
带你遨游银河系的 10 种分布式数据库原创
大家好,我是悟空。
这次我们来聊下分布式场景下的数据库。首先我们还是来看下关系型和非关系型的数据库的区别和特点。
一、关系型 vs 非关系型
1.1 关系型
1.1.1 什么是关系型?
关系型数据库指的是使用关系模型(二维表格模型)来组织数据的数据库,由二维表及其之间的联系所组成的一个数据组织。
1.1.2 常见关系型数据库
常见关系型数据库管理系统(ORDBMS):Oracle、MySql、Microsoft SQL Server、SQLite、PostgreSQ、IBM DB2。
1.1.3 关系型的优势
采用二维表结构非常贴近正常开发逻辑。
支持通用的SQL(结构化查询语言)语句。
丰富的完整性大大减少了数据冗余和数据不一致的问题。
可以用SQL句子多个表之间做非常繁杂的查询;
关系型数据库提供对事务的支持。
1.1.4 关系型的不足之处
(1)存储的是行记录。
不能存储数组、嵌套字段等格式的数据。
(2)扩展表结构不方便。
操作不存在的列会报错,而增加列又需要执行 SQL 语句才行。而且修改时需要特别注意,因为更新表时会长时间锁表,这对线上环境可能造成严重影响。
(3)占用内存高。
关系型数据库在对大量数据的表进行统计之类的运算时,占用内存会很高,因为它即使只针对某一列进行运算,也会将整行数据从存储设备读入内存。
(4)全文搜索性能差
类似于 MySQL 的关系型数据库,只能用 like 进行整表扫描的匹配,效率很低。现如今,有很多场景需要支持模糊匹配,而且必须支持高效查找。比如查询包含关键字的日志信息,又或者是根据某个商品关键字查询商品列表。
1.2 非关系型
1.2.1 什么是非关系型?

NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
1.2.2 常见非关系型数据库
键值数据库:Redis、Memcached、Riak。
列式数据库:Bigtable、HBase、Cassandra。
文档数据库:MongoDB、CouchDB、MarkLogic。
图形数据库:Neo4j、InfoGrid。
1.2.3 非关系型的优势
格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
速度快:NoSQL 可以使用硬盘或者内存来存储,而关系型数据库只能使用硬盘;
高扩展性;
成本低:nosql数据库部署简单,基本都是开源软件。
1.2.4 非关系型的不足之处
不提供sql支持,学习和使用成本较高;
无事务处理。MongoDB 4.0 已支持事务。
数据结构相对复杂,复杂查询方面稍欠。
二、分布式数据库
2.1 分布式数据库的定义
分布式数据库其实没有一个官方的定义,只是我们技术人员提出的一个约定俗成的说法。
在数据库领域,当产品不断演进逐渐被大家认识和认可后,就会成了一个标准,比如说微软的 SQL Server 数据库,其他数据库都喜欢拿它作为对比,那 SQL Server 数据库就会成为一个标准。
但是分布式数据库也是最近几年才被大家提出,还是比较新的,也没有参照。不过我们可以通过这些大厂大牛们总结的经验来认识分布式数据库。
分布式数据库就是用分布式架构实现的数据库。
2.2 分布式数据库的优势
分布式一直是我研究的一个话题,现在很多流行的技术都用上了分布式架构,比如微服务、消息队列。
那为什么我们要用分布式架构呢?简单来说,就是用多机(机器)来横向扩展单机的性能,另外一个很重要的原因就是分布式的可靠性,比如多机备份、容灾等。
那数据库是不是也需要提升性能和保证可靠性呢?答案是肯定的。
哪些大厂在用分布式数据库?
每年双 11,阿里就喜欢 show 一波交易战绩,其分布式数据库 OceanBase 功不可没。头部大厂如腾讯、字节跳动、美团也开始使用分布式数据库,还有各大银行也上线了分布式数据库。
所以说分布式数据库是一种趋势,如果业务场景要求高性能和高可靠,就可以考虑使用分布式架构下的数据库了。
2.3 分布式数据库的特点
首先我们来看下数据库按照交易类型区分的两大场景:
联机交易(OLTP)
OLTP 是面向交易的处理过程,单笔交易的数据量小,但是要在很短的时间内给出结果,典型场景包括购物、缴费、转账等;
联机分析(OLAP)
OLAP 场景通常是基于大数据集的运算,典型场景包括生成个人年度账单和企业财务报表等。
OLTP 的特点是写多读少、低延时、高并发,那么数据库+分布式在 OLTP 场景下会具有哪些特点呢?
