
世界最优秀的分布式文件系统架构演进之路原创
前言
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS,解决了海量数据存储的问题;实现了一个分布式计算引擎MapReduce,解决了海量数据如何计算的问题;实现了一个分布式资源调度框架YARN,解决了资源调度,任务管理的问题。而我们今天重点给大家介绍的是Hadoop里享誉世界的优秀的分布式文件系统-HDFS。
Hadoop重要的比较大的版本有:Hadoop1,Hadoop2,hadoop3。同时也相对应的有HDFS1,HDFS2,HDFS3三个大版本。后面的HDFS的版本,都是对前一个版本的架构进行了调整优化,而在这个调整优化的过程当中都是解决上一个版本的架构缺陷,然而这些低版本的架构缺陷也是我们在平时工作当中会经常遇到的问题,所以这篇文章一个重要的目的就是通过给大家介绍HDFS不同版本的架构演进,通过学习高版本是如何解决低版本的架构问题从而来提升我们的系统架构能力。
HDFS1
最早出来投入商业使用的的Hadoop的版本,我们称为Hadoop1,里面的HDFS就是HDFS1,当时刚出来HDFS1,大家都很兴奋,因为它解决了一个海量数据如何存储的问题。HDFS1用的是主从式架构,主节点只有一个叫:Namenode,从节点有多个叫:DataNode。
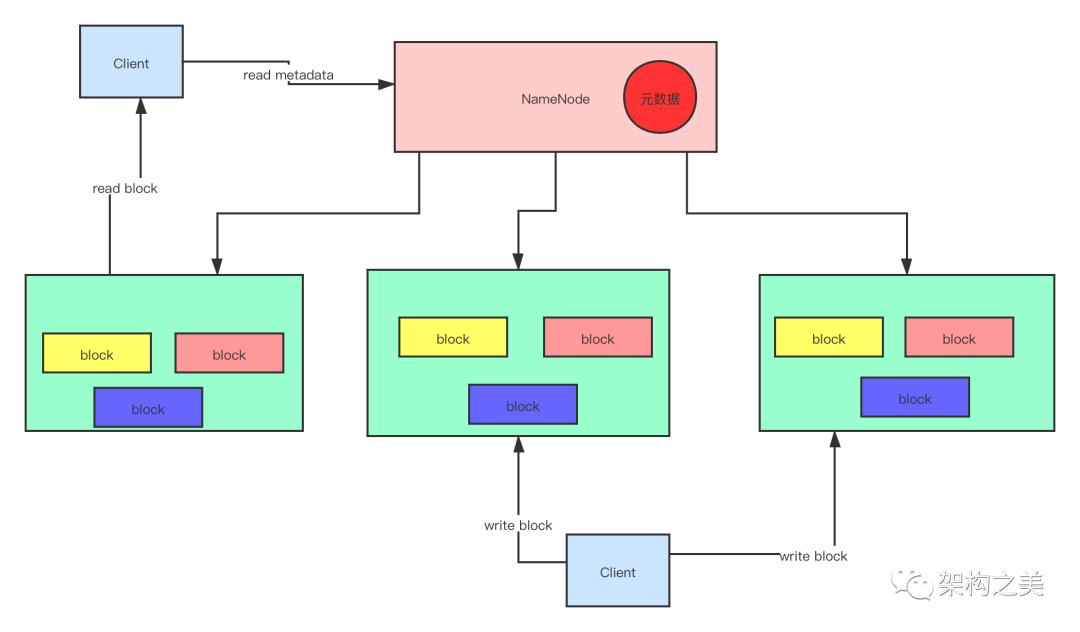
我们往HDFS上上传一个大文件,HDFS会自动把文件划分成为大小固定的数据块(HDFS1的时候,默认块的大小是64M,可以配置),然后这些数据块会分散到存储的不同的服务器上面,为了保证数据安全,HDFS1里默认每个数据块都有3个副本。Namenode是HDFS的主节点,里面维护了文件系统的目录树,存储了文件系统的元数据信息,用户上传文件,下载文件等操作都必须跟NameNode进行交互,因为它存储了元数据信息,Namenode为了能快速响应用户的操作,启动的时候就把元数据信息加载到了内存里面。DataNode是HDFS的从节点,干的活就很简单,就是存储block文件块。
01 / HDFS1架构缺陷
缺陷一:单点故障问题(高可用)
我们很清楚的看到,HDFS1里面只有一个NameNode,那么也就是说如果这个Namenode出问题以后,整个分布式文件系统就不能用了。
