
【全网首发】关于一张 5 亿数据表之我与 DBA 的 battle原创
你好,我是yes。
事情是这样的,最近公司需要统一更改一些老表的主键类型,以前表的主键都是 int 类型,这次要改成 bigint。
然后我整理的时候发现一张表,里面竟然有 5 亿的数据,之前排查问题优化过几条慢 sql,这个表的查询竟然没进慢 sql 名单,有点突破我的认知,平日使用也没啥问题。
后面还发现了好多张 3000w 到 8000w 的表,里面字段数量也比较正常,10个左右,也在好好的用着,所以不要死板的听网上说超过 1000w、2000w 就要分表啥的。
避免提前优化,出了问题再处理才是王道,因为你提前做的一些准备,很大可能是无用功,浪费了感情和精力。
话说回 5 亿数据的这张表。
当天晚上执行修改类型语句时,由于执行时间超过了自建 sql 平台的时间阈值(平台发现一条 sql 执行超过 2 小时就会主动关闭连接)
而这个修改类型的 modify 语句又不能分开执行,只能一次性执行,所以就尬住了。
当时还有一条方案是绕开 sql 平台, 让 dba 在外面直接执行,后面由于时间太晚了,所以就等第二天再说。
到了第二天,分析了下这张表,发现其实之前的数据都是没用的,可以进行归档,也就是把 21 年的数据移到另一张表中,只留下 22 年的数据。
这张表是有时间索引的。
我查了下 21 年的数据大概有 3 亿多,删除这些数据后,估计能减少一半多 modify 的时间,而且本身这张表也是要归档的,只是今年忘了做了(说明一直没遇到查询慢的问题)。
所以方案就变成,先进行数据归档,即 insert into 21年的数据到新表中,然后 delete 这张表里面 21 年的数据,然后再 modify 更改类型。
insert into 和 delete 语句都很简单,但是由于数据量太大,避免长事务的问题,dba要求我们自行拆分 sql 语句给他执行。
当时我就寻思着:这拆分也得开发来拆?DBA 就仅仅是个无情的执行机器?
行吧,拆就拆,然后我就将 insert into 拆成了 100 条, delete 也拆成了 100 条给了 DBA。
当天晚上 DBA 又执行了一波,不过当时的 delete 有好几条失败了,他询问我,这个表当前还会有请求让其变更吗?
我说不可能,因为这张表相当于流水表,删除的是 21 年的数据,当前不可能有 21 年数据的变更,但确实是报错了,我看了下错误,锁超时。

当时我就奇怪,为什么有锁等待超时,现在不可能有业务在操作 21年的数据。
后面我才发现 DBA 是在并行执行多条 delete 语句。
于是,我在群里跟 DBA 说应该因为你并行执行多条 delete ,它们之前有竞争关系,而一条 delete 删除的数据挺多的,所以等锁等超时了。
DBA 来了句:有 id 范围限制的,delete 之间应该不会有冲突的。
我简化下,几条 delete 语句如下所示:
delete from yes where date < '2022-06-25' and (id >= 1 and id <10)
delete from yes where date < '2022-06-25' and (id >= 10 and id <20)
delete from yes where date < '2022-06-25' and (id >= 20 and id <30)
好了,背景交代完毕,看到这你可以思考一下,并行执行上面这几条 delete 语句,它们之间是否会发生竞争锁呢?
