,我们来测试一下覆盖指数可以优化到多高。
环境
首先,让我们检查一下测试环境。
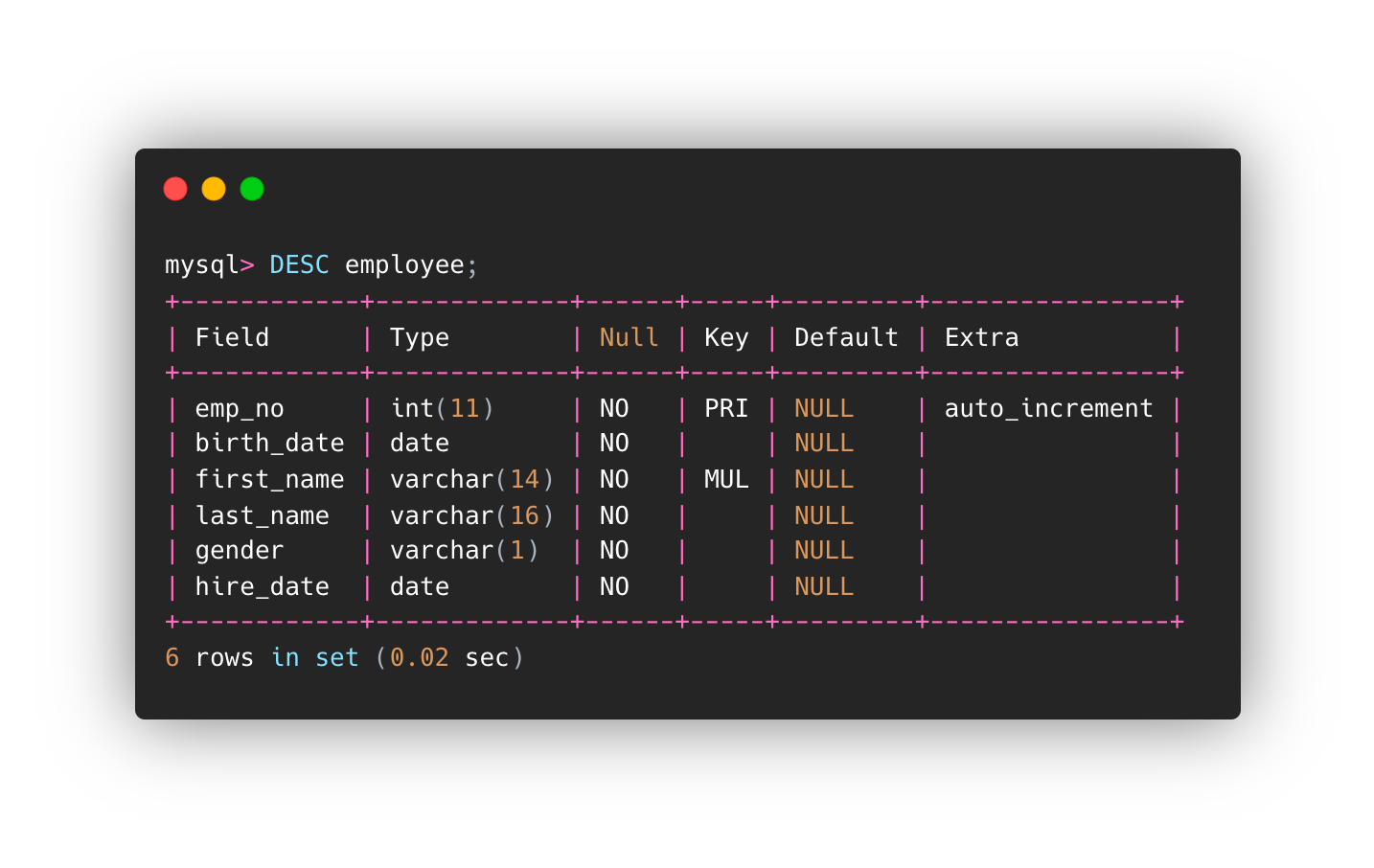
MySQL 版本是 8.0.17,我使用了雇员表,如下所示。
