
Linux中对磁盘I/O篇性能优化实践转载
正文
一、背景知识
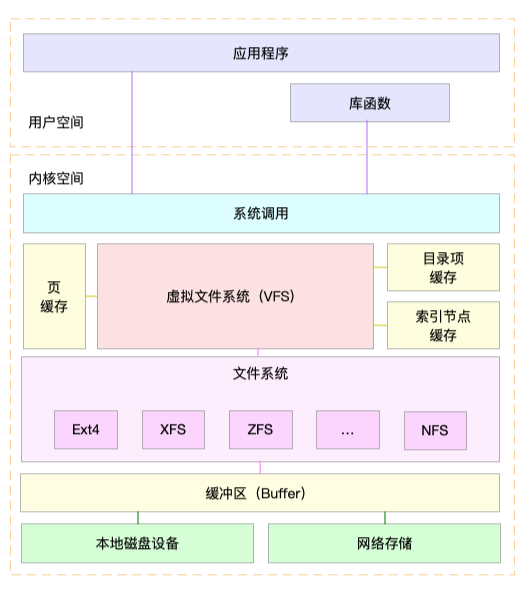
Linux系统IO栈
磁盘和文件系统的管理,也是操作系统最核心的功能。
磁盘为系统提供了最基本的持久化存储。
文件系统则在磁盘的基础上,提供了一个用来管理文件的树状结构。
以下为Linux 文件系统的架构图,可以更好地理解系统调用、VFS、缓存、文件系统以及块存储之间的关系。
一切皆文件
1)什么是I/O?
I/O就是数据在设备与内存间来回copy的过程。
Input(读取):数据从数据源头(I/O资源)流入内存;
Output(写出):数据从内存流出至数据目的地(I/O资源)。
2)I/O资源
普通文件、目录、存储设备、鼠标、键盘、打印机等设备。
可以使用一个文件路径即可操作以上任何资源。如使用/dev/input/mouse0即可引用鼠标等
3)进程文件系统procfs
系统中每一个正在运行的进程在/proc中都有一个对应的目录,组织方式为/proc/PID。
- /proc/PID/cmdline 记录启动进程时使用的命令行
- /proc/PID/cwd 记录进程所在的工作目录
- /proc/PID/fd 记录进程打开了哪些文件
- /proc/PID/maps 记录了映射到该进程地址空间的所有文件(可参考文章Linux性能优化实践-内存篇Memory Maped File部分)
- /proc/PID/status 记录进程的运行状态以及内存使用情况等。
上述内容只会保存于内存,不会保存在磁盘上。
4)设备文件系统devfs
将系统中的所有设备以文件形式呈现在/dev中
5)临时文件系统tmpfs
位于/tmp,用于存储临时性文件,/tmp下的文件不像普通文件存放于磁盘,而是常驻内存。当内存不足时,放入磁盘的swap space中。该文件系统设计目的是快速进行文件操作,系统重启后,/tmp下的文件会被全部清理掉。
通过上述例子,可以知道,操作系统可以通过文件系统管理各类资源。程序员只需要简单的读写相应文件就能实现对设备、网络通信、进程间通信等的I/O控制了。
6)打开文件open
在Linux系统中,每个进程被创建后都会自动打开三个文件:
标准输入,文件描述符为0,数据来源为键盘;
标准输出,文件描述符为1,数据输出至屏幕;
标准错误,文件描述符为2,数据输出至屏幕
因此,这三个描述符不需要显示打开。
当调用open时,操作系统会创建一些数据结构,
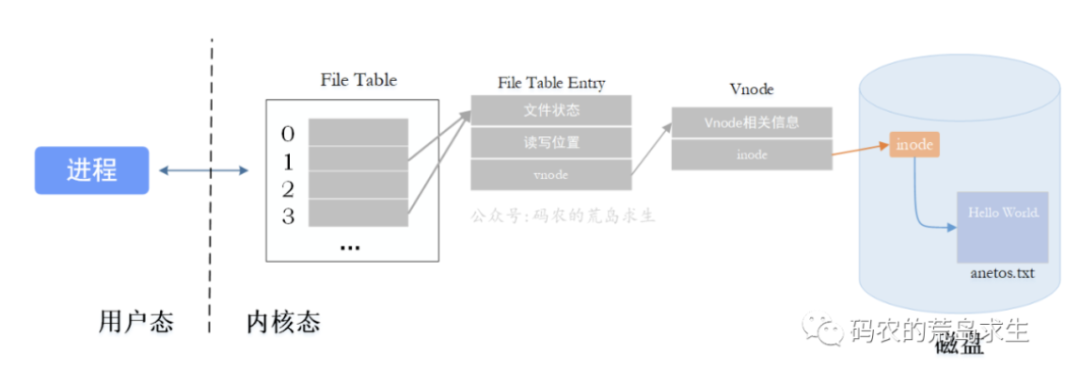
File table:进程打开的文件列表(局部,仅进程可见)
每个进程都有一个与之对应的File table。可将File table理解为一个数组,下标为文件描述符,内容是指向File table entry(文件表项)结构体的指针
File table entry:文件表项
包含文件状态、读写位置信息以及一个指向vnode结构体的指针
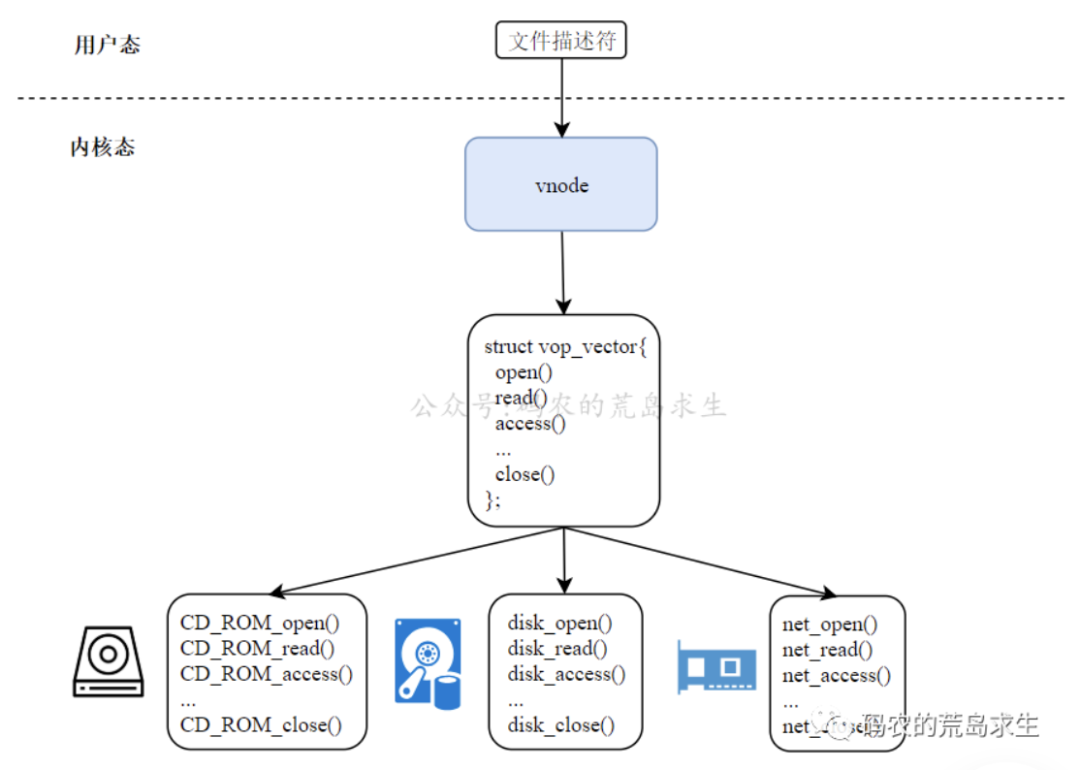
vnode:一切皆文件的关键
每个打开的文件或设备都有一个对应的vnode,记录了文件的类型及操作文件的方法,还保存了一个指向普通文件inode的指针。
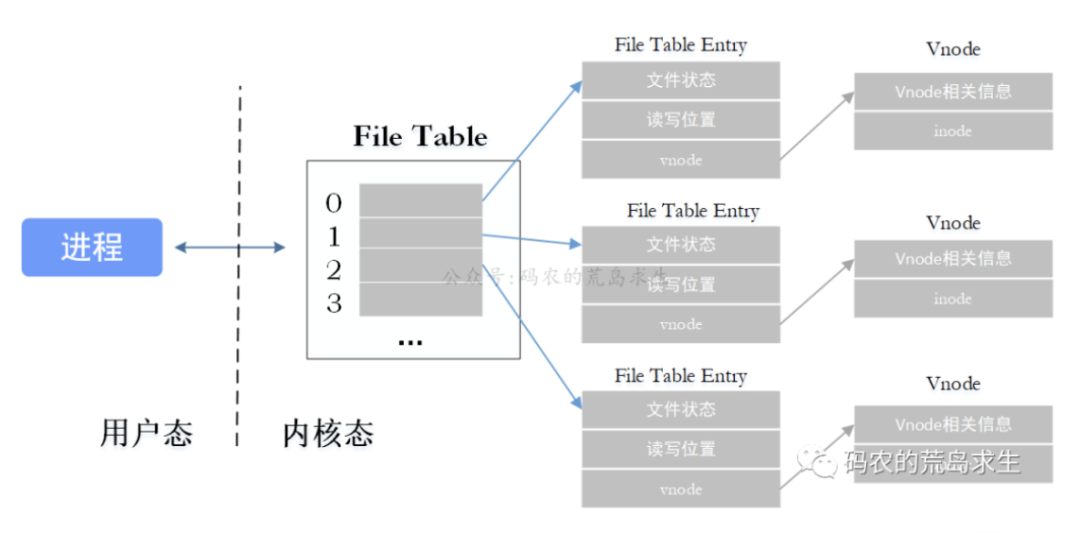
当我们开启一个程序并打开一个文件,调用open时,操作系统将在该进程File table结构中找到下一个可用的文件描述符,即为3(顺序分配),接着创建File table entry、vnode结构体,注意vnode中的inode指针将指向磁盘中具体文件的inode。
当一个应用程序刚刚启动的时候,0是标准输入,1是标准输出,2是标准错误。如果此时去打开一个新的文件,它的文件描述符会是3。POSIX标准要求每次打开文件时(含socket)必须使用当前进程中最小可用的文件描述符号
通过将vnode对外提供统一的接口vop,不同I/O设备需要基于该接口实现相应的设备操作,从而实现了一切皆文件的操作。
7)I/O重定向
I/O指的是字节从内存的流入流出,I/O重定向指的是这些字节流的流向发生改变。系统调用函数
int dup2(int oldfd, int newfd);
将oldfd对应的File table entry拷贝至newfd对应的File table entry中。这些newfd的字节流实际指向oldfd文件中。
例如我们运行程序打开一个文件,那么返回的fd将是3,再调用
