
译者注
该原文是Ayende Rahien大佬业余自己在使用C# 和 .NET构建一个简单、高性能兼容Redis协议的数据库的经历。
首先这个"Redis"是非常简单的实现,但是他在优化这个简单"Redis"路程很有趣,也能给我们在从事性能优化工作时带来一些启示。
由于接下来的两篇较短,本文一起把它们一起翻译
原作者:Ayende Rahien
原链接:
https://ayende.com/blog/197505-C/high-performance-net-building-a-redis-clone-separation-of-computation-i-o
另外Ayende大佬是.NET开源的高性能多范式数据库RavenDB所在公司的CTO,不排除这些文章是为了以后会在RavenDB上兼容Redis协议做的尝试。大家也可以多多支持,下方给出了链接
RavenDB地址:https://github.com/ravendb/ravendb
构建Redis克隆版-计算与I/O的分离(四)
在达到125w/s的性能以后,我决定试试把代码修改成流水线(pipeline)会发生什么。这个改动很复杂,因为我要追踪所有的输入请求,又需要将输入请求发送到对应的的多个线程进行处理。
在我看来,这些代码本身就是垃圾。但是只要它能在架构上为我指明正确的方向,那么就是值得的。您可以再下面阅读那些代码,但是它有点复杂,我们尽可能的多读取客户端请求,然后将其发送到每个专用线程来运行它。
就性能而言,它比上一个版本的代码慢(大约20%),但是它有一个好处,那就是能很容易的看出哪里的花费的资源最多。
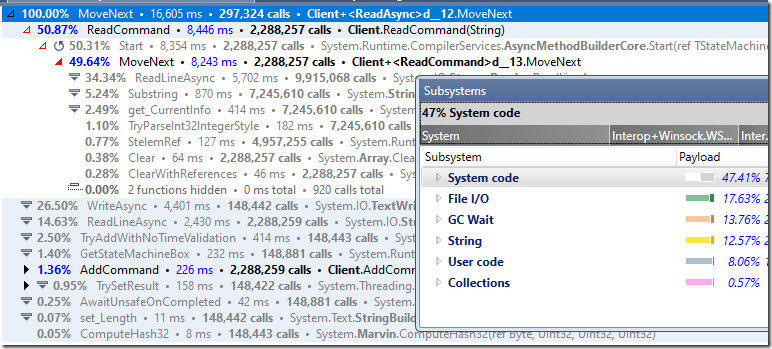
看看下面的分析器结果:
您可以看到,我们在 I/O 和字符串处理方面花费了很多时间。GC也花费了很多时间。
我想分阶段解决这个问题。第一部分是停止到处使用字符串。之后的下一个阶段可能是更改 I/O 模型。
就目前而言,我们的代码是这样的:
using System.Collections.Concurrent;
using System.Net.Sockets;
using System.Text;
using System.Threading.Channels;
var listener = new TcpListener(System.Net.IPAddress.Any, 6379);
listener.Start();
ShardedDictionary _state = new(Environment.ProcessorCount / 2);
while (true)
{
var tcp = listener.AcceptTcpClient();
var stream = tcp.GetStream();
var client = new Client(tcp, new StreamReader(stream), new StreamWriter(stream)
{
AutoFlush = true
}, _state);
var _ = client.ReadAsync();
}
class Client
{
public readonly TcpClient Tcp;
public readonly StreamReader Reader;
public readonly StreamWriter Writer;
public readonly ShardedDictionary Dic;
public struct Command
{
public string Key;
public string? Value;
public bool Completed;
}
private List<string> _args = new();
private Task<string?> _nextLine;
private Command[] _commands = Array.Empty<Command>();
private int _commandsLength = 0;
private StringBuilder _buffer = new();
private int _shardFactor;
public Client(TcpClient tcp, StreamReader reader, StreamWriter writer, ShardedDictionary dic)
{
Tcp = tcp;
Reader = reader;
Writer = writer;
Dic = dic;
_shardFactor = dic.Factor;
}
public async Task ReadAsync()
{
try
{
while (true)
{
if (_buffer.Length != 0)
{
await Writer.WriteAsync(_buffer);
_buffer.Length = 0;
}
var lineTask = _nextLine ?? Reader.ReadLineAsync();
if (lineTask.IsCompleted == false)
{
if (_commandsLength != 0)
{
_nextLine = lineTask;
Dic.Enqueue(this, Math.Abs(_commands[0].Key.GetHashCode()) % _shardFactor);
return;
}
}
var line = await lineTask;
_nextLine = null;
if (line == null)
{
using (Tcp) // done reading...