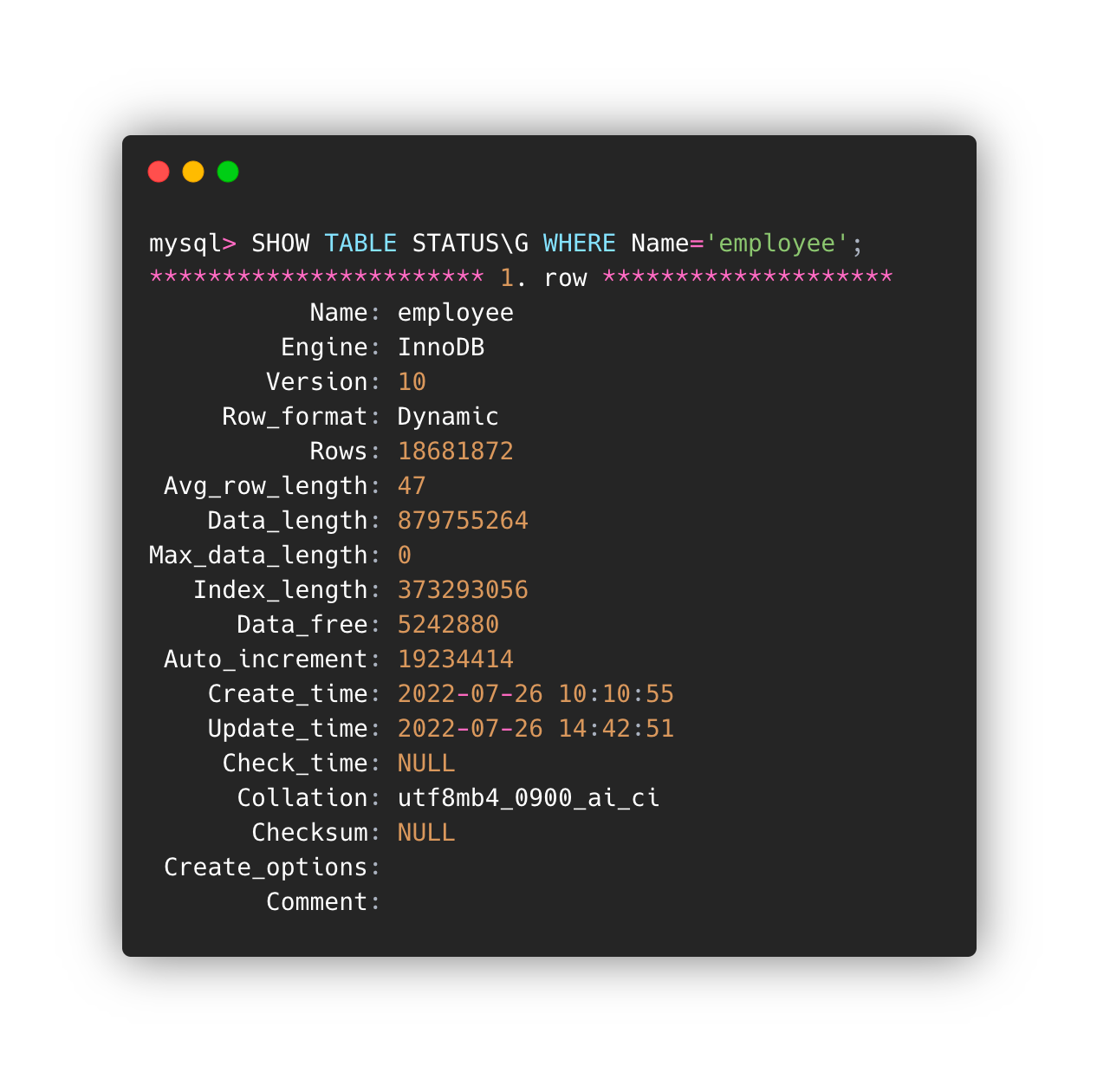
测试数据量约为1900万。
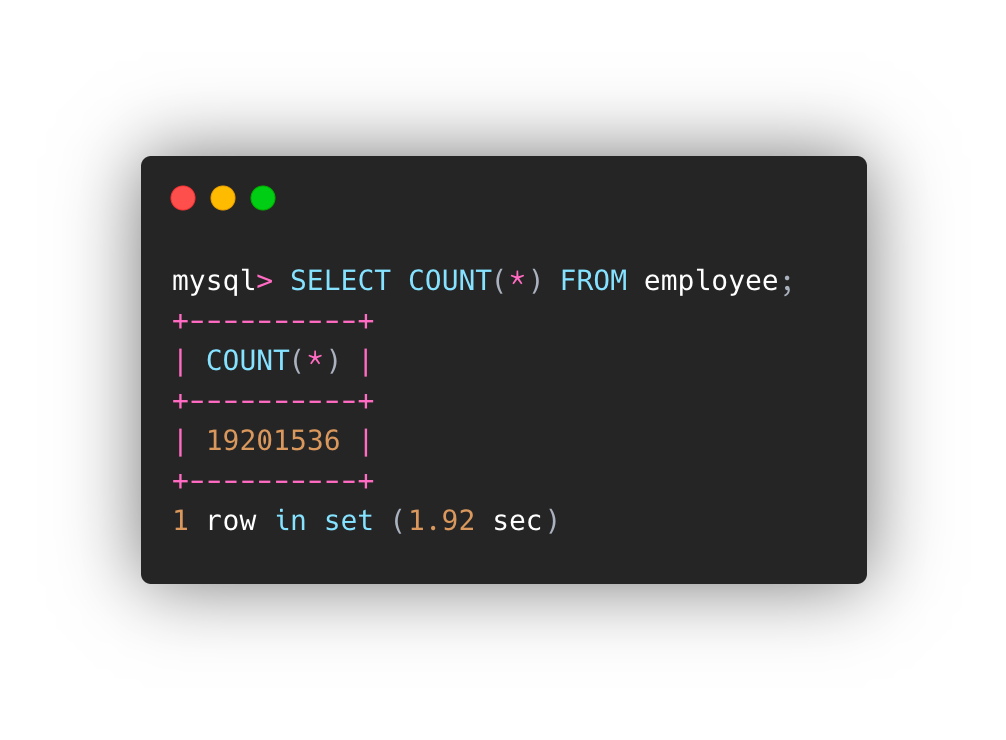
以下是索引信息。
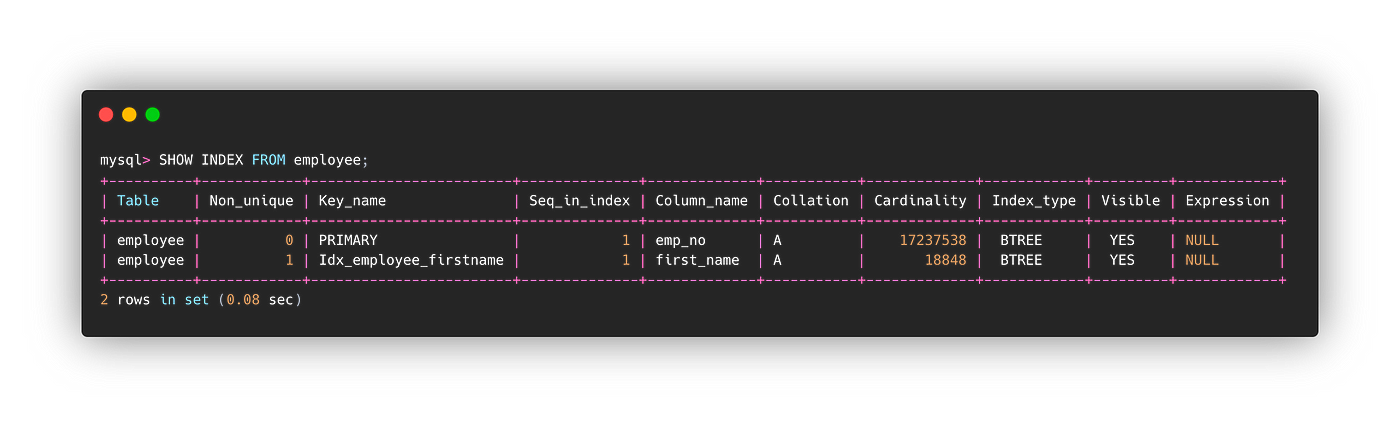
