
聊聊 Netty 那些事儿之从内核角度看 IO 模型原创
从今天开始我们来聊聊Netty的那些事儿,我们都知道Netty是一个高性能异步事件驱动的网络框架。
它的设计异常优雅简洁,扩展性高,稳定性强。拥有非常详细完整的用户文档。
同时内置了很多非常有用的模块基本上做到了开箱即用,用户只需要编写短短几行代码,就可以快速构建出一个具有高吞吐,低延时,更少的资源消耗,高性能(非必要的内存拷贝最小化)等特征的高并发网络应用程序。
本文我们来探讨下支持Netty具有高吞吐,低延时特征的基石----netty的网络IO模型。
由Netty的网络IO模型开始,我们来正式揭开本系列Netty源码解析的序幕:
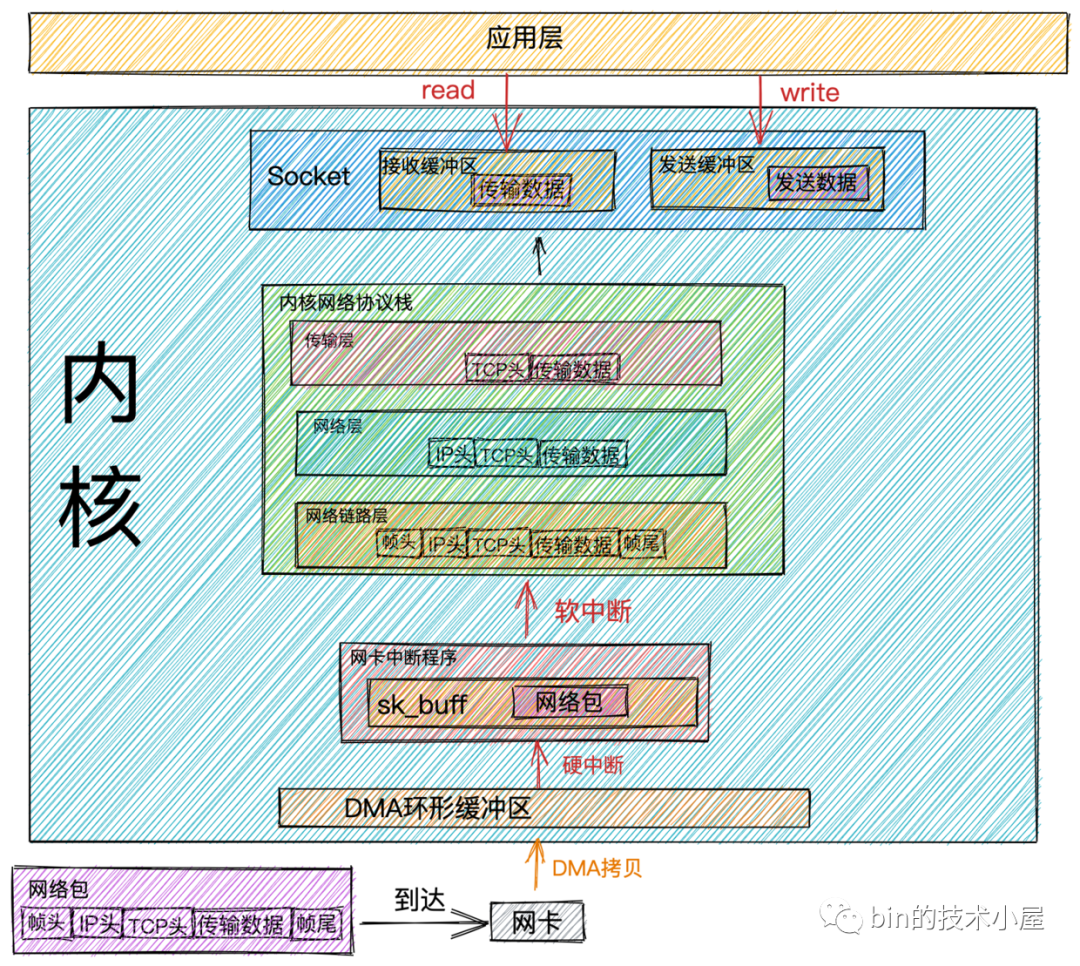
网络包接收流程
-
当 网络数据帧通过网络传输到达网卡时,网卡会将网络数据帧通过DMA的方式放到环形缓冲区RingBuffer中。
RingBuffer是网卡在启动的时候分配和初始化的环形缓冲队列。当RingBuffer满的时候,新来的数据包就会被丢弃。我们可以通过ifconfig命令查看网卡收发数据包的情况。其中overruns数据项表示当RingBuffer满时,被丢弃的数据包。如果发现出现丢包情况,可以通过ethtool命令来增大RingBuffer长度。
-
当 DMA操作完成时,网卡会向CPU发起一个硬中断,告诉CPU有网络数据到达。CPU调用网卡驱动注册的硬中断响应程序。网卡硬中断响应程序会为网络数据帧创建内核数据结构sk_buffer,并将网络数据帧拷贝到sk_buffer中。然后发起软中断请求,通知内核有新的网络数据帧到达。
sk_buff缓冲区,是一个维护网络帧结构的双向链表,链表中的每一个元素都是一个网络帧。虽然 TCP/IP 协议栈分了好几层,但上下不同层之间的传递,实际上只需要操作这个数据结构中的指针,而无需进行数据复制。
-
内核线程 ksoftirqd发现有软中断请求到来,随后调用网卡驱动注册的poll函数,poll函数将sk_buffer中的网络数据包送到内核协议栈中注册的ip_rcv函数中。
每个CPU会绑定一个ksoftirqd内核线程专门用来处理软中断响应。2个 CPU 时,就会有ksoftirqd/0和ksoftirqd/1这两个内核线程。
这里有个事情需要注意下: 网卡接收到数据后,当
DMA拷贝完成时,向CPU发出硬中断,这时哪个CPU上响应了这个硬中断,那么在网卡硬中断响应程序中发出的软中断请求也会在这个CPU绑定的ksoftirqd线程中响应。所以如果发现Linux软中断,CPU消耗都集中在一个核上的话,那么就需要调整硬中断的CPU亲和性,来将硬中断打散到不通的CPU核上去。
-
在 ip_rcv函数中也就是上图中的网络层,取出数据包的IP头,判断该数据包下一跳的走向,如果数据包是发送给本机的,则取出传输层的协议类型(TCP或者UDP),并去掉数据包的IP头,将数据包交给上图中得传输层处理。
传输层的处理函数:
TCP协议对应内核协议栈中注册的tcp_rcv函数,UDP协议对应内核协议栈中注册的udp_rcv函数。
-
当我们采用的是
TCP协议时,数据包到达传输层时,会在内核协议栈中的tcp_rcv函数处理,在tcp_rcv函数中去掉TCP头,根据四元组(源IP,源端口,目的IP,目的端口)查找对应的Socket,如果找到对应的Socket则将网络数据包中的传输数据拷贝到Socket中的接收缓冲区中。如果没有找到,则发送一个目标不可达的icmp包。 -
内核在接收网络数据包时所做的工作我们就介绍完了,现在我们把视角放到应用层,当我们程序通过系统调用
read读取Socket接收缓冲区中的数据时,如果接收缓冲区中没有数据,那么应用程序就会在系统调用上阻塞,直到Socket接收缓冲区有数据,然后CPU将内核空间(Socket接收缓冲区)的数据拷贝到用户空间,最后系统调用read返回,应用程序读取数据。
性能开销
从内核处理网络数据包接收的整个过程来看,内核帮我们做了非常之多的工作,最终我们的应用程序才能读取到网络数据。
随着而来的也带来了很多的性能开销,结合前面介绍的网络数据包接收过程我们来看下网络数据包接收的过程中都有哪些性能开销:
-
应用程序通过 系统调用从用户态转为内核态的开销以及系统调用返回时从内核态转为用户态的开销。 -
网络数据从 内核空间通过CPU拷贝到用户空间的开销。 -
内核线程 ksoftirqd响应软中断的开销。 -
CPU响应硬中断的开销。 -
DMA拷贝网络数据包到内存中的开销。
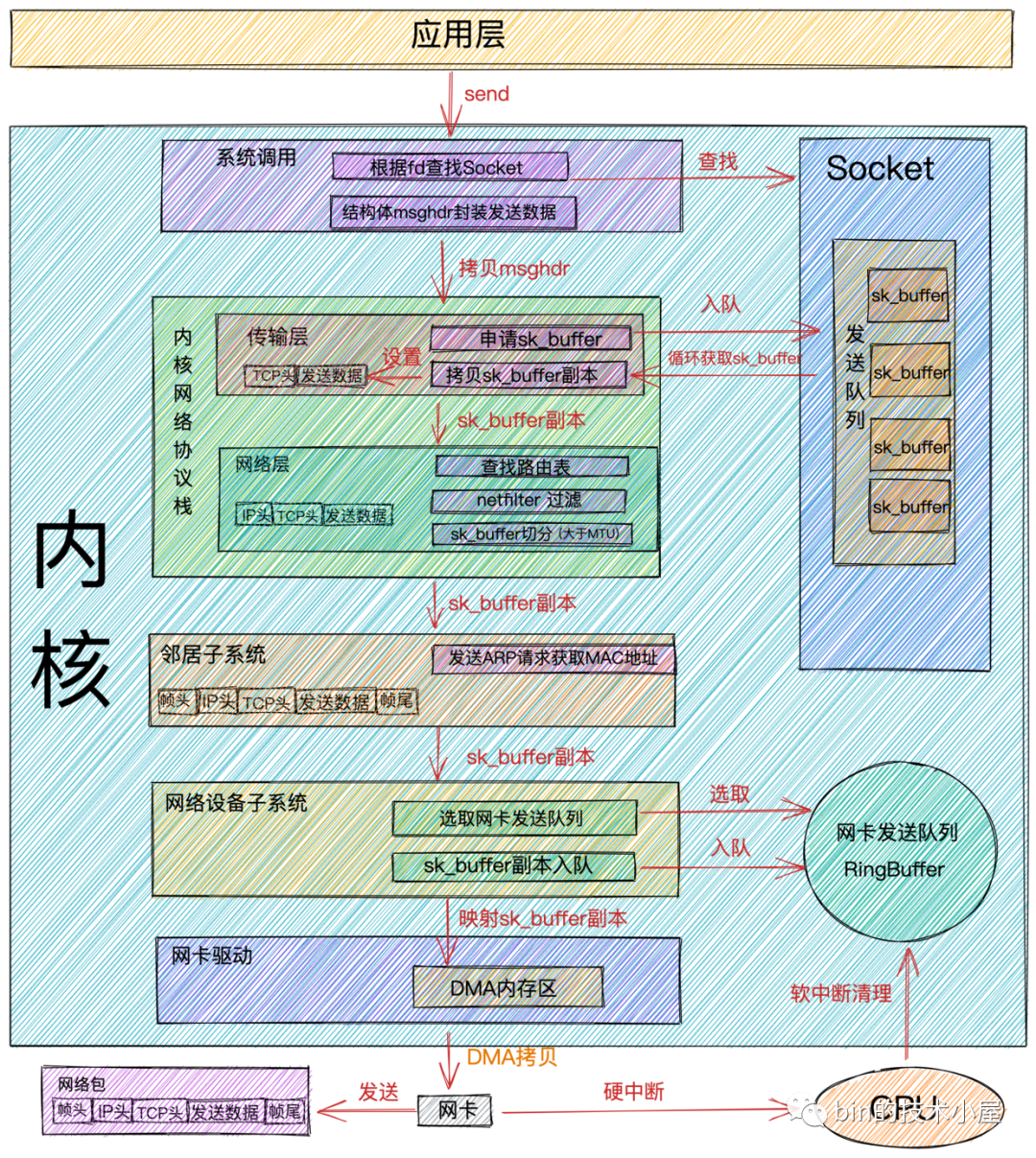
网络包发送流程
-
当我们在应用程序中调用
send系统调用发送数据时,由于是系统调用所以线程会发生一次用户态到内核态的转换,在内核中首先根据fd将真正的Socket找出,这个Socket对象中记录着各种协议栈的函数地址,然后构造struct msghdr对象,将用户需要发送的数据全部封装在这个struct msghdr结构体中。 -
调用内核协议栈函数
inet_sendmsg,发送流程进入内核协议栈处理。在进入到内核协议栈之后,内核会找到Socket上的具体协议的发送函数。
比如:我们使用的是
TCP协议,对应的TCP协议发送函数是tcp_sendmsg,如果是UDP协议的话,对应的发送函数为udp_sendmsg。
-
在 TCP协议的发送函数tcp_sendmsg中,创建内核数据结构sk_buffer,将struct msghdr结构体中的发送数据拷贝到sk_buffer中。调用tcp_write_queue_tail函数获取Socket发送队列中的队尾元素,将新创建的sk_buffer添加到Socket发送队列的尾部。
Socket的发送队列是由sk_buffer组成的一个双向链表。
发送流程走到这里,用户要发送的数据总算是从
用户空间拷贝到了内核中,这时虽然发送数据已经拷贝到了内核Socket中的发送队列中,但并不代表内核会开始发送,因为TCP协议的流量控制和拥塞控制,用户要发送的数据包并不一定会立马被发送出去,需要符合TCP协议的发送条件。如果没有达到发送条件,那么本次send系统调用就会直接返回。
-
如果符合发送条件,则开始调用
tcp_write_xmit内核函数。在这个函数中,会循环获取Socket发送队列中待发送的sk_buffer,然后进行拥塞控制以及滑动窗口的管理。 -
将从
Socket发送队列中获取到的sk_buffer重新拷贝一份,设置sk_buffer副本中的TCP HEADER。
sk_buffer内部其实包含了网络协议中所有的header。在设置TCP HEADER的时候,只是把指针指向sk_buffer的合适位置。后面再设置IP HEADER的时候,在把指针移动一下就行,避免频繁的内存申请和拷贝,效率很高。
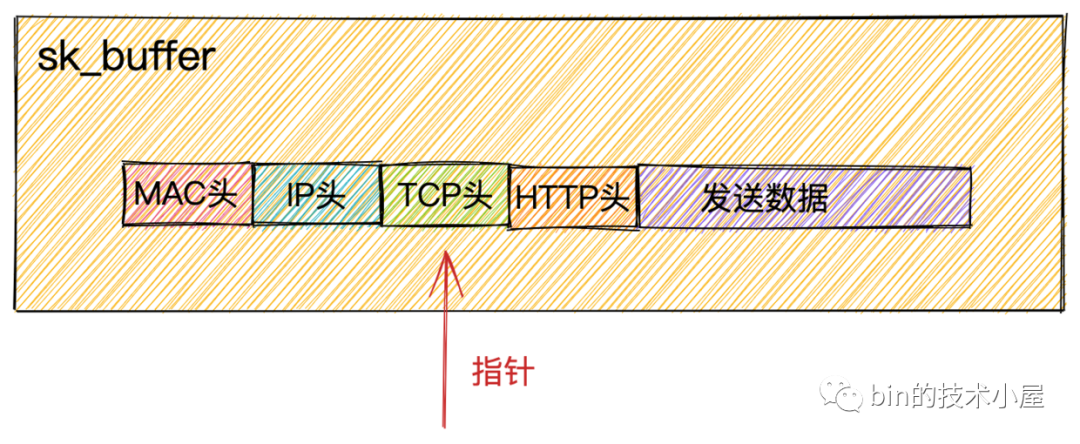
为什么不直接使用
Socket发送队列中的sk_buffer而是需要拷贝一份呢?因为TCP协议是支持丢包重传的,在没有收到对端的ACK之前,这个sk_buffer是不能删除的。内核每次调用网卡发送数据的时候,实际上传递的是sk_buffer的拷贝副本,当网卡把数据发送出去后,sk_buffer拷贝副本会被释放。当收到对端的ACK之后,Socket发送队列中的sk_buffer才会被真正删除。
-
当设置完
TCP头后,内核协议栈传输层的事情就做完了,下面通过调用ip_queue_xmit内核函数,正式来到内核协议栈网络层的处理。通过
route命令可以查看本机路由配置。如果你使用
iptables配置了一些规则,那么这里将检测是否命中规则。如果你设置了非常复杂的 netfilter 规则,在这个函数里将会导致你的线程CPU 开销会极大增加。 -
将
sk_buffer中的指针移动到IP头位置上,设置IP头。 -
执行
netfilters过滤。过滤通过之后,如果数据大于MTU的话,则执行分片。 -
检查 Socket中是否有缓存路由表,如果没有的话,则查找路由项,并缓存到Socket中。接着在把路由表设置到sk_buffer中。 -
内核协议栈
网络层的事情处理完后,现在发送流程进入了到了邻居子系统,邻居子系统位于内核协议栈中的网络层和网络接口层之间,用于发送ARP请求获取MAC地址,然后将sk_buffer中的指针移动到MAC头位置,填充MAC头。 -
经过
邻居子系统的处理,现在sk_buffer中已经封装了一个完整的数据帧,随后内核将sk_buffer交给网络设备子系统进行处理。网络设备子系统主要做以下几项事情: -
选择发送队列( RingBuffer)。因为网卡拥有多个发送队列,所以在发送前需要选择一个发送队列。 -
将 sk_buffer添加到发送队列中。 -
循环从发送队列( RingBuffer)中取出sk_buffer,调用内核函数sch_direct_xmit发送数据,其中会调用网卡驱动程序来发送数据。
以上过程全部是用户线程的内核态在执行,占用的CPU时间是系统态时间(
sy),当分配给用户线程的CPU quota用完的时候,会触发NET_TX_SOFTIRQ类型的软中断,内核线程ksoftirqd会响应这个软中断,并执行NET_TX_SOFTIRQ类型的软中断注册的回调函数net_tx_action,在回调函数中会执行到驱动程序函数dev_hard_start_xmit来发送数据。
注意:当触发
NET_TX_SOFTIRQ软中断来发送数据时,后边消耗的 CPU 就都显示在si这里了,不会消耗用户进程的系统态时间(sy)了。
从这里可以看到网络包的发送过程和接受过程是不同的,在介绍网络包的接受过程时,我们提到是通过触发
NET_RX_SOFTIRQ类型的软中断在内核线程ksoftirqd中执行内核网络协议栈接受数据。而在网络数据包的发送过程中是用户线程的内核态在执行内核网络协议栈,只有当线程的CPU quota用尽时,才触发NET_TX_SOFTIRQ软中断来发送数据。
在整个网络包的发送和接受过程中,
NET_TX_SOFTIRQ类型的软中断只会在发送网络包时并且当用户线程的CPU quota用尽时,才会触发。剩下的接受过程中触发的软中断类型以及发送完数据触发的软中断类型均为NET_RX_SOFTIRQ。所以这就是你在服务器上查看/proc/softirqs,一般NET_RX都要比NET_TX大很多的的原因。
-
现在发送流程终于到了网卡真实发送数据的阶段,前边我们讲到无论是用户线程的内核态还是触发
NET_TX_SOFTIRQ类型的软中断在发送数据的时候最终会调用到网卡的驱动程序函数dev_hard_start_xmit来发送数据。在网卡驱动程序函数dev_hard_start_xmit中会将sk_buffer映射到网卡可访问的内存 DMA 区域,最终网卡驱动程序通过DMA的方式将数据帧通过物理网卡发送出去。 -
当数据发送完毕后,还有最后一项重要的工作,就是清理工作。数据发送完毕后,网卡设备会向
CPU发送一个硬中断,CPU调用网卡驱动程序注册的硬中断响应程序,在硬中断响应中触发NET_RX_SOFTIRQ类型的软中断,在软中断的回调函数igb_poll中清理释放sk_buffer,清理网卡发送队列(RingBuffer),解除 DMA 映射。
无论
硬中断是因为有数据要接收,还是说发送完成通知,从硬中断触发的软中断都是NET_RX_SOFTIRQ。
这里释放清理的只是
sk_buffer的副本,真正的sk_buffer现在还是存放在Socket的发送队列中。前面在传输层处理的时候我们提到过,因为传输层需要保证可靠性,所以sk_buffer其实还没有删除。它得等收到对方的 ACK 之后才会真正删除。
性能开销
前边我们提到了在网络包接收过程中涉及到的性能开销,现在介绍完了网络包的发送过程,我们来看下在数据包发送过程中的性能开销:
-
和接收数据一样,应用程序在调用
系统调用send的时候会从用户态转为内核态以及发送完数据后,系统调用返回时从内核态转为用户态的开销。 -
用户线程内核态
CPU quota用尽时触发NET_TX_SOFTIRQ类型软中断,内核响应软中断的开销。 -
网卡发送完数据,向
CPU发送硬中断,CPU响应硬中断的开销。以及在硬中断中发送NET_RX_SOFTIRQ软中断执行具体的内存清理动作。内核响应软中断的开销。 -
内存拷贝的开销。我们来回顾下在数据包发送的过程中都发生了哪些内存拷贝:
-
在内核协议栈的传输层中, TCP协议对应的发送函数tcp_sendmsg会申请sk_buffer,将用户要发送的数据拷贝到sk_buffer中。 -
在发送流程从传输层到网络层的时候,会 拷贝一个sk_buffer副本出来,将这个sk_buffer副本向下传递。原始sk_buffer保留在Socket发送队列中,等待网络对端ACK,对端ACK后删除Socket发送队列中的sk_buffer。对端没有发送ACK,则重新从Socket发送队列中发送,实现TCP协议的可靠传输。 -
在网络层,如果发现要发送的数据大于 MTU,则会进行分片操作,申请额外的sk_buffer,并将原来的sk_buffer拷贝到多个小的sk_buffer中。
再谈(阻塞,非阻塞)与(同步,异步)
在我们聊完网络数据的接收和发送过程后,我们来谈下IO中特别容易混淆的概念:阻塞与同步,非阻塞与异步。
网上各种博文还有各种书籍中有大量的关于这两个概念的解释,但是笔者觉得还是不够形象化,只是对概念的生硬解释,如果硬套概念的话,其实感觉阻塞与同步,非阻塞与异步还是没啥区别,时间长了,还是比较模糊容易混淆。
所以笔者在这里尝试换一种更加形象化,更加容易理解记忆的方式来清晰地解释下什么是阻塞与非阻塞,什么是同步与异步。
经过前边对网络数据包接收流程的介绍,在这里我们可以将整个流程总结为两个阶段:

-
数据准备阶段: 在这个阶段,网络数据包到达网卡,通过
DMA的方式将数据包拷贝到内存中,然后经过硬中断,软中断,接着通过内核线程ksoftirqd经过内核协议栈的处理,最终将数据发送到内核Socket的接收缓冲区中。 -
数据拷贝阶段: 当数据到达
内核Socket的接收缓冲区中时,此时数据存在于内核空间中,需要将数据拷贝到用户空间中,才能够被应用程序读取。
阻塞与非阻塞
阻塞与非阻塞的区别主要发生在第一阶段:数据准备阶段。
当应用程序发起系统调用read时,线程从用户态转为内核态,读取内核Socket的接收缓冲区中的网络数据。
阻塞
如果这时内核Socket的接收缓冲区没有数据,那么线程就会一直等待,直到Socket接收缓冲区有数据为止。随后将数据从内核空间拷贝到用户空间,系统调用read返回。
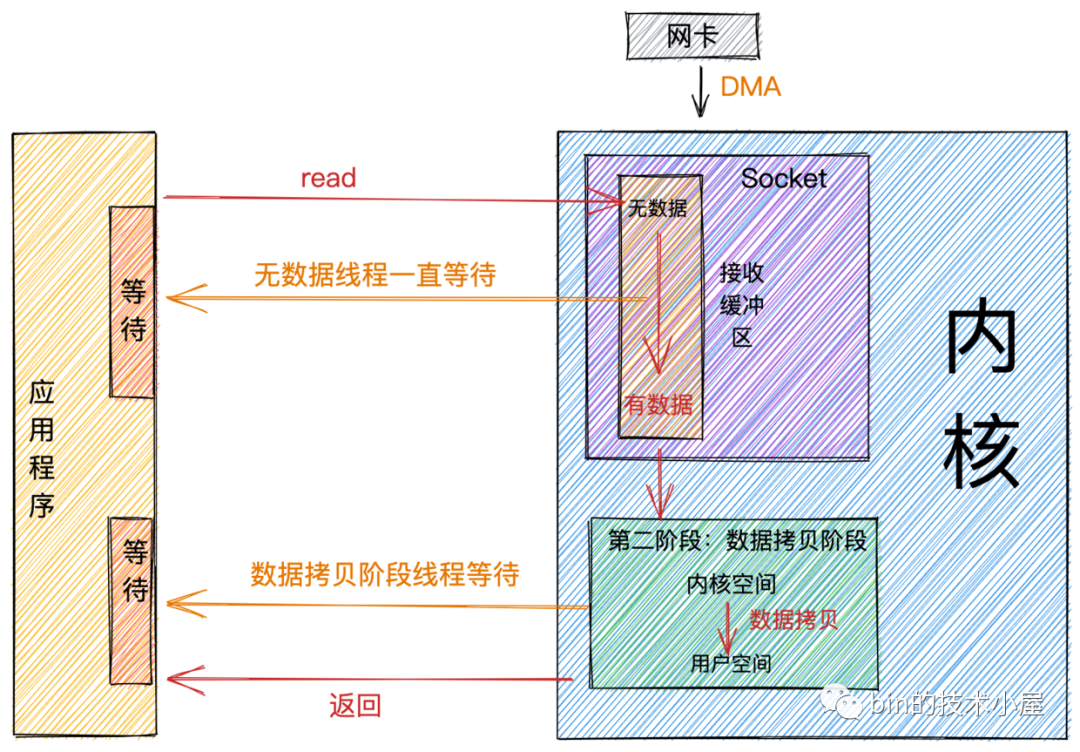
从图中我们可以看出:阻塞的特点是在第一阶段和第二阶段都会等待。
非阻塞
阻塞和非阻塞主要的区分是在第一阶段:数据准备阶段。
-
在第一阶段,当
Socket的接收缓冲区中没有数据的时候,阻塞模式下应用线程会一直等待。非阻塞模式下应用线程不会等待,系统调用直接返回错误标志EWOULDBLOCK。 -
当
Socket的接收缓冲区中有数据的时候,阻塞和非阻塞的表现是一样的,都会进入第二阶段等待数据从内核空间拷贝到用户空间,然后系统调用返回。
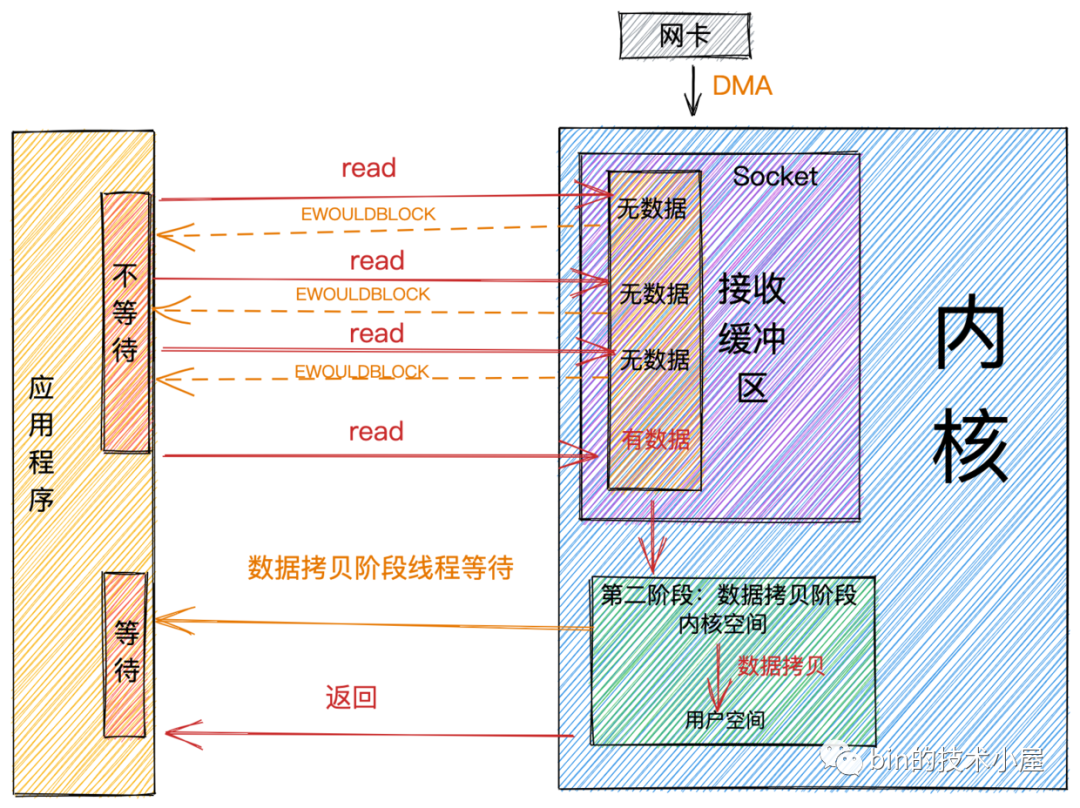
从上图中,我们可以看出:非阻塞的特点是第一阶段不会等待,但是在第二阶段还是会等待。
同步与异步
同步与异步主要的区别发生在第二阶段:数据拷贝阶段。
前边我们提到在数据拷贝阶段主要是将数据从内核空间拷贝到用户空间。然后应用程序才可以读取数据。
当内核Socket的接收缓冲区有数据到达时,进入第二阶段。
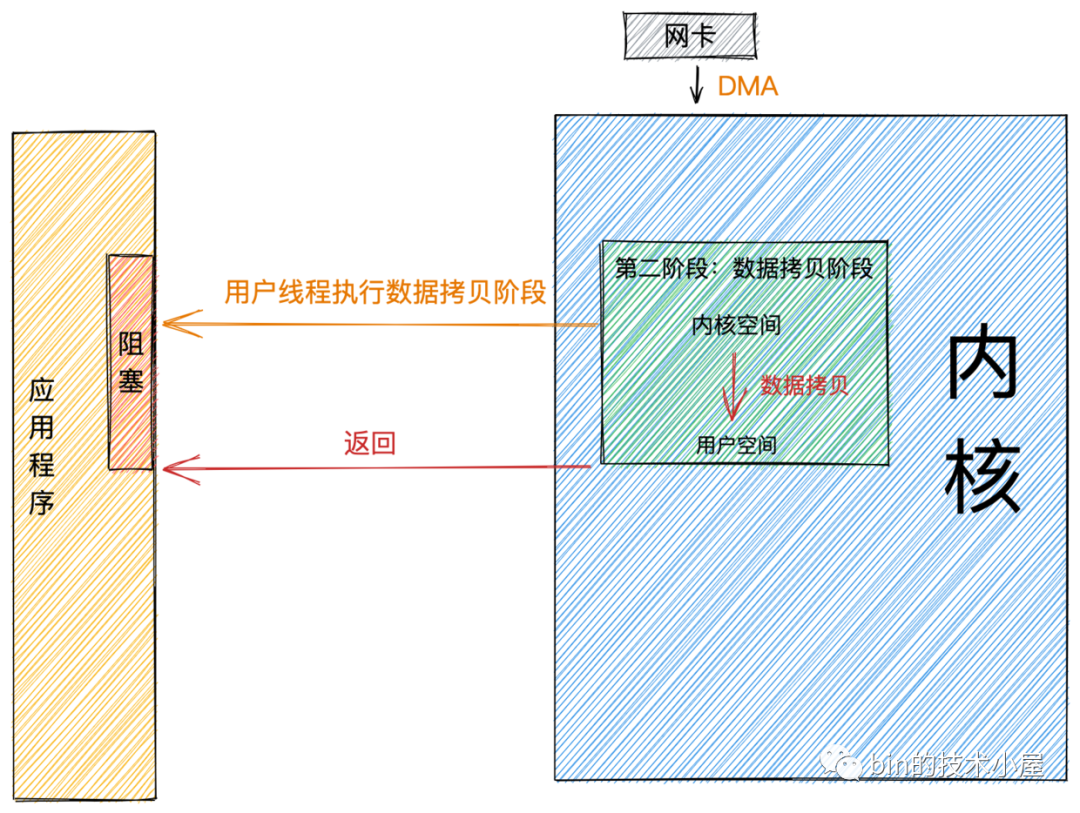
同步
同步模式在数据准备好后,是由用户线程的内核态来执行第二阶段。所以应用程序会在第二阶段发生阻塞,直到数据从内核空间拷贝到用户空间,系统调用才会返回。
Linux下的 epoll和Mac 下的 kqueue都属于同步 IO。
异步
异步模式下是由内核来执行第二阶段的数据拷贝操作,当内核执行完第二阶段,会通知用户线程IO操作已经完成,并将数据回调给用户线程。所以在异步模式下 数据准备阶段和数据拷贝阶段均是由内核来完成,不会对应用程序造成任何阻塞。
基于以上特征,我们可以看到异步模式需要内核的支持,比较依赖操作系统底层的支持。
在目前流行的操作系统中,只有Windows 中的 IOCP才真正属于异步 IO,实现的也非常成熟。但Windows很少用来作为服务器使用。
而常用来作为服务器使用的Linux,异步IO机制实现的不够成熟,与NIO相比性能提升的也不够明显。
但Linux kernel 在5.1版本由Facebook的大神Jens Axboe引入了新的异步IO库io_uring 改善了原来Linux native AIO的一些性能问题。性能相比Epoll以及之前原生的AIO提高了不少,值得关注。