dup2(3, 1);
那么标准输出和新打开的文件File table均指向统一的File table entry。我们调用printf输出的数据将重定向至新打开的文件。
8)文件描述符
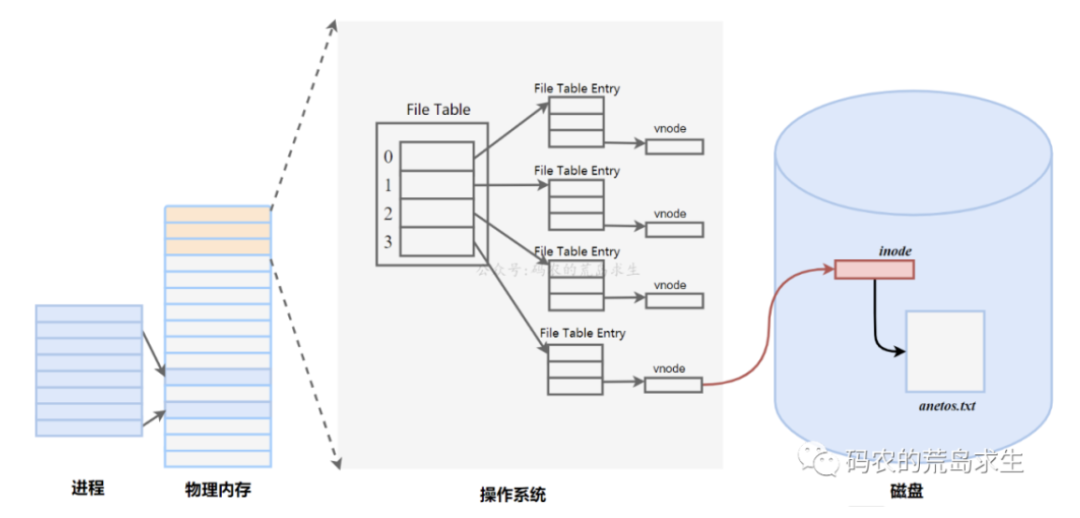
操作系统为每一个进程维护了一个文件描述符表,该表的索引值都从从0开始的,所以在不同的进程中可以看到相同的文件描述符,这种情况下相同的文件描述符可能指向同一个文件,也可能指向不同的文件,具体情况需要具体分析,下面用一张简图就可以很容易的明白了。
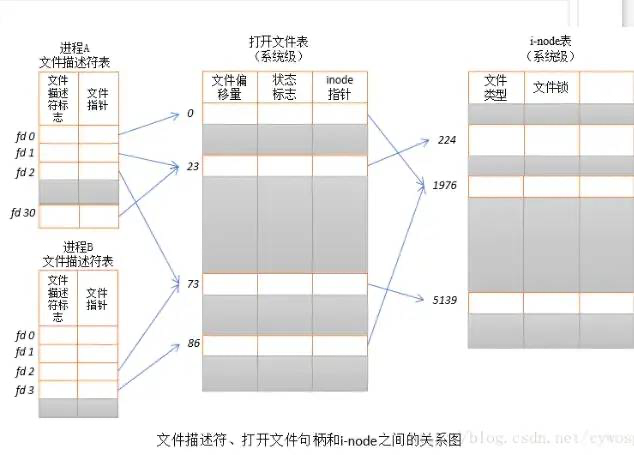
进程 + 文件描述符ID确认唯一性,因为内核为每个进程都有一份其所属的文件描述符表。应用程序进程拿到的文件描述符ID(进程文件描述符表的索引),通过索引拿到文件指针,指向系统级文件描述符表的文件偏移量,再通过文件偏移量找到inode指针,最终对应到真实的文件。
文件描述符是一个重要的系统资源,理论上系统内存多大就应该可以打开多少个文件描述符,但是实际情况是,内核会有系统级限制,以及用户级限制(不让某一个应用程序进程消耗掉所有的文件资源,可以使用ulimit -n 查看系统能打开的最大文件数)。
查看进程打开的文件描述符-lsof
lsof -p $pid
# pid必须为进程号,线程号将没有任何输出

第四列为对应的fd及文件打开方式(w为写打开,u为读写方式,r为读打开)。
通过查看procfs文件系统相关目录也可查看
VFS
为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
在 VFS 的下方,Linux 支持各种各样的文件系统,如 Ext4、XFS、NFS 等等。按照存储位置的不同,这些文件系统可以分为三类。
第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS 等,都是这类文件系统。
第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是一种最常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象。
第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿第一类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc 文件系统、/sys 文件系统、NFS 等)挂载进来。
VFS 内部通过目录项、索引节点、逻辑块以及超级块等数据结构,来管理文件。
目录项,记录了文件的名字,以及文件与其他目录项之间的目录关系。
索引节点,记录了文件的元数据。
逻辑块,是由连续磁盘扇区构成的最小读写单元,用来存储文件数据。
超级块,用来记录文件系统整体的状态,如索引节点和逻辑块的使用情况等。
其中,目录项是一个内存缓存;而超级块、索引节点和逻辑块,都是存储在磁盘中的持久化数据。
各项缓存查看方法:
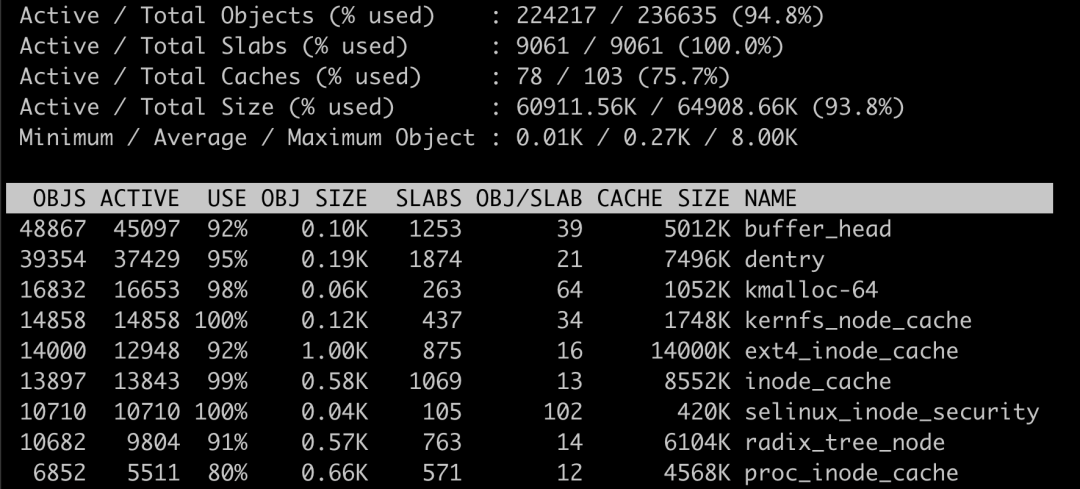
cat /proc/slabinfo | grep -E '^#|dentry|inode'
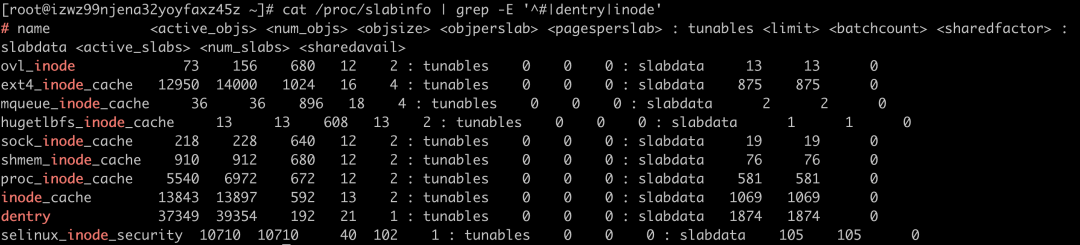
dentry 行表示目录项缓存,inode_cache 行,表示 VFS 索引节点缓存,其余的则是各种文件系统的索引节点缓存。
在实际性能分析中,更常使用 slabtop,来找到占用内存最多的缓存类型。
文件系统
1)文件系统的作用
控制数据的存储和检索。如果没有文件系统,放在存储设备(比如磁盘)上的数据仅仅是一堆字节,无法区分各类数据的边界在哪。
2)block-磁盘I/O读写单位
内存的读写以字节为单位,由于磁盘I/O相对缓慢,以4K字节为一个单位进行访问。4K字节称为一个block(块)。
3)inode-定位文件存储的数据的block序号
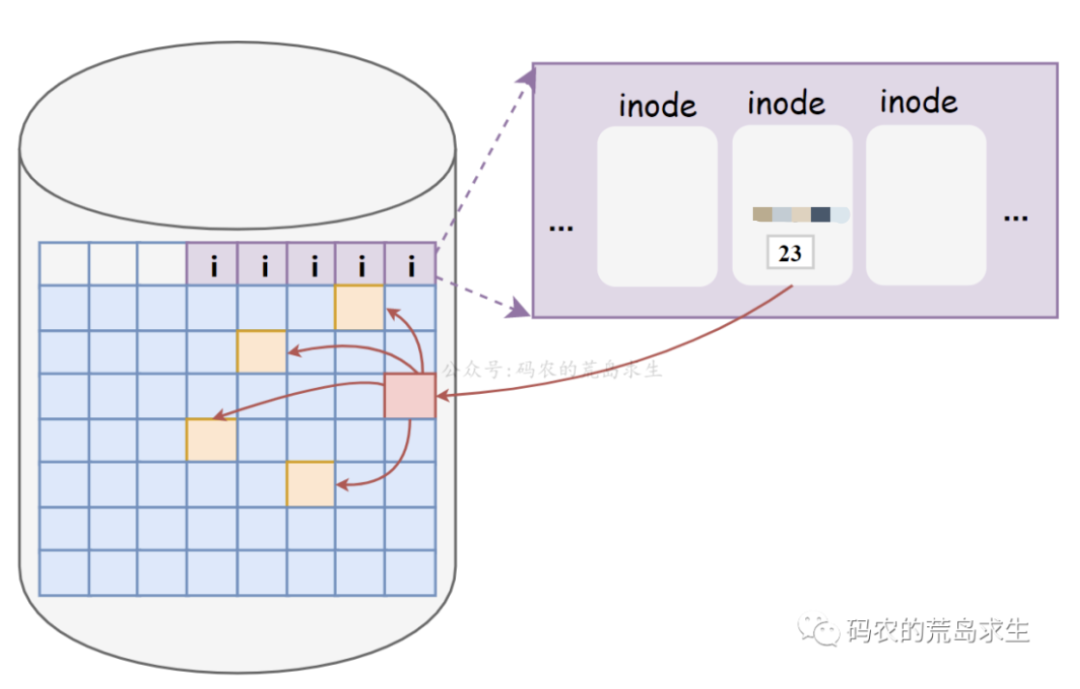
"i"可以理解为索引。和普通文件一样,也存储于磁盘。每个inode包含了关于文件的所有信息。如文件占用磁盘空间的大小,由多少block组成,文件创建时间,文件上一次修改时间,该文件由哪些block组成等,即存储指文件的元数据。inode中使用一个数组保存block序号。
直接指针:inode中数组存储的block序号直接保存文件存储所在的数据。