特点:
在写多读少的场景很强大。
低延时的响应。
支持高并发。
支持海量存储。
高可靠性。
三、10 种分布式数据库
3.1 PingCAP 的 TiDB
开源 + 良好的社区运营,拥有超高人气。
定义:是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
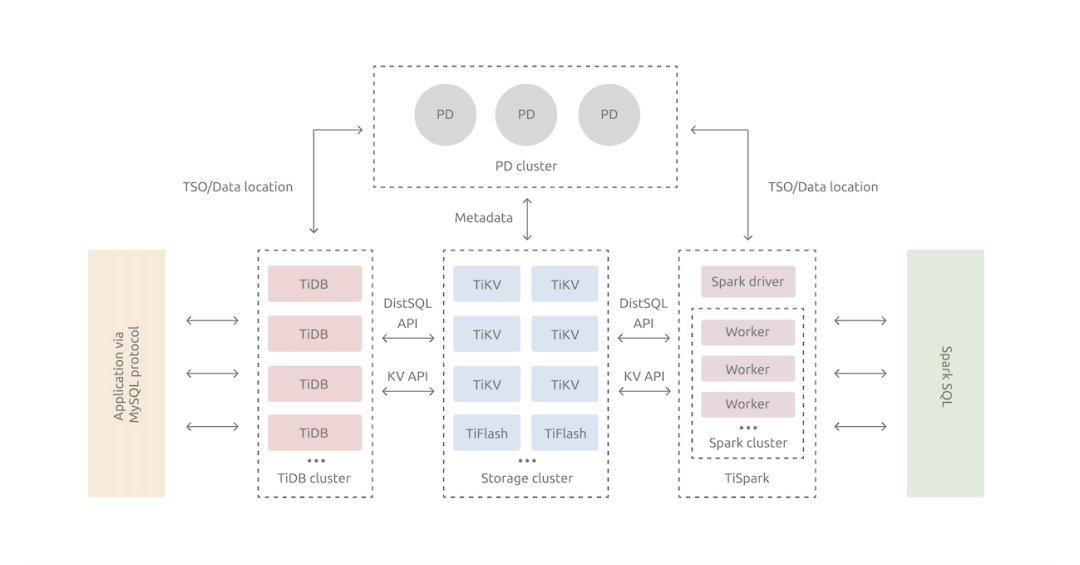
TiDB 架构图
TIDB 采用分层架构,有三种角色:
TIDB:作为 SQL 引擎。
TiKV:作为底层分布式键值存储。
PD:承担元数据管理和全局时钟的职责。
TiDB 的衍生项目:
Ti-Binlog、Ti-CDC 支持数据导出。
Ti-Operator 更方便地实现容器云部署。
Chaos Mesh 支持混沌工程。
缺点:不支持全球化部署,这为跨地域大规模集群应用 TiDB 设置了障碍。
3.2 Google 的 Spanner
Spanner是谷歌公司研发的、可扩展的、多版本、全球分布式、同步复制数据库。它支持外部一致性的分布式事务。
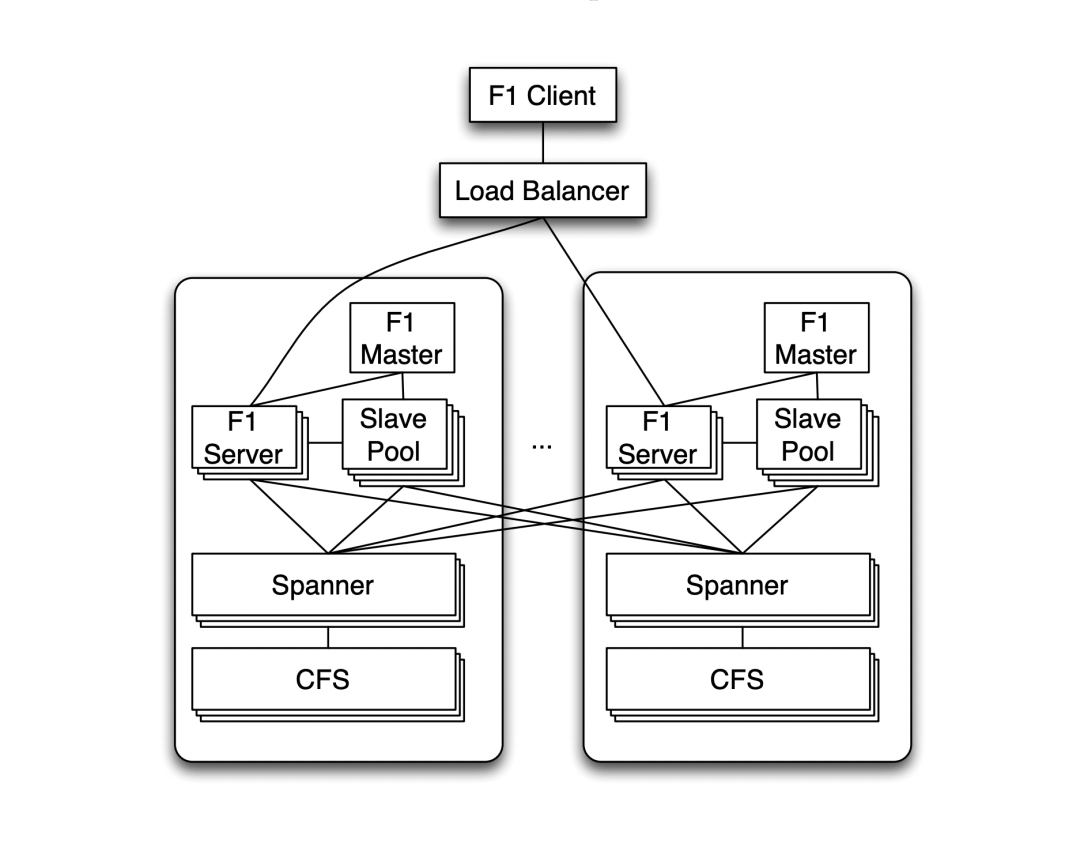
F1 主要作为 SQL 引擎
Spanner 主要负责事务一致性、复制机制、可扩展存储等。
Spanner 架构中的核心处理模块是 Spanserver,
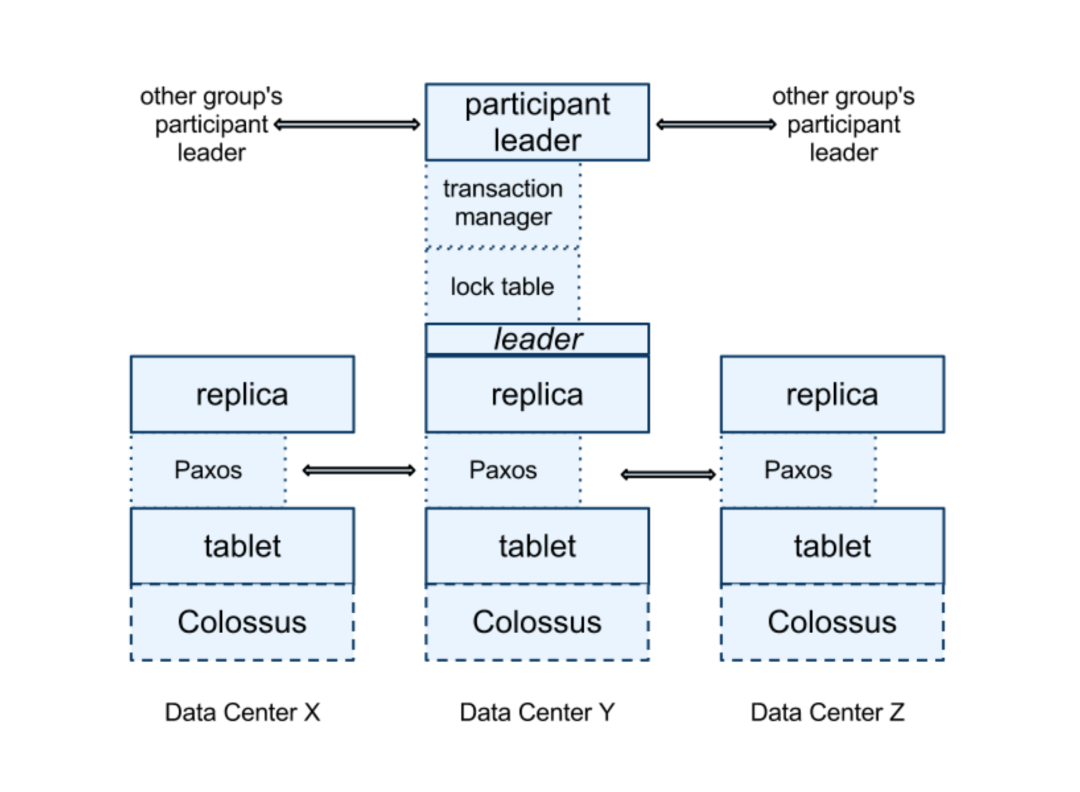
Spanner 的架构,来自 Google 论文