IO模型
在进行网络IO操作时,用什么样的IO模型来读写数据将在很大程度上决定了网络框架的IO性能。所以IO模型的选择是构建一个高性能网络框架的基础。
在《UNIX 网络编程》一书中介绍了五种IO模型:阻塞IO,非阻塞IO,IO多路复用,信号驱动IO,异步IO,每一种IO模型的出现都是对前一种的升级优化。
下面我们就来分别介绍下这五种IO模型各自都解决了什么问题,适用于哪些场景,各自的优缺点是什么?
阻塞IO(BIO)
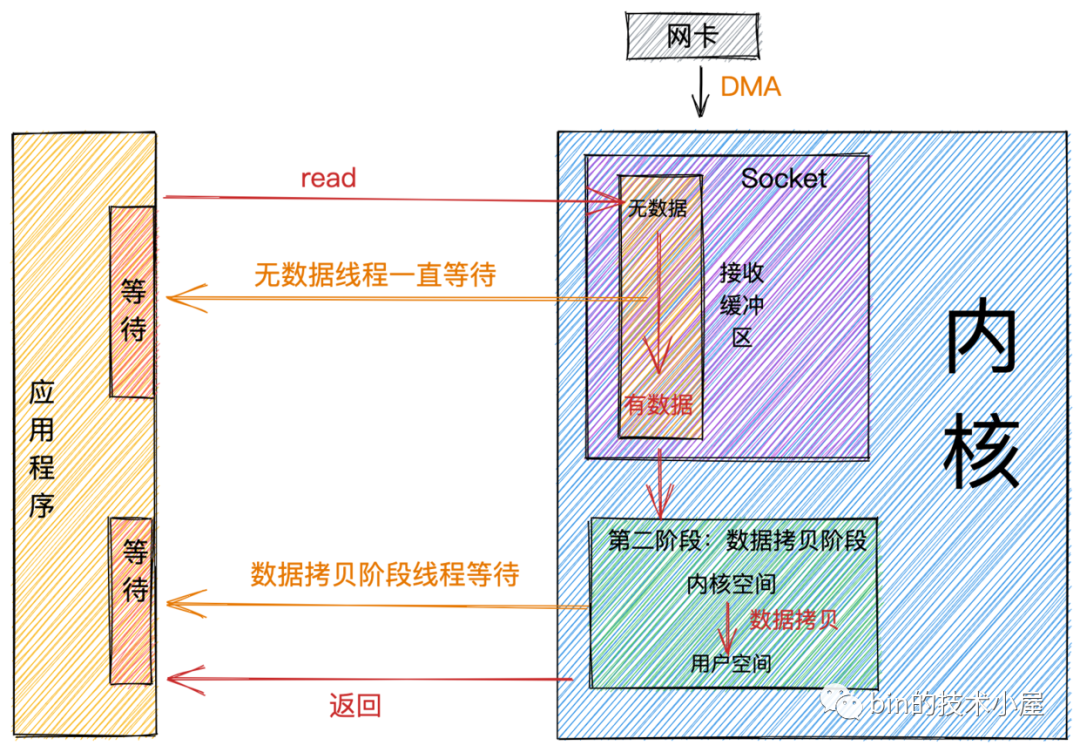
经过前一小节对阻塞这个概念的介绍,相信大家可以很容易理解阻塞IO的概念和过程。
既然这小节我们谈的是IO,那么下边我们来看下在阻塞IO模型下,网络数据的读写过程。
阻塞读
当用户线程发起read系统调用,用户线程从用户态切换到内核态,在内核中去查看Socket接收缓冲区是否有数据到来。
-
Socket接收缓冲区中有数据,则用户线程在内核态将内核空间中的数据拷贝到用户空间,系统IO调用返回。 -
Socket接收缓冲区中无数据,则用户线程让出CPU,进入阻塞状态。当数据到达Socket接收缓冲区后,内核唤醒阻塞状态中的用户线程进入就绪状态,随后经过CPU的调度获取到CPU quota进入运行状态,将内核空间的数据拷贝到用户空间,随后系统调用返回。
阻塞写
当用户线程发起send系统调用时,用户线程从用户态切换到内核态,将发送数据从用户空间拷贝到内核空间中的Socket发送缓冲区中。
-
当
Socket发送缓冲区能够容纳下发送数据时,用户线程会将全部的发送数据写入Socket缓冲区,然后执行在《网络包发送流程》这小节介绍的后续流程,然后返回。 -
当
Socket发送缓冲区空间不够,无法容纳下全部发送数据时,用户线程让出CPU,进入阻塞状态,直到Socket发送缓冲区能够容纳下全部发送数据时,内核唤醒用户线程,执行后续发送流程。
阻塞IO模型下的写操作做事风格比较硬刚,非得要把全部的发送数据写入发送缓冲区才肯善罢甘休。
阻塞IO模型

由于阻塞IO的读写特点,所以导致在阻塞IO模型下,每个请求都需要被一个独立的线程处理。一个线程在同一时刻只能与一个连接绑定。来一个请求,服务端就需要创建一个线程用来处理请求。
当客户端请求的并发量突然增大时,服务端在一瞬间就会创建出大量的线程,而创建线程是需要系统资源开销的,这样一来就会一瞬间占用大量的系统资源。
如果客户端创建好连接后,但是一直不发数据,通常大部分情况下,网络连接也并不总是有数据可读,那么在空闲的这段时间内,服务端线程就会一直处于阻塞状态,无法干其他的事情。CPU也无法得到充分的发挥,同时还会导致大量线程切换的开销。
适用场景
基于以上阻塞IO模型的特点,该模型只适用于连接数少,并发度低的业务场景。
比如公司内部的一些管理系统,通常请求数在100个左右,使用阻塞IO模型还是非常适合的。而且性能还不输NIO。
该模型在C10K之前,是普遍被采用的一种IO模型。
非阻塞IO(NIO)
阻塞IO模型最大的问题就是一个线程只能处理一个连接,如果这个连接上没有数据的话,那么这个线程就只能阻塞在系统IO调用上,不能干其他的事情。这对系统资源来说,是一种极大的浪费。同时大量的线程上下文切换,也是一个巨大的系统开销。
所以为了解决这个问题,我们就需要用尽可能少的线程去处理更多的连接。,网络IO模型的演变也是根据这个需求来一步一步演进的。
基于这个需求,第一种解决方案非阻塞IO就出现了。我们在上一小节中介绍了非阻塞的概念,现在我们来看下网络读写操作在非阻塞IO下的特点:

非阻塞读
当用户线程发起非阻塞read系统调用时,用户线程从用户态转为内核态,在内核中去查看Socket接收缓冲区是否有数据到来。
-
Socket接收缓冲区中无数据,系统调用立马返回,并带有一个EWOULDBLOCK或EAGAIN错误,这个阶段用户线程不会阻塞,也不会让出CPU,而是会继续轮训直到Socket接收缓冲区中有数据为止。 -
Socket接收缓冲区中有数据,用户线程在内核态会将内核空间中的数据拷贝到用户空间,注意这个数据拷贝阶段,应用程序是阻塞的,当数据拷贝完成,系统调用返回。
非阻塞写
前边我们在介绍阻塞写的时候提到阻塞写的风格特别的硬朗,头比较铁非要把全部发送数据一次性都写到Socket的发送缓冲区中才返回,如果发送缓冲区中没有足够的空间容纳,那么就一直阻塞死等,特别的刚。
相比较而言非阻塞写的特点就比较佛系,当发送缓冲区中没有足够的空间容纳全部发送数据时,非阻塞写的特点是能写多少写多少,写不下了,就立即返回。并将写入到发送缓冲区的字节数返回给应用程序,方便用户线程不断的轮训尝试将剩下的数据写入发送缓冲区中。
非阻塞IO模型
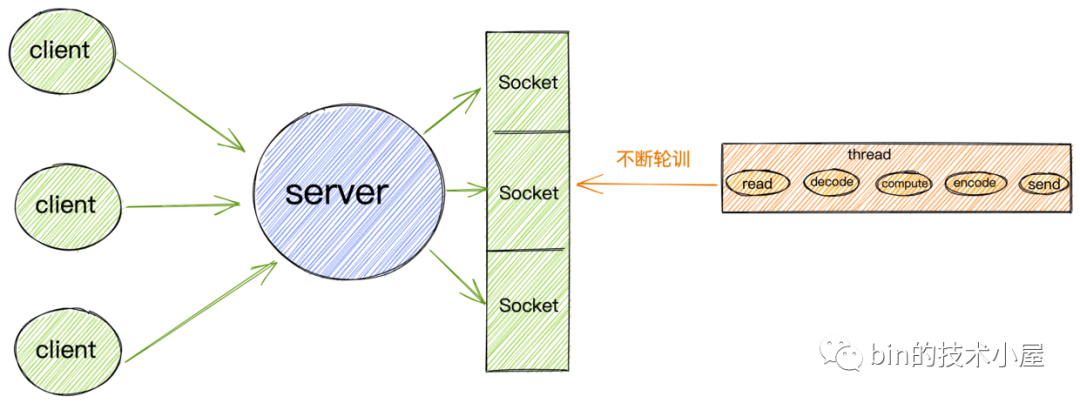
基于以上非阻塞IO的特点,我们就不必像阻塞IO那样为每个请求分配一个线程去处理连接上的读写了。
我们可以利用一个线程或者很少的线程,去不断地轮询每个Socket的接收缓冲区是否有数据到达,如果没有数据,不必阻塞线程,而是接着去轮询下一个Socket接收缓冲区,直到轮询到数据后,处理连接上的读写,或者交给业务线程池去处理,轮询线程则继续轮询其他的Socket接收缓冲区。
这样一个非阻塞IO模型就实现了我们在本小节开始提出的需求:我们需要用尽可能少的线程去处理更多的连接
适用场景
虽然非阻塞IO模型与阻塞IO模型相比,减少了很大一部分的资源消耗和系统开销。
但是它仍然有很大的性能问题,因为在非阻塞IO模型下,需要用户线程去不断地发起系统调用去轮训Socket接收缓冲区,这就需要用户线程不断地从用户态切换到内核态,内核态切换到用户态。随着并发量的增大,这个上下文切换的开销也是巨大的。
所以单纯的非阻塞IO模型还是无法适用于高并发的场景。只能适用于C10K以下的场景。
IO多路复用
在非阻塞IO这一小节的开头,我们提到网络IO模型的演变都是围绕着---如何用尽可能少的线程去处理更多的连接这个核心需求开始展开的。
本小节我们来谈谈IO多路复用模型,那么什么是多路?,什么又是复用呢?
我们还是以这个核心需求来对这两个概念展开阐述:
-
多路:我们的核心需求是要用尽可能少的线程来处理尽可能多的连接,这里的
多路指的就是我们需要处理的众多连接。 -
复用:核心需求要求我们使用
尽可能少的线程,尽可能少的系统开销去处理尽可能多的连接(多路),那么这里的复用指的就是用有限的资源,比如用一个线程或者固定数量的线程去处理众多连接上的读写事件。换句话说,在阻塞IO模型中一个连接就需要分配一个独立的线程去专门处理这个连接上的读写,到了IO多路复用模型中,多个连接可以复用这一个独立的线程去处理这多个连接上的读写。
好了,IO多路复用模型的概念解释清楚了,那么问题的关键是我们如何去实现这个复用,也就是如何让一个独立的线程去处理众多连接上的读写事件呢?
这个问题其实在非阻塞IO模型中已经给出了它的答案,在非阻塞IO模型中,利用非阻塞的系统IO调用去不断的轮询众多连接的Socket接收缓冲区看是否有数据到来,如果有则处理,如果没有则继续轮询下一个Socket。这样就达到了用一个线程去处理众多连接上的读写事件了。
但是非阻塞IO模型最大的问题就是需要不断的发起系统调用去轮询各个Socket中的接收缓冲区是否有数据到来,频繁的系统调用随之带来了大量的上下文切换开销。随着并发量的提升,这样也会导致非常严重的性能问题。
那么如何避免频繁的系统调用同时又可以实现我们的核心需求呢?
这就需要操作系统的内核来支持这样的操作,我们可以把频繁的轮询操作交给操作系统内核来替我们完成,这样就避免了在用户空间频繁的去使用系统调用来轮询所带来的性能开销。
正如我们所想,操作系统内核也确实为我们提供了这样的功能实现,下面我们来一起看下操作系统对IO多路复用模型的实现。
select
select是操作系统内核提供给我们使用的一个系统调用,它解决了在非阻塞IO模型中需要不断的发起系统IO调用去轮询各个连接上的Socket接收缓冲区所带来的用户空间与内核空间不断切换的系统开销。
select系统调用将轮询的操作交给了内核来帮助我们完成,从而避免了在用户空间不断的发起轮询所带来的的系统性能开销。

-
首先用户线程在发起
select系统调用的时候会阻塞在select系统调用上。此时,用户线程从用户态切换到了内核态完成了一次上下文切换 -
用户线程将需要监听的
Socket对应的文件描述符fd数组通过select系统调用传递给内核。此时,用户线程将用户空间中的文件描述符fd数组拷贝到内核空间。
这里的文件描述符数组其实是一个BitMap,BitMap下标为文件描述符fd,下标对应的值为:1表示该fd上有读写事件,0表示该fd上没有读写事件。