一次间接指针:inode中数组存储的block序号记录的是文件存储的block序号。如下图所示。
最大能保存多大的文件:(直接指针个数+一次间接指针*1024+二次间接指针*1024*1024+三次间接指针*1024*1024*1024)*4K(假设每个block能存储1024个block序号)。
为什么不全部使用**间接指针:实际上计算机上大多数文件都很小,对于大多数文件,使用直接指针就可以了,对于少数较大文件则需要依次使用直接指针、一次间接指针等直到能装下该文件。
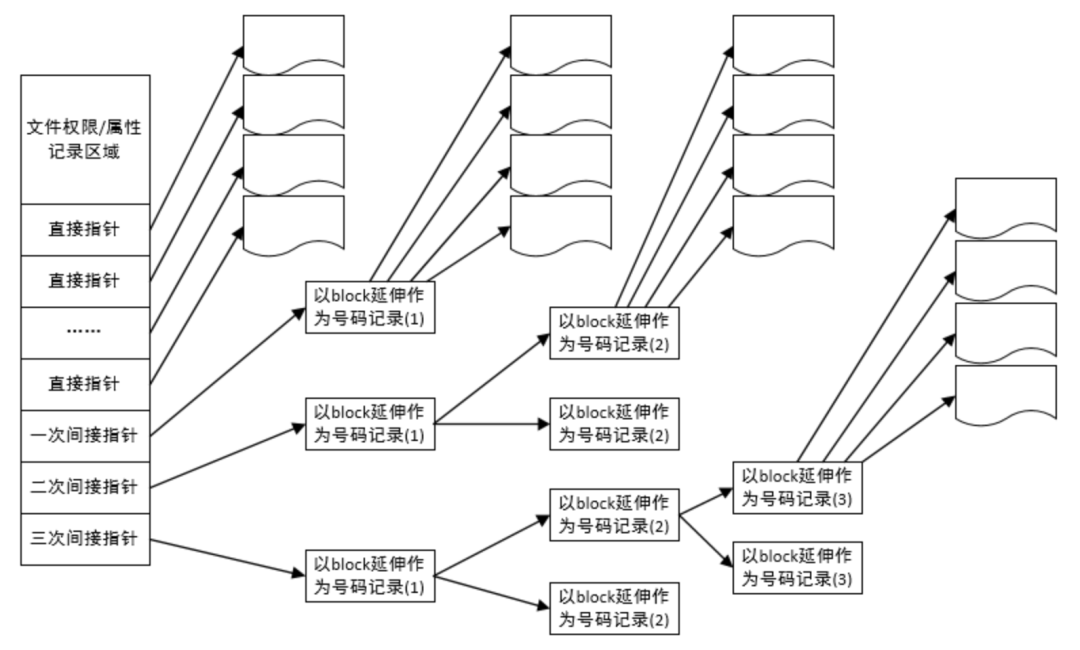
4)目录-记录文件对应的inode序号
所有inode存储在磁盘固定的几个block中,所以我们可以通过inode序号找到对应的某个inode。一个inode序号唯一标识一个inode,一个inode标识一个文件。因此inode序号与文件一一映射。
我们假设inode的大小为256个字节,那么每个block可以装入16(4KB/256)个inode。如下inode序号分布如下:
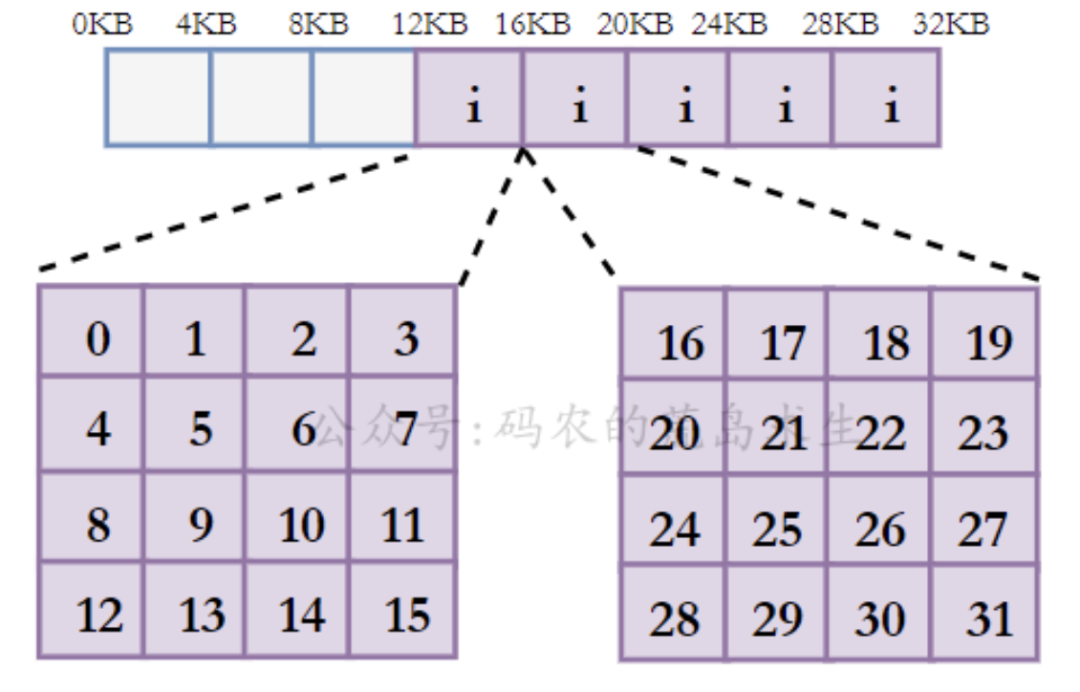
对于普通文件,其对应的inode指向的block中存储的是文件数据;文件夹对应的inode指向的block存储的是该文件夹下所有文件名inode序号的对应关系,整体关系如下所示:
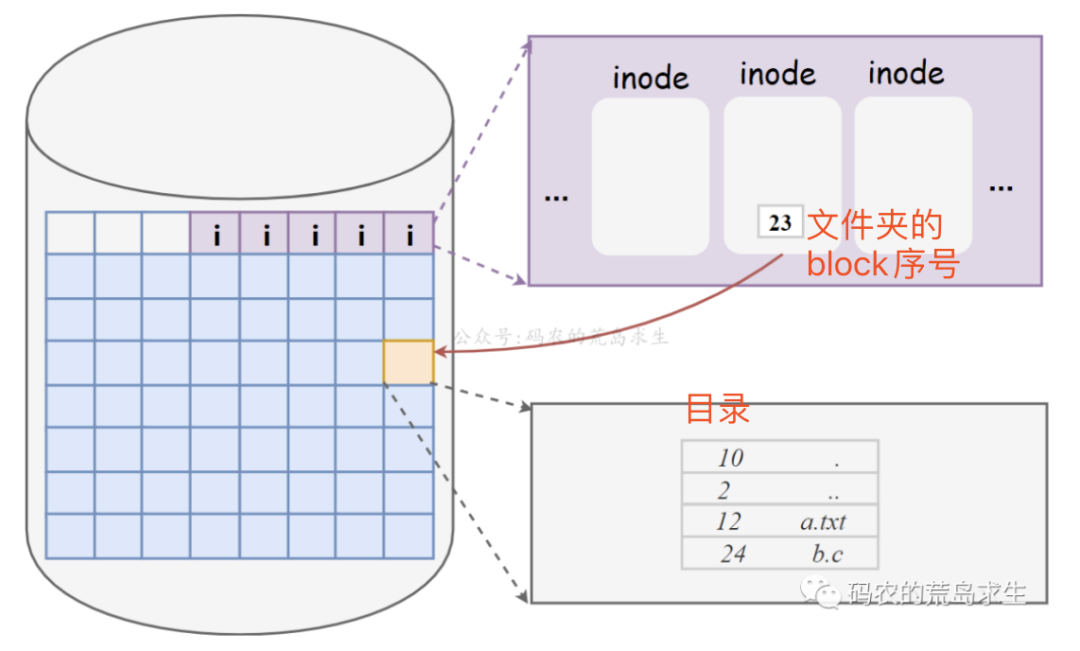
ls -i 打印出文件对应的inode序号,其中文件夹本身对应的inode序号即为"."对应的inode序号。如下:当前文件夹下的inode序号即为263249。

通过文件夹的inode序号,可以找到对应的inode,查找inode可以找到该文件夹对应的block序号,通过读取该block存储的数据就能找到该目录下所有文件名及其对应的inode序号了。
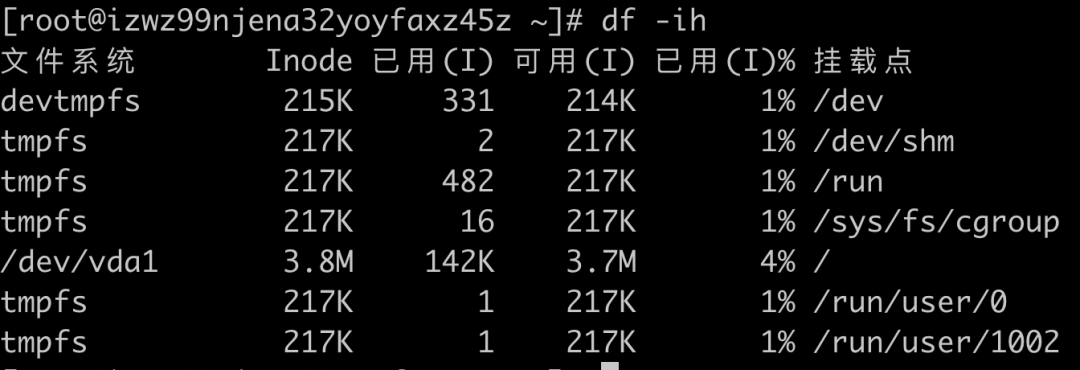
另外,除了文件数据,索引节点也会占据磁盘空间,可以通过df -i查看索引节点占用的空间。索引节点的总容量在格式化磁盘时设定好的,一般由格式化工具自动生成。当你发现索引节点空间不足,但磁盘空间充足时,很可能就是过多小文件导致的。
5)bitmap-跟踪inode及block使用情况
bitmap每个比特位对应一个inode或者block,0表示空闲,1表示正在使用。每个block大小为4KB,比特位即为32K(4K*8),即32768(32*1024),也就是每个block可以跟踪inode或block的数量达32768。
6)superblock超级块-文件系统元数据
位于第0号block。存储信息:有多少inode,这些inode存储的block序号范围,有多少用于存储文件数据的block,有哪些空闲的inode以及block,文件系统类型(比如ext2或ext3等)等。
当mount一个新的文件系统时,操作系统会首先读取该文件系统的superblock,这样操作系统就能了解关于该文件系统的所有信息,当访问该文件系统的文件时就能准确知道该去磁盘的哪些位置找到所需的数据结构进行读取该文件。

Page Cache层
引入Cache层的目的是为了提高Linux操作系统对磁盘访问的性能。Cache层在内存中缓存了磁盘上的部分数据。当数据的请求到达时,如果在Cache中存在该数据且是最新的,则直接将数据传递给用户程序,免除了对底层磁盘的操作,提高了性能。Cache层也正是磁盘IOPS为什么能突破200的主要原因之一。
在Linux的实现中,文件Cache分为两个层面,一是Page Cache,另一个Buffer Cache,每一个Page Cache包含若干Buffer Cache。Page Cache主要用来作为文件系统上的文件数据的缓存来用,尤其是针对当进程对文件有read/write操作的时候。Buffer Cache则主要是设计用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用。
磁盘Cache有两大功能:预读和回写。预读其实就是利用了局部性原理,具体过程是:对于每个文件的第一个读请求,系统读入所请求的页面并读入紧随其后的少数几个页面(通常是三个页面),这时的预读称为同步预读。对于第二次读请求,如果所读页面不在Cache中,即不在前次预读的页中,则表明文件访问不是顺序访问,系统继续采用同步预读;如果所读页面在Cache中,则表明前次预读命中,操作系统把预读页的大小扩大一倍,此时预读过程是异步的,应用程序可以不等预读完成即可返回,只要后台慢慢读页面即可,这时的预读称为异步预读。任何接下来的读请求都会处于两种情况之一:第一种情况是所请求的页面处于预读的页面中,这时继续进行异步预读;第二种情况是所请求的页面处于预读页面之外,这时系统就要进行同步预读。