缺陷二:内存受限问题
NameNode为了能快速响应用户的操作,把文件系统的元数据信息加载到了内存里面,那么如果一个集群里面存储的文件较多,产生的元数据量也很大,大到namenode所在的服务器撑不下去了,那么文件系统的寿命也就到尽头了,所以从这个角度说,之前的HDFS1的架构里Namenode有内存受限的问题。
我们大体能看得出来,在HDFS1架构设计中,DataNode是没有明显的问题的,主要的问题是在NameNode这儿。
HDFS2
HDFS1明显感觉架构不太成熟,所以HDFS2就是对HDFS1的问题进行解决。
01 / 单点故障问题解决(高可用)
大家先跟着我的思路走,现在我们要解决的是一个单点的问题,其实解决的思路很简单,因为之前是只有一个NameNode,所以有单点故障问题,那我们把设计成两个Namenode就可以了,如果其中一个namenode有问题,就切换到另外一个NameNode上。
所以现在我们想要实现的是:其中一个Namenode有问题,然后可以把服务切换到另外一个Namenode上。如果是这样的话,首先需要解决一个问题:如何保证两个NameNode之间的元数据保持一致?因为只有这样才能保证服务切换以后还能正常干活。
保证两个NameNode之间元数据一致
为了解决两个NameNode之间元数据一致的问题,引入了第三方的一个JournalNode集群。
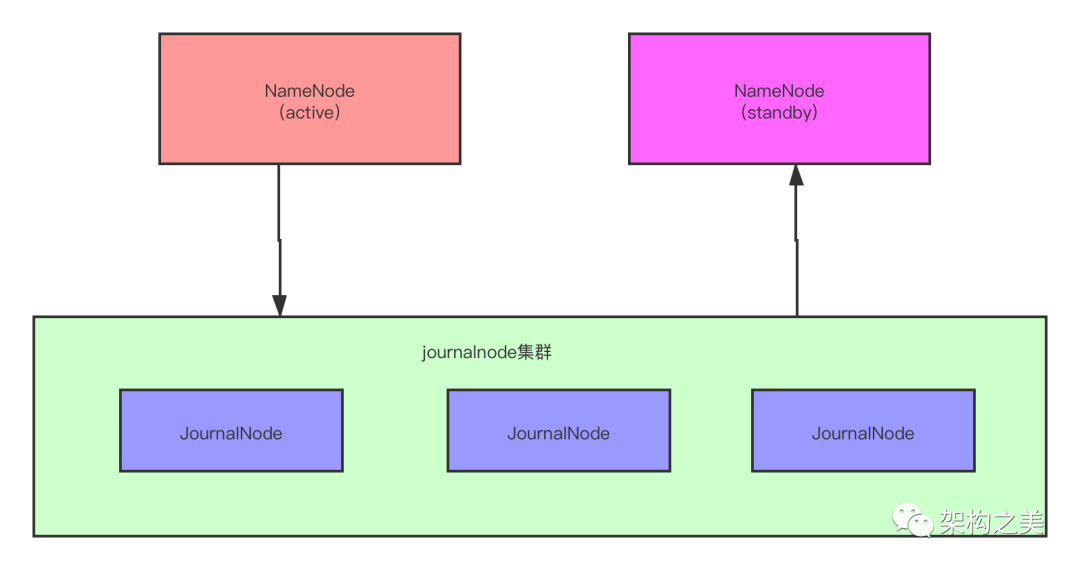
JournalNode集群的特点:JournalNode守护进程是相对轻量级的,那么这些守护进程可与其它Hadoop守护进程,如NameNode,运行在相同的主机上。由于元数据的改变必须写入大多数(一半以上)JNs,所以至少存在3个JournalNodes守护进程,这样系统能够容忍单个Journal Node故障。当然也可以运行多于3个JournalNodes,但为了增加系统能够容忍的故障主机的数量,应该运行奇数个JNs。当运行N个JNs时,系统最多可以接受(N-1)/2个主机故障并能继续正常运行,所以Jounal Node集群本身是没有单点故障问题的。
引入了Journal Node集群以后,Active状态的NameNode实时的往Journal Node集群写元数据,StandBy状态的NameNode实时从Journal Node集群同步元数据,这样就保证了两个NameNode之间的元数据是一致的。
