
数据库篇——hash索引原创
前言
记得有一次面试,面试官问到我什么是索引,我告诉他B+树这种数据结构就是索引,面试官又问我,索引只能是B+树吗?但是我当时的认知太局限,难以回答这个问题,回想起来,我想回答的是,任何能够链接数据的结构或者方式的组合都可以称之为索引。
索引的应用本身就源于生活中的实践,当我们脱离生活谈论技术,那么技术将毫无意义,技术永远是源自生活并更好的服务与生活。
什么是hash
记得参加成都某知名大数据公司的面试时,被问到一道题就是,什么是hash?我沉默很久,都难以给出一个让自己觉得容易理解的答案,后来才明白对一项技术,自己都不能简单的讲述这项技术时,自己就应该反思,是不是自己掌握的过于片面,并没有理解其精髓。
在那次面试中,非常感谢面试官给出了他的理解,让我对hash有了更深层次的理解;面试官并没有直接告诉我他的答案,而是反问我一个int类型能表示多大的范围,我很快的给出了答案-2的31次幂到2的31次幂减1;面试官又问我java中的对象数量有没有可能超过int的表达范围呢?这时候我也明白了什么是hash了,说来简单,一句话概括hash:在有限的范围内表达无限的场景,这就是hash。我们看下面的例子就能明白什么是hash。
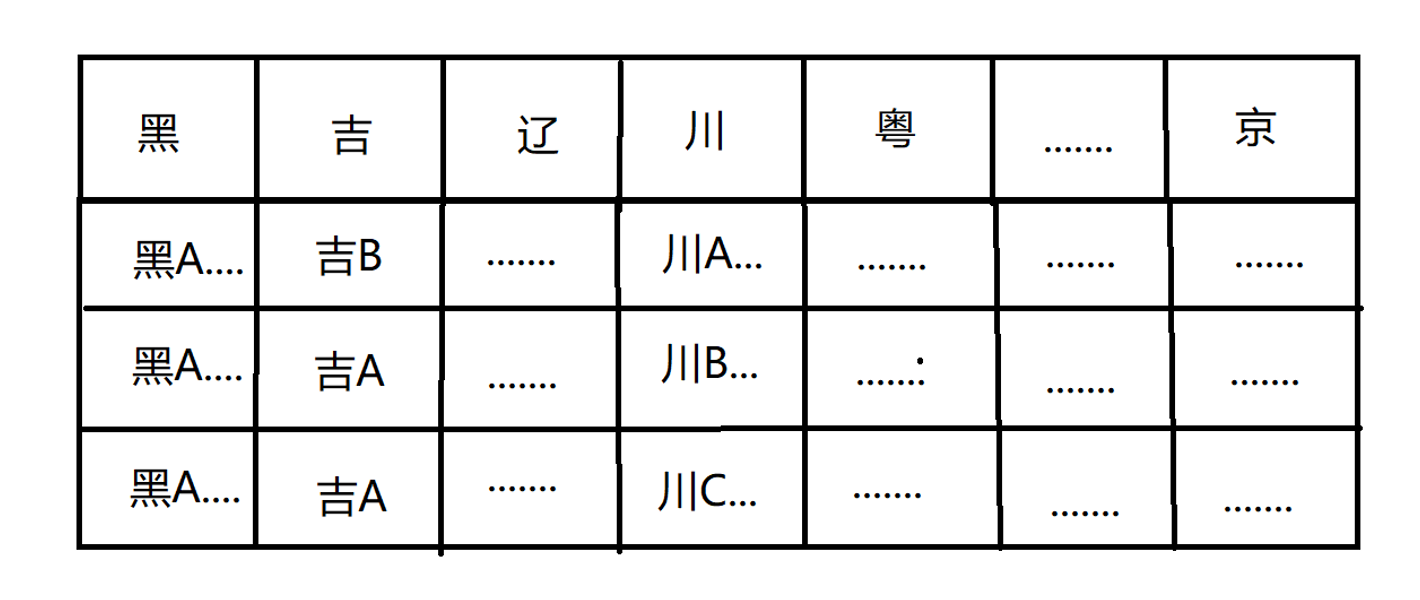
我们在一个停了上千辆的停车场中,找到来自四川上牌登记的车,我们只需要通过车牌开头的各个省行政区划分的简称就能找到那些车属于成都上牌登记,那么我们要找到来自成都的车,只需要找到简称川并且第二个字符是A开头的车辆。相比通过内容简介链接地址的方式,我们通过截取内容的固定部分,来将不同的车牌进行分门别类的方式,这就是一种hash,如下图
我们将每个车牌的第一个关键字,将车牌按省划分,这样就用几十个省的简称,链接了所有车牌,换个说法就是我们将无数个不同的车牌用有限的省简称来表达。
