
一次C10K场景下的线上Dubbo问题排查及优化转载
导语
Dubbo 是一款轻量级的开源 Java 服务框架,是众多企业在建设分布式服务架构时的首选。中国工商银行自 2014 年开始探索分布式架构转型工作,基于开源 Dubbo 自主研发了分布式服务平台。
Dubbo 框架在提供方消费方数量较小的服务规模下,运行稳定、性能良好。随着银行业务线上化、多样化、智能化的需求越来越旺盛,在可预见的未来,会出现一个提供方为数千个、甚至上万个消费方提供服务的场景。
在如此高负载量下,若服务端程序设计不够良好,网络服务在处理数以万计的客户端连接时、可能会出现效率低下甚至完全瘫痪的情况,即为 C10K 问题。那么,基于 Dubbo 的分布式服务平台能否应对复杂的 C10K 场景?为此,我们搭建了大规模连接环境、模拟服务调用进行了一系列探索和验证。
正文
C10K 场景下 Dubbo 服务调用出现大量交易失败
1、准备环境
使用 Dubbo2.5.9(默认 netty 版本为 3.2.5.Final)版本编写服务提供方和对应的服务消费方。提供方服务方法中无实际业务逻辑、仅 sleep 100ms;消费方侧配置服务超时时间为 5s,每个消费方启动后每分钟调用1次服务。
准备 1 台 8C16G 服务器以容器化方式部署一个服务提供方,准备数百台 8C16G 服务器以容器化方式部署 7000 个服务消费方。
启动 Dubbo 监控中心,以监控服务调用情况。
2、定制验证场景,观察验证结果
验证情况不尽如人意。C10K 场景下 Dubbo 服务调用存在超时失败的情况。
如果分布式服务调用耗时长,从服务消费方到服务提供方全链路节点都会长时间占用线程池资源,增加了额外的性能损耗。而当服务调用并发突增时,很容易造成全链路节点堵塞,从而影响其他服务的调用,并进一步造成整个服务集群性能下降甚至整体不可用,导致发生雪崩。服务调用超时问题不可忽视。因此,针对该 C10K 场景下 Dubbo 服务调用超时失败情况我们进行了详细分析。