回写是通过暂时将数据存在Cache里,然后统一异步写到磁盘中。通过这种异步的数据I/O模式解决了程序中的计算速度和数据存储速度不匹配的鸿沟,减少了访问底层存储介质的次数,使存储系统的性能大大提高。Linux 2.6.32内核之前,采用pdflush机制来将脏页真正写到磁盘中,什么时候开始回写呢?下面两种情况下,脏页会被写回到磁盘:
在空闲内存低于一个特定的阈值时,内核必须将脏页写回磁盘,以便释放内存。
当脏页在内存中驻留超过一定的阈值时,内核必须将超时的脏页写回磁盘,以确保脏页不会无限期地驻留在内存中。
回写开始后,pdflush会持续写数据,直到满足以下两个条件:
已经有指定的最小数目的页被写回到磁盘。
空闲内存页已经回升,超过了阈值。
Linux 2.6.32内核之后,放弃了原有的pdflush机制,改成了bdi_writeback机制。bdi_writeback机制主要解决了原有fdflush机制存在的一个问题:在多磁盘的系统中,pdflush管理了所有磁盘的Cache,从而导致一定程度的I/O瓶颈。bdi_writeback机制为每个磁盘都创建了一个线程,专门负责这个磁盘的Page Cache的刷新工作,从而实现了每个磁盘的数据刷新在线程级的分离,提高了I/O性能。
回写机制存在的问题是回写不及时引发数据丢失(可由sync|fsync解决),回写期间读I/O性能很差。
磁盘
磁盘是可以持久化存储的设备,根据存储介质的不同,常见磁盘可以分为两类:机械磁盘和固态磁盘。
固态磁盘(Solid State Disk),通常缩写为 SSD,由固态电子元器件组成。固态磁盘不需要磁道寻址,所以,不管是连续 I/O,还是随机 I/O 的性能,都比机械磁盘要好得多。
以下介绍机械磁盘的工作原理
1)访问速度
内存纳秒级别,磁盘毫秒级别,内存的访问速度大约是磁盘的10万倍。
2)构造
盘片platter:磁盘中用于存储数据的称为盘片,两面均可存储数据;
磁道track:盘片上每一个用于存储数据的同心圆称为磁道;
扇区sector:一个磁道将被划分成多个弧段,每个弧段称为一个扇区。扇区是磁盘上最小的存储单位(也称最小可寻址单元)。通常每个扇区可以存储512个字节,即使我们只需要磁盘上的某一个字节,但是也需要将其所在扇区全部读入内存然后再选取那个字节。另磁盘支持多扇区读写,文件系统将磁盘视为一个个block组成的存储设备,许多文件系统一次读写4KB(8个扇区)。这里我们需要清楚block是逻辑概念。
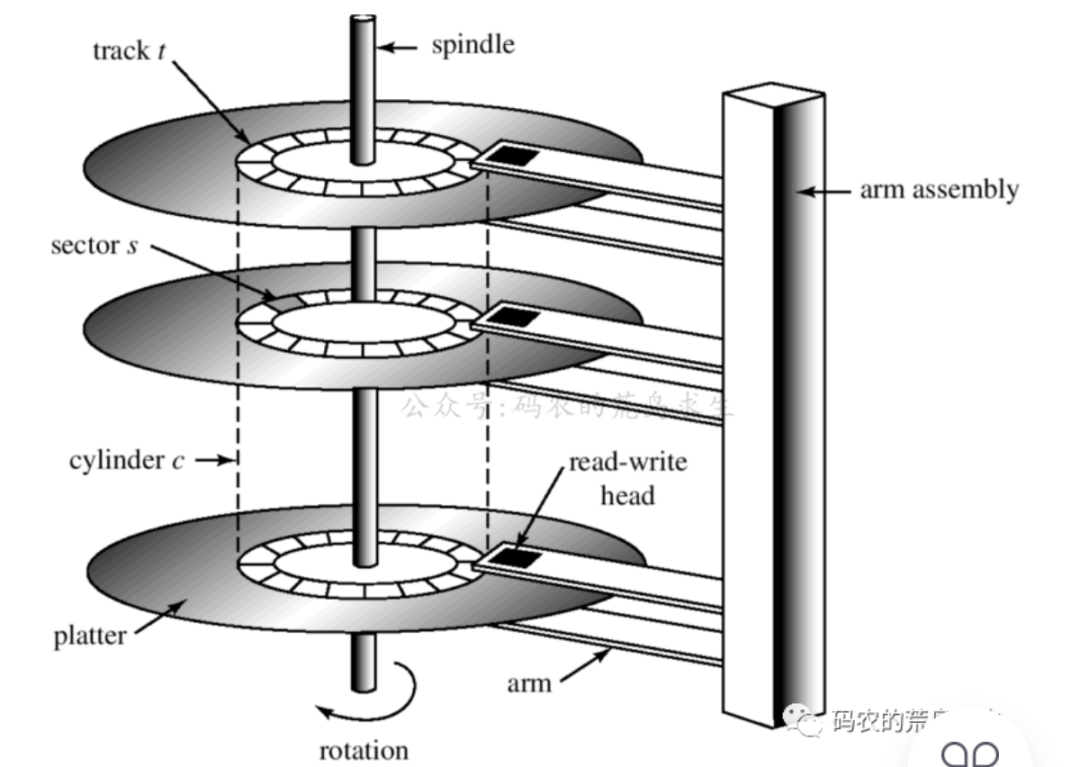
柱面Cylinder:所有盘面的同一磁道构成一个圆柱,这个圆柱称为柱面Cylinder。磁盘的读写是按照柱面进行的,即机械臂杆从上到下有多个磁头,数据读写时会首先从上方的磁头开始依次向下操作,只有同一个柱面上所有磁头都读写完毕后机械臂杆才会转移至其它柱面。
3)如何读写数据
假设有三个磁道,每个磁道划分为12个扇区,如下所示。当前磁头位于第30号扇区。假设我们接到需求,需要读取第0号扇区的数据,则处理步骤如下:
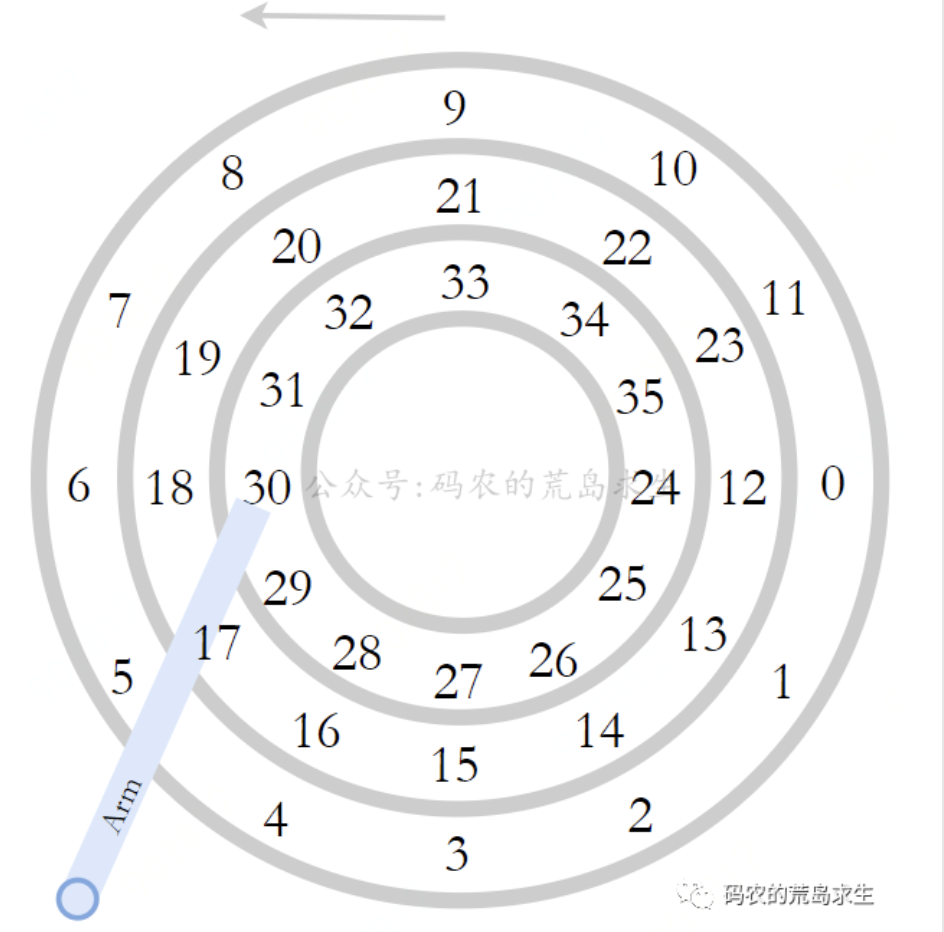
寻道:转动机械臂,将磁头放置于0号扇区所在的磁道上。该操作通常需要0.5ms~2ms,这一时间称为寻道时间。
旋转:等到0号扇区旋转至磁头下面。这一过程花费的时间称为旋转延迟,平均时间为4.15ms。
传输:当扇区旋转至磁头位置后,就可以进行数据读写,将数据从磁盘读入到磁头或从磁头写入到磁盘占用的时间称为数据传输时间,平均每个扇区的平均传输时间为18.6微秒。
可以看到访问的瓶颈主要在寻道和旋转上,如果要读取的数据都分布在同一磁道的连续扇区中,即为顺序访问。此外,连续 I/O 还可以通过预读的方式,来减少 I/O 请求的次数,这也是其性能优异的一个原因。那么最大访问速度能达到210MB/s。因为这是磁盘可以专心于数据读写,不用变换磁道。因此平时我们说的磁盘速度慢,是在随机访问的前提下。
通用块层
在 Linux 中,磁盘实际上是作为一个块设备来管理的,也就是以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主、次设备号。主设备号用在驱动程序中,用来区分设备类型;而次设备号则是用来给多个同类设备编号。