文件描述符fd其实就是一个整数值,在Linux中一切皆文件,Socket也是一个文件。描述进程所有信息的数据结构task_struct中有一个属性struct files_struct *files,它最终指向了一个数组,数组里存放了进程打开的所有文件列表,文件信息封装在struct file结构体中,这个数组存放的类型就是struct file结构体,数组的下标则是我们常说的文件描述符fd。
-
当用户线程调用完 select后开始进入阻塞状态,内核开始轮询遍历fd数组,查看fd对应的Socket接收缓冲区中是否有数据到来。如果有数据到来,则将fd对应BitMap的值设置为1。如果没有数据到来,则保持值为0。
注意这里内核会修改原始的
fd数组!!
-
内核遍历一遍
fd数组后,如果发现有些fd上有IO数据到来,则将修改后的fd数组返回给用户线程。此时,会将fd数组从内核空间拷贝到用户空间。 -
当内核将修改后的
fd数组返回给用户线程后,用户线程解除阻塞,由用户线程开始遍历fd数组然后找出fd数组中值为1的Socket文件描述符。最后对这些Socket发起系统调用读取数据。
select不会告诉用户线程具体哪些fd上有IO数据到来,只是在IO活跃的fd上打上标记,将打好标记的完整fd数组返回给用户线程,所以用户线程还需要遍历fd数组找出具体哪些fd上有IO数据到来。
-
由于内核在遍历的过程中已经修改了 fd数组,所以在用户线程遍历完fd数组后获取到IO就绪的Socket后,就需要重置fd数组,并重新调用select传入重置后的fd数组,让内核发起新的一轮遍历轮询。
API介绍
当我们熟悉了select的原理后,就很容易理解内核给我们提供的select API了。
int select(int maxfdp1,fd_set *readset,fd_set *writeset,fd_set *exceptset,const struct timeval *timeout)
从select API中我们可以看到,select系统调用是在规定的超时时间内,监听(轮询)用户感兴趣的文件描述符集合上的可读,可写,异常三类事件。
-
maxfdp1 :select传递给内核监听的文件描述符集合中数值最大的文件描述符+1,目的是用于限定内核遍历范围。比如:select监听的文件描述符集合为{0,1,2,3,4},那么maxfdp1的值为5。 -
fd_set *readset:对可读事件感兴趣的文件描述符集合。 -
fd_set *writeset:对可写事件感兴趣的文件描述符集合。 -
fd_set *exceptset:对异常事件感兴趣的文件描述符集合。
这里的
fd_set就是我们前边提到的文件描述符数组,是一个BitMap结构。
-
const struct timeval *timeout:select系统调用超时时间,在这段时间内,内核如果没有发现有IO就绪的文件描述符,就直接返回。
上小节提到,在内核遍历完fd数组后,发现有IO就绪的fd,则会将该fd对应的BitMap中的值设置为1,并将修改后的fd数组,返回给用户线程。
在用户线程中需要重新遍历fd数组,找出IO就绪的fd出来,然后发起真正的读写调用。
下面介绍下在用户线程中重新遍历fd数组的过程中,我们需要用到的API:
-
void FD_ZERO(fd_set *fdset):清空指定的文件描述符集合,即让fd_set中不在包含任何文件描述符。 -
void FD_SET(int fd, fd_set *fdset):将一个给定的文件描述符加入集合之中。
每次调用
select之前都要通过FD_ZERO和FD_SET重新设置文件描述符,因为文件描述符集合会在内核中被修改。
-
int FD_ISSET(int fd, fd_set *fdset):检查集合中指定的文件描述符是否可以读写。用户线程遍历文件描述符集合,调用该方法检查相应的文件描述符是否IO就绪。 -
void FD_CLR(int fd, fd_set *fdset):将一个给定的文件描述符从集合中删除
性能开销
虽然select解决了非阻塞IO模型中频繁发起系统调用的问题,但是在整个select工作过程中,我们还是看出了select有些不足的地方。
-
在发起
select系统调用以及返回时,用户线程各发生了一次用户态到内核态以及内核态到用户态的上下文切换开销。发生2次上下文切换 -
在发起
select系统调用以及返回时,用户线程在内核态需要将文件描述符集合从用户空间拷贝到内核空间。以及在内核修改完文件描述符集合后,又要将它从内核空间拷贝到用户空间。发生2次文件描述符集合的拷贝 -
虽然由原来在
用户空间发起轮询优化成了在内核空间发起轮询但select不会告诉用户线程到底是哪些Socket上发生了IO就绪事件,只是对IO就绪的Socket作了标记,用户线程依然要遍历文件描述符集合去查找具体IO就绪的Socket。时间复杂度依然为O(n)。
大部分情况下,网络连接并不总是活跃的,如果
select监听了大量的客户端连接,只有少数的连接活跃,然而使用轮询的这种方式会随着连接数的增大,效率会越来越低。
-
内核会对原始的文件描述符集合进行修改。导致每次在用户空间重新发起select调用时,都需要对文件描述符集合进行重置。 -
BitMap结构的文件描述符集合,长度为固定的1024,所以只能监听0~1023的文件描述符。 -
select系统调用 不是线程安全的。
以上select的不足所产生的性能开销都会随着并发量的增大而线性增长。
很明显select也不能解决C10K问题,只适用于1000个左右的并发连接场景。
poll
poll相当于是改进版的select,但是工作原理基本和select没有本质的区别。
int poll(struct pollfd *fds, unsigned int nfds, int timeout)
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 需要监听的事件 */
short revents; /* 实际发生的事件 由内核修改设置 */
};
select中使用的文件描述符集合是采用的固定长度为1024的BitMap结构的fd_set,而poll换成了一个pollfd结构没有固定长度的数组,这样就没有了最大描述符数量的限制(当然还会受到系统文件描述符限制)
poll只是改进了select只能监听1024个文件描述符的数量限制,但是并没有在性能方面做出改进。和select上本质并没有多大差别。
-
同样需要在
内核空间和用户空间中对文件描述符集合进行轮询,查找出IO就绪的Socket的时间复杂度依然为O(n)。 -
同样需要将
包含大量文件描述符的集合整体在用户空间和内核空间之间来回复制,无论这些文件描述符是否就绪。他们的开销都会随着文件描述符数量的增加而线性增大。 -
select,poll在每次新增,删除需要监听的socket时,都需要将整个新的socket集合全量传至内核。
poll同样不适用高并发的场景。依然无法解决C10K问题。
epoll
通过上边对select,poll核心原理的介绍,我们看到select,poll的性能瓶颈主要体现在下面三个地方:
-
因为内核不会保存我们要监听的
socket集合,所以在每次调用select,poll的时候都需要传入,传出全量的socket文件描述符集合。这导致了大量的文件描述符在用户空间和内核空间频繁的来回复制。 -
由于内核不会通知具体
IO就绪的socket,只是在这些IO就绪的socket上打好标记,所以当select系统调用返回时,在用户空间还是需要完整遍历一遍socket文件描述符集合来获取具体IO就绪的socket。 -
在
内核空间中也是通过遍历的方式来得到IO就绪的socket。
下面我们来看下epoll是如何解决这些问题的。在介绍epoll的核心原理之前,我们需要介绍下理解epoll工作过程所需要的一些核心基础知识。
Socket的创建
服务端线程调用accept系统调用后开始阻塞,当有客户端连接上来并完成TCP三次握手后,内核会创建一个对应的Socket作为服务端与客户端通信的内核接口。
在Linux内核的角度看来,一切皆是文件,Socket也不例外,当内核创建出Socket之后,会将这个Socket放到当前进程所打开的文件列表中管理起来。
下面我们来看下进程管理这些打开的文件列表相关的内核数据结构是什么样的?在了解完这些数据结构后,我们会更加清晰的理解Socket在内核中所发挥的作用。并且对后面我们理解epoll的创建过程有很大的帮助。
进程中管理文件列表结构
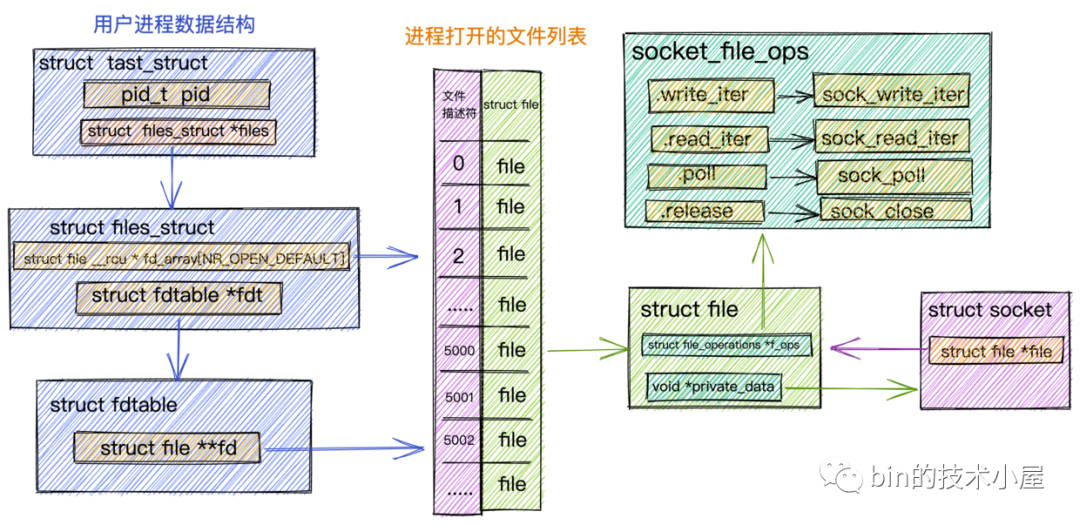
struct tast_struct是内核中用来表示进程的一个数据结构,它包含了进程的所有信息。本小节我们只列出和文件管理相关的属性。
其中进程内打开的所有文件是通过一个数组fd_array来进行组织管理,数组的下标即为我们常提到的文件描述符,数组中存放的是对应的文件数据结构struct file。每打开一个文件,内核都会创建一个struct file与之对应,并在fd_array中找到一个空闲位置分配给它,数组中对应的下标,就是我们在用户空间用到的文件描述符。
对于任何一个进程,默认情况下,文件描述符
0表示stdin 标准输入,文件描述符1表示stdout 标准输出,文件描述符2表示stderr 标准错误输出。
进程中打开的文件列表fd_array定义在内核数据结构struct files_struct中,在struct fdtable结构中有一个指针struct fd **fd指向fd_array。
由于本小节讨论的是内核网络系统部分的数据结构,所以这里拿Socket文件类型来举例说明:
用于封装文件元信息的内核数据结构struct file中的private_data指针指向具体的Socket结构。
struct file中的file_operations属性定义了文件的操作函数,不同的文件类型,对应的file_operations是不同的,针对Socket文件类型,这里的file_operations指向socket_file_ops。
我们在
用户空间对Socket发起的读写等系统调用,进入内核首先会调用的是Socket对应的struct file中指向的socket_file_ops。比如:对Socket发起write写操作,在内核中首先被调用的就是socket_file_ops中定义的sock_write_iter。Socket发起read读操作内核中对应的则是sock_read_iter。
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
Socket内核结构
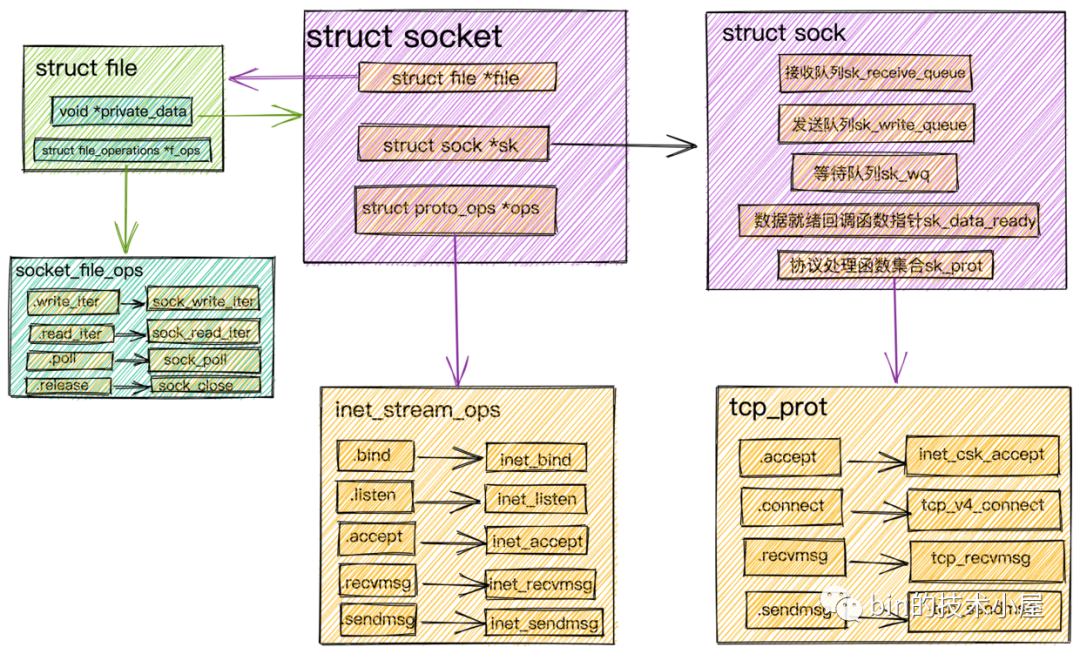
在我们进行网络程序的编写时会首先创建一个Socket,然后基于这个Socket进行bind,listen,我们先将这个Socket称作为监听Socket。
-
当我们调用 accept后,内核会基于监听Socket创建出来一个新的Socket专门用于与客户端之间的网络通信。并将监听Socket中的Socket操作函数集合(inet_stream_ops)ops赋值到新的Socket的ops属性中。
const struct proto_ops inet_stream_ops = {
.bind = inet_bind,
.connect = inet_stream_connect,
.accept = inet_accept,
.poll = tcp_poll,
.listen = inet_listen,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
......
}
这里需要注意的是,
监听的 socket和真正用来网络通信的Socket,是两个 Socket,一个叫作监听 Socket,一个叫作已连接的Socket。
-
接着内核会为 已连接的Socket创建struct file并初始化,并把Socket文件操作函数集合(socket_file_ops)赋值给struct file中的f_ops指针。然后将struct socket中的file指针指向这个新分配申请的struct file结构体。
内核会维护两个队列:
一个是已经完成 TCP三次握手,连接状态处于established的连接队列。内核中为icsk_accept_queue。一个是还没有完成 TCP三次握手,连接状态处于syn_rcvd的半连接队列。
-
然后调用 socket->ops->accept,从Socket内核结构图中我们可以看到其实调用的是inet_accept,该函数会在icsk_accept_queue中查找是否有已经建立好的连接,如果有的话,直接从icsk_accept_queue中获取已经创建好的struct sock。并将这个struct sock对象赋值给struct socket中的sock指针。
struct sock在struct socket中是一个非常核心的内核对象,正是在这里定义了我们在介绍网络包的接收发送流程中提到的接收队列,发送队列,等待队列,数据就绪回调函数指针,内核协议栈操作函数集合
-
根据创建 Socket时发起的系统调用sock_create中的protocol参数(对于TCP协议这里的参数值为SOCK_STREAM)查找到对于 tcp 定义的操作方法实现集合inet_stream_ops和tcp_prot。并把它们分别设置到socket->ops和sock->sk_prot上。
这里可以回看下本小节开头的《Socket内核结构图》捋一下他们之间的关系。
socket相关的操作接口定义在inet_stream_ops函数集合中,负责对上给用户提供接口。而socket与内核协议栈之间的操作接口定义在struct sock中的sk_prot指针上,这里指向tcp_prot协议操作函数集合。
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.backlog_rcv = tcp_v4_do_rcv,
......
}
之前提到的对
Socket发起的系统IO调用,在内核中首先会调用Socket的文件结构struct file中的file_operations文件操作集合,然后调用struct socket中的ops指向的inet_stream_opssocket操作函数,最终调用到struct sock中sk_prot指针指向的tcp_prot内核协议栈操作函数接口集合。

-
将
struct sock对象中的sk_data_ready函数指针设置为sock_def_readable,在Socket数据就绪的时候内核会回调该函数。 -
struct sock中的等待队列中存放的是系统IO调用发生阻塞的进程fd,以及相应的回调函数。记住这个地方,后边介绍epoll的时候我们还会提到!
-
当 struct file,struct socket,struct sock这些核心的内核对象创建好之后,最后就是把socket对象对应的struct file放到进程打开的文件列表fd_array中。随后系统调用accept返回socket的文件描述符fd给用户程序。
阻塞IO中用户进程阻塞以及唤醒原理
在前边小节我们介绍阻塞IO的时候提到,当用户进程发起系统IO调用时,这里我们拿read举例,用户进程会在内核态查看对应Socket接收缓冲区是否有数据到来。
-
Socket接收缓冲区有数据,则拷贝数据到用户空间,系统调用返回。 -
Socket接收缓冲区没有数据,则用户进程让出CPU进入阻塞状态,当数据到达接收缓冲区时,用户进程会被唤醒,从阻塞状态进入就绪状态,等待CPU调度。
本小节我们就来看下用户进程是如何阻塞在Socket上,又是如何在Socket上被唤醒的。理解这个过程很重要,对我们理解epoll的事件通知过程很有帮助
-
首先我们在用户进程中对 Socket进行read系统调用时,用户进程会从用户态转为内核态。 -
在进程的 struct task_struct结构找到fd_array,并根据Socket的文件描述符fd找到对应的struct file,调用struct file中的文件操作函数结合file_operations,read系统调用对应的是sock_read_iter。 -
在 sock_read_iter函数中找到struct file指向的struct socket,并调用socket->ops->recvmsg,这里我们知道调用的是inet_stream_ops集合中定义的inet_recvmsg。 -
在 inet_recvmsg中会找到struct sock,并调用sock->skprot->recvmsg,这里调用的是tcp_prot集合中定义的tcp_recvmsg函数。
整个调用过程可以参考上边的《系统IO调用结构图》
熟悉了内核函数调用栈后,我们来看下系统IO调用在tcp_recvmsg内核函数中是如何将用户进程给阻塞掉的

int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t len, int nonblock, int flags, int *addr_len)
{
.................省略非核心代码...............
//访问sock对象中定义的接收队列
skb_queue_walk(&sk->sk_receive_queue, skb) {
.................省略非核心代码...............
//没有收到足够数据,调用sk_wait_data 阻塞当前进程
sk_wait_data(sk, &timeo);
}
int sk_wait_data(struct sock *sk, long *timeo)
{
//创建struct sock中等待队列上的元素wait_queue_t
//将进程描述符和回调函数autoremove_wake_function关联到wait_queue_t中
DEFINE_WAIT(wait);
// 调用 sk_sleep 获取 sock 对象下的等待队列的头指针wait_queue_head_t
// 调用prepare_to_wait将新创建的等待项wait_queue_t插入到等待队列中,并将进程状态设置为可打断 INTERRUPTIBLE
prepare_to_wait(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE);
set_bit(SOCK_ASYNC_WAITDATA, &sk->sk_socket->flags);
// 通过调用schedule_timeout让出CPU,然后进行睡眠,导致一次上下文切换
rc = sk_wait_event(sk, timeo, !skb_queue_empty(&sk->sk_receive_queue));
...
-
首先会在 DEFINE_WAIT中创建struct sock中等待队列上的等待类型wait_queue_t。
#define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function)
#define DEFINE_WAIT_FUNC(name, function) \
wait_queue_t name = { \
.private = current, \
.func = function, \
.task_list = LIST_HEAD_INIT((name).task_list), \
}
等待类型wait_queue_t中的private用来关联阻塞在当前socket上的用户进程fd。func用来关联等待项上注册的回调函数。这里注册的是autoremove_wake_function。
-
调用
sk_sleep(sk)获取struct sock对象中的等待队列头指针wait_queue_head_t。 -
调用
prepare_to_wait将新创建的等待项wait_queue_t插入到等待队列中,并将进程设置为可打断INTERRUPTIBL。 -
调用
sk_wait_event让出CPU,进程进入睡眠状态。
用户进程的阻塞过程我们就介绍完了,关键是要理解记住struct sock中定义的等待队列上的等待类型wait_queue_t的结构。后面epoll的介绍中我们还会用到它。
下面我们接着介绍当数据就绪后,用户进程是如何被唤醒的
在本文开始介绍《网络包接收过程》这一小节中我们提到:
-
当网络数据包到达网卡时,网卡通过 DMA的方式将数据放到RingBuffer中。 -
然后向CPU发起硬中断,在硬中断响应程序中创建 sk_buffer,并将网络数据拷贝至sk_buffer中。 -
随后发起软中断,内核线程 ksoftirqd响应软中断,调用poll函数将sk_buffer送往内核协议栈做层层协议处理。 -
在传输层 tcp_rcv 函数中,去掉TCP头,根据四元组(源IP,源端口,目的IP,目的端口)查找对应的Socket。 -
最后将 sk_buffer放到Socket中的接收队列里。
上边这些过程是内核接收网络数据的完整过程,下边我们来看下,当数据包接收完毕后,用户进程是如何被唤醒的。