C10K场景问题分析
根据服务调用交易链路,我们首先怀疑交易超时是因为提供方或消费方自身进程卡顿或网络存在延迟导致的。
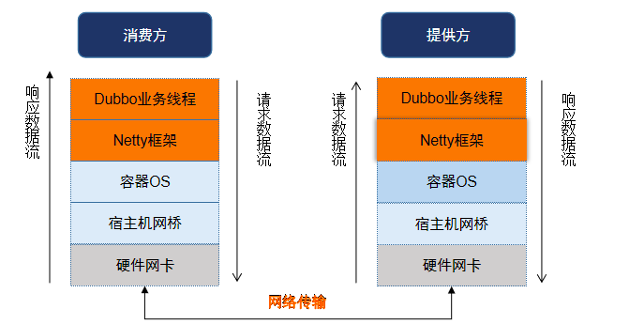
因此,我们在存在交易失败的提供方、消费方服务器上开启进程 gc 日志,多次打印进程 jstack,并在宿主机进行网络抓包。
1、观察 gc 日志、jstack
提供方、消费方进程 gc 时长、gc 间隔、内存使用情况、线程堆栈等无明显异常,暂时排除 gc 触发 stop the world 导致超时、或线程设计不当导致阻塞而超时等猜想。
2、针对以上两种场景下的失败交易,分别观察网络抓包,对应有以下两种不同的现象
针对场景 1:提供方稳定运行过程中交易超时
跟踪网络抓包及提供方、消费方交易日志。消费方发起服务调用请求发起后,在提供方端迅速抓到消费方请求报文,但提供方从收到请求报文到开始处理交易耗时 2s+。
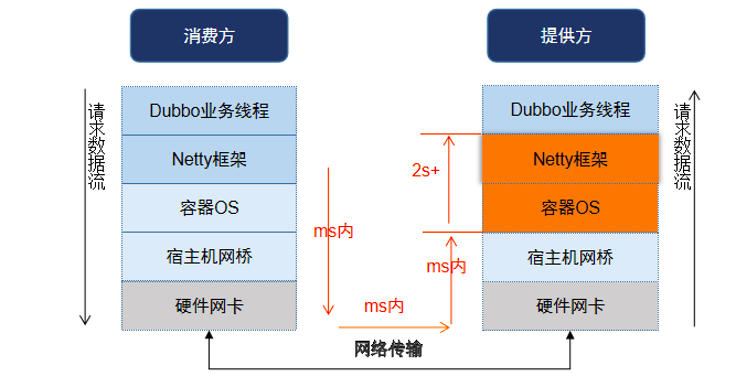
同时,观察交易请求响应的数据流。提供方业务方法处理完毕后到向消费方发送回包之间也耗时 2s+,此后消费方端迅速收到交易返回报文。但此时交易总耗时已超过 5s、超过服务调用超时时间,导致抛出超时异常。
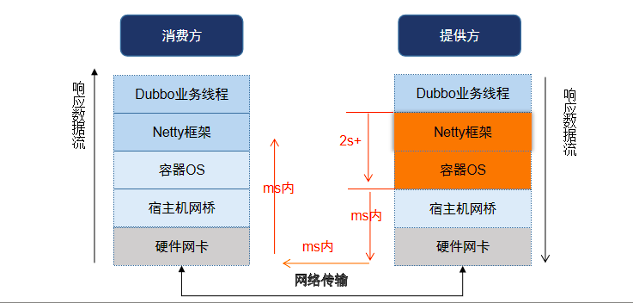
由此,判断导致交易超时的原因不在消费方侧,而在提供方侧。
针对场景 2:提供方重启后大量交易超时
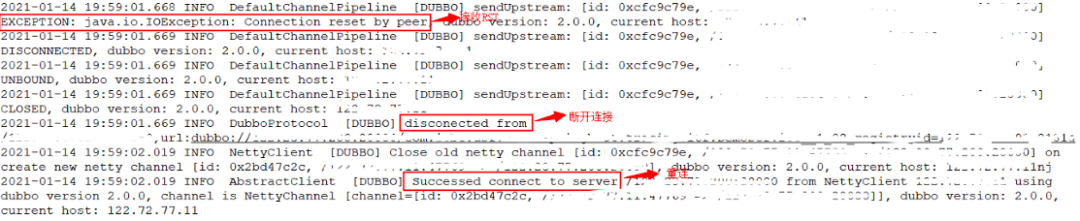
服务调用请求发起后,提供方迅速收到消费方的请求报文,但提供方未正常将交易报文递交给应用层,而是回复了 RST 报文,该笔交易超时失败。