{
return;
}
}
await ReadCommand(line);
AddCommand();
}
}
catch (Exception e)
{
await HandleError(e);
}
}
private async Task ReadCommand(string line)
{
_args.Clear();
if (line[0] != '*')
throw new InvalidDataException("Cannot understand arg batch: " + line);
var argsv = int.Parse(line.Substring(1));
for (int i = 0; i < argsv; i++)
{
line = await Reader.ReadLineAsync() ?? string.Empty;
if (line[0] != '$')
throw new InvalidDataException("Cannot understand arg length: " + line);
var argLen = int.Parse(line.Substring(1));
line = await Reader.ReadLineAsync() ?? string.Empty;
if (line.Length != argLen)
throw new InvalidDataException("Wrong arg length expected " + argLen + " got: " + line);
_args.Add(line);
}
}
private void AddCommand()
{
if (_commandsLength >= _commands.Length)
{
Array.Resize(ref _commands, _commands.Length + 8);
}
ref Command cmd = ref _commands[_commandsLength++];
cmd.Completed = false;
switch (_args[0])
{
case "GET":
cmd.Key = _args[1];
cmd.Value = null;
break;
case "SET":
cmd.Key = _args[1];
cmd.Value = _args[2];
break;
default:
throw new ArgumentOutOfRangeException("Unknown command: " + _args[0]);
}
}
public async Task NextAsync()
{
try
{
WriteToBuffer();
await ReadAsync();
}
catch (Exception e)
{
await HandleError(e);
}
}
private void WriteToBuffer()
{
for (int i = 0; i < _commandsLength; i++)
{
ref Command cmd = ref _commands[i];
if (cmd.Value == null)
{
_buffer.Append("$-1\r\n");
}
else
{
_buffer.Append($"${cmd.Value.Length}\r\n{cmd.Value}\r\n");
}
}
_commandsLength = 0;
}
public async Task HandleError(Exception e)
{
using (Tcp)
{
try
{
string? line;
var errReader = new StringReader(e.ToString());
while ((line = errReader.ReadLine()) != null)
{
await Writer.WriteAsync("-");
await Writer.WriteLineAsync(line);
}
await Writer.FlushAsync();
}
catch (Exception)
{
// nothing we can do
}
}
}
internal void Execute(Dictionary<string, string> localDic, int index)
{
int? next = null;
for (int i = 0; i < _commandsLength; i++)
{
ref var cmd = ref _commands[i];
var cur = Math.Abs(cmd.Key.GetHashCode()) % _shardFactor;
if (cur == index) // match
{
cmd.Completed = true;
if (cmd.Value != null)
{
localDic[cmd.Key] = cmd.Value;
}
else
{
localDic.TryGetValue(cmd.Key, out cmd.Value);
}
}
else if (cmd.Completed == false)
{
next = cur;
}
}
if (next != null)
{
Dic.Enqueue(this, next.Value);
}
else
{
_ = NextAsync();
}
}
}
class ShardedDictionary
{
Dictionary<string, string>[] _dics;
BlockingCollection<Client>[] _workers;
public int Factor => _dics.Length;
public ShardedDictionary(int shardingFactor)
{
_dics = new Dictionary<string, string>[shardingFactor];
_workers = new BlockingCollection<Client>[shardingFactor];
