
数据库中使用流式查询避免数据量过大导致OOM的优化转载
4年前
565212
导语
通常情况下,Mybatis将查询结果返回成一个集合 ,如果集合过大,可能出现内存溢出情况。本篇是一篇mybatis数据库优化实战,内容相对比较简单,适合初级开发者阅读!
正文
今天mybatis查询数据库中大量的数据,程序抛出:
java.lang.OutOfMemoryError: Java heap space
看下日志,是因为一次查询数据量过大导致JVM内存溢出了,虽然可以配置JVM大小,但是指标不治本,还是需要优化代码。网上查看大家都是流式查询,这里记录下解决的过程。
01、Mapper.xml配置
select语句需要增加fetchSize属性,底层是调用jdbc的setFetchSize方法,查询时从结果集里面每次取设置的行数,循环去取,直到取完。默认size是0,也就是默认会一次性把结果集的数据全部取出来,当结果集数据量很大时就容易造成内存溢出。
<select id="listTaskResultIpInfo" fetchSize="1000" resultType="String">
select info from task_result_info where project_id = #{projectId} and task_id = #{taskId}
</select>
注意:此时需要在mysql连接URL中增加useCursorFetch=true。
jdbc.url=jdbc:mysql://127.0.0.1:3306/test?useCursorFetch=true
02、自定义ResultHandler
package com.iie.test.handler.result;
import com.iie.test.entity.po.custom.CustTaskResultInfo;
import org.apache.ibatis.session.ResultContext;
import org.apache.ibatis.session.ResultHandler;
import java.util.ArrayList;
import java.util.List;
/**
* Created by bo on 2019/8/23.
* MyBatis中使用流式查询避免数据量过大导致OOM
*/
public class ResultInfoHandler implements ResultHandler<CustTaskResultInfo> {
// 存储每批数据的临时容器
private List<CustTaskResultInfo> resultInfoList = new ArrayList<>();
public List<CustTaskResultInfo> getResultInfoList() {
return resultInfoList;
}
@Override
public void handleResult(ResultContext<? extends CustTaskResultInfo> resultContext) {
CustTaskResultInfo custTaskResultInfo = resultContext.getResultObject();
resultInfoList.add(CustTaskResultInfo);
}
}
03、spring中配置sqlSessionTemplate
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation" value="classpath:mybatis/mybatis-config.xml"/>
<!-- mapper扫描 -->
<property name="mapperLocations" value="classpath:mybatis/mapper/*/*.xml"/>
</bean>
<bean id="sqlSessionTemplate" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg index="0" ref="sqlSessionFactory" />
</bean>
04、service中使用
@Autowired
private SqlSessionTemplate sqlSessionTemplate;
public List<CustTaskResultInfo> listTaskResultInfo(Long projectId, Long taskId) {
Map<String, Object> param = new HashMap<>();
param.put("projectId", projectId);
param.put("taskId", taskId);
ResultInfoHandler handler = new ResultInfoHandler();
sqlSessionTemplate.select("com.iie.cyberpecker.dao.custom.CustTaskResultInfoMapper.listTaskResultInfo", param, handler);
return handler.getResultInfoList();
}
推荐下我的 IDEA 视频,里面很多骚操作:https://www.bilibili.com/video/BV187411n7xF
05、疑问
上面这种方案必须要定义一个sqlSessionTemplate,我想着能不能直接在mapper.xml中配置,网上说的是这样实现:
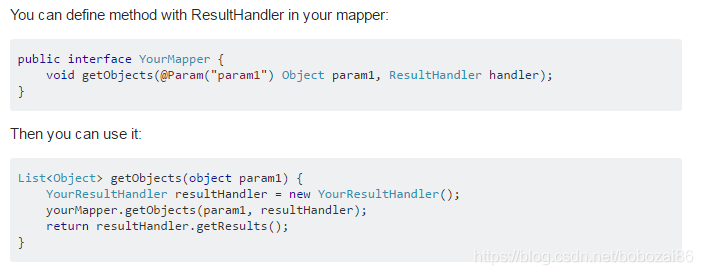
但是我这样实现一直没有成功,查询数据为空,有遇到同样问题解决的可以留言给我。
点赞收藏
分类:

