
【全网首发】关于我在某安科技中nginx多层代理静态资源遇到的问题原创
关于我在某安科技中nginx多层代理静态资源遇到的问题
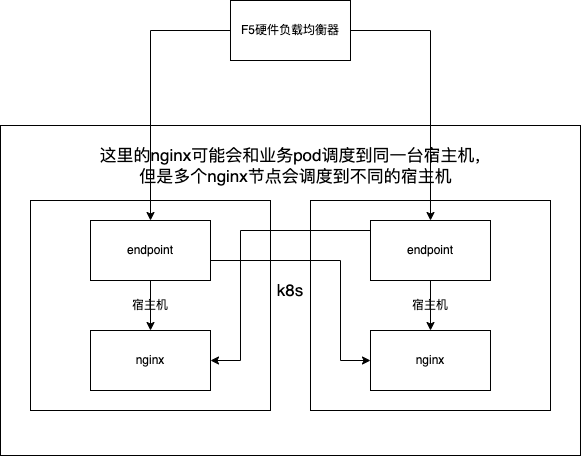
在nginx部署架构中,后端接口和前端静态资源都会通过nginx进行代理,他的部署架构图如下
在nginx会做如下代理:
- 监听80端口,同时也是endpoint的入口
- 根据path将请求转发到微服务网关
- 根据path将请求转发到前端静态资源代理
- 监听5000端口,作为前端静态资源代理入口
- 根据path匹配对应的静态资源目录
前端静态资源的请求会从80端口的server转发到5000端口的server,这个转发通过svc name进行转发。有关svc的需要了解k8s的相关知识(推荐阅读《kubernetes权威指南》)。简单认为svc name是k8s在内部为nginx创建的域名,k8s内部署的应用都通过svc name就可以请求到nginx,但是这个请求可能会分配到不同的nginx节点上,因为会进行负载均衡。
问题:在这种架构下,我们对前端静态资源进行了压力测试,通过jmeter进行压测,性能不尽人意,并且在持续一段时间后伴随着报错,查看nginx日志后,发现大量的报错,提示端口不够用。

当时的问题定位于排查
- 通过报错我们分析,静态资源请求是80端口的请求转发到5000端口时,实际上是重新创建的tcp连接,这个时候请求可能会负载到任意的nginx上,tcp连接发起方会随机的使用系统的一个端口作为自己的端口与5000建立连接,当并发足够的时候,就会发生65535个端口都被占用的情况(实际上并没有65535,系统占用和其他应用会占用某些端口,保留端口等)。
- 我们查阅一些资料后,得知,当应用调用close()方法,并不会马上释放连接,而是将连接从活跃状态变成TIME_WAIT状态,操作系统会在TIME_WAIT时间之后,释放连接,我们就在想可以调小这个时间吗,linux2.x内核之后确实支持修改这个系统参数,但是容器部署的坏处就是,我也不知道怎么修改基础镜像中操作系统的内核参数,即使我进入容器中修改了操作系统参数,重启后就会失效,所以就放弃了这个想法。