查询
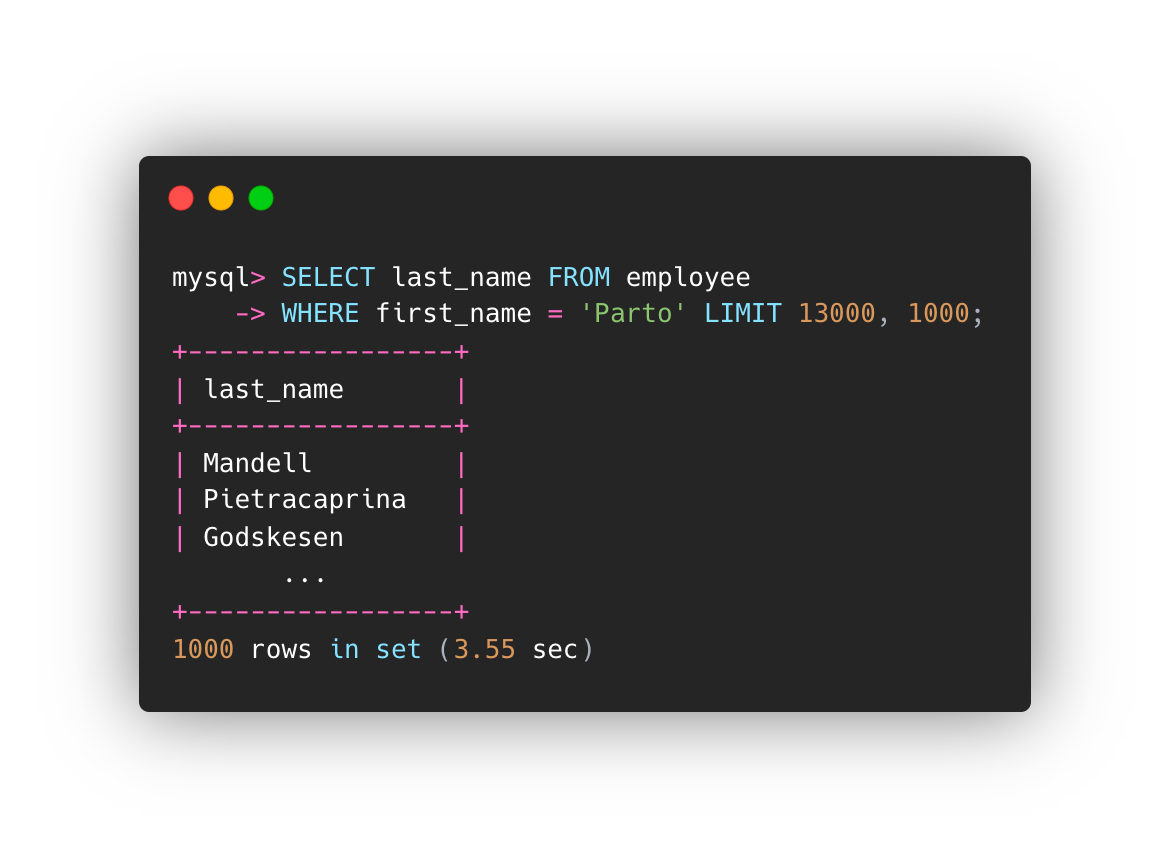
#1。在无索引上搜索列。
SELECT last_name FROM employee WHERE first_name = 'Parto' LIMIT 13000, 1000;
