
译者注
该原文是Ayende Rahien大佬业余自己在使用C# 和 .NET构建一个简单、高性能兼容Redis协议的数据库的经历。
首先这个"Redis"是非常简单的实现,但是他在优化这个简单"Redis"路程很有趣,也能给我们在从事性能优化工作时带来一些启示。
原作者:Ayende Rahien
原链接:
https://ayende.com/blog/197665-C/high-performance-net-building-a-redis-clone-****ysis-ii
另外Ayende大佬是.NET开源的高性能多范式数据库RavenDB所在公司的CTO,不排除这些文章是为了以后会在RavenDB上兼容Redis协议做的尝试。大家也可以多多支持,下方给出了链接
RavenDB地址:https://github.com/ravendb/ravendb
构建Redis克隆版-第二次分析
我要倒退几步,看看我接下来应该看哪里,看看我应该注意哪里。到目前为止,在本系列中,我主要关注的是如何读取和处理数据。但我认为我们应该退一两步,看看我们现在的总体情况。我在分析器中运行了使用Pipelines和字符串的版本,试图了解我们的进展情况。例如,在上一篇文章中,我使用的 ConcurrentDictionary 有很大的性能开销。现在还是这样吗?
以下是代码库中当前的热点数据:
更详细来看,如下所示:
可以看到处理网络请求占用了大部分的时间,我们再来看看HandleConnection代码:


public async Task HandleConnection()
{
while (true)
{
var result = await _netReader.ReadAsync();
var (consumed, examined) = ParseNetworkData(result);
_netReader.AdvanceTo(consumed, examined);
await _netWriter.FlushAsync();
}
}
查看代码和分析器的结果,我觉得我知道如何做的更好。下面的一个小修改给我带来了2%的性能提升。
public async Task HandleConnection()
{
// 复用了readTask 和 flushTask
// 降低了一些内存占用
ValueTask<ReadResult> readTask = _netReader.ReadAsync();
ValueTask<FlushResult> flushTask = ValueTask.FromResult(new FlushResult());
while (true)
{
var result = await readTask;
await flushTask;
var (consumed, examined) = ParseNetworkData(result);
_netReader.AdvanceTo(consumed, examined);
readTask = _netReader.ReadAsync();
flushTask = _netWriter.FlushAsync();
}
}
我们的想法是将网络的读写并行化。这是一个小小的提升,但是任何一点点帮助都是好的,特别是当各种优化会关联影响时。
看看这个,我们已经有将近20亿个ReadAsync调用,让我们看看它的成本是多少:

真是... 哇。
为什么InternalTokenSource如此昂贵?我敢打赌问题就在这里,它被锁定了。在我的用例中,我知道有一个单独的线程在运行这些命令,不会有并发问题,所以值得看看是否可以跳过它。不幸的是,没有一个简单的方法可以跳过检查。幸运的是,我可以从框架中复制代码并在本地对其进行修改,以了解这样做的影响。所以我就这样做了(在构造函数中初始化一次) :

这意味着我们在每次请求处理上有大约40%的改进。正如我前面提到的,这不是我们现在能够做到的,因为源码里面就有lock,但是这是一个关于使用 PipeReader 读取数据性能损耗有趣的点。
另一个非常有趣的方面是后端存储,它是一个ConcurrentDictionary。如果我们看看它的成本,我们会发现:

您会注意到,我正在使用NonBlocking的NuGet包,它提供了一个无锁的 ConcurrentDictionary实现。如果我们使用.NET框架中的默认实现,它确实使用了锁,我们将看到:

下面有它们的对比:
请注意,这两个选项之间存在非常大的成本差别(有利于非阻塞)。但是,当我们运行一个真实的基准测试时,它并没有特别大的差别。
那接下来呢?
看看分析器的结果,我们没有什么可以继续改进的。我们的大部分成本都在网络中,而不是在我们运行的代码中。
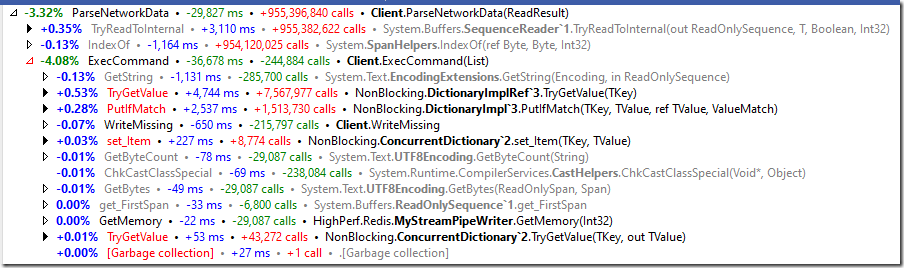
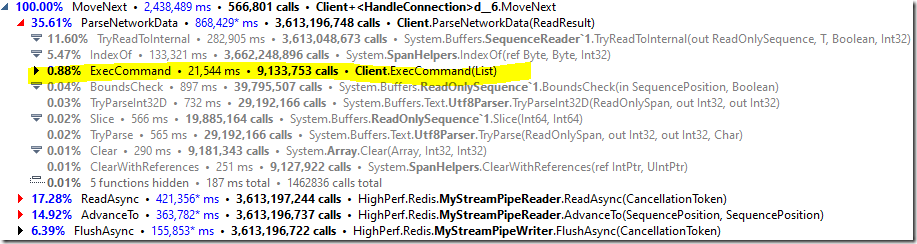
我们的大部分代码都在 ParseNetworkData 调用中,看起来像这样:

所以我们实际上花在执行服务器核心功能上的时间是可以忽略不计的。实际上,解析来自缓冲区的命令花费了大量时间。注意,在这里,我们实际上并不执行任何 I/O 操作,所有操作都在内存中的缓冲区上进行操作。
Redis协议对于机器解析来说并不友好,需要我们进行大量的查找才能找到分隔符(因此有很多的IndexOf()调用)。我不认为你能在这方面有显著的改进。这意味着我们必须考虑其他更好的性能选择。
我们花费了35% 的运行时来解析来自客户端的命令流,而我们执行的代码不到运行时的1% 。我不认为流解析还有重要的优化机会,因此我们只剩I/O的优化方向。我们能做得更好吗?
我们目前使用的是异步I/O和Pipelines。看看这个让我感兴趣的项目,它在Linux使用了IO_Uring(通过这个API)来满足他们的需要。它们的解析也很简单,请看这里,与我的代码运行的方式非常相似。
因此,为了进入性能的下一个阶段(提醒一下,我们现在的性能是180w/s) ,我们可能还需要使用基于IO_Uring的方法。有一个NuGet软件包来支持它,但是这使得我可以在一个晚上花几个小时来完成这个任务,而不是花几天或者一周的时间来完成。我不认为在不久的将来我会继续追求这个目标。
结尾
完结撒花!!!按照Ayende大佬的意思是后面会尝试在linux上使用IO_Uring来实现,目前来看大佬还没有其它的更新,已经发布的博文已经全部翻译。
我也在大佬博文底部提出了其它的一些性能优化的小建议,建议来自我之前发布的文章,同样高性能的网络服务开发。有兴趣的可以查看下方链接。
https://www.cnblogs.com/InCerry/p/highperformance-alternats.html
系列链接
使用.NET简单实现一个Redis的高性能克隆版(一)
使用.NET简单实现一个Redis的高性能克隆版(二)
使用.NET简单实现一个Redis的高性能克隆版(三)
使用.NET简单实现一个Redis的高性能克隆版(四、五)
使用.NET简单实现一个Redis的高性能克隆版(六)
后续大佬有其它更新的话,也欢迎艾特我催更