- 前端的静态资源其实也是http协议,我们就开始从http协议入手,看看有没有办法解决端口被占用完的问题,正好http提供了keepalive参数,此参数可以让客户端请求的时候,将几个或者多个个http请求合并为一个tcp连接传输;我们尝试在jmeter请求头中加入keepalive后继续压测,情况并没得到缓解,我们又在nginx配置中声明了keepalive,也没有得到缓解。
- 后续我们根据报错乱查阅一通资料后,发现操作系统提供了一个参数tw_reuse,这个参数意思是,对于处于TIME_WAIT的连接可以应用于新的tcp连接,简单来说就是可以复用处于TIME_WAIT状态的tcp连接,这个在linux内核系统默认为0即关闭状态,我们任然需要修改系统配置,又回到了原来的问题,修改后只是临时的重启后就失效了,我们没有选择尝试。
- 我们后面尝试更换nginx的版本,看是否能够解决此问题,我们更换了几个版本(不断升级版本或者降级版本),发现不会出现502,并且日志中没有提示端口不够的情况,但是tps并没有上升,而且迎来了新的问题,更换nginx版本后后端的登录接口在压测时出现了异常,这是在原来版本上没有的问题,具体错误已经回顾不起来了,但是我们始终没有找到静态代理与后端登录接口同时不异常的版本。
- 白天搞到第二天3点,我已经没有精力了,还好当时已经星期六了,打车回去后,美美睡一觉,爬起来第一件事就是在自己电脑复现这个场景,在本地非虚拟机的环境上搭建了nginx,并使用相同的模式从80端口转发请求到5000端口,并没有出现任何异常,不过我的upstream 为localhost:5000,不知道是不是因为localhost的缘故并不会消耗端口。但是我发现了一个更重要的现象,请求通过80端口再转发到5000端口的性能损耗非常的大,直接请求5000端口的一个1kp大小的静态资源tps能够达到6200左右,而通过80后再转发到5000端口的相同静态资源请求tps只能达到2500左右,压测报告图下面,我将测试结果整理后发给了架构组的相关同事,后续维护nginx的相关同事将静态资源作为nginx localhost 配置存在80端口的server块中。