观察在提供方重启后 1-2 分钟内出现大量的 RST 报文。通过部署脚本,在提供方重启后每隔 10ms 打印 established 状态的连接数,发现提供方重启后连接数未能迅速恢复到 7000,而是经过 1-2 分钟后连接数才恢复至正常数值。而在此过程中,逐台消费方上查询与提供方的连接状态,均为 established,怀疑提供方存在单边连接情况。
我们继续分别分析这两种异常场景。
场景 1:提供方实际交易前后均耗时长、导致交易超时
细化收集提供方的运行状态及性能指标:
1、在提供方服务器上每隔 3s 收集服务提供方 jstack,观察到 netty worker 线程每 60s 左右频繁处理心跳。
2、同时打印 top -H,观察到占用 CPU 时间片较多的线程排名前 10 中包含 9 个 netty worker 线程。因提供方服务器为 8C,Dubbo 默认 netty worker 线程数为 9 个,即所有 9 个 netty worker 线程均较忙碌。
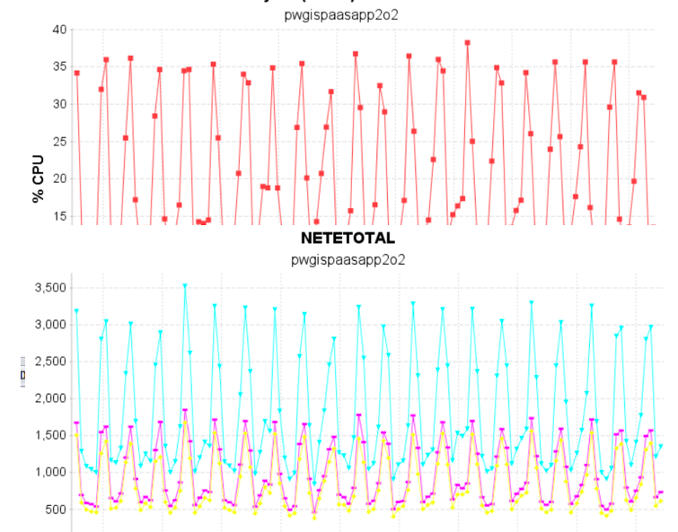
3、部署服务器系统性能采集工具 nmon,观察到 CPU 每隔 60 秒左右产生毛刺;相同时间网络报文数也有毛刺。
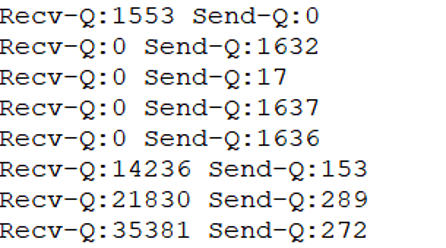
4、部署 ss -ntp 连续打印网络接收队列、发送队列中的数据积压情况。观察到在耗时长的交易时间点附近队列堆积较多。
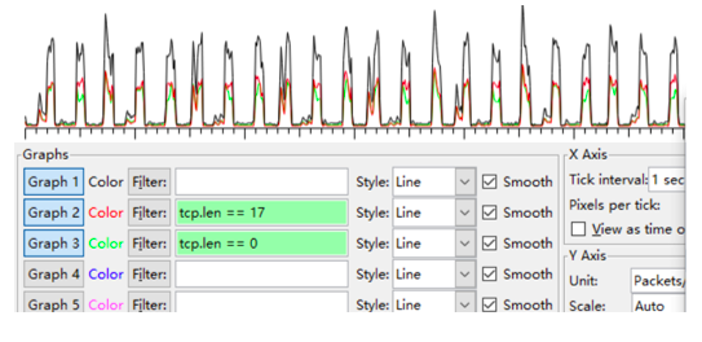
5、Dubbo 服务框架中提供方和消费方发送心跳报文(报文长度为 17)的周期为 60s,与以上间隔接近。结合网络抓包,耗时长的交易时间点附近心跳包较多。