什么是hash冲突
在上面的例子中,我们将车牌按照省行政区分门别类,我们遇到了许许多多同一个省的车牌号,例如川A·12345和川B·14323,他们都会归为川这一类,这就是hash冲突,多个不同的值通过算出了同一个hash值被称之为hash冲突。
hash在数据库索引中的应用
在上面的例子中,我们将车牌号的第一个字符作为hash值来进行分门别类,那么我们怎么在数据库中应用hash呢?
在关系型数据库中,数据是由行和列组成的逻辑表结构,我们的一条记录往往由多个列组成,例如id、name、age等等,我们在查询的时候,会常常编写如下代码:
select * from table where id = ?
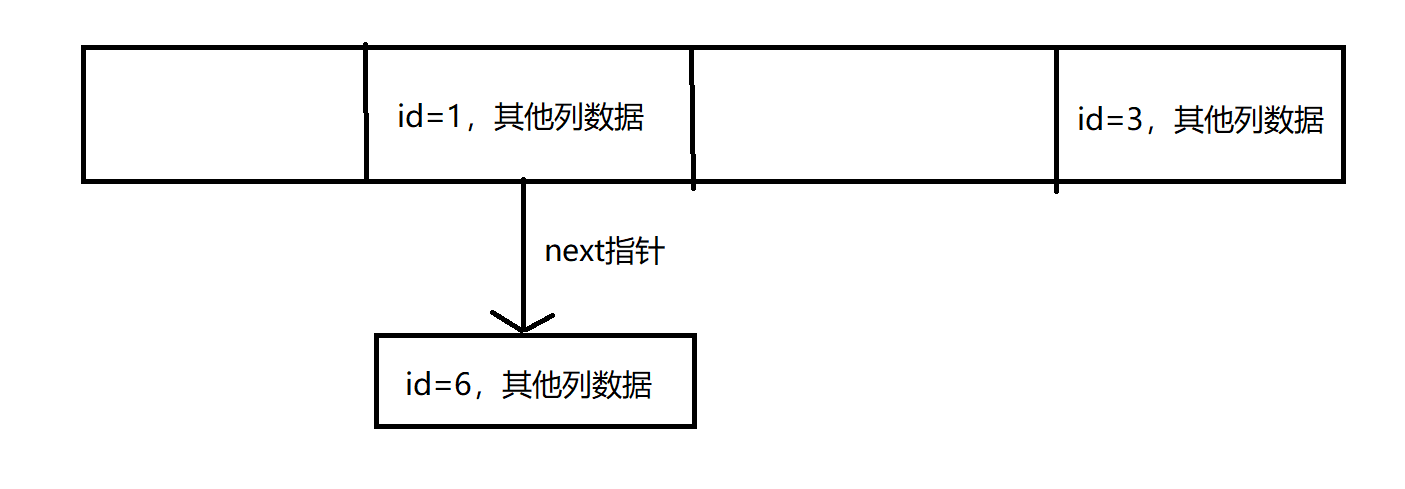
对于column = 值的查询,如果存在id的hash索引,那么数据库最简单的物理优化则是,将以刚好大于或等于表行数并的2次幂的数为长度创建数组,将id的二进制值与数组长度-1按位与(id&(length-1)得到的数作为下标(当lenght为2的次幂+1时,id&(length-1)=id%length),插入到数组中,如果下标所在的元素存在值,则查找next指针的下一个元素,如果不存在next指针则将自己的offset或者指针赋值给next。在这种情况下,我们将id与数组长度求余数来将id分门别类,余数为1的放入下标为1的槽、余数为3的放入下标为3的槽、如果一个槽中有多个元素则通过指针相连;示意图如下:
当我们要查找id=6的数据,只需要用6%4=2作为下标遍历下标为2这个槽的元素中id=6的值。
当然,不止column=值的查询可以用hash索引,下面语句同样也可以通过hash的方式查找。(设table的id列为hash索引)
select * from table where id in (?,?,?,?)