-
当软中断将
sk_buffer放到Socket的接收队列上时,接着就会调用数据就绪函数回调指针sk_data_ready,前边我们提到,这个函数指针在初始化的时候指向了sock_def_readable函数。 -
在
sock_def_readable函数中会去获取socket->sock->sk_wq等待队列。在wake_up_common函数中从等待队列sk_wq中找出一个等待项wait_queue_t,回调注册在该等待项上的func回调函数(wait_queue_t->func),创建等待项wait_queue_t是我们提到,这里注册的回调函数是autoremove_wake_function。
即使是有多个进程都阻塞在同一个 socket 上,也只唤醒 1 个进程。其作用是为了避免惊群。
-
在 autoremove_wake_function函数中,根据等待项wait_queue_t上的private关联的阻塞进程fd调用try_to_wake_up唤醒阻塞在该Socket上的进程。
记住
wait_queue_t中的func函数指针,在epoll中这里会注册epoll的回调函数。
现在理解epoll所需要的基础知识我们就介绍完了,唠叨了这么多,下面终于正式进入本小节的主题epoll了。
epoll_create创建epoll对象
epoll_create是内核提供给我们创建epoll对象的一个系统调用,当我们在用户进程中调用epoll_create时,内核会为我们创建一个struct eventpoll对象,并且也有相应的struct file与之关联,同样需要把这个struct eventpoll对象所关联的struct file放入进程打开的文件列表fd_array中管理。
熟悉了
Socket的创建逻辑,epoll的创建逻辑也就不难理解了。
struct eventpoll对象关联的struct file中的file_operations 指针指向的是eventpoll_fops操作函数集合。
static const struct file_operations eventpoll_fops = {
.release = ep_eventpoll_release;
.poll = ep_eventpoll_poll,
}
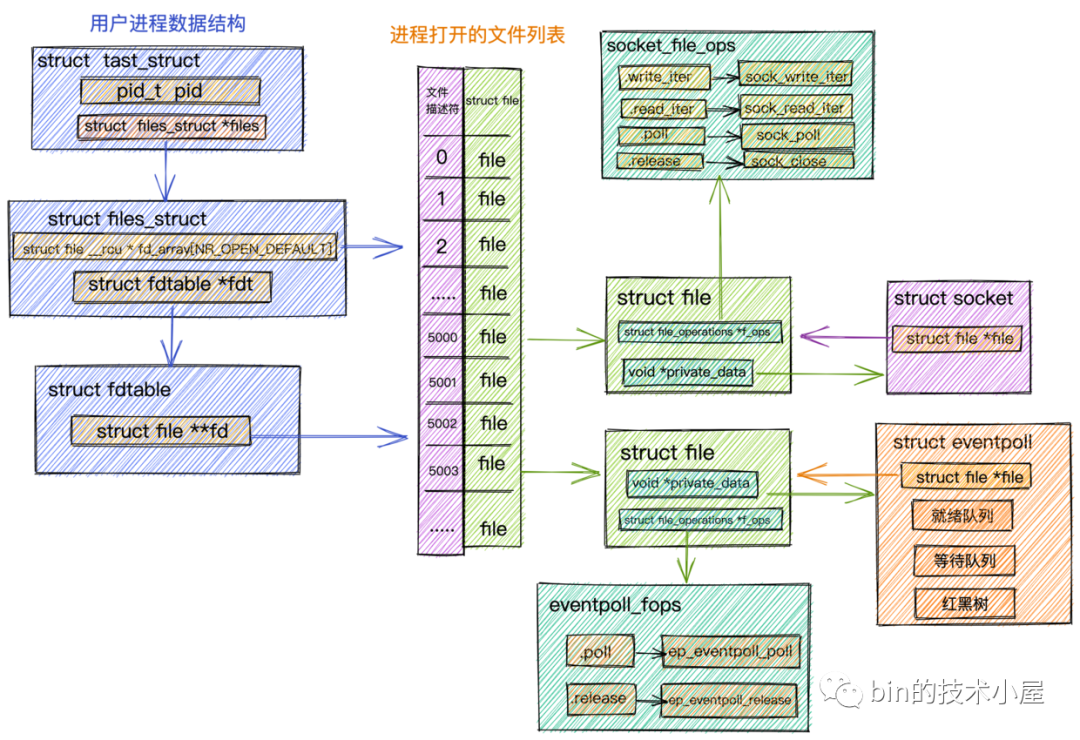
struct eventpoll {
//等待队列,阻塞在epoll上的进程会放在这里
wait_queue_head_t wq;
//就绪队列,IO就绪的socket连接会放在这里
struct list_head rdllist;
//红黑树用来管理所有监听的socket连接
struct rb_root rbr;
......
}
-
wait_queue_head_t wq:epoll中的等待队列,队列里存放的是阻塞在epoll上的用户进程。在IO就绪的时候epoll可以通过这个队列找到这些阻塞的进程并唤醒它们,从而执行IO调用读写Socket上的数据。
这里注意与
Socket中的等待队列区分!!!
-
struct list_head rdllist:epoll中的就绪队列,队列里存放的是都是IO就绪的Socket,被唤醒的用户进程可以直接读取这个队列获取IO活跃的Socket。无需再次遍历整个Socket集合。
这里正是
epoll比select ,poll高效之处,select ,poll返回的是全部的socket连接,我们需要在用户空间再次遍历找出真正IO活跃的Socket连接。而epoll只是返回IO活跃的Socket连接。用户进程可以直接进行IO操作。
-
struct rb_root rbr :由于红黑树在查找,插入,删除等综合性能方面是最优的,所以epoll内部使用一颗红黑树来管理海量的Socket连接。
select用数组管理连接,poll用链表管理连接。
epoll_ctl向epoll对象中添加监听的Socket
当我们调用epoll_create在内核中创建出epoll对象struct eventpoll后,我们就可以利用epoll_ctl向epoll中添加我们需要管理的Socket连接了。
-
首先要在epoll内核中创建一个表示 Socket连接的数据结构struct epitem,而在epoll中为了综合性能的考虑,采用一颗红黑树来管理这些海量socket连接。所以struct epitem是一个红黑树节点。

struct epitem
{
//指向所属epoll对象
struct eventpoll *ep;
//注册的感兴趣的事件,也就是用户空间的epoll_event
struct epoll_event event;
//指向epoll对象中的就绪队列
struct list_head rdllink;
//指向epoll中对应的红黑树节点
struct rb_node rbn;
//指向epitem所表示的socket->file结构以及对应的fd
struct epoll_filefd ffd;
}
这里重点记住
struct epitem结构中的rdllink以及epoll_filefd成员,后面我们会用到。
-
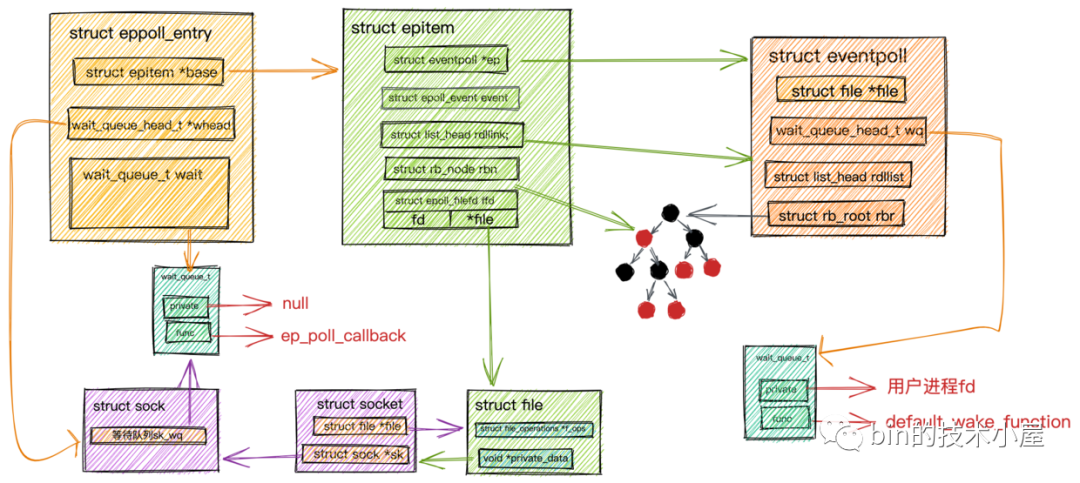
在内核中创建完表示 Socket连接的数据结构struct epitem后,我们就需要在Socket中的等待队列上创建等待项wait_queue_t并且注册epoll的回调函数ep_poll_callback。
通过《阻塞IO中用户进程阻塞以及唤醒原理》小节的铺垫,我想大家已经猜到这一步的意义所在了吧!当时在等待项wait_queue_t中注册的是autoremove_wake_function回调函数。还记得吗?
epoll的回调函数
ep_poll_callback正是epoll同步IO事件通知机制的核心所在,也是区别于select,poll采用内核轮询方式的根本性能差异所在。

这里又出现了一个新的数据结构struct eppoll_entry,那它的作用是干什么的呢?大家可以结合上图先猜测下它的作用!
我们知道socket->sock->sk_wq等待队列中的类型是wait_queue_t,我们需要在struct epitem所表示的socket的等待队列上注册epoll回调函数ep_poll_callback。
这样当数据到达socket中的接收队列时,内核会回调sk_data_ready,在阻塞IO中用户进程阻塞以及唤醒原理这一小节中,我们知道这个sk_data_ready函数指针会指向sk_def_readable函数,在sk_def_readable中会回调注册在等待队列里的等待项wait_queue_t -> func回调函数ep_poll_callback。在ep_poll_callback中需要找到epitem,将IO就绪的epitem放入epoll中的就绪队列中。
而socket等待队列中类型是wait_queue_t无法关联到epitem。所以就出现了struct eppoll_entry结构体,它的作用就是关联Socket等待队列中的等待项wait_queue_t和epitem。
struct eppoll_entry {
//指向关联的epitem
struct epitem *base;
// 关联监听socket中等待队列中的等待项 (private = null func = ep_poll_callback)
wait_queue_t wait;
// 监听socket中等待队列头指针
wait_queue_head_t *whead;
.........
};
这样在ep_poll_callback回调函数中就可以根据Socket等待队列中的等待项wait,通过container_of宏找到eppoll_entry,继而找到epitem了。
container_of在Linux内核中是一个常用的宏,用于从包含在某个结构中的指针获得结构本身的指针,通俗地讲就是通过结构体变量中某个成员的首地址进而获得整个结构体变量的首地址。
这里需要注意下这次等待项
wait_queue_t中的private设置的是null,因为这里Socket是交给epoll来管理的,阻塞在Socket上的进程是也由epoll来唤醒。在等待项wait_queue_t注册的func是ep_poll_callback而不是autoremove_wake_function,阻塞进程并不需要autoremove_wake_function来唤醒,所以这里设置private为null
-
当在 Socket的等待队列中创建好等待项wait_queue_t并且注册了epoll的回调函数ep_poll_callback,然后又通过eppoll_entry关联了epitem后。剩下要做的就是将epitem插入到epoll中的红黑树struct rb_root rbr中。
这里可以看到
epoll另一个优化的地方,epoll将所有的socket连接通过内核中的红黑树来集中管理。每次添加或者删除socket连接都是增量添加删除,而不是像select,poll那样每次调用都是全量socket连接集合传入内核。避免了频繁大量的内存拷贝。
epoll_wait同步阻塞获取IO就绪的Socket
-
用户程序调用
epoll_wait后,内核首先会查找epoll中的就绪队列eventpoll->rdllist是否有IO就绪的epitem。epitem里封装了socket的信息。如果就绪队列中有就绪的epitem,就将就绪的socket信息封装到epoll_event返回。 -
如果
eventpoll->rdllist就绪队列中没有IO就绪的epitem,则会创建等待项wait_queue_t,将用户进程的fd关联到wait_queue_t->private上,并在等待项wait_queue_t->func上注册回调函数default_wake_function。最后将等待项添加到epoll中的等待队列中。用户进程让出CPU,进入阻塞状态。