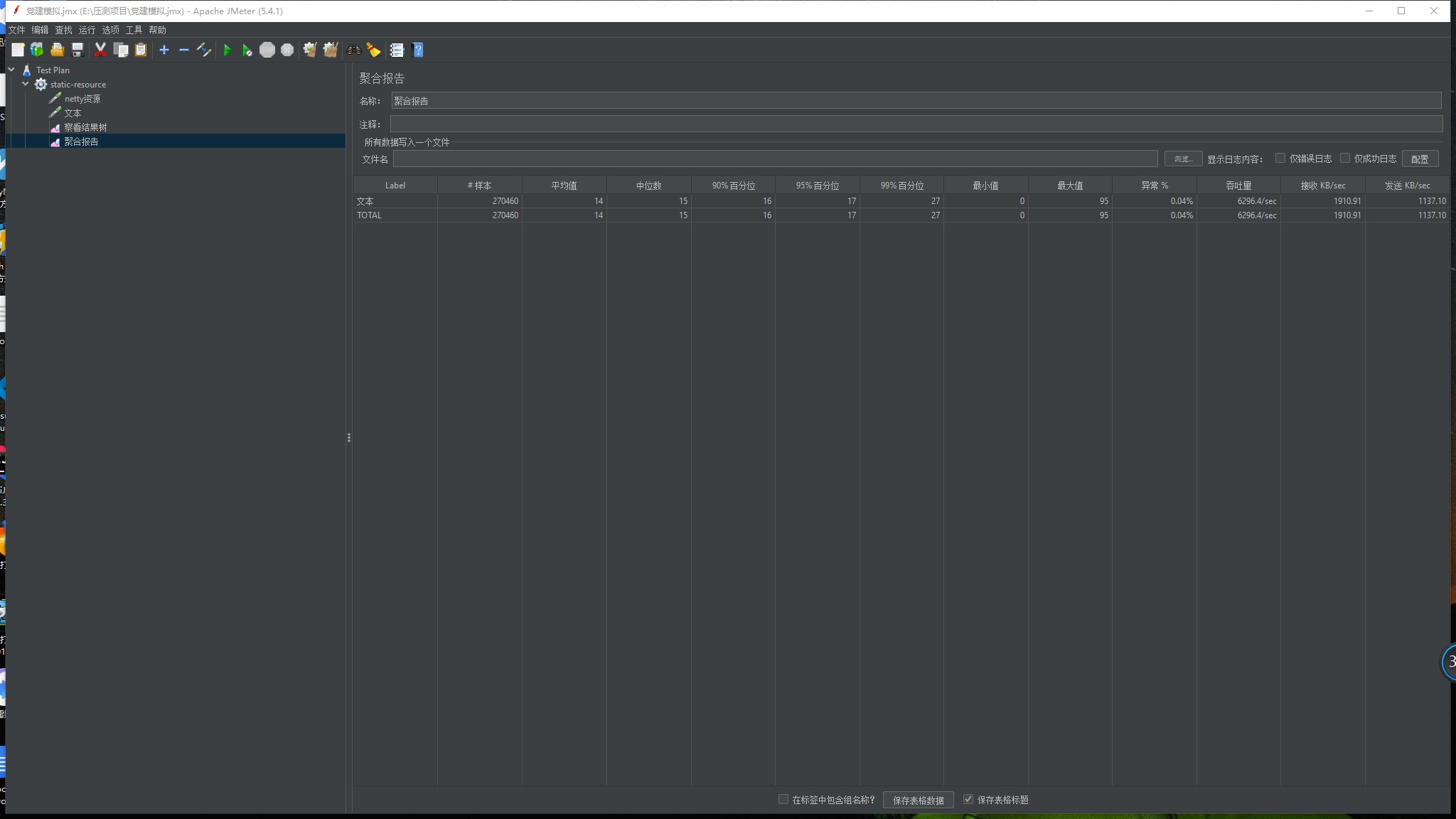
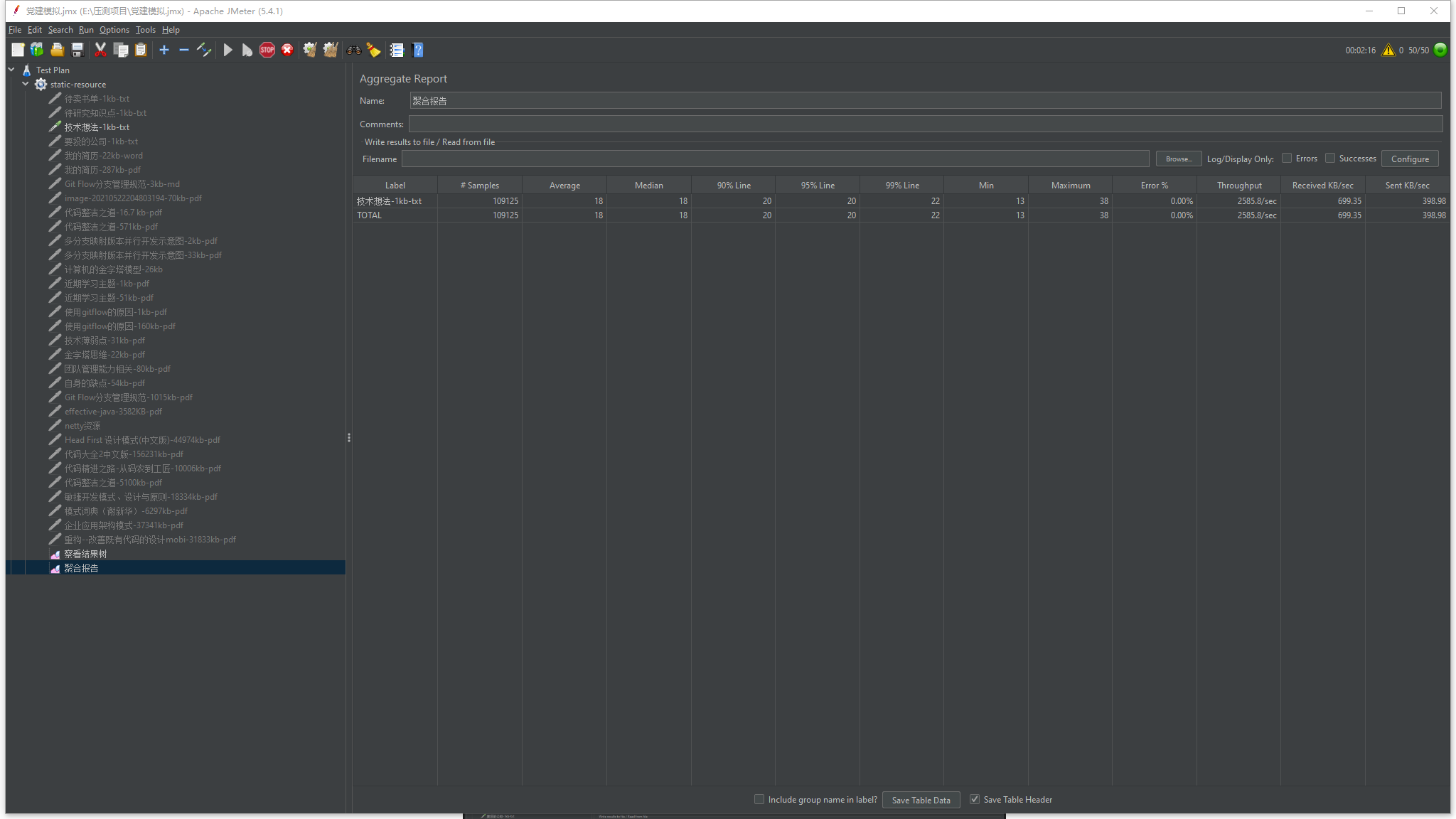
回顾:
现在的我已经离开了当时的公司,当时的问题现在想起来已经有些模糊了,有些陈述可能是错误的,不过并妨碍我们进行回顾。
重新分析:
- 首先,会造成端口被占用完的问题,主要是压测时的一次组合场景足足有40多个静态资源,并且许多文件并不小,所以当时我们首先还测试了jmeter集群和nginx集群之间是否有足够的带宽,虽然没得到最大带宽,但远超当时tps最高时流量。
- 看问题总得透过现象看本质,造成端口不够用的原因,很大部分原因是因为静态资源过多,并且静态资源过大,资源多并且大,就会造成传输完一个资源需要的时间较长,一个后端接口数据不过几十到几百字节,而一张压缩了的图片都在几十kb到几百kb左右,如果是高清图片则会更大,这会造成tcp连接使用时间很长,高并发下就会出现没有连接可以用,一个连接需要绑定一个端口。
- keepalive这个属性是否有用,我觉得是有用的,只是我们当时nginx的部署是基于镜像,nginx配置只开放path和upstream的映射,其他配置只能通过环境变量注入,keepalive是可以配置到upstream块上的,环境变量应该只能注入全局的配置,某些配置并不是应用于全局作用域,所以当时的keepalive是否生效我是持怀疑态度的。
upstream backend {
server 10.0.0.100:1234;
server 10.0.0.101:1234;
#使用keepalive来达到连接复用
keepalive 128;
}
- 回到操作系统层面,我们有一个思路通过修改系统的TIME_WAIT参数来让处于TIME_WAIT状态的连接更快释放,如果我们应用了这个参数是否有用了呢?