根据 Dubbo 框架的心跳机制,当消费方数量较大时,提供方发送心跳报文、需应答的消费方心跳报文将会很密集。因此,怀疑是心跳密集导致 netty 线程忙碌,从而影响交易请求的处理,继而导致交易耗时增加。
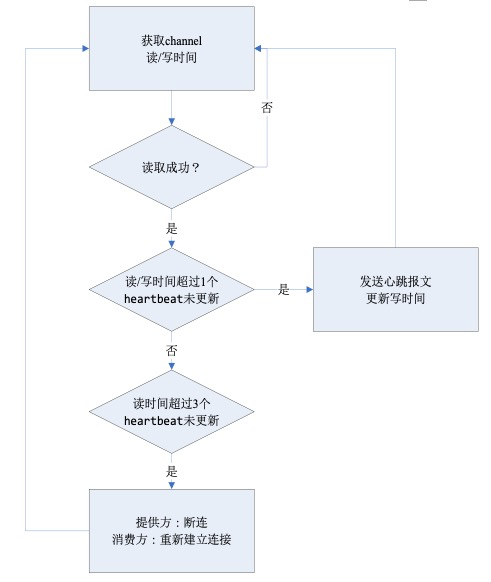
进一步分析 netty worker 线程的运行机制,记录每个 netty worker 线程在处理连接请求、处理写队列、处理 selectKeys 这三个关键环节的处理耗时。观察到每间隔 60s 左右(与心跳间隔一致)处理读取数据包较多、耗时较大,期间存在交易耗时增加的情况。同一时间观察网络抓包,提供方收到较多的心跳报文。
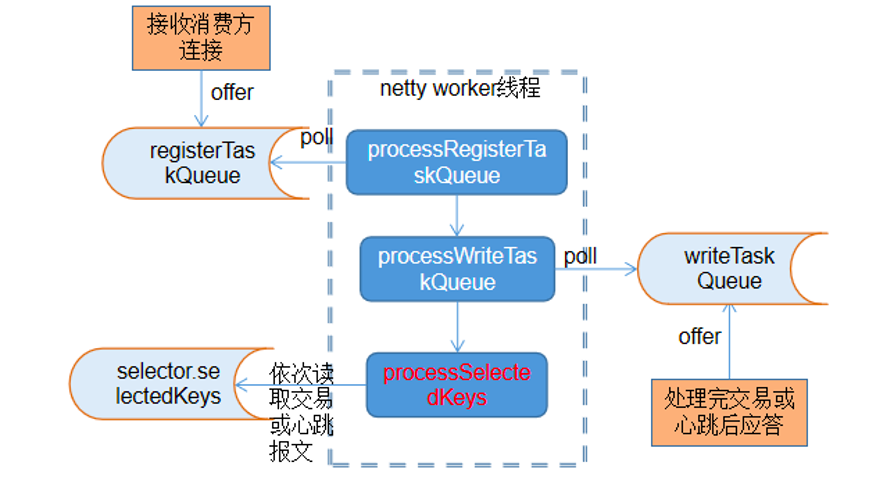
因此,确认以上怀疑。心跳密集导致 netty worker 线程忙碌,从而导致交易耗时增长。
场景 2:单边连接导致交易超时
1、分析单边连接产生的原因
TCP 建立连接三次握手的过程中,若全连接队列满,将导致单边连接。
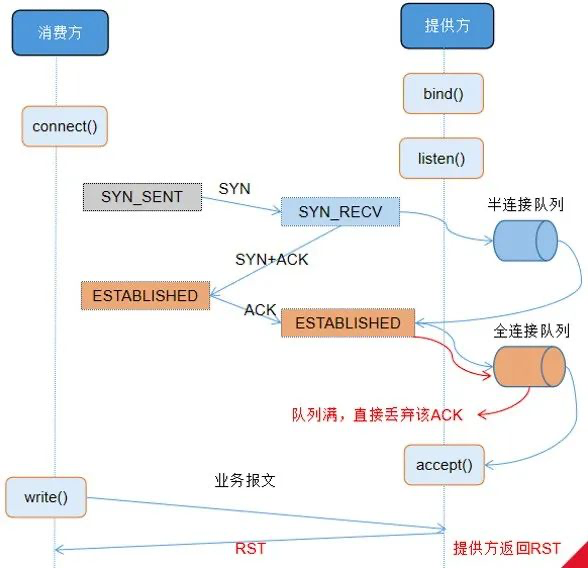
全连接队列大小由系统参数 net.core.somaxconn 及 listen(somaxconn,backlog) 的 backlog 取最小值决定。somaxconn 是 Linux 内核的参数,默认值是 128;backlog 在创建 Socket 时设置,Dubbo2.5.9 中默认 backlog 值是 50。因此,生产环境全连接队列是 50。通过 ss 命令(Socket Statistics)也查得全连接队列大小为 50。

观察 TCP 连接队列情况,证实存在全连接队列溢出的现象。

即:全连接队列容量不足导致大量单边连接产生。因在本验证场景下,订阅提供方的消费方数量过多,当提供方重启后,注册中心向消费方推送提供方上线通知,所有消费方几乎同时与提供方重建连接,导致全连接队列溢出。