Spanserver 的核心工作有三部分:
基于 Paxos 协议的数据复制。Paxos 协议可以看我之前写的一篇文章:《用三国杀讲分布式算法,舒适了吧?》
基于 Tablet 的分片管理。
基于 2PC 的事务一致性管理。2PC 协议可以看我之前写的一篇文章:《用太极拳讲分布式理论,真舒服!》
2017 年,F1 和 Spanner 被拆分了,不再是绑定关系。原理如如下:
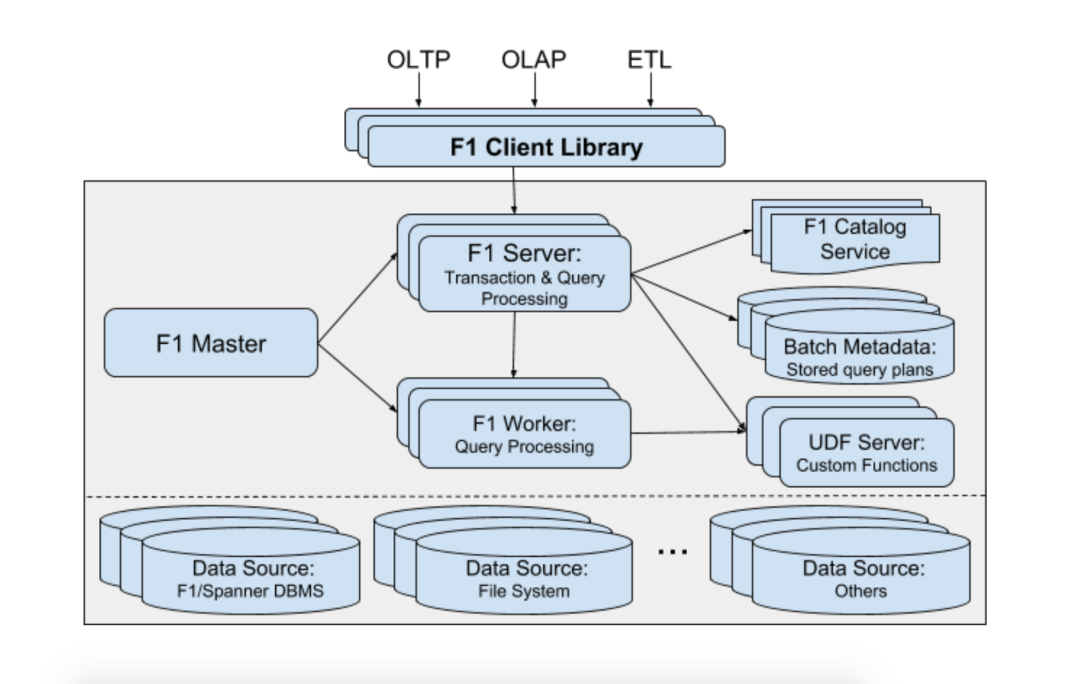
3.3 CockroachDB 蟑螂数据库
CockroachDB (蟑螂数据库)是一个可伸缩的、支持地理位置处理、支持事务处理的数据存储系统。
为什么叫做蟑螂?
因为这个数据库只要损坏的节点不超过总数一半,那么集群仍然可以正常工作,生命力超强。
通过分布式一致性算法实例来调节确保一致性,它所选择使用Raft一致性算法。所有的一致性状态存在于RocksDB中。
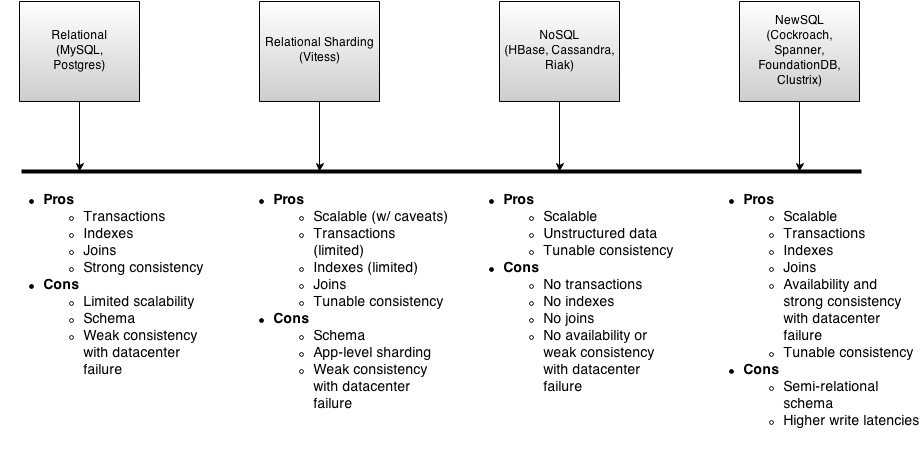
Cockroach 是一个分布式的 SQL 数据库。首要设计目标就是 可扩展性,强一致性,可存活性,就像它的名字一样。Cockroach 的目标是在无人工干预的情况下,以极小的中断时间容忍磁盘,主机,机架甚至 数据中心灾难 。Cockroach 的节点是对等的,其中一个设计目标是以最少配置加无依赖,部署去中心化的对等节点。中文社区地址:cockroachdb-cn。