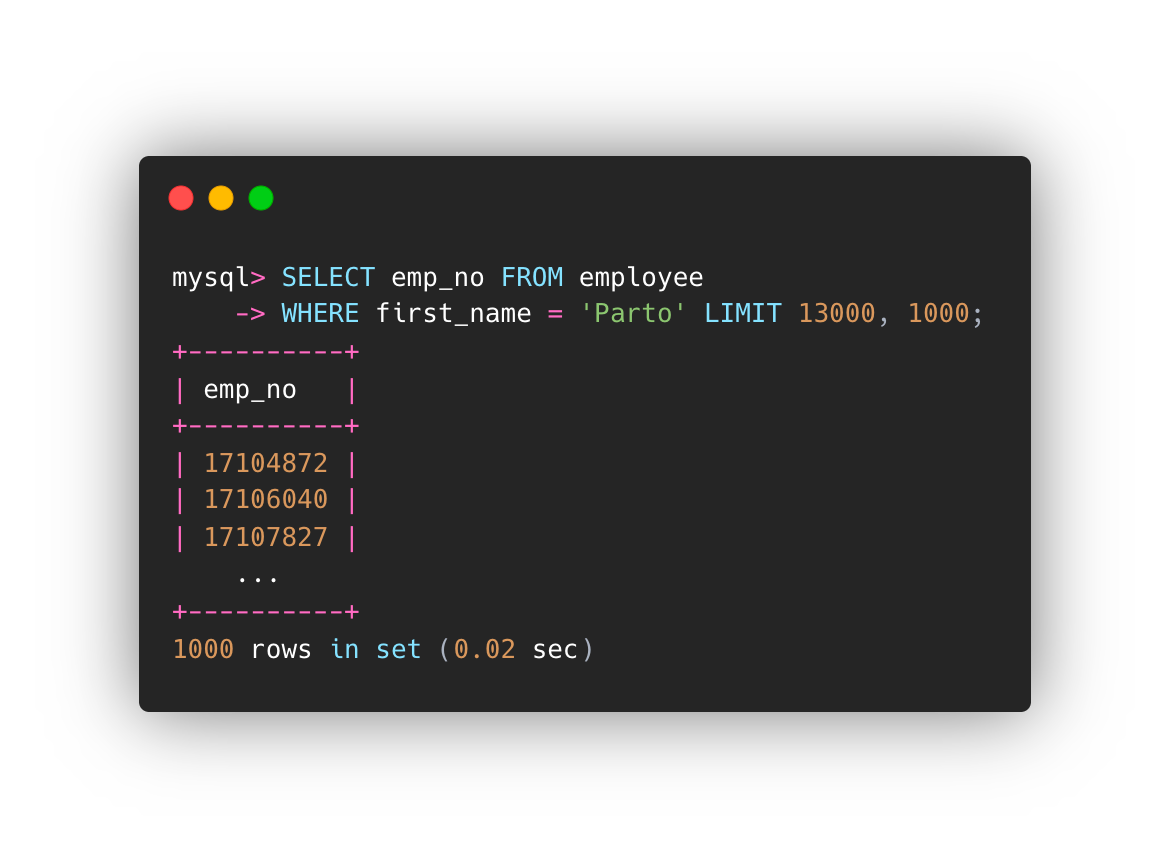
#2。在索引上搜索列 - 覆盖索引
SELECT emp_no FROM employee WHERE first_name = 'Parto' LIMIT 