2、分析单边连接影响范围
单边连接影响范围多为消费方首笔交易,偶发为首笔开始连续失败 2-3 笔。
建立为单边的连接下,交易非必然失败。三次握手全连接队列满后,若半连接队列空闲,提供方创建定时器向消费方重传 syn+ack,重传默认 5 次,重传间隔以倍数增长,1s..2s..4s.. 共 31s。在重传次数内,若全连接队列恢复空闲,消费方应答 ack、连接建立成功。此时交易成功。
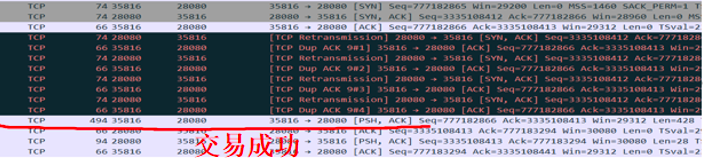
在重传次数内,若全连接队列仍然忙碌,新交易到达超时时间后失败。
到达重传次数后,连接被丢弃。此后消费方发送请求,提供方应答 RST。后交易到达超时时间失败。
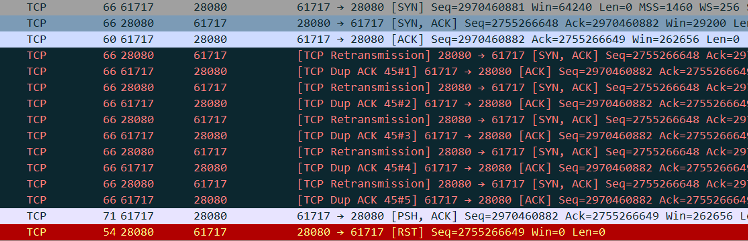
根据 Dubbo 的服务调用模型,提供方发送RST后,消费方抛出异常 Connection reset by peer,后断开与提供方的连接。而消费方无法收到当前交易的响应报文、导致超时异常。同时,消费方定时器每2s检测与提供方连接,若连接异常,发起重连,连接恢复。此后交易正常。
3、C10K 场景问题分析总结
总结以上造成交易超时的原因有两个:
1、心跳机制导致 netty worker 线程忙碌。在每个心跳任务中,提供方向所有 1 个心跳周期内未收发过报文的消费方发送心跳;消费方向所有 1 个心跳周期内未收发过报文的提供方发送心跳。提供方上所连接的消费方较多,导致心跳报文堆积;同时,处理心跳过程消耗较多 CPU,影响了业务报文的处理时效。
2、全连接队列容量不足。在提供方重启后该队列溢出,导致大量单边连接产生。单边连接下首笔交易大概率超时失败。
4、下一步思考