开始表演
当前事务隔离级别为:可重复读隔离级别,mysql 版本5.7+
答案是它们之间会冲突,会竞争锁。
一切拿事实说话,为了这个事实首先我们得有一张表。
CREATE TABLE `yes` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`address` varchar(45) DEFAULT NULL,
`date` date DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_date` (`date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
小数据量演示
先来看看小数据量,可以看到数据库就 5 条数据。 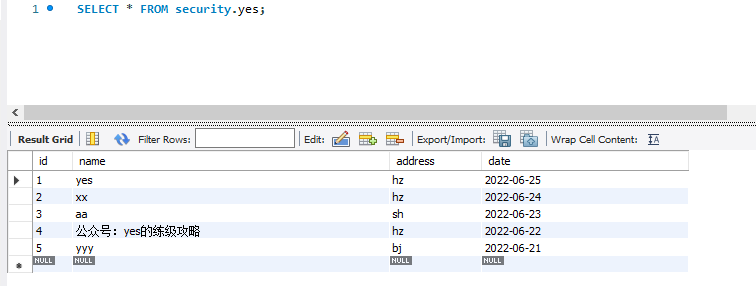 这时候我在客户端 A 执行一条 delete 语句:
这时候我在客户端 A 执行一条 delete 语句:
delete from yes where date < '2022-06-25' and (id > 1 and id <3)
不提交事务。
此时在客户端 B 执行另一条 delete语句:
delete from yes where date < '2022-06-25' and (id >= 3 and id <5)
可以看到,此时发生了阻塞: 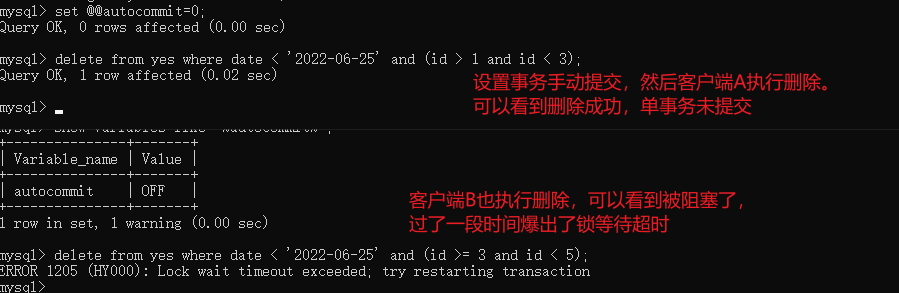 是不是有点奇怪?看起来它们之间没有冲突的呀?
是不是有点奇怪?看起来它们之间没有冲突的呀?
让我们执行下 select * from information_schema.innodb_locks;,看看锁的详情:

可以看到 lock_mode 是 X 锁,说明是排他锁,然后 lock_type 是 RECORD 说明是行锁。
lock_index 是 PRIMARY ,说明锁的是主键索引, lock_data 是 3,也就是锁的是主键 ID 为 3 的那条记录。
此时我们就知道了,确实发生了竞争,且竞争之地发生在主键索引上,用的是行锁,冲突的那行就是 ID 为 3 的那行。
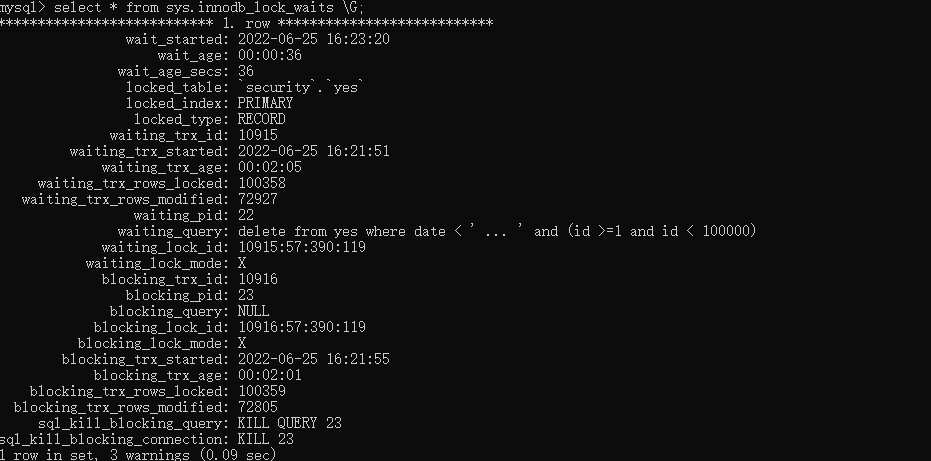
我们再来执行select * from sys.innodb_lock_waits \G;,看下对应的 lock_id 是不是我们执行的语句:
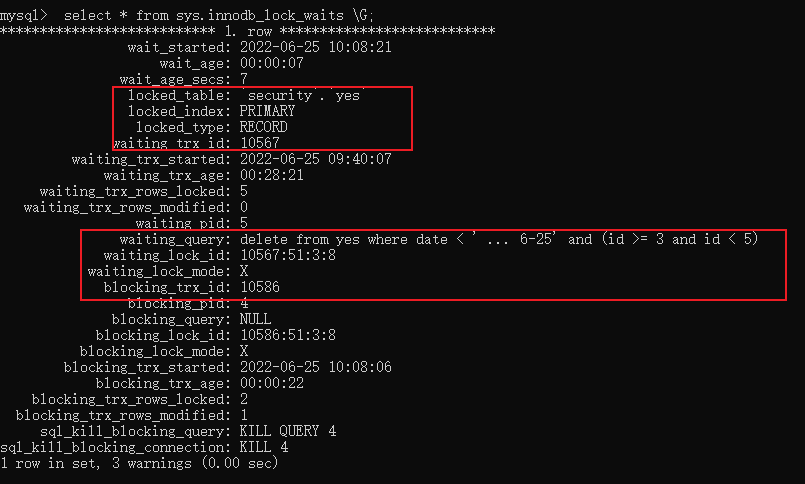 可以看到,确实是 10586 被阻塞了,对应的就是客户端 B 执行的那条语句。
可以看到,确实是 10586 被阻塞了,对应的就是客户端 B 执行的那条语句。
这个实验已经和那天晚上阻塞的情况吻合了,当然结果是结果,重要的是搞清楚为什么会这样。
让我们继续往下看。
我们来 explain 一下这个 delete 语句:  发现 delete 语句用的是主键索引,即使 date 列有索引能也能覆盖到条件字段(id),用的也是主键索引。
发现 delete 语句用的是主键索引,即使 date 列有索引能也能覆盖到条件字段(id),用的也是主键索引。
但是讲道理即使用的主键索引也不对呀,有 id < 3这个条件,为什么会锁 id=3 这行?
因为在可重复读隔离级别下,实际上范围加锁(id >1)规则是会往后遍历,直到扫描到不满足条件 即 id = 3 的那行,然后停止,因此这条语句最后扫描到的那行恰巧就是 id =3 的这一行,于是锁住了它。
此时另一条 delete 语句执行的时候是需要 id =3 这条记录的行锁(这个没啥疑问吧?),所以就竞争了,然后由于第一条语句 delete 的数据量大,所以执行的久,于是就触发了第二条的锁超时。
好了,通过小数据分析得到的结果已经和那天晚上执行的结果一致,其实到这已经可以结束了,但是为了严谨一些,现在我们拿大数据量来继续实验一次。
大数据量演示
为了更加真实,首先我多加了一些字段:

然后随机插入了 1000w 数据:
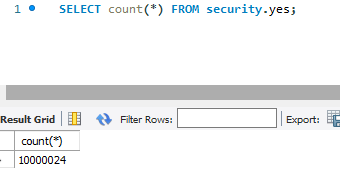
这时候我在客户端 A 执行 delete 语句:
delete from yes where date < '2022-06-25' and (id > 1 and id <100000)
不提交事务。
此时在客户端 B 执行另一条 delete 语句:
delete from yes where date < '2022-06-25' and (id >= 100000 and id <200000)
同样发生了阻塞,而且一样用的是主键,同样还是竞争的是边界值的那一行 id:100000:

好了,大数据量的也测试过了,得到一样的结论,这样就能解释为啥当天并行执行多条 delete 语句会出现锁超时的情况。
所以 DBA 的结论是错的,我们来小结一下:
小结:
在可重复读隔离级别下,带上索引键和主键通过范围搜索条件来执行 delete 语句,不论数据量大还是小,mysql 都会利用主键索引来扫描记录(我猜测反正都要删数据,即本来就要删除二级索引和聚簇索引的数据,所以索性就用主键索引扫描?)
而范围扫描加锁的数据会扫到第一个不满足条件的记录,即第一个不满足条件的记录也会被上锁,因此并行删除的时候因为边界值产生了竞争关系,又由于 delete 语句执行的时间长,导致了 lock wait timeout 的报错。
最后
好了,分析结束。
话说今天随机插入数据的时候搞了我好久...写了个存储过程来插,但是执行了半天发生一直插不进去,一直在 runing,就非常的纳闷,想着一千万数据也不需要这么久的啊。
后面奇了怪了,于是新建了一张表,分分钟就插成功了。于是又回来看之前的表,看来看去看不出个所以然,于是准备把这张表删了,发现删都删不掉,最终发现我有个小窗口执行的语句把整个表锁了....所以怎么都插不进去。
前后搞了 3 个多小时,最终执行的结果就花了 2 分钟...
难受。
话说回来,这 DBA 是真的懒,感觉他的活都不用动脑,搞啥都是 sql 平台上我们提交sql,由我们的技术负责人审核,审核过了,他在界面上点一下执行就行。
前面说的拆 SQL 这种非业务相关的也得我们拆,给他排的整整齐齐让他执行。
平时我们监控报警,什么数据库 CPU 报警了,也是报警到我们这边,由我们来看具体是什么导致的。
总之,不要过多信任 DBA,一切还是得靠自己,自己行才是真的行,包括 DBA 告诉你的一些结论,还是自己实验最为靠谱。
如果文章有什么错误,还请留言或联系我纠正之~
💥看到这里的你,如果对于我写的内容很感兴趣,有任何疑问,欢迎在下面留言📥,会第一次时间给大家解答,谢谢!
我是yes,从一点点到亿点点,我们下篇见~