跟虚拟文件系统 VFS 类似,为了减小不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理各种不同的块设备。
通用块层,其实是处在文件系统和磁盘驱动中间的一个块设备抽象层。它主要有两个功能。
第一个功能跟虚拟文件系统的功能类似。向上,为文件系统和应用程序,提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
第二个功能,通用块层还会给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
其中,对 I/O 请求排序的过程,也就是我们熟悉的 I/O 调度。事实上,Linux 内核支持四种 I/O 调度算法,分别是 NONE、NOOP、CFQ 以及 DeadLine。
第一种 NONE ,更确切来说,并不能算 I/O 调度算法。因为它完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 其实不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。
第二种 NOOP ,是最简单的一种 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。
第三种 CFQ(Completely Fair Scheduler),也被称为完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。
类似于进程 CPU 调度,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。
最后一种 DeadLine 调度算法,分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。DeadLine 调度算法,多用在 I/O 压力比较重的场景,比如数据库等。
通用块层是 Linux 磁盘 I/O 的核心。向上,它为文件系统和应用程序,提供访问了块设备的标准接口;向下,把各种异构的磁盘设备,抽象为统一的块设备,并会对文件系统和应用程序发来的 I/O 请求进行重新排序、请求合并等,提高了磁盘访问的效率。
I/O 栈
Linux 存储系统的 I/O 栈,由上到下分为三个层次,分别是文件系统层、通用块层和设备层。
文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
通用块层,包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
设备层,包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作。
存储系统的 I/O ,通常是整个系统中最慢的一环。所以, Linux 通过多种缓存机制来优化 I/O 效率。
比方说,为了优化文件访问的性能,会使用页缓存(page cache)、索引节点缓存(inode cache)、目录项缓存(dentry)等多种缓存机制,以减少对下层块设备的直接调用。
同样,为了优化块设备的访问效率,会使用缓冲区(Buffer),来缓存块设备的数据。
二、性能指标
磁盘性能指标
使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
吞吐量,是指每秒的 I/O 请求大小。
响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
要注意的是,使用率只考虑有没有 I/O,而不考虑 I/O 的大小。换句话说,当使用率是 100% 的时候,磁盘依然有可能接受新的 I/O 请求。因为使用率是从时间角度衡量I/O,但是磁盘还可以支持并行写,所以即使使用率100%,有可能还可以接收新的I/O(不饱和)
不要孤立地去比较某一指标,而要结合读写比例、I/O 类型(随机还是连续)以及 I/O 的大小,综合来分析。举个例子,在数据库、大量小文件等这类随机读写比较多的场景中,IOPS 更能反映系统的整体性能;而在多媒体等顺序读写较多的场景中,吞吐量才更能反映系统的整体性能。
整体性能指标

三、工具篇
磁盘整体的 I/O 性能数据-iostat
iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。
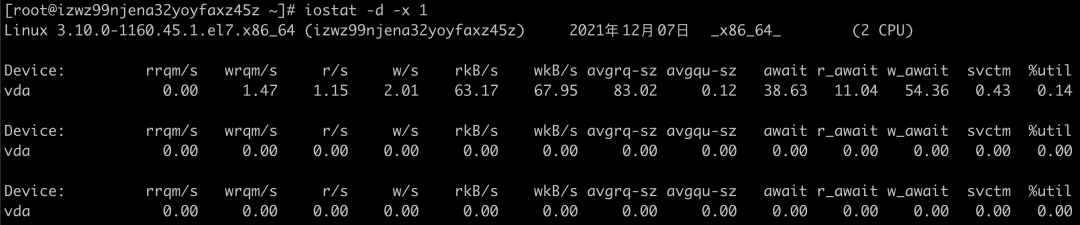
各个字段的含义如下:
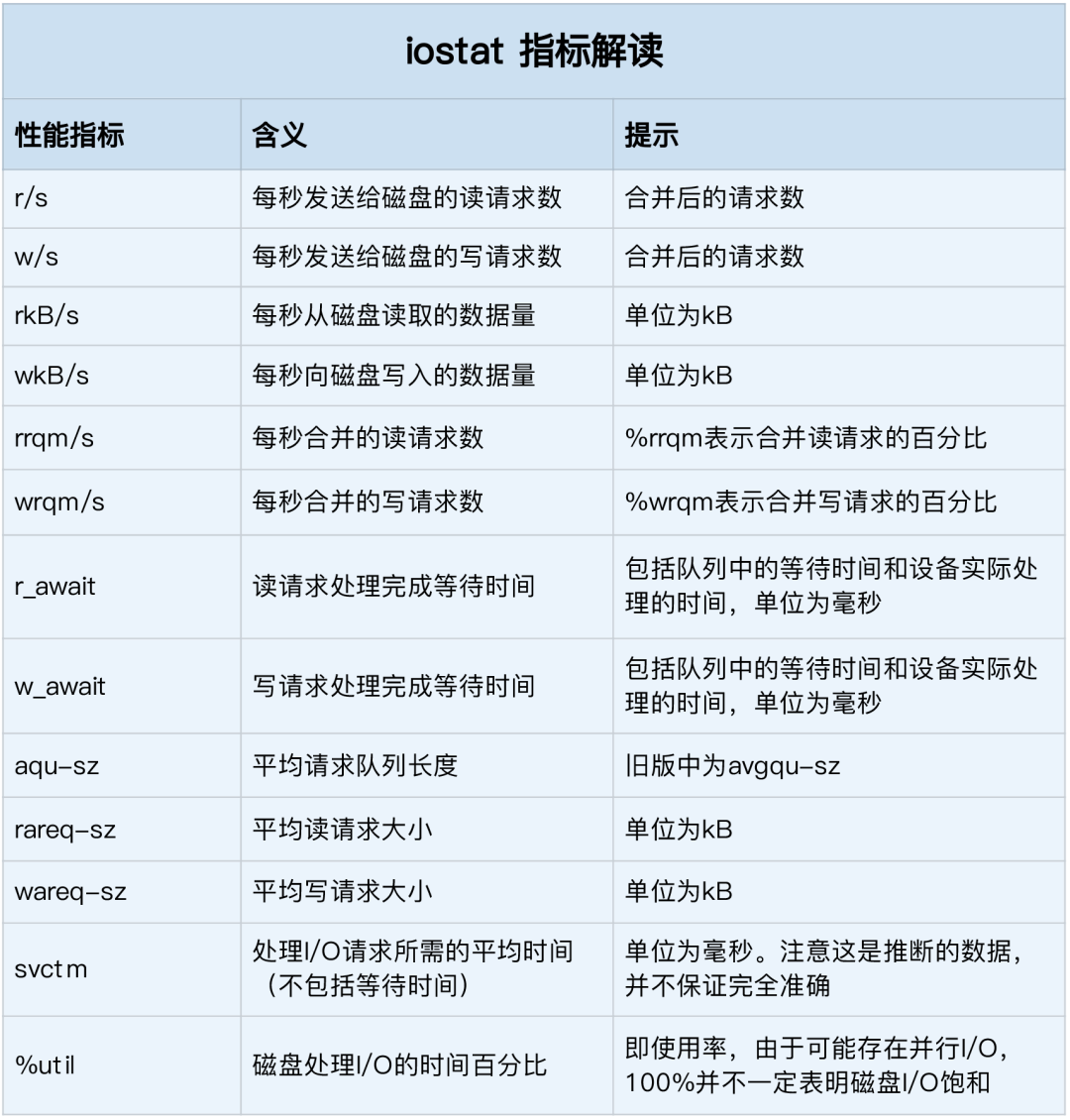
这些指标中,要注意:
%util ,就是我们前面提到的磁盘 I/O 使用率;
r/s+ w/s ,就是 IOPS;
rkB/s+wkB/s ,就是吞吐量;
r_await+w_await ,就是响应时间。
在观测指标时,也别忘了结合请求的大小( rareq-sz 和 wareq-sz)一起分析。
进程的 I/O情况-pidstat
pidstat -d 1
输出示例

从 pidstat 的输出你能看到,它可以实时查看每个进程的 I/O 情况,包括下面这些内容。
用户 ID(UID)和进程 ID(PID) 。
每秒读取的数据大小(kB_rd/s) ,单位是 KB。
每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
进程I/O 大小排序-iotop
安装方法
yum install iotopiotop输出如下:

前两行分别表示,进程的磁盘读写大小总数和磁盘真实的读写大小总数。因为缓存、缓冲区、I/O 合并等因素的影响,它们可能并不相等。
剩下的部分,则是从各个角度来分别表示进程的 I/O 情况,包括线程 ID、I/O 优先级、每秒读磁盘的大小、每秒写磁盘的大小、换入和等待 I/O 的时钟百分比等。
通过上述分析,遇到I/O性能时,先通过iostat查看磁盘整体性能,然后用pidstat或iotop定位到具体的进程。
定位进程的引起瓶颈的文件-strace、lsof
strace -f -p $pid -T -tt -e write
# -f表示跟踪子进程和子线程,-T表示显示系统调用的时长,-tt表示显示跟踪时间
# -e 搜索指定关键字输出
输出示例

lsof -p $pid
# pid必须为进程号,线程号将没有任何输出
5)提供I/O与CPU等**度对比-vmstat
另外,我们还可以使用vmstat作为辅助分析。因为相对于 iostat 来说,vmstat 可以同时提供 CPU、内存和 I/O 的使用情况。
性能指标和工具的联系
1)第一个维度,从文件系统和磁盘 I/O 的性能指标出发
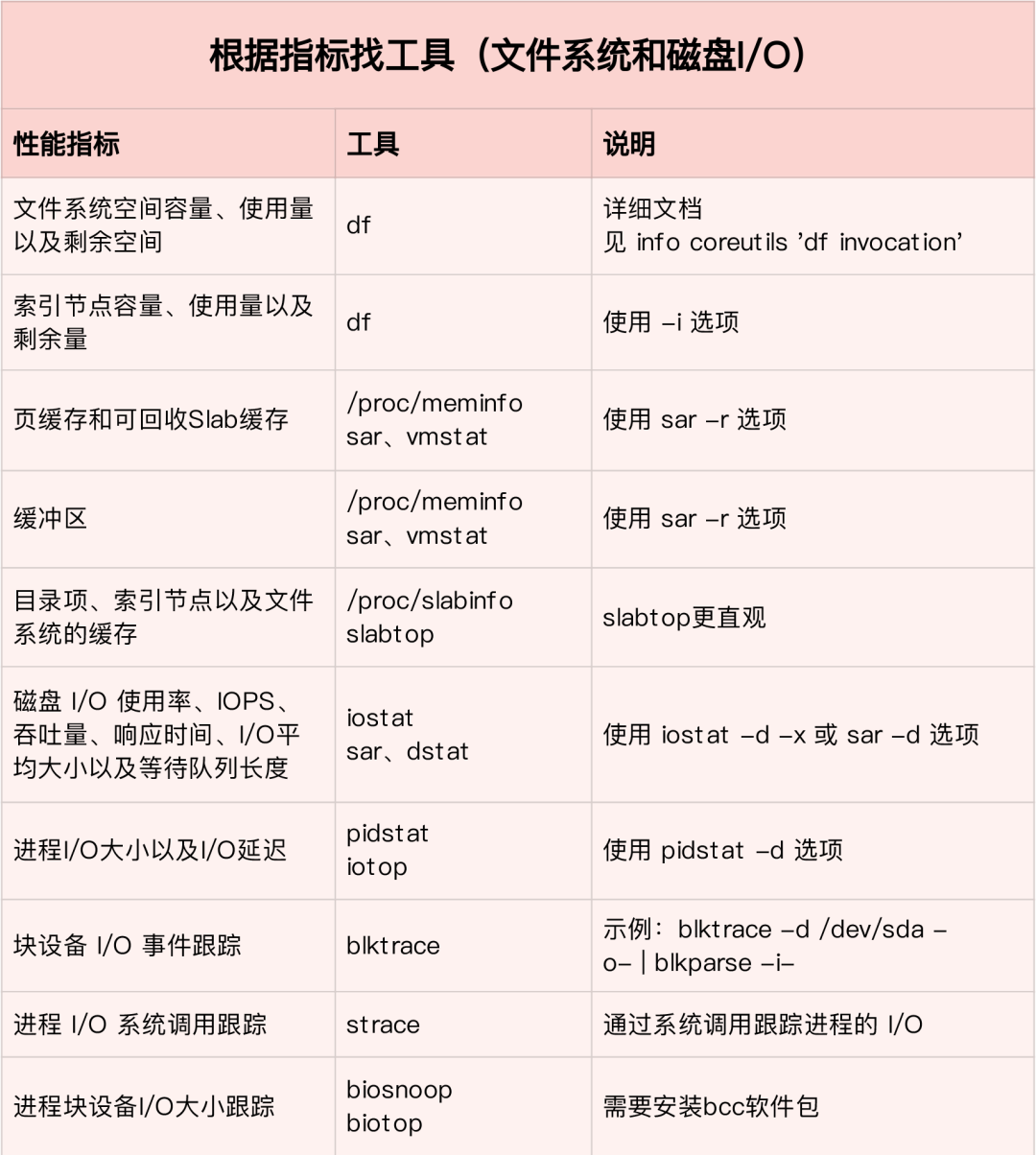
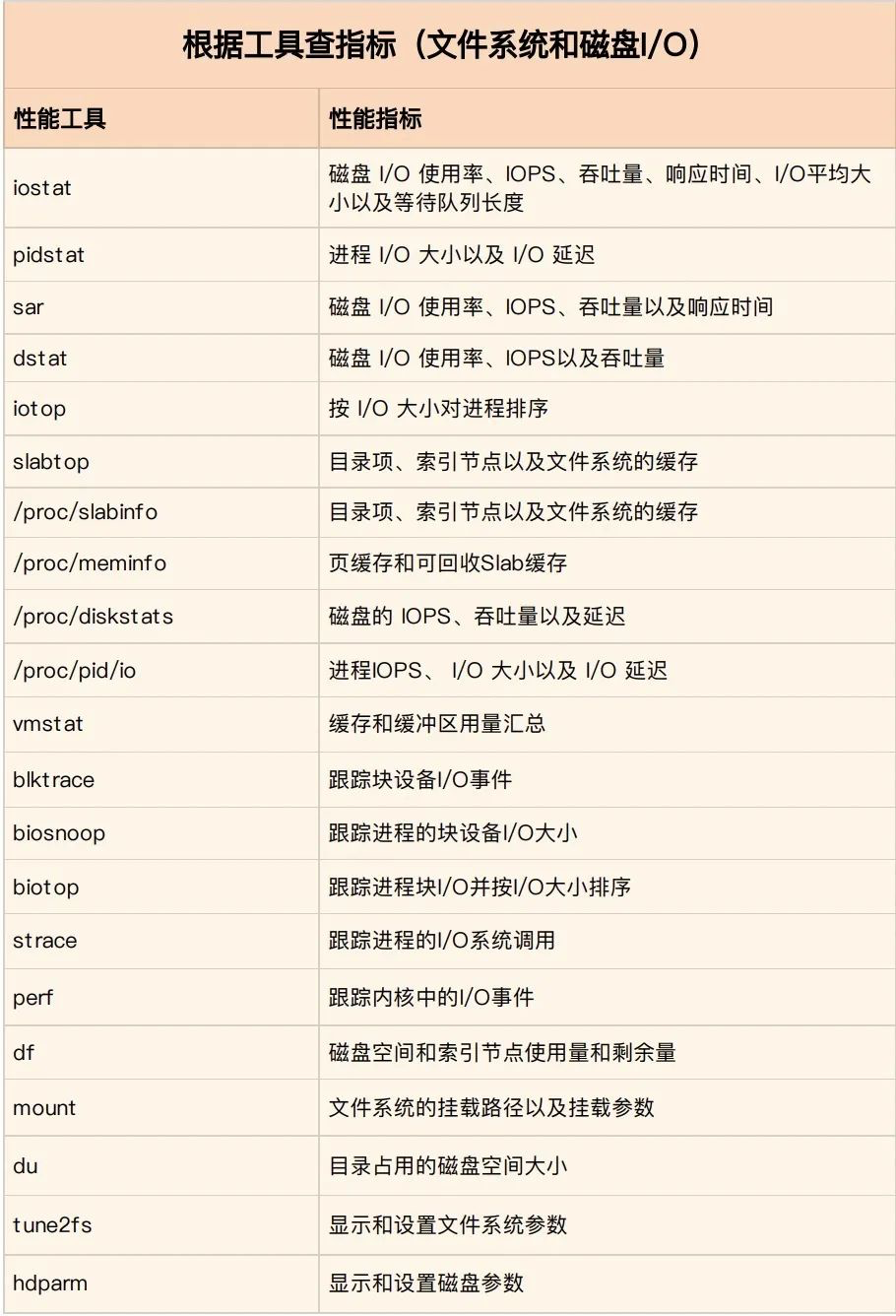
2)第二个维度,从工具出发
当已经安装了某个工具后,要知道这个工具能提供哪些指标。
四、瓶颈排查策略
先用 iostat 发现磁盘 I/O 性能瓶颈;
再借助 pidstat ,定位出导致瓶颈的进程;
随后通过strace及lsof分析进程的 I/O 行为;
最后,结合应用程序的原理,分析这些 I/O 的来源。
为了缩小排查范围,可以先运行那几个支持指标较多的工具,如 iostat、vmstat、pidstat 等。然后再根据观察到的现象,结合系统和应用程序的原理,寻找下一步的分析方向。过程如下图。
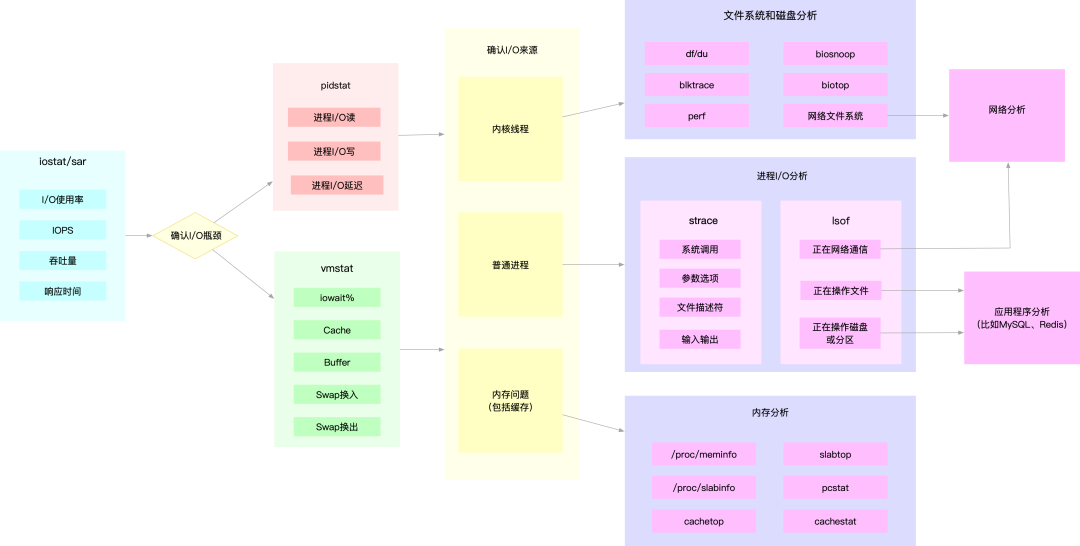
例如,在前面讲过的 MySQL 和 Redis 案例中,我们就是通过 iostat 确认磁盘出现 I/O 性能瓶颈,然后用 pidstat 找出 I/O 最大的进程,接着借助 strace 找出该进程正在读写的文件,最后结合应用程序的原理,找出大量 I/O 的原因。
再如,当你用 iostat 发现磁盘有 I/O 性能瓶颈后,再用 pidstat 和 vmstat 检查,可能会发现 I/O 来自内核线程,如 Swap 使用大量升高。这种情况下,你就得进行内存分析了,先找出占用大量内存的进程,再设法减少内存的使用。
五、优化方向
性能极限评估
找出了 I/O 的性能瓶颈后,下一步要做的就是优化了,也就是如何以最快的速度完成 I/O 操作,或者换个思路,减少甚至避免磁盘的 I/O 操作。
为了更客观合理地评估优化效果,我们首先应该对磁盘和文件系统进行基准测试,得到文件系统或者磁盘 I/O 的极限性能。
fio安装
yum install -y fio
测试示例
# 随机读
fio -name=randread -direct=1 -iodepth=64 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 随机写