两个NameNode自动切换
目前虽然解决了单点故障的问题,但是目前假如Active NameNode出了问题,还需要我们人工的参与把Standby N ameNode切换成为Active NameNode,这个过程并不是自动化的,但是很明显这个过程我们需要自动化,接下来我们看HDFS2是如何解决自动切换问题的。为了解决自动切换问题,HDFS2引入了ZooKeeper集群和ZKFC进程。
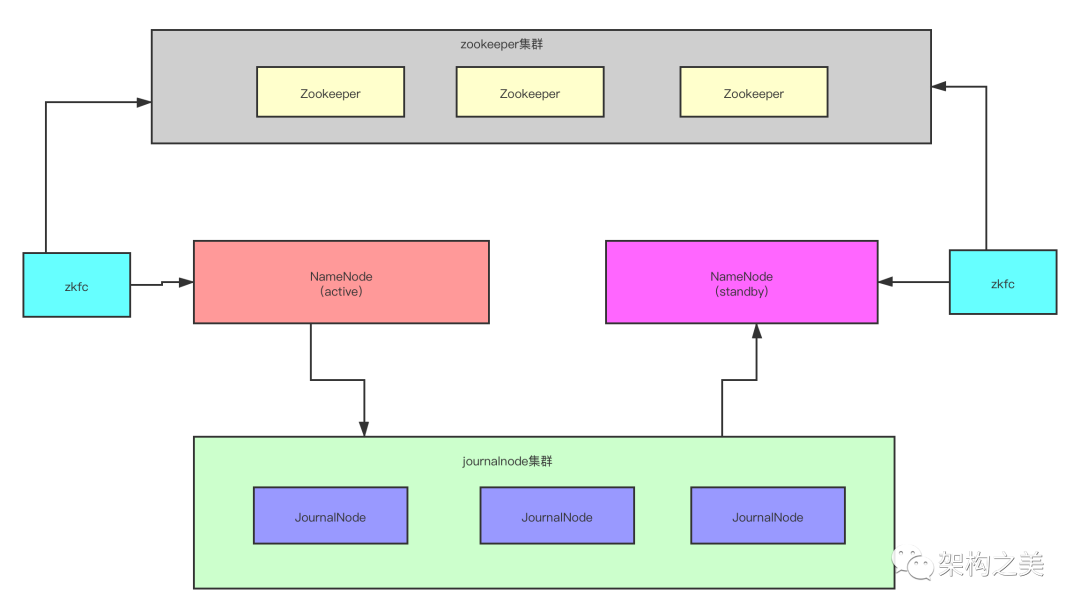
ZKFC是DFSZKFailoverController的简称,这个服务跟NameNode的服务安装在同一台服务器上,主要的作用就是监控NameNode健康状态并向ZooKeeper注册NameNode,如果Active的NameNode挂掉后,ZKFC为StandBy的NameNode竞争锁(分布式锁),获得ZKFC锁的NameNode变为active,所以引入了ZooKeeper集群和ZKFC进程后就解决了NameNode自动切换的问题。
02 / 内存受限问题解决
前面我们虽然解决了高可用的问题,但是如果NameNode的元数据量很大,大到当前NameNode所在的服务器存不下,这个时候集群就不可用了,换句话说就是NameNode的扩展性有问题。为了解决这个问题,HDFS2引入了联邦的机制。
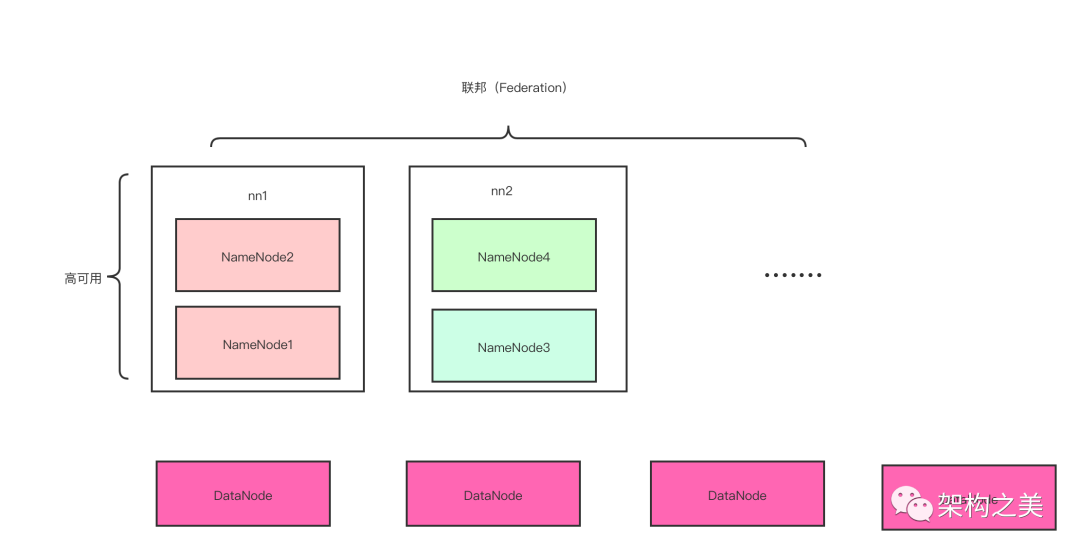
如上图所示这个是一个完整的集群,由多个namenode构成,namenode1和namenode2构成一套namenode,我们取名叫nn1,这两个namenode之间是高可用关系,管理的元数据是一模一样的;namenode3和namenode4构成一套namenode,假设我们取名叫nn2,这两个namenode之间也是高可用关系,管理的元数据也是一模一样的,但是nn1和nn2管理的元数据是不一样的,他们分别只是管理了整个集群元数据的一部分,引入了联邦机制以后,如果后面元数据又存不了,那继续扩nn3,nn4…就可以了。所以这个时候NameNode就在存储元数据方面提升了可扩展性,解决了内存受限的问题。
联邦这个名字是国外翻译过来的,英文名是Federation,之所以叫联邦的管理方式是因为Hadoop的作者是Doug cutting,在美国上学,美国是联邦制的国家,作者从国家管理的方式上联想到元数据的管理方式,其实这个跟我们国家的管理方式也有点类似,就好比我们整个国家是一个完整的集群,但是如果所有的元数据都由北京来管理的话,内存肯定不够,所以中国分了34个省级行政区域,各个区域管理自己的元数据,这行就解决了单服务器内存受限的问题。
HDFS2引入了联邦机制以后,我们用户的使用方式不发生改变,联邦机制对于用户是透明的,因为我们会在上游做一层映射,HDFS2的不同目录的元数据就自动映射到不同的namenode上。
03 / HDFS2的架构缺陷
缺陷一:高可用只能有两个namenode
为了解决单点故障问题,HDFS2设计了两个namenode,一个是active,另外一个是standby,但是这样的话,如果刚好两个NameNode连续出问题了,这个时候集群照样还是不可用,所以从这这个角度讲,NameNode的可扩展性还是有待提高的。
注意:这个时候不要跟联邦那儿混淆,联邦那儿是可以有无数个namenode的,咱们这儿说的只能支持两个namenode指的是是高可用方案。
缺陷二:副本为3,存储浪费了200%
其实这个问题HDFS1的时候就存在,而且这个问题跟NameNode的设计没关系,主要是DataNode这儿的问题,DataNode为了保证数据安全,默认一个block都会有3个副本,这样存储就会浪费了200%。
HDFS3
其实到了HDFS2,HDFS就已经比较成熟稳定了,但是HDFS3还是精益求精,再从架构设计上重新设计了一下。
01 / 高可用之解决只能有两个namenode
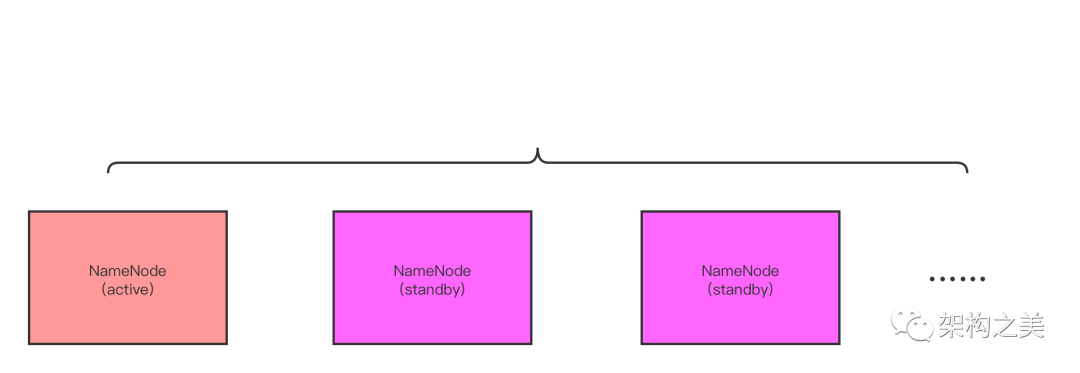
当时在设计HDFS2的时候只是使用了两个NameNode去解决高可用问题,那这样的话,集群里就只有一个NameNode是Standby状态,这个时候假设同时两个NameNode都有问题的话,集群还是存在不可用的风险,所以在设计HDFS3的时候,使其可支持配置多个NameNode用来支持高可用,这样的话就保证了集群的稳定性。
02 / 解决存储浪费问题