CockroachDB 提供两种不同的的事务特性,包括快照隔离(snapshot isolation,简称SI)和顺序的快照隔离(SSI)语义,后者是默认的隔离级别。
CockroachDB 是一个分布式的K/V数据仓库,支持ACID事务,多版本值存储是其首要特性。主要的设计目标是全球一致性和可靠性,从蟑螂的命名上是就能看出这点。蟑螂数据库能处理磁盘、物理机器、机架甚至数据中心失效情况下最小延迟的服务中断;整个失效过程无需人工干预。蟑螂的节点是均衡的,其设计目标是同质部署(只有一个二进制包)且最小配置。
CockroachDB 和 TiDB、YugabyteDB 都公开声称设计灵感来自 Spanner,所以往往会被认为是同构的产品。CockroachDB 和 TiDB,经常会被大家拿来比较。
区别:
CockroachDB 采用了标准的 P2P 架构,只要损坏的节点不超过总数一半,那么集群仍然可以正常工作。
CockroachDB 支持全球化部署,因为它采用了混合逻辑时钟(HLC),所以能够在全球物理范围下做到数据一致性。
分片管理机制的不同。
3.4 YugabyteDB
在架构上和 CockroachDB 有很多相似之处,比如支持全球化部署,采用混合逻辑时钟(HLC),基于 Percolator 的事务模型,兼容 PostgreSQL 协议。
由于高度的相似性,YugabyteDB 与 CockroachDB 的竞争表现得非常激烈。
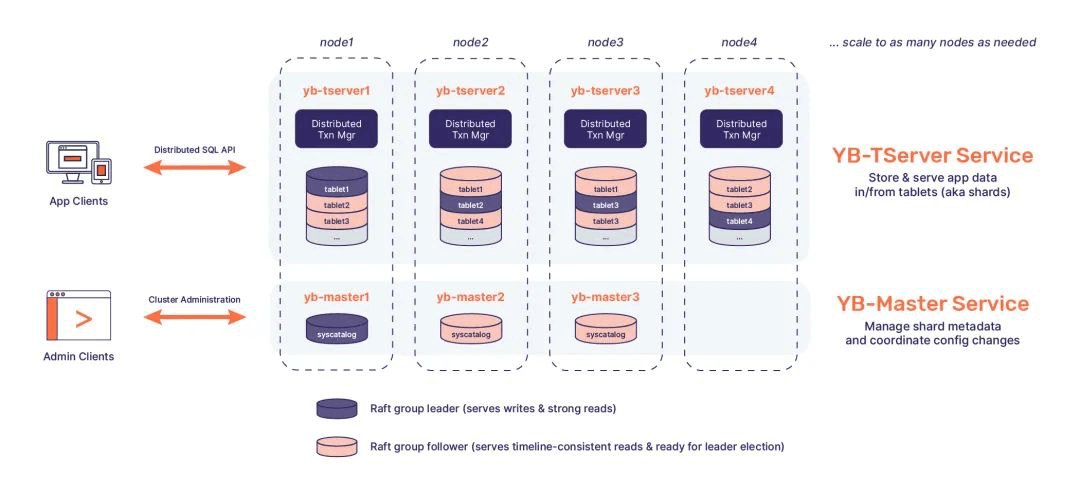