这里和
阻塞IO模型中的阻塞原理是一样的,只不过在阻塞IO模型中注册到等待项wait_queue_t->func上的是autoremove_wake_function,并将等待项添加到socket中的等待队列中。这里注册的是default_wake_function,将等待项添加到epoll中的等待队列上。
-
前边做了那么多的知识铺垫,下面终于到了 epoll的整个工作流程了:

-
当网络数据包在软中断中经过内核协议栈的处理到达
socket的接收缓冲区时,紧接着会调用socket的数据就绪回调指针sk_data_ready,回调函数为sock_def_readable。在socket的等待队列中找出等待项,其中等待项中注册的回调函数为ep_poll_callback。 -
在回调函数
ep_poll_callback中,根据struct eppoll_entry中的struct wait_queue_t wait通过container_of宏找到eppoll_entry对象并通过它的base指针找到封装socket的数据结构struct epitem,并将它加入到epoll中的就绪队列rdllist中。 -
随后查看
epoll中的等待队列中是否有等待项,也就是说查看是否有进程阻塞在epoll_wait上等待IO就绪的socket。如果没有等待项,则软中断处理完成。 -
如果有等待项,则回到注册在等待项中的回调函数
default_wake_function,在回调函数中唤醒阻塞进程,并将就绪队列rdllist中的epitem的IO就绪socket信息封装到struct epoll_event中返回。 -
用户进程拿到
epoll_event获取IO就绪的socket,发起系统IO调用读取数据。
再谈水平触发和边缘触发
网上有大量的关于这两种模式的讲解,大部分讲的比较模糊,感觉只是强行从概念上进行描述,看完让人难以理解。所以在这里,笔者想结合上边epoll的工作过程,再次对这两种模式做下自己的解读,力求清晰的解释出这两种工作模式的异同。
经过上边对epoll工作过程的详细解读,我们知道,当我们监听的socket上有数据到来时,软中断会执行epoll的回调函数ep_poll_callback,在回调函数中会将epoll中描述socket信息的数据结构epitem插入到epoll中的就绪队列rdllist中。随后用户进程从epoll的等待队列中被唤醒,epoll_wait将IO就绪的socket返回给用户进程,随即epoll_wait会清空rdllist。
水平触发和边缘触发最关键的区别就在于当socket中的接收缓冲区还有数据可读时。epoll_wait是否会清空rdllist。
-
水平触发:在这种模式下,用户线程调用
epoll_wait获取到IO就绪的socket后,对Socket进行系统IO调用读取数据,假设socket中的数据只读了一部分没有全部读完,这时再次调用epoll_wait,epoll_wait会检查这些Socket中的接收缓冲区是否还有数据可读,如果还有数据可读,就将socket重新放回rdllist。所以当socket上的IO没有被处理完时,再次调用epoll_wait依然可以获得这些socket,用户进程可以接着处理socket上的IO事件。 -
边缘触发: 在这种模式下,
epoll_wait就会直接清空rdllist,不管socket上是否还有数据可读。所以在边缘触发模式下,当你没有来得及处理socket接收缓冲区的剩下可读数据时,再次调用epoll_wait,因为这时rdlist已经被清空了,socket不会再次从epoll_wait中返回,所以用户进程就不会再次获得这个socket了,也就无法在对它进行IO处理了。除非,这个socket上有新的IO数据到达,根据epoll的工作过程,该socket会被再次放入rdllist中。
如果你在
边缘触发模式下,处理了部分socket上的数据,那么想要处理剩下部分的数据,就只能等到这个socket上再次有网络数据到达。
在Netty中实现的EpollSocketChannel默认的就是边缘触发模式。JDK的NIO默认是水平触发模式。
epoll对select,poll的优化总结
-
epoll在内核中通过红黑树管理海量的连接,所以在调用epoll_wait获取IO就绪的socket时,不需要传入监听的socket文件描述符。从而避免了海量的文件描述符集合在用户空间和内核空间中来回复制。
select,poll每次调用时都需要传递全量的文件描述符集合,导致大量频繁的拷贝操作。
-
epoll仅会通知IO就绪的socket。避免了在用户空间遍历的开销。
select,poll只会在IO就绪的socket上打好标记,依然是全量返回,所以在用户空间还需要用户程序在一次遍历全量集合找出具体IO就绪的socket。
-
epoll通过在socket的等待队列上注册回调函数ep_poll_callback通知用户程序IO就绪的socket。避免了在内核中轮询的开销。
大部分情况下
socket上并不总是IO活跃的,在面对海量连接的情况下,select,poll采用内核轮询的方式获取IO活跃的socket,无疑是性能低下的核心原因。
根据以上epoll的性能优势,它是目前为止各大主流网络框架,以及反向代理中间件使用到的网络IO模型。
利用epoll多路复用IO模型可以轻松的解决C10K问题。
C100k的解决方案也还是基于C10K的方案,通过epoll 配合线程池,再加上 CPU、内存和网络接口的性能和容量提升。大部分情况下,C100K很自然就可以达到。
甚至C1000K的解决方法,本质上还是构建在 epoll 的多路复用 I/O 模型上。只不过,除了 I/O 模型之外,还需要从应用程序到 Linux 内核、再到 CPU、内存和网络等各个层次的深度优化,特别是需要借助硬件,来卸载那些原来通过软件处理的大量功能(去掉大量的中断响应开销,以及内核协议栈处理的开销)。
信号驱动IO

大家对这个装备肯定不会陌生,当我们去一些美食城吃饭的时候,点完餐付了钱,老板会给我们一个信号器。然后我们带着这个信号器可以去找餐桌,或者干些其他的事情。当信号器亮了的时候,这时代表饭餐已经做好,我们可以去窗口取餐了。
这个典型的生活场景和我们要介绍的信号驱动IO模型就很像。
在信号驱动IO模型下,用户进程操作通过系统调用 sigaction 函数发起一个 IO 请求,在对应的socket注册一个信号回调,此时不阻塞用户进程,进程会继续工作。当内核数据就绪时,内核就为该进程生成一个 SIGIO 信号,通过信号回调通知进程进行相关 IO 操作。
这里需要注意的是:
信号驱动式 IO 模型依然是同步IO,因为它虽然可以在等待数据的时候不被阻塞,也不会频繁的轮询,但是当数据就绪,内核信号通知后,用户进程依然要自己去读取数据,在数据拷贝阶段发生阻塞。
信号驱动 IO模型 相比于前三种 IO 模型,实现了在等待数据就绪时,进程不被阻塞,主循环可以继续工作,所以
理论上性能更佳。
但是实际上,使用TCP协议通信时,信号驱动IO模型几乎不会被采用。原因如下:
-
信号IO 在大量 IO 操作时可能会因为信号队列溢出导致没法通知 -
SIGIO 信号是一种 Unix 信号,信号没有附加信息,如果一个信号源有多种产生信号的原因,信号接收者就无法确定究竟发生了什么。而 TCP socket 生产的信号事件有七种之多,这样应用程序收到 SIGIO,根本无从区分处理。
但信号驱动IO模型可以用在 UDP通信上,因为UDP 只有一个数据请求事件,这也就意味着在正常情况下 UDP 进程只要捕获 SIGIO 信号,就调用 read 系统调用读取到达的数据。如果出现异常,就返回一个异常错误。
这里插句题外话,大家觉不觉得阻塞IO模型在生活中的例子就像是我们在食堂排队打饭。你自己需要排队去打饭同时打饭师傅在配菜的过程中你需要等待。

IO多路复用模型就像是我们在饭店门口排队等待叫号。叫号器就好比select,poll,epoll可以统一管理全部顾客的吃饭就绪事件,客户好比是socket连接,谁可以去吃饭了,叫号器就通知谁。

##异步IO(AIO)
以上介绍的四种IO模型均为同步IO,它们都会阻塞在第二阶段数据拷贝阶段。
通过在前边小节《同步与异步》中的介绍,相信大家很容易就会理解异步IO模型,在异步IO模型下,IO操作在数据准备阶段和数据拷贝阶段均是由内核来完成,不会对应用程序造成任何阻塞。应用进程只需要在指定的数组中引用数据即可。
异步 IO 与信号驱动 IO 的主要区别在于:信号驱动 IO 由内核通知何时可以开始一个 IO 操作,而异步 IO由内核通知 IO 操作何时已经完成。
举个生活中的例子:异步IO模型就像我们去一个高档饭店里的包间吃饭,我们只需要坐在包间里面,点完餐(类比异步IO调用)之后,我们就什么也不需要管,该喝酒喝酒,该聊天聊天,饭餐做好后服务员(类比内核)会自己给我们送到包间(类比用户空间)来。整个过程没有任何阻塞。

异步IO的系统调用需要操作系统内核来支持,目前只有Window中的IOCP实现了非常成熟的异步IO机制。
而Linux系统对异步IO机制实现的不够成熟,且与NIO的性能相比提升也不明显。
但Linux kernel 在5.1版本由Facebook的大神Jens Axboe引入了新的异步IO库
io_uring改善了原来Linux native AIO的一些性能问题。性能相比Epoll以及之前原生的AIO提高了不少,值得关注。
再加上信号驱动IO模型不适用TCP协议,所以目前大部分采用的还是IO多路复用模型。
IO线程模型
在前边内容的介绍中,我们详述了网络数据包的接收和发送过程,并通过介绍5种IO模型了解了内核是如何读取网络数据并通知给用户线程的。
前边的内容都是以内核空间的视角来剖析网络数据的收发模型,本小节我们站在用户空间的视角来看下如果对网络数据进行收发。
相对内核来讲,用户空间的IO线程模型相对就简单一些。这些用户空间的IO线程模型都是在讨论当多线程一起配合工作时谁负责接收连接,谁负责响应IO 读写、谁负责计算、谁负责发送和接收,仅仅是用户IO线程的不同分工模式罢了。
Reactor
Reactor是利用NIO对IO线程进行不同的分工:
-
使用前边我们提到的 IO多路复用模型比如select,poll,epoll,kqueue,进行IO事件的注册和监听。 -
将监听到 就绪的IO事件分发dispatch到各个具体的处理Handler中进行相应的IO事件处理。
通过IO多路复用技术就可以不断的监听IO事件,不断的分发dispatch,就像一个反应堆一样,看起来像不断的产生IO事件,因此我们称这种模式为Reactor模型。
下面我们来看下Reactor模型的三种分类:
单Reactor单线程