13000, 1000;
结果
搜索无索引列耗时 3.55 秒,索引列耗时 0.02 秒。随着过滤行的增长,它会产生更大的差异。
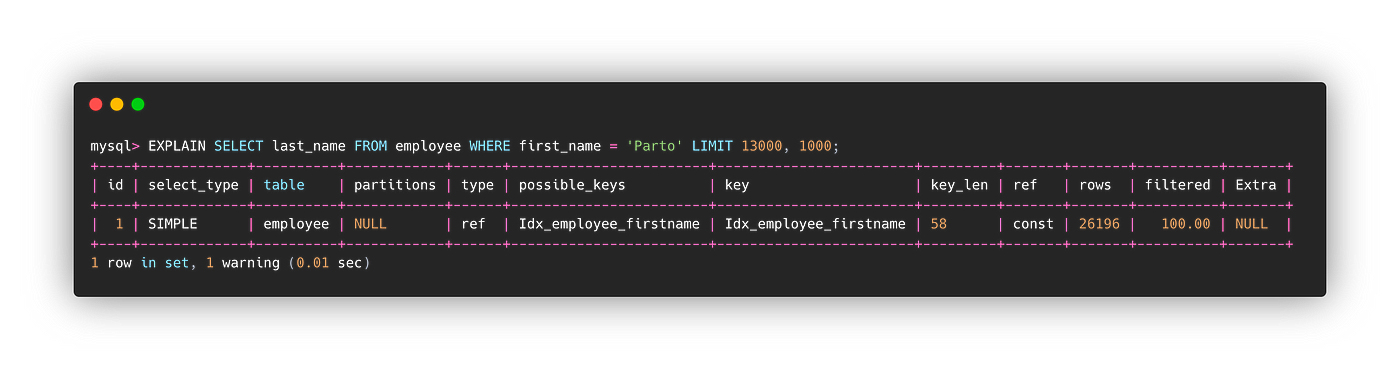