Yugabyte 采用两层架构:查询层和存储层。不过这个架构仅仅是逻辑上的,部署结构中,这两层都位于 TServer 进程中。这一点和 TiDB 不同。
Yugabyte 的查询层支持同时 SQL 和 CQL 两种 API,其中 CQL 是兼容 Cassandra 的一种方言语法,对应于文档数据库的存储模型;而 SQL API 是直接基于 PostgresQL 魔改的,能比较好地兼容 PG 语法,
Yugabyte 的存储层才是重头戏。其中 TServer 负责存储 tablet,每个 tablet 对应一个 Raft Group,分布在三个不同的节点上,以此保证高可用性。Master 负责元数据管理,除了 tablet 的位置信息,还包括表结构等信息。Master 本身也依靠 Raft 实现高可用。
3.5 阿里OceanBase
OceanBase是由蚂蚁集团完全自主研发的金融级分布式关系数据库,始创于2010年。OceanBase具有数据强一致、高可用、高性能、在线扩展、高度兼容SQL标准和主流关系数据库、低成本等特点。
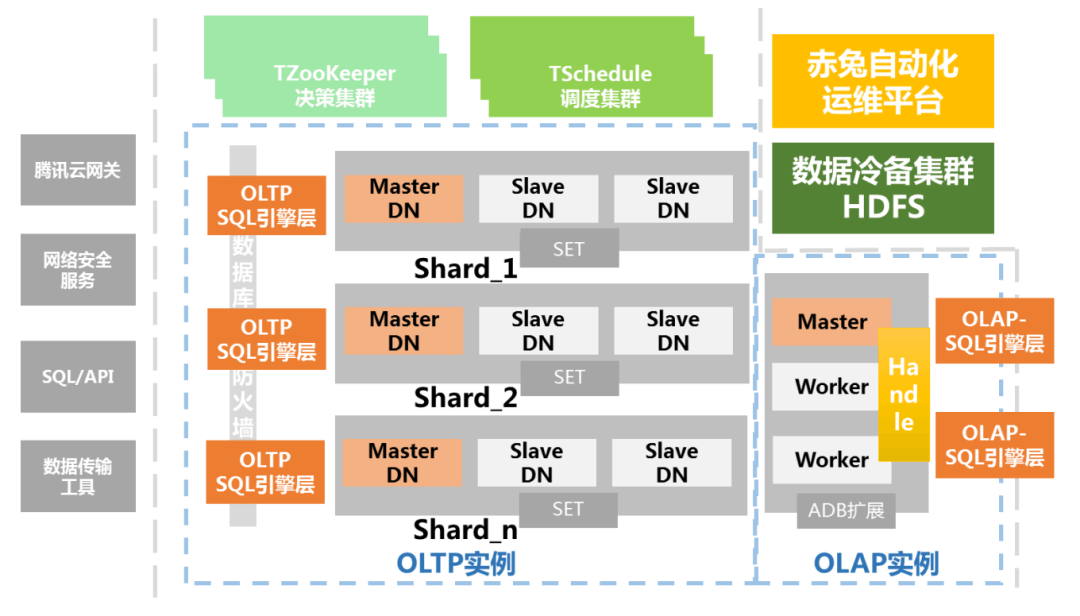
3.6 腾讯的 TDSQL
TDSQL 的节点都是用的 MySQL。它是采用分布式集群架构(如下图),这种集群架构具有较高的灵活性,简化了各个 节点之间的通信机制,也简化了对于硬件的需求。这不仅意味着 TDSQL 的关系型实例、分 布式实例、分析性实例可以混合部署在同一集群中,也意味着即使是简单的 x86 服务器,也 可以搭建出类似于小型机、共享存储等一样稳定可靠的数据库。