后续我查阅了更多的资料,发现这个参数并没有想象那么的简单,TIME_WAIT参数的作用,需要与tcp的4次挥手相结合理解,并不是我上文写的那么简单的作用,详解可以参考:https://blog.51cto.com/u_13291771/2798453 简单来讲,tcp关闭需要双方都知道,主动方a发起关闭只是保证了a不会再发送数据到另一方b,b流向a的方向数据并不一定发送完毕,所以需要进行4次挥手,那么我们a发出关闭指令,b数据发送完毕也发出关闭指令,a也接受到了并回复ack,但是因为网络问题,此次ack丢失了,所以b并不知道我们是否收到他发出的关闭指令,如下图所示。
所以a收到对方关闭指令后不能马上释放这个连接,会将连接置为TIME_WAIT状态,并不会马上回收连接,我们可以通过netstat指令进行查看,如下所示:
netstat -aonp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 81 0 0.0.0.0:8080 0.0.0.0:* LISTEN 1/java off (0.00/0/0)
tcp 0 0 127.0.0.1:8100 0.0.0.0:* LISTEN 24/soffice.bin off (0.00/0/0)
tcp 932 0 172.20.5.59:40576 172.20.4.203:8080 TIME_WAIT - off (0.00/0/0)
tcp 947 0 172.20.4.172:57166 172.20.4.203:8080 TIME_WAIT - off (0.00/0/0)
此时的a需要保持一段时间来应答b重发的关闭指令(b在一段时间内没有收到a的ack应答会重新发起关闭指令,这是tcp的超时重传的设计,详细可以阅读《计算机网络:自顶向下》),TIME_WAIT时间就是指导a需要保持这个连接存活多久,所以,缩小TIME_WAIT能一定程度的缓解端口被用尽的情况,但是降低TIME_WAIT的持续时间的方法是一种以可靠性换取性能的一种方式。
注意:连接进入TIME_WAIT仍需要占用资源。
- tcp_tw_reuse,这个参数作用是当新的连接进来的时候,可以复用处于TIME_WAIT的socket,默认值是0,与TIME_WAIT一样,会丢失可靠性。
那么我们怎么解决端口被使用完的问题呢?