1、针对以上场景 1:如何能降低单个 netty worker 线程处理心跳的时间,加速 IO 线程的运行效率?初步设想了如下几种方案:
- 降低单个心跳的处理耗时
- 增加 netty worker 线程数,降低单个 IO 线程的负载
- 打散心跳,避免密集处理
2、针对以上场景 2:如何规避首笔大量半连接导致的交易失败?设想了如下方案:
- 增加 TCP 全连接队列的长度,涉及操作系统、容器、Netty
- 提高服务端 accept 连接的速度
交易报文处理效率提升
1、逐层优化
基于以上设想,我们从系统层面、Dubbo 框架层面进行了大量的优化,以提升 C10K 场景下交易处理效率,提升服务调用的性能容量。
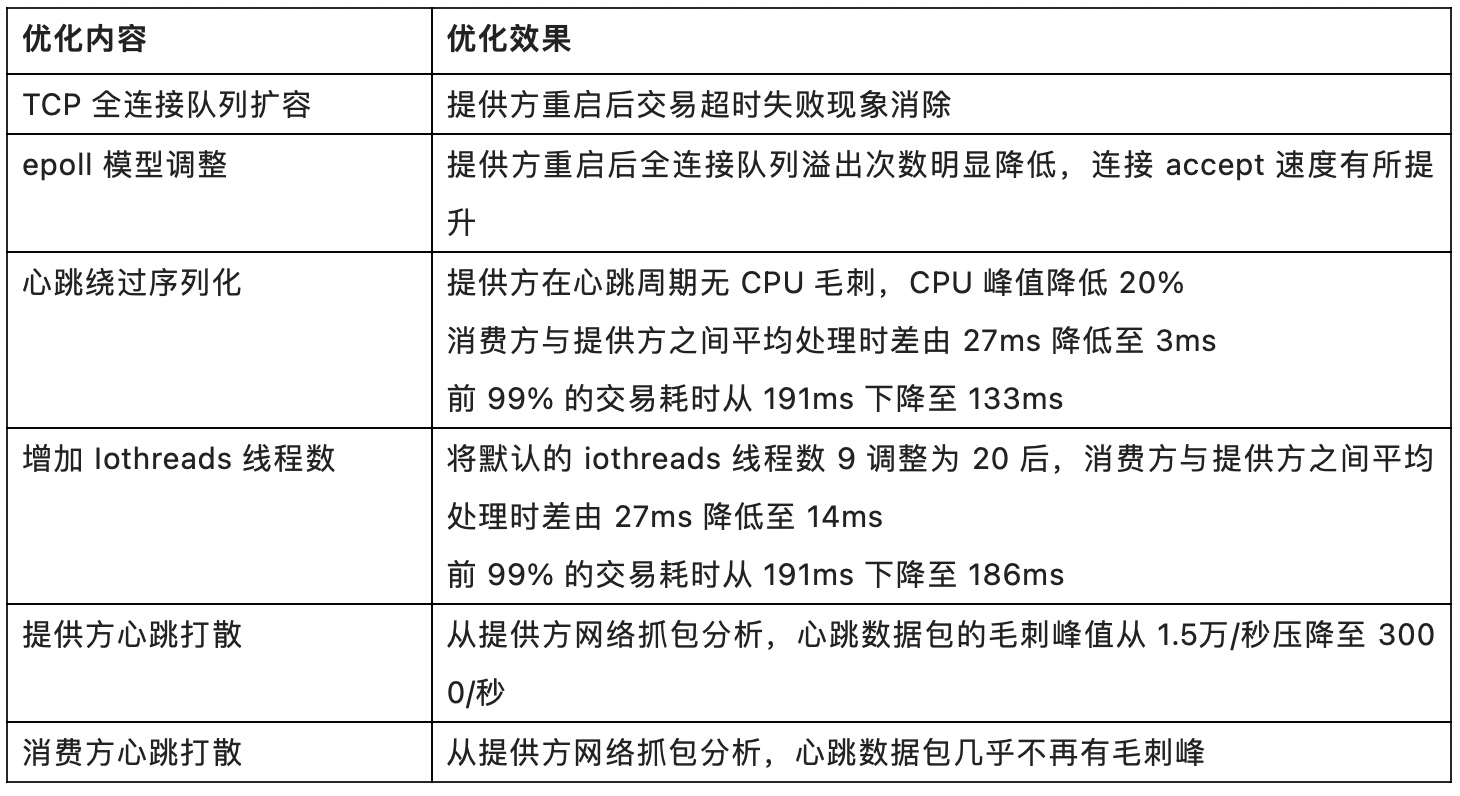
优化内容包括以下方面:
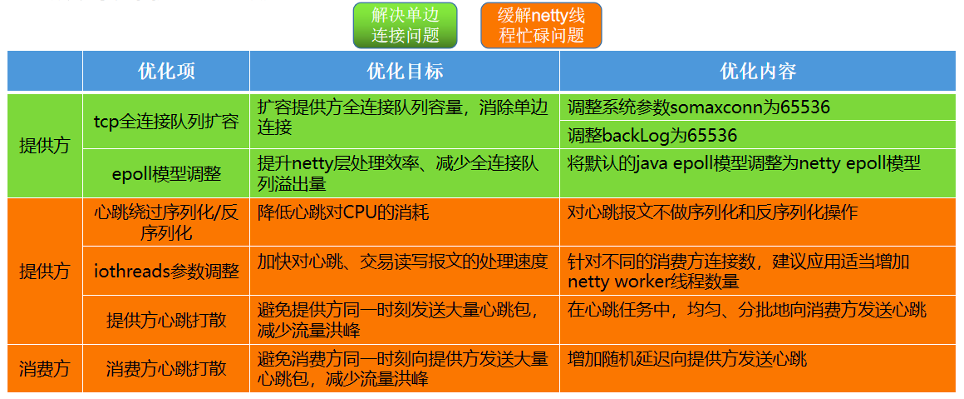
具体涉及优化的框架层如下:
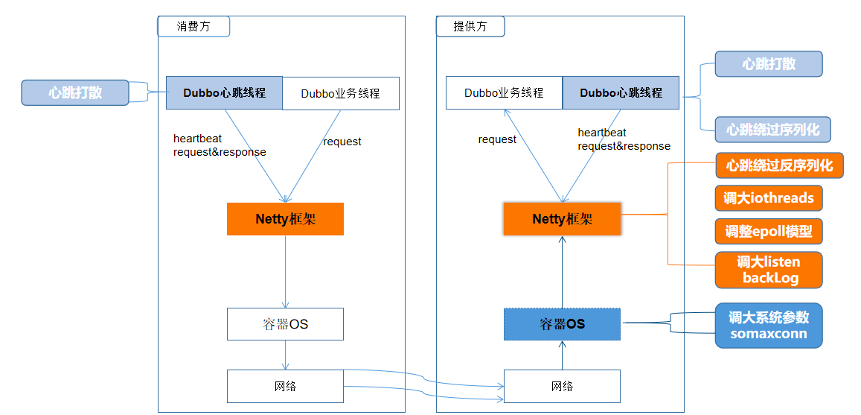
经对各优化内容逐项验证,各措施均有不同程度的提升,效果分别如下:
2、综合优化验证效果
综合运用以上优化效果最佳。在此 1 个提供方连接 7000 个消费方的验证场景下,重启提供方后、长时间运行无交易超时场景。对比优化前后,提供方 CPU 峰值下降 30%,消费方与提供方之间处理时差控制在 1ms 以内,P99 交易耗时从 191ms 下降至 125ms。在提升交易成功率的同时,有效减少了消费方等待时间、降低了服务运行资源占用、提升了系统稳定性。
3、线上实际运行效果
基于以上验证结果,中国工商银行在分布式服务平台中集成了以上优化内容。截至发文日期,线上已存在应用一个提供方上连接上万个消费方的场景。落地该优化版本后,在提供方版本升级、及长时间运行下均无异常交易超时情况,实际运行效果符合预期。