3.7 中兴通讯的 GoldenDB
GoldenDB 几乎是国内银行业应用规模最大的分布式数据库,和 TDSQL 同样在数据节点上选择了 MySQL,但全局时钟节点的增加使它称为一个标准的 PGXC 架构。
3.8 腾讯的 TBase
TBase 是腾讯数据平台团队在开源的 PostgreSQL 基础上研发的企业级分布式 HTAP 数据库管理系统:
- 具备高性能可扩展的分布式事务能力,支持 RC 和 RR 两种隔离级别;
- 通过安全、管理、审计三权分立体系,提供全方位的数据安全保证机制;
- 支持高性能分区表,可使得数据检索效率成倍提升;
- SQL 方面兼容 2003 标准、PostgreSQL 语法和常用 Oracle 函数&数据类型、窗口函数等;
- 提供大小商户数据分离、冷热数据分离等高效的数据治理能力
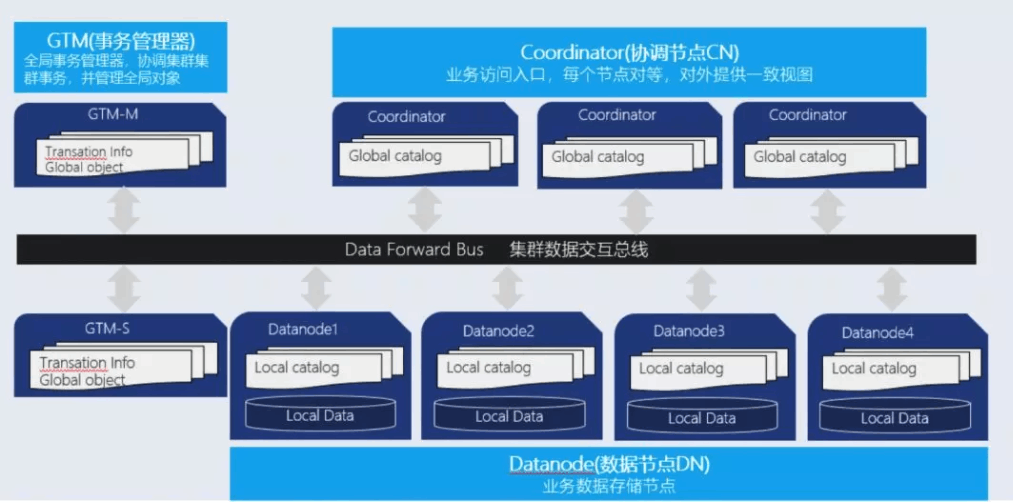
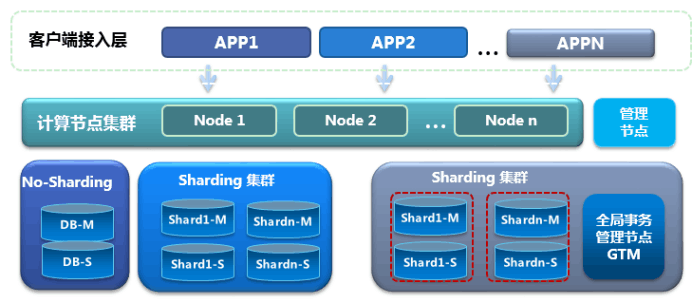
集群中有三种节点类型,各自承担不同的功能,通过网络连接成为一个系统。这三种节点类型分别是:
- **Coordinator:**协调节点,对外提供接口,负责数据的分发和查询规划,多个节点位置对等,每个节点都提供相同的数据库视图,CN 存储系统的全局元数据。
- **Datanode:**处理存储本节点相关的元数据,每个节点还存储数据的一个分片。在功能上,DN 节点负责完成执行协调节点分发的执行请求。