- 在upstream块中使用keepalive
- 其实这个问题在nginx官方中有解答,原文参考:https://www.nginx.com/blog/overcoming-ephemeral-port-exhaustion-nginx-plus 或参考:https://www.codenong.com/cs105164127/
方案二讲解:
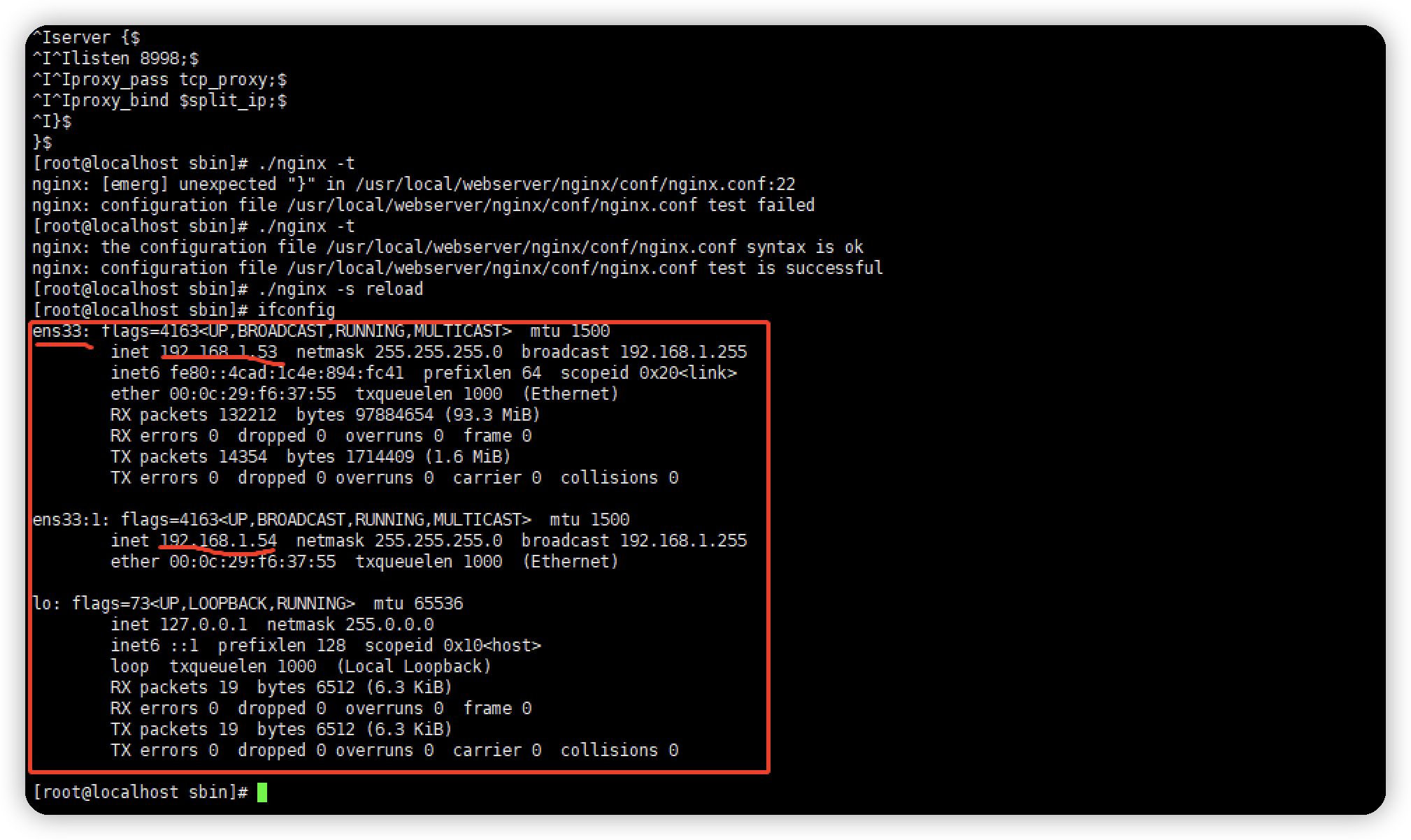
了解计算机组成和操作系统的应该比较明白,计算机中的io设备网卡是可以绑定多个ip的,许多设备还会拥有不同子网的ip,例如路由器,其实在keepalived实现高可用也是通过在网卡上绑定多个ip,我们通过将nginx所在机器分配多个同一子网的ip,来达到扩容可用端口的目的。