Reactor模型是依赖IO多路复用技术实现监听IO事件,从而源源不断的产生IO就绪事件,在Linux系统下我们使用epoll来进行IO多路复用,我们以Linux系统为例:
-
单 Reactor意味着只有一个epoll对象,用来监听所有的事件,比如连接事件,读写事件。 -
单线程意味着只有一个线程来执行epoll_wait获取IO就绪的Socket,然后对这些就绪的Socket执行读写,以及后边的业务处理也依然是这个线程。
单Reactor单线程模型就好比我们开了一个很小很小的小饭馆,作为老板的我们需要一个人干所有的事情,包括:迎接顾客(accept事件),为顾客介绍菜单等待顾客点菜(IO请求),做菜(业务处理),上菜(IO响应),送客(断开连接)。
单Reactor多线程
随着客人的增多(并发请求),显然饭馆里的事情只有我们一个人干(单线程)肯定是忙不过来的,这时候我们就需要多招聘一些员工(多线程)来帮着一起干上述的事情。
于是就有了单Reactor多线程模型:
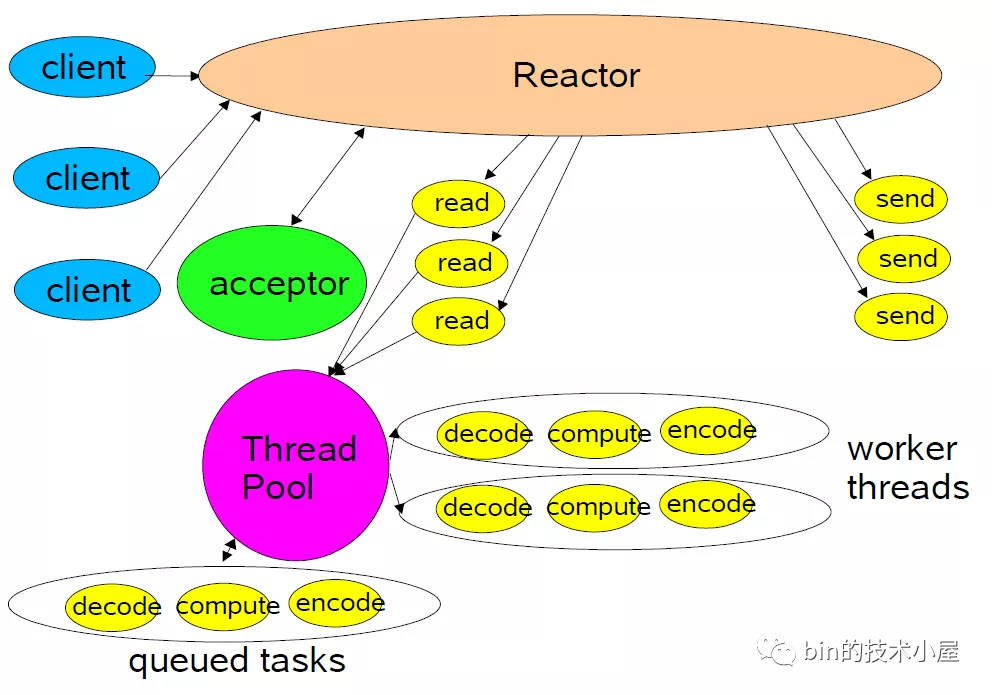
-
这种模式下,也是只有一个 epoll对象来监听所有的IO事件,一个线程来调用epoll_wait获取IO就绪的Socket。 -
但是当 IO就绪事件产生时,这些IO事件对应处理的业务Handler,我们是通过线程池来执行。这样相比单Reactor单线程模型提高了执行效率,充分发挥了多核CPU的优势。
主从Reactor多线程
做任何事情都要区分事情的优先级,我们应该优先高效的去做优先级更高的事情,而不是一股脑不分优先级的全部去做。
当我们的小饭馆客人越来越多(并发量越来越大),我们就需要扩大饭店的规模,在这个过程中我们发现,迎接客人是饭店最重要的工作,我们要先把客人迎接进来,不能让客人一看人多就走掉,只要客人进来了,哪怕菜做的慢一点也没关系。
于是,主从Reactor多线程模型就产生了:
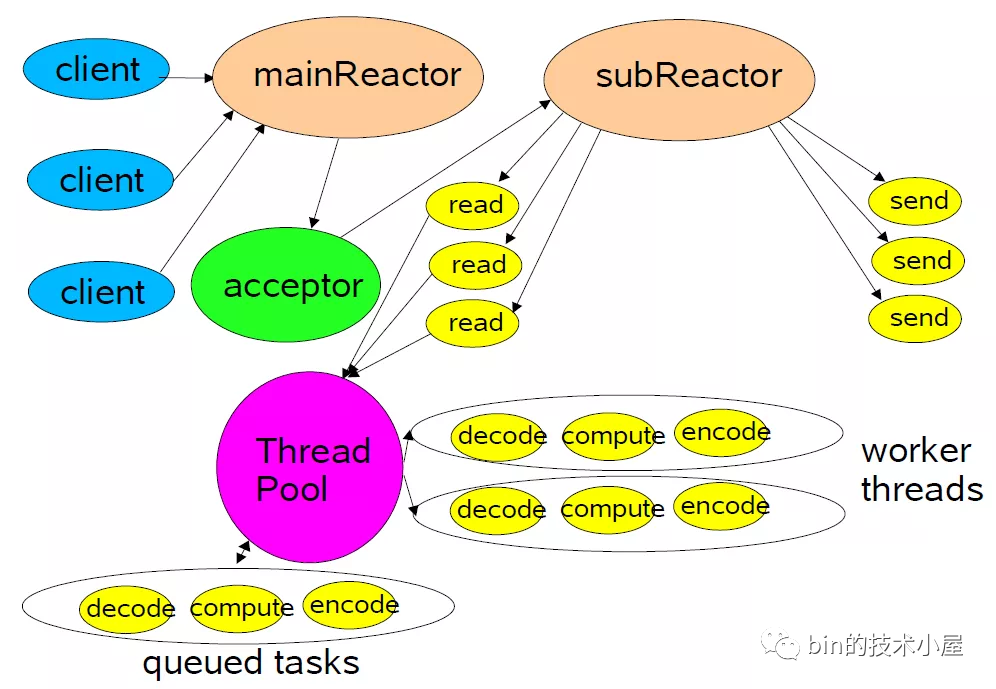
-
我们由原来的
单Reactor变为了多Reactor。主Reactor用来优先专门做优先级最高的事情,也就是迎接客人(处理连接事件),对应的处理Handler就是图中的acceptor。 -
当创建好连接,建立好对应的
socket后,在acceptor中将要监听的read事件注册到从Reactor中,由从Reactor来监听socket上的读写事件。 -
最终将读写的业务逻辑处理交给线程池处理。
注意:这里向
从Reactor注册的只是read事件,并没有注册write事件,因为read事件是由epoll内核触发的,而write事件则是由用户业务线程触发的(什么时候发送数据是由具体业务线程决定的),所以write事件理应是由用户业务线程去注册。
用户线程注册
write事件的时机是只有当用户发送的数据无法一次性全部写入buffer时,才会去注册write事件,等待buffer重新可写时,继续写入剩下的发送数据、如果用户线程可以一股脑的将发送数据全部写入buffer,那么也就无需注册write事件到从Reactor中。
主从Reactor多线程模型是现在大部分主流网络框架中采用的一种IO线程模型。我们本系列的主题Netty就是用的这种模型。
Proactor
Proactor是基于AIO对IO线程进行分工的一种模型。前边我们介绍了异步IO模型,它是操作系统内核支持的一种全异步编程模型,在数据准备阶段和数据拷贝阶段全程无阻塞。
ProactorIO线程模型将IO事件的监听,IO操作的执行,IO结果的dispatch统统交给内核来做。
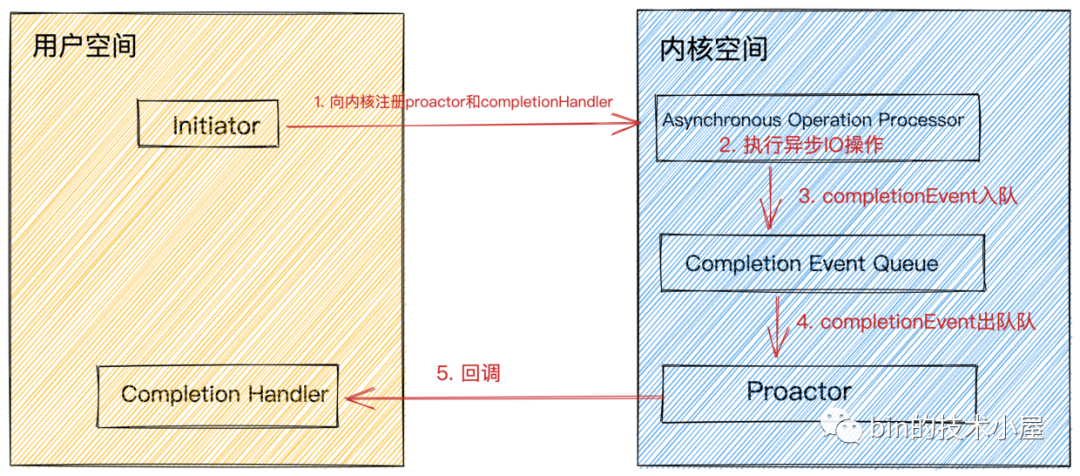
Proactor模型组件介绍:
-
completion handler为用户程序定义的异步IO操作回调函数,在异步IO操作完成时会被内核回调并通知IO结果。 -
Completion Event Queue异步IO操作完成后,会产生对应的IO完成事件,将IO完成事件放入该队列中。 -
Asynchronous Operation Processor负责异步IO的执行。执行完成后产生IO完成事件放入Completion Event Queue队列中。 -
Proactor是一个事件循环派发器,负责从Completion Event Queue中获取IO完成事件,并回调与IO完成事件关联的completion handler。 -
Initiator初始化异步操作(asynchronous operation)并通过Asynchronous Operation Processor将completion handler和proactor注册到内核。
Proactor模型执行过程:
-
用户线程发起
aio_read,并告诉内核用户空间中的读缓冲区地址,以便内核完成IO操作将结果放入用户空间的读缓冲区,用户线程直接可以读取结果(无任何阻塞)。 -
Initiator初始化aio_read异步读取操作(asynchronous operation),并将completion handler注册到内核。
在
Proactor中我们关心的IO完成事件:内核已经帮我们读好数据并放入我们指定的读缓冲区,用户线程可以直接读取。在Reactor中我们关心的是IO就绪事件:数据已经到来,但是需要用户线程自己去读取。
-
此时用户线程就可以做其他事情了,无需等待IO结果。而内核与此同时开始异步执行IO操作。当
IO操作完成时会产生一个completion event事件,将这个IO完成事件放入completion event queue中。 -
Proactor从completion event queue中取出completion event,并回调与IO完成事件关联的completion handler。 -
在
completion handler中完成业务逻辑处理。
Reactor与Proactor对比
-
Reactor是基于NIO实现的一种IO线程模型,Proactor是基于AIO实现的IO线程模型。 -
Reactor关心的是IO就绪事件,Proactor关心的是IO完成事件。 -
在
Proactor中,用户程序需要向内核传递用户空间的读缓冲区地址。Reactor则不需要。这也就导致了在Proactor中每个并发操作都要求有独立的缓存区,在内存上有一定的开销。 -
Proactor的实现逻辑复杂,编码成本较Reactor要高很多。 -
Proactor在处理高耗时 IO时的性能要高于Reactor,但对于低耗时 IO的执行效率提升并不明显。
Netty的IO模型
在我们介绍完网络数据包在内核中的收发过程以及五种IO模型和两种IO线程模型后,现在我们来看下netty中的IO模型是什么样的。
在我们介绍Reactor IO线程模型的时候提到有三种Reactor模型:单Reactor单线程,单Reactor多线程,主从Reactor多线程。
这三种Reactor模型在netty中都是支持的,但是我们常用的是主从Reactor多线程模型。
而我们之前介绍的三种Reactor只是一种模型,是一种设计思想。实际上各种网络框架在实现中并不是严格按照模型来实现的,会有一些小的不同,但大体设计思想上是一样的。
下面我们来看下netty中的主从Reactor多线程模型是什么样子的?

-
Reactor在netty中是以group的形式出现的,netty中将Reactor分为两组,一组是MainReactorGroup也就是我们在编码中常常看到的EventLoopGroup bossGroup,另一组是SubReactorGroup也就是我们在编码中常常看到的EventLoopGroup workerGroup。 -
MainReactorGroup中通常只有一个Reactor,专门负责做最重要的事情,也就是监听连接accept事件。当有连接事件产生时,在对应的处理handler acceptor中创建初始化相应的NioSocketChannel(代表一个Socket连接)。然后以负载均衡的方式在SubReactorGroup中选取一个Reactor,注册上去,监听Read事件。
MainReactorGroup中只有一个Reactor的原因是,通常我们服务端程序只会绑定监听一个端口,如果要绑定监听多个端口,就会配置多个Reactor。
-
SubReactorGroup中有多个Reactor,具体Reactor的个数可以由系统参数-D io.netty.eventLoopThreads指定。默认的Reactor的个数为CPU核数 * 2。SubReactorGroup中的Reactor主要负责监听读写事件,每一个Reactor负责监听一组socket连接。将全量的连接分摊在多个Reactor中。 -
一个
Reactor分配一个IO线程,这个IO线程负责从Reactor中获取IO就绪事件,执行IO调用获取IO数据,执行PipeLine。
Socket连接在创建后就被固定的分配给一个Reactor,所以一个Socket连接也只会被一个固定的IO线程执行,每个Socket连接分配一个独立的PipeLine实例,用来编排这个Socket连接上的IO处理逻辑。这种无锁串行化的设计的目的是为了防止多线程并发执行同一个socket连接上的IO逻辑处理,防止出现线程安全问题。同时使系统吞吐量达到最大化
由于每个
Reactor中只有一个IO线程,这个IO线程既要执行IO活跃Socket连接对应的PipeLine中的ChannelHandler,又要从Reactor中获取IO就绪事件,执行IO调用。所以PipeLine中ChannelHandler中执行的逻辑不能耗时太长,尽量将耗时的业务逻辑处理放入单独的业务线程池中处理,否则会影响其他连接的IO读写,从而近一步影响整个服务程序的IO吞吐。
-
当 IO请求在业务线程中完成相应的业务逻辑处理后,在业务线程中利用持有的ChannelHandlerContext引用将响应数据在PipeLine中反向传播,最终写回给客户端。
netty中的IO模型我们介绍完了,下面我们来简单介绍下在netty中是如何支持前边提到的三种Reactor模型的。
配置单Reactor单线程
EventLoopGroup eventGroup = new NioEventLoopGroup(1);
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(eventGroup);
配置多Reactor线程
EventLoopGroup eventGroup = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(eventGroup);
配置主从Reactor多线程
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(bossGroup, workerGroup);
总结
本文是一篇信息量比较大的文章,用了25张图,22336个字从内核如何处理网络数据包的收发过程开始展开,随后又在内核角度介绍了经常容易混淆的阻塞与非阻塞,同步与异步的概念。以这个作为铺垫,我们通过一个C10K的问题,引出了五种IO模型,随后在IO多路复用中以技术演进的形式介绍了select,poll,epoll的原理和它们综合的对比。最后我们介绍了两种IO线程模型以及netty中的Reactor模型。
感谢大家听我唠叨到这里,哈哈,现在大家可以揉揉眼,伸个懒腰,好好休息一下了。