- GTM: 全局事务管理器(Global transaction manager.),负责管理集群事务信息,同时管理集群的全局对象,比如序列,除此之外 GTM 上不提供其他的功能。
3.9 VoltDB
VoltDB 官网提供的简介:VoltDB是全球最快的内存型数据库,它继承了传统关系数据库的强一致性要求,又提供了互联网云上部署的能力和分布式 数据库的横向扩展能力。VoltDB通过将数据库全部保存在内存中的方法,消除了大量的数据和日志的磁盘存取操作,通过单线程的方式,消除了磁盘锁和记录锁;通过数据库分片技术,让数据库支持高并发请求;通过分布式集群支持数据库横向扩展。其查询速度达到传统数据库的100倍以上。
2019 年正式闭源,变为纯商业化产品。而同时,VoltDB 在国内也没有建立完备的服务支持体系,这在很大程度上影响到它的推广。
3.10 巨杉 SequoiaDB
SequoiaDB 巨杉数据库是一款开源的金融级分布式关系型数据库,主要面对高并发联机交易型场景提供高性能、可靠稳定以及无限水平扩展的数据库服务。
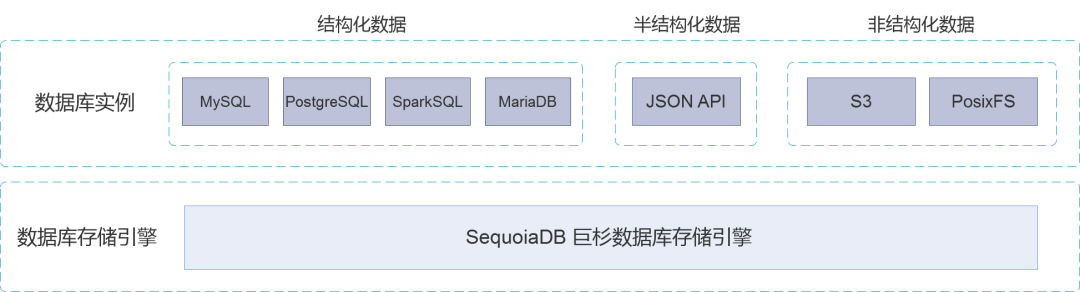
用户可以在 SequoiaDB 巨杉数据库中创建多种类型的数据库实例,以满足上层不同应用程序各自的需求。
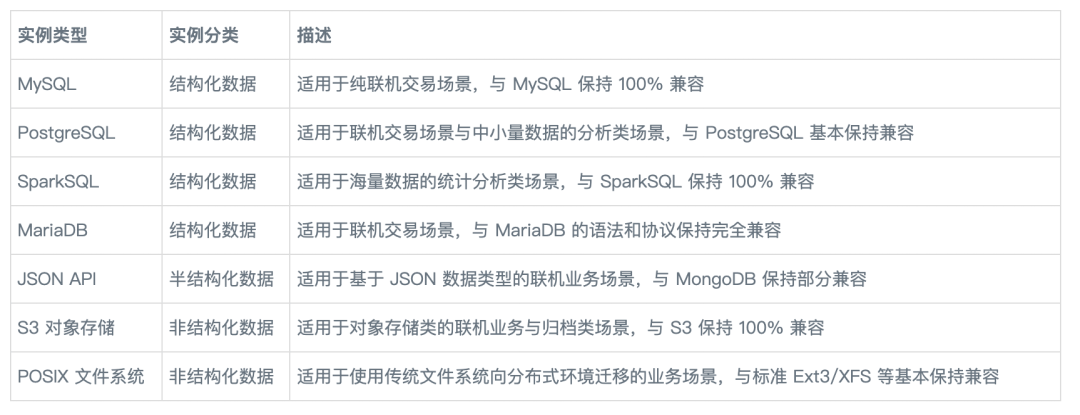