1.给网卡分配2个ip
2.配置示例
http {
#上游服务,我们这里就是到静态资源的端口
upstream static_server {
server http://svc.name:8999
}
server {
# ...
location / {
# ...
proxy_pass http://static_server;
proxy_bind $split_ip;
proxy_set_header X-Forwarded-For $remote_addr;
}
}
#按流量使用ip
split_clients "$remote_addr$remote_port" $split_ip {
#10% 10.0.0.210;
#10% 10.0.0.211;
#10% 10.0.0.212;
#10% 10.0.0.213;
#10% 10.0.0.214;
#10% 10.0.0.215;
#10% 10.0.0.216;
#10% 10.0.0.217;
50% 192.168.1.53;
* 192.168.1.54;
}
}
3.演示结果
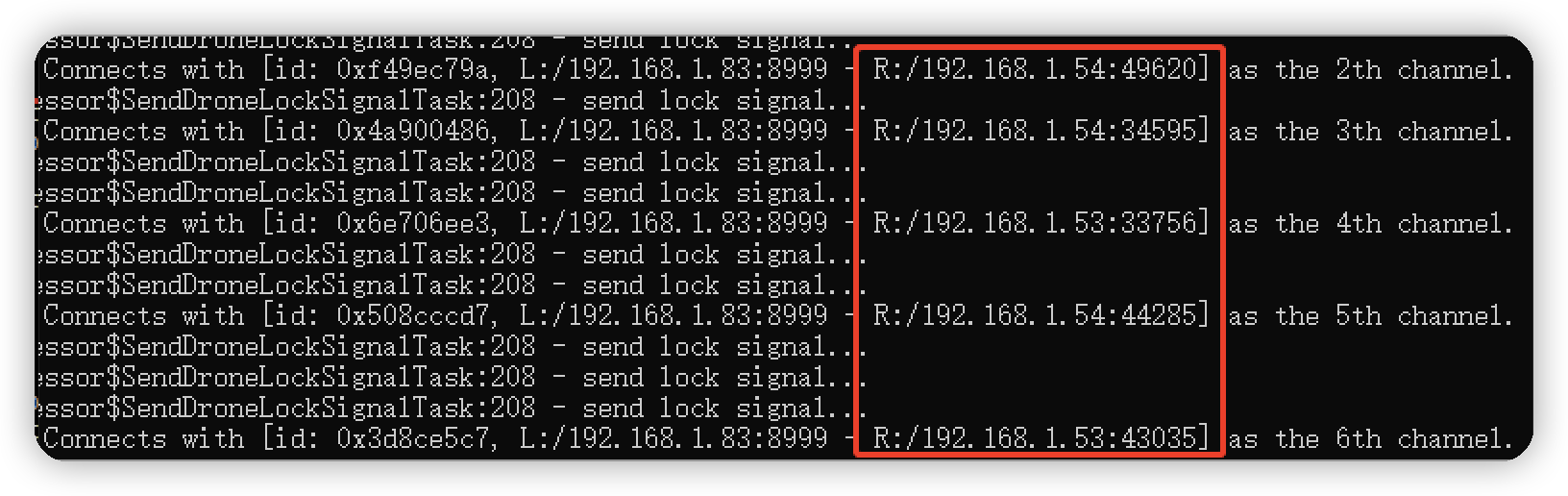
不足之处
- 当时没有查看容器的网络状况,应该netstat查看一下容器的网络,同时netstat查看宿主机的网络,确认端口全被占用发生在容器中还是宿主机上,为什么要查看宿主机的网络,因为转发通过svc进行的,nginx调度会优先调度到没有相同pod的宿主机上,所以存在nginx转发到另一个台nginx上,k8s的网络则会通过宿主机的nat模式来与另一台宿主机通信,一个宿主机上存在多个pod,所以宿主机的端口可能优先会被用完。
- 我并不记得我是否查看了pod的资源利用情况和宿主机资源的利用情况
- 定位问题不够严谨,keepalive应用并没有生效
- 当时对tcp不够了解,对nginx也理解较浅