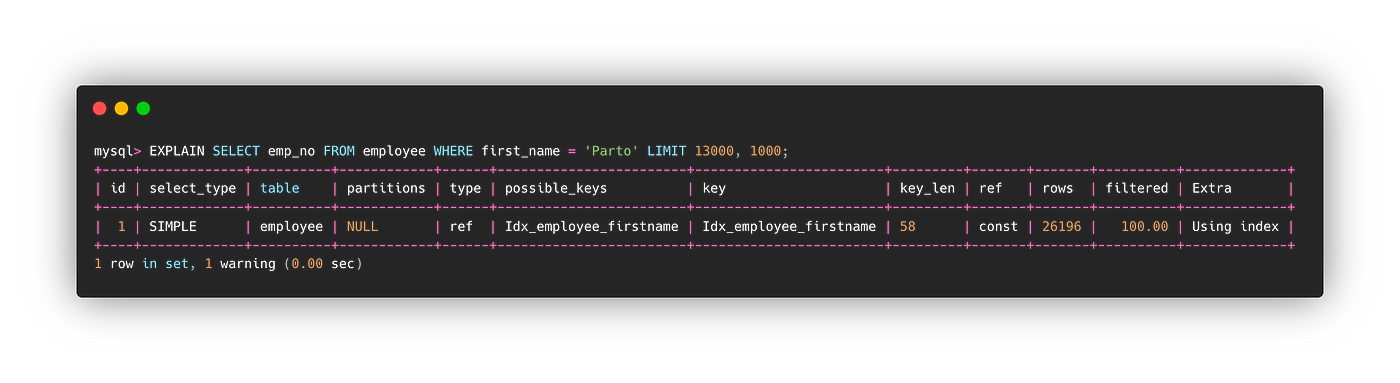
注意额外列中的“使用索引”。发起索引覆盖查询时,可以在explain的额外列中看到使用索引的信息。
覆盖指数并非总是在所有情况下都可以使用,但如果可以,您应该使用它。至少如果你看到了这个结果😋