SequoiaDB 巨杉数据库支持 MySQL、PostgreSQL、SparkSQL 和 MariaDB 四种关系型数据库实例、类 MongoDB 的 JSON 文档类数据库实例、以及 S3 对象存储与 POSIX 文件系统的非结构化数据实例。
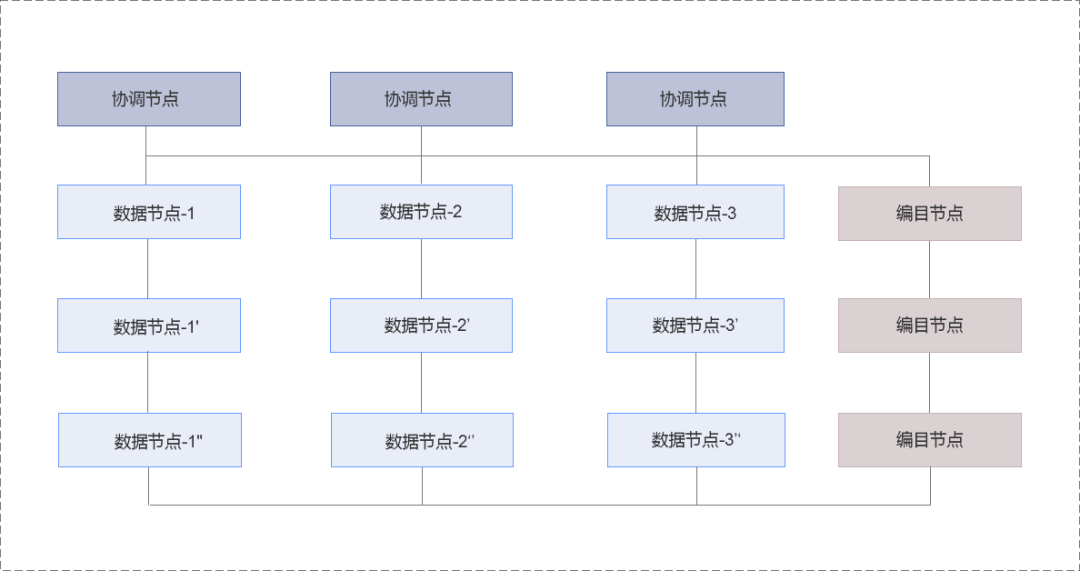
SequoiaDB 巨杉数据库存储引擎采用分布式架构。集群中的每个节点为一个独立进程,节点之间采用 TCP/IP 协议进行通讯。
同一个操作系统可以部署多个节点,节点之间采用不同的端口进行区分。
好了,对于分布式数据库,如果你也有分布式数据库的使用经验,欢迎留言~
参考资料:
https://docs.pingcap.com/zh/tidb/stable
http://vldb.org/pvldb/vol11/p1835-samwel.pdf
http://ericfu.me/yugabyte-db-introduction/
https://blog.csdn.net/duan_zhihua/article/details/88549173
https://www.voltdb.com/
https://www.zhihu.com/question/24225007/answer/1707736658
https://www.zhihu.com/question/24225007/answer/1326259742
https://time.geekbang.org/column/article/296558