fio -name=randwrite -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序读
fio -name=read -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
# 顺序写
fio -name=write -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/sdb
在这其中,有几个参数需要重点关注一下。
direct,表示是否跳过系统缓存。上面示例中设置的 1 ,就表示跳过系统缓存。
iodepth,表示使用异步 I/O(asynchronous I/O,简称 AIO)时,同时发出的 I/O 请求上限。在上面的示例中,设置的是 64。
rw,表示 I/O 模式。示例中, read/write 分别表示顺序读 / 写,而 randread/randwrite 则分别表示随机读 / 写。
ioengine,表示 I/O 引擎,它支持同步(sync)、异步(libaio)、内存映射(mmap)、网络(net)等各种 I/O 引擎。上面示例中,设置的 libaio 表示使用异步 I/O。
bs,表示 I/O 的大小。示例中,设置成了 4K(这也是默认值)。
filename,表示文件路径,当然,它可以是磁盘路径(测试磁盘性能),也可以是文件路径(测试文件系统性能)。示例中,把它设置成了磁盘 /dev/sdb。不过注意,用磁盘路径测试写,会破坏这个磁盘中的文件系统,所以在使用前,一定要事先做好数据备份。注意测试时别在系统盘或者存有重要的磁盘中来操作。
另外fio 支持 I/O 的重放。借助前面提到过的 blktrace,再配合上 fio,就可以实现对应用程序 I/O 模式的基准测试。需要先用 blktrace ,记录磁盘设备的 I/O 访问情况;然后使用 fio ,重放 blktrace 的记录。
# 使用blktrace跟踪磁盘I/O,注意指定应用程序正在操作的磁盘
$ blktrace /dev/sdb
# 查看blktrace记录的结果
# ls
sdb.blktrace.0 sdb.blktrace.1
# 将结果转化为二进制文件
$ blkparse sdb -d sdb.bin
# 使用fio重放日志
$ fio --name=replay --filename=/dev/sdb --direct=1 --read_iolog=sdb.bin
应用程序优化
应用程序处于整个 I/O 栈的最上端,它可以通过系统调用,来调整 I/O 模式(如顺序还是随机、同步还是异步), 同时,它也是 I/O 数据的最终来源。在我看来,可以有这么几种方式来优化应用程序的 I/O 性能。
第一,可以用追加写代替随机写,减少寻址开销,加快 I/O 写的速度。
第二,可以借助缓存 I/O ,充分利用系统缓存,降低实际 I/O 的次数。
第三,可以在应用程序内部构建自己的缓存,或者用 Redis 这类外部缓存系统。这样,一方面,能在应用程序内部,控制缓存的数据和生命周期;另一方面,也能降低其他应用程序使用缓存对自身的影响。比如,在前面的 MySQL 案例中,我们已经见识过,只是因为一个干扰应用清理了系统缓存,就会导致 MySQL 查询有数百倍的性能差距(0.1s vs 15s)。再如, C 标准库提供的 fopen、fread 等库函数,都会利用标准库的缓存,减少磁盘的操作。而你直接使用 open、read 等系统调用时,就只能利用操作系统提供的页缓存和缓冲区等,而没有库函数的缓存可用。第四,在需要频繁读写同一块磁盘空间时,可以用 mmap 代替 read/write,减少内存的拷贝次数。
第五,在需要同步写的场景中,尽量将写请求合并,而不是让每个请求都同步写入磁盘,即可以用 fsync() 取代 O_SYNC。第六,在多个应用程序共享相同磁盘时,为了保证 I/O 不被某个应用完全占用,推荐你使用 cgroups 的 I/O 子系统,来限制进程 / 进程组的 IOPS 以及吞吐量。
最后,在使用 CFQ 调度器时,可以用 ionice 来调整进程的 I/O 调度优先级,特别是提高核心应用的 I/O 优先级。ionice 支持三个优先级类:Idle、Best-effort 和 Realtime。其中, Best-effort 和 Realtime 还分别支持 0-7 的级别,数值越小,则表示优先级别越高。
文件系统优化