select * from table1 right join table2 on (table1.id=table2.table1_id) where table2
hash索引的时间复杂度与空间复杂度
hash索引每次查找元素的时间复杂度约等于O(1),实际的时间复杂的与数据的hash冲突率有关。
hash索引的空间复杂度为O(n),因为每一个元素都需要存储一次。
关于时间复杂度和空间复杂度的计算方法,参考《漫画算法:小灰的算法之旅》《算法图解》
hash索引的局限性
在本文介绍了hash索引,并介绍了hash在数据库中的应用,但是作为从事开发工作的人员都一定知道,关系型数据库中应用最多、最广泛的、还是b+树,那么为什么现在的软件行业中hash索引应用较少了?
hash索引虽然有上面谈到的时间复杂度的优势,并且相比b+树在空间复杂度上也存在优势,但是没有被广泛应用,主要有如下缺点:
-
查询性能受hash冲突率影响,性能不稳定
-
只能通过等值匹配的方式查询,不能范围查询
-
结构存储上没有顺序,查询时排序无法支持
在数据库软件应用场景日益复杂的今天,简单的hash表已经很难满足关系型数据库的基础查询功。
总结:
我们用现实生活中的车牌分类来讲解hash,用生活的例子来理解hash与hash冲突,我们也讲到了hash在数据库索引中的应用。
本文中讲到的hash索引只是数据索引的冰山一角,工业数据库软件设计与实践中,有许许多多复杂的结构与实现方式,仅仅在物理优化的层面上有:bitmap、gin、Query tree、b tree、b+ tree、heap等多种方式,他们之间各有各的优势,适用的场景也不同,其中有些基于内存构建,有些基于磁盘构建,但是不论何种方式,如果高性能的使用数据库,需要大量关系优化、物理优化和数据结构上的知识的支撑,数据的应用并不是简简单单的查看执行计划,在我写本文之前,曾面试过上百位候选人,但能够将mysql执行计划(postgres执行计划会更为详细和复杂)讲清楚的,各种执行计划怎样的sql产生的寥寥无几。
在后续的文章中,我讲继续讲解关于数据库索引相关的知识,包括后续的B tree和B+ tree篇,我还将继续讲解hash与tree的结合,在数据库表连接方式篇,我还将继续讲到与hash有关的连接“hash join”,数据库应用中还存在许多与hash思想相结合的应用;
希望我的文章能够帮到大家,这也是我继续写下去的动力。
物理优化:基于代价的查询优化(Cost-based Optimizer,简称CBO)也可以称为代价优化、物理 优化,引用《PostgreSQL技术内幕:查询优化深度探索》,在mysql中又名“基于成本的优化”,引用《MySQL是怎样运行的 从根儿上理解MySQL》
逻辑优化:逻辑优化是指建立在关系代数基础之上的优化形式,引用《PostgreSQL技术内幕:查询优化深度探索》
推荐阅读篇:关于数据库相关知识推荐大家阅读《mysql是怎样运行的——从根儿上理解mysql》