for (int i = 0; i < shardingFactor; i++)
{
var dic = new Dictionary<string, string>();
var worker = new BlockingCollection<Client>();
_dics[i] = dic;
_workers[i] = worker;
var index = i;
// readers
new Thread(() =>
{
ExecWorker(dic, index, worker);
})
{
IsBackground = true,
}.Start();
}
}
private static void ExecWorker(Dictionary<string, string> dic, int index, BlockingCollection<Client> worker)
{
while (true)
{
worker.Take().Execute(dic, index);
}
}
public void Enqueue(Client c, int index)
{
_workers[index].Add(c);
}
}
构建Redis克隆版-踩了一个坑(五)
现在,我已经完成了这些简单的工作,我决定将Redis实现改为使用System.IO.Pipelines。这是一个高性能的I/O API,专门针对那些需要高系统性能的服务器设计。
API有一点不同,但是它的使用方式非常合乎逻辑,并且有意义。下面是用于处理来自客户端命令的主循环:
public async Task HandleConnection()
{
while (true)
{
var result = await _netReader.ReadAsync();
var (consumed, examined) = ParseNetworkData(result);
_netReader.AdvanceTo(consumed, examined);
await _netWriter.FlushAsync();
}
}
我们的想法是,我们从网络获得一个缓冲区,我们读取一切(包括流水线命令) ,然后刷新到客户端。当我们开始处理实际的命令时,更有趣的事情发生了,因为现在我们使用的不是 StreamReader而是PipeReader。所以我们处理的是字节级别,而不是字符串级别。
下面是大致的代码,我没有展示整个代码,因为我想集中在我遇到的问题:
(SequencePosition Consumed, SequencePosition Examined) ParseNetworkData(ReadResult result)
{
var reader = new SequenceReader<byte>(result.Buffer);
while (true)
{
_cmds.Clear();
if (reader.TryReadTo(out ReadOnlySpan<byte> line, (byte)'\n') == false)
return (reader.Consumed, reader.Position);
if (line.Length == 0 || line[0] != '*' || line[line.Length - 1] != '\r')
ThrowBadBuffer(result.Buffer);
if (Utf8Parser.TryParse(line.Slice(1), out int argc, out int bytesConsumed) == false ||
bytesConsumed + 2 != line.Length) // account for the * and \r
ThrowBadBuffer(result.Buffer);
for (int i = 0; i < argc; i++)
{
// **** redacted - reading cmd to _cmds buffer
}
ExecCommand(_cmds);
}
}
代码从缓冲区读取并解析Redis协议,然后执行命令。它在同一个缓冲区(流水线)中支持多个命令,而且性能非常糟糕。
是的,相对于使用字符串的简单性而言,对于字节处理想使用正确API要难得多,而且它的速度比字符串还要慢得多。在我的开发机器上,我说的慢得多是指以下几点:
- 以前的版本大约每秒钟126,017.72次操作。
- 此版本低于每秒100次操作。
是的,你没有看错,每秒少于100次操作,而未优化版本的操作则超过10万次。
你可以想象,那真是... 令人惊讶。
我实际上写了两次实现,使用不同的方法,试图找出我做错了什么。使用PipeReader肯定没那么糟。
我查看了分析器的输出,试图弄清楚发生了什么:
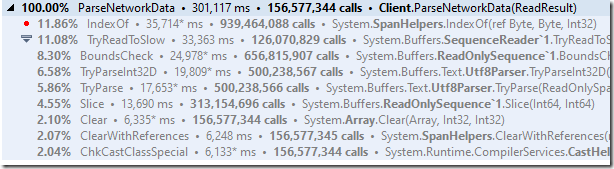
它非常清楚地表明,这个实现非常糟糕,不是吗?到底怎么回事?
底层的问题实际上相当简单,并且与Pipelines API如何实现这么高的性能有关。替代掉那些高频的System call,您需要获得一个缓冲区并处理。处理完缓冲区之后,您可以很方便的看到处理了多少数据,然后可以处理另一个调用。
然而,实际使用的数据和我们期望的数据是有区别的,如下所示:
# 请求redis 设置15字节的Key - memtier-2818567
# 数据为256字节 - xxxxxxxxxx ... xxxxxx
*3
$3
SET
$15
memtier-2818567
$256
xxxxxxxxxx ... xxxxxx
# 请求redis 获取Key - memtier-2818567 对应的数据
*2
$3
GET
$15
memtier-7689405
# 请求redis 获取Key - memtier-2818567 对应的数据
*2
$3
GET
$15
# !!! 这里发现有问题,Key应是memtier-2818567 但是只读取出了memt
memt
您在这里看到的是一个流水线命令,缓冲区中有335个字节。我们将在一次读取中中处理所有这些命令,除了... 看着最后四行。这是什么?