应用程序访问普通文件时,实际是由文件系统间接负责,文件在磁盘中的读写。所以,跟文件系统中相关的也有很多优化 I/O 性能的方式。
第一,你可以根据实际负载场景的不同,选择最适合的文件系统。比如 Ubuntu 默认使用 ext4 文件系统,而 CentOS 7 默认使用 xfs 文件系统。相比于 ext4 ,xfs 支持更大的磁盘分区和更大的文件数量,如 xfs 支持大于 16TB 的磁盘。但是 xfs 文件系统的缺点在于无法收缩,而 ext4 则可以。
第二,在选好文件系统后,还可以进一步优化文件系统的配置选项,包括文件系统的特性(如 ext_attr、dir_index)、日志模式(如 journal、ordered、writeback)、挂载选项(如 noatime)等等。比如, 使用 tune2fs 这个工具,可以调整文件系统的特性(tune2fs 也常用来查看文件系统超级块的内容)。而通过 /etc/fstab ,或者 mount 命令行参数,我们可以调整文件系统的日志模式和挂载选项等。
第三,可以优化文件系统的缓存。比如,你可以优化 pdflush 脏页的刷新频率(比如设置 dirty_expire_centisecs 和 dirty_writeback_centisecs)以及脏页的限额(比如调整 dirty_background_ratio 和 dirty_ratio 等)。再如,你还可以优化内核回收目录项缓存和索引节点缓存的倾向,即调整 vfs_cache_pressure(/proc/sys/vm/vfs_cache_pressure,默认值 100),数值越大,就表示越容易回收。
最后,在不需要持久化时,你还可以用内存文件系统 tmpfs,以获得更好的 I/O 性能 。tmpfs 把数据直接保存在内存中,而不是磁盘中。比如 /dev/shm/ ,就是大多数 Linux 默认配置的一个内存文件系统,它的大小默认为总内存的一半。
磁盘优化
数据的持久化存储,最终还是要落到具体的物理磁盘中,同时,磁盘也是整个 I/O 栈的最底层。从磁盘角度出发,自然也有很多有效的性能优化方法。
第一,最简单有效的优化方法,就是换用性能更好的磁盘,比如用 SSD 替代 HDD。
第二,我们可以使用 RAID ,把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列。这样做既可以提高数据的可靠性,又可以提升数据的访问性能。
第三,针对磁盘和应用程序 I/O 模式的特征,我们可以选择最适合的 I/O 调度算法。比方说,SSD 和虚拟机中的磁盘,通常用的是 noop 调度算法。而数据库应用,我更推荐使用 deadline 算法。调整参数/sys/block/{DEVICE-NAME}/queue/scheduler
第四,我们可以对应用程序的数据,进行磁盘级别的隔离。比如,我们可以为日志、数据库等 I/O 压力比较重的应用,配置单独的磁盘。
第五,在顺序读比较多的场景中,我们可以增大磁盘的预读数据,比如,可以通过下面两种方法,调整 /dev/sdb 的预读大小。
调整内核选项 /sys/block/sdb/queue/read_ahead_kb,默认大小是 128 KB,单位为 KB。
使用 blockdev 工具设置,比如 blockdev --setra 8192 /dev/sdb,注意这里的单位是 512B(0.5KB),所以它的数值总是 read_ahead_kb 的两倍。
第六,我们可以优化内核块设备 I/O 的选项。比如,可以调整磁盘队列的长度 /sys/block/sdb/queue/nr_requests,适当增大队列长度,可以提升磁盘的吞吐量(当然也会导致 I/O 延迟增大)。
最后,要注意,磁盘本身出现硬件错误,也会导致 I/O 性能急剧下降,所以发现磁盘性能急剧下降时,还需要确认,磁盘本身是不是出现了硬件错误。比如,可以查看 dmesg 中是否有硬件 I/O 故障的日志。还可以使用 badblocks、**artctl 等工具,检测磁盘的硬件问题,或用 e2fsck 等来检测文件系统的错误。如果发现问题,可以使用 fsck 等工具来修复。
切记,磁盘和文件系统的 I/O ,通常是整个系统中最慢的一个模块。所以,在优化 I/O 问题时,除了可以优化 I/O 的执行流程,还可以借助更快的内存、网络、CPU 等,减少 I/O 调用。比如,可以充分利用系统提供的 Buffer、Cache,或是应用程序内部缓存, 再或者 Redis 这类的外部缓存系统。