HDFS3之前的存储文件的方案是将一个文件切分成多个Block进行存储,通常一个Block 64MB或者128MB,每个Block有多个副本(replica),每个副本作为一个整体存储在一个DataNode上,这种方法在增加可用性的同时也增加了存储成本。ErasureCode通过将M个数据block进行编码(Reed-Solomon,LRC),生成K个校验(parity)block, 这M+K个block组成一个block group,可以同时容忍K个block失败,任何K个block都可以由其他M个block算出来. overhead是K/M。
以M=6,K=3为例,使用EC之前,假设block副本数为3,那么6个block一共18个副本,overhead是200%,使用EC后,9个block,每个block只需一个副本,一共9个副本,其中6个数据副本,3个校验副本,overhead是3/6=50%。
在存储系统中,纠删码技术主要是通过利用纠删码算法将原始的数据进行编码得到校验,并将数据和校验一并存储起来,以达到容错的目的。其基本思想是将k块原始的数据元素通过一定的编码计算,得到m块校验元素。对于这k+m块元素,当其中任意的m块元素出错(包括数据和校验出错),均可以通过对应的重构算法恢复出原来的k块数据。生成校验的过程被称为编码(encoding),恢复丢失数据块的过程被称为解码(decoding)。
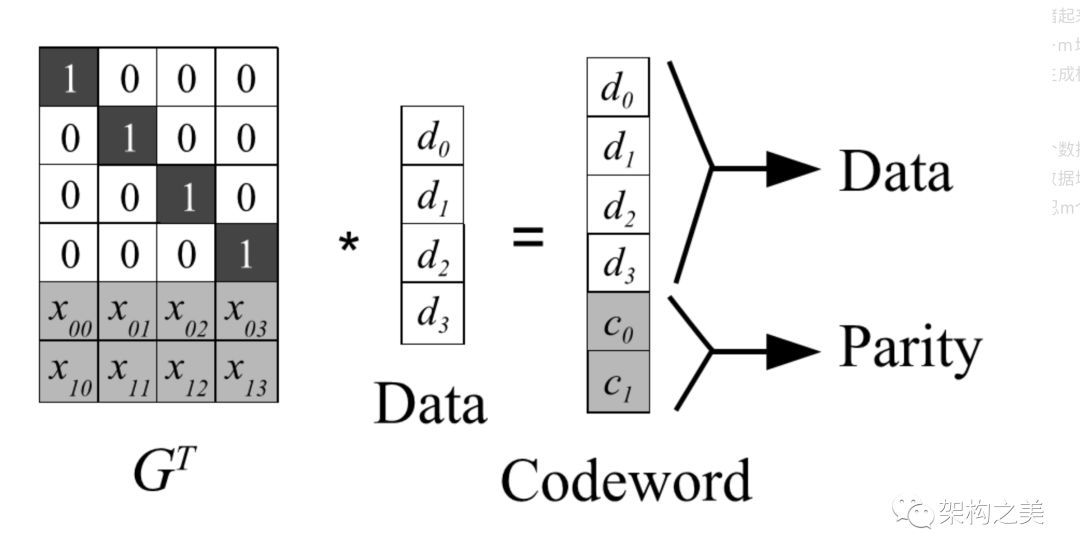
Reed-Solomon(RS)码是存储系统较为常用的一种纠删码,它有两个参数k和m,记为RS(k,m)。如下图所示,k个数据块组成一个向量被乘上一个生成矩阵(Generator Matrix)GT从而得到一个码字(codeword)向量,该向量由k个数据块和m个校验块构成。如果一个数据块丢失,可以用(GT)-1乘以码字向量来恢复出丢失的数据块。RS(k,m)最多可容忍m个块(包括数据块和校验块)丢失。
它是社区最新的HDFS3内部的方案,需要对整个HDFS内部实现进行改造,包括DataNode,NameNode还有DFSClient,该方案同时支持在线和离线EC。
03 / 在线EC
当前HDFS block的副本作为一个整体连续(contiguous)的存储在一个DataNode上,在locality上具有一定的优势,特别是对于MapReduce这样的应用,但是这种方法不好做在线EC。当前社区方案不以block为单位进行EC,而是以strip为单位进行EC(HDFS依旧管理Block)设计思路参考了QFS。