我们得到了客户端发送来的部分命令。换句话说,我们需要执行一个Key大小为15字节的GET操作,但是这里只接收到了前4个字节。这是意料之中的事,我们消耗了缓存区所有空间,直到最后四行(从而让 PipeReader 知道我们已经完成了它们)。
问题是,当我们现在在客户端发出一个请求时,我们在服务端得到最后四行的部分(我们没有使用它) ,但是我们还没有准备好处理它。所以数据丢失了,PipeReader知道它需要从网络上读取更多的数据。
但是... 我的代码有一个小bug。它将报告说它检查了下面**的部分,而没有检查绿色的部分。

换句话说,我们告诉PipeReader,我们已经消费了缓冲区的一部分,又检查了缓冲区的一部分,但缓冲区上还有一些字节既没有消费也没有检查。这意味着,当我们发出读取调用,期望从网络上获得数据时,我们实际上会再次获得相同的缓冲区,进行完全相同的处理。
最终,我们在缓冲区中会有更多来自另客户端的数据,虽然解决方案的正确性不会受到影响,但这会非常的影响性能。
修复非常简单,我们需要告诉PipeReader我们检查了整个缓冲区,这样它就不会忙碌地等待和等待来自网络的更多数据。以下是错误修复方法:
< return (reader.Consumed, reader.Position);
修改为:
> return (reader.Consumed, result.Buffer.End);
有了这一改动,我们可以达到每秒187,104.21次操作!这比以前提高了50%,这真是太棒了。我还没有对事情进行适当的分析,因为我还想解决另一个问题,我们如何处理来自网络的数据。在我的下一篇文章中会有更多关于这个问题的内容。
关于上文中提到的BUG - 译者注
这一个微小的BUG大家可能比较难理解,因为很多人都没有接触过PipeReader这么底层的API。我们来看看上文中while循环的代码:
public async Task HandleConnection()
{
while (true)
{
var result = await _netReader.ReadAsync();
var (consumed, examined) = ParseNetworkData(result);
// 主要是AdvanceTo方法,这个方法有两个参数
// consumed: 目前处理了多少数据,比如redis协议是按行处理,也就是\n
// examined:检查了多少数据,检查的数据和处理的数据不一定一样,因为
// 可能由于网络延时,还没有接收一个完整的数据包
_netReader.AdvanceTo(consumed, examined);
await _netWriter.FlushAsync();
}
}
另外就是修改点:
< return (reader.Consumed, reader.Position);
修改为:
> return (reader.Consumed, result.Buffer.End);
修改前的代码是检查的数据是返回当前的Position,但是当前的Position是小于我们实际上检查的长度
按照 if (reader.TryReadTo(out ReadOnlySpan<byte> line, (byte)'\n') == false)
代码所示,我们其实检查了流中的所有位置,只是从头读到尾巴没有读取到\n,如上面的例子就是读取到了最后一行,只读取了ment,因为网络请求原因,完整的memtier-7689405\n还没有接收到。
此时我们返回Position是上图中**的部分,但是实际上我们是检查到了绿色的memt部分,返回到上层以后,执行_netReader.AdvanceTo(consumed, examined);。
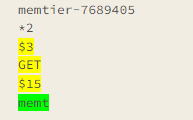
Pipeline发现还有剩余的绿色memt没有被检查,就会继续走var (consumed, examined) = ParseNetworkData(result);,又重新读取了memt,由于没有\n又返回了**部分的Position,所以这里就形成了忙等,再没有新的数据到来之前,这里将一直循环;虽然没有BUG,但是非常影响性能。
而修改以后检查位置返回result.Buffer.End,就包括了绿色的memt部分,这样的话var result = await _netReader.ReadAsync();只有当有新的数据到来时才会继续走下面的代码,这样的话充分的利用了Pipelines的优势,性能会更加好。
公众号
之前一直有朋友让开通公众号,由于一直比较忙没有弄。
现在终于抽空弄好了,译者公众号如下,欢迎大家关注。

系列链接
使用.NET简单实现一个Redis的高性能克隆版(一)
使用.NET简单实现一个Redis的高性能克隆版(二)
使用.NET简单实现一个Redis的高性能克隆版(三)