对于配置了EC的文件,客户端写入时将文件的数据切成一个个的64KB的strip,相邻的strip发往不同的DataNode,比如当前使用(6,3)-Reed-solomon编码,当前正在写的文件有6个strip: strip1, strip2, strip3, strip4, strip5, strip6, 那么这6个strip和相应的编码出来的3个校验strip共9个strip会并行的发往9个不同的DataNode。这种方式写入性能更好,但是也会对网卡出口带来一些压力,同时牺牲了locality。如果文件大小不是64KB * 6的整数倍(本文例子),那么最后一个strip group显然不是满的,这时客户端还会将最后一个strip group的长度记在校验块中,后续读的时候,可以根据这个长度和数据块长度还有文件长度来校验。
对于append和hflush操作,最后一个parity strip group很可能还没有切换成新的strip group,这就需要DataNode更新最后一个parity strip的数据。
读操作,丢失block时,只需要读9个DataNode中任意6个DataNode即可修复。修复过程需要读多个DataNode,耗费网络带宽和磁盘IO。
04 / 离线EC
该方案也支持离线EC,可以异步的将多副本文件转成EC文件,通过集成在NameNode中的ECManager和DataNode上的ECWorker来支持。命令行工具提供replication和ec之间的转换,可以通过命令行配置哪些文件/目录使用EC. 在转换方程中,不支持append。
这样的话,HDFS3靠就删码技术解决了存储浪费的问题。
尾声
好了,到目前为止我们看到HDFS,三个大的版本的演进的过程,一开始是HDFS1,HDFS1有问题,所以就有了HDFS2,HDFS2就是为了解决HDFS1架构缺陷的,同学们,我们回过头来想想,其实HDFS1的那些架构设计问题,是不是我们平时的项目当中也是存在的,所以以后大家在项目中遇到类似问题的时候,不妨可以参考借鉴一下HDFS2的解决的思路。HDFS3是对HDFS2的优化,其实HDFS3解决的这些问题,如果自己设计过文件系统的同学(本人自己设计过分布式图片服务器)也可用类似的思路去解决系统的高可用和副本造成存储浪费的问题。
作者:孙玄,奈学教育CEO,『架构之美』公众号作者,前58同城技术委员会主席。

