
CPU平均负载过高,最后发现竟然却是这个搞鬼!转载
前言
最近在项目上遇到负载均衡过高的问题,分析好几天,还因此移植了一个CPU检测工具,后面在小二哥的指导找到了问题原因,小二哥有些读者应该会比较熟悉,之前发的微信滑动卡顿就是他分析的,他是一个非常厉害的android系统工程师。
我这个问题比较棘手的是平均负载过高的时候,CPU占用和IOwait都是正常的,所以我第一时间还去查了僵尸进程,把僵尸进程都干掉后,发现CPU平均负载还是很高,最后在小二哥的提示下研究了下D进程,最后解决问题。
正文
1、什么是平均负载?
使用命令
cat /proc/loadavg
6.00 6.00 6.00 1/721 5555
查看当前系统的平均负载,前三个数分别是 1分钟、5分钟、15分钟的平均进程数。第四个的分子是正在运行的进程数,分母是进程总数;最后一个最近运行的进程ID号。
或者使用
uptime
08:24:29 up 19:34, 0 users, load average: 6.00, 6.00, 6.00
命令查看平均负载
- 08:24:29 //当前时间
- up 19:34 //运行时间
- 0 users //当前的用户数量
- load average: 6.00, 6.00, 6.00 //分别是 1分钟、5分钟、15分钟的平均进程数
还可以使用下面这个命令查看
dumpsys cpuinfo
所以什么是平均负载?
简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
这里我先解释下,可运行状态和不可中断状态这俩词儿。所谓可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。
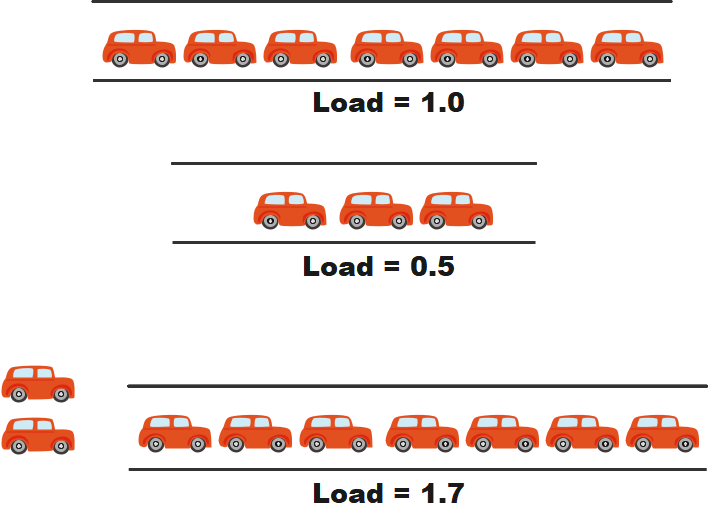
把CPU当作一座桥梁,当load 等于1的时候,桥梁上正好有足够的汽车在行驶,当load等于0.5的时候,桥梁上还非常宽松,当load 等于1.7时候,说明已经有超负荷的汽车需要通过桥梁了。
2、平均负载与 CPU 使用率?
现实工作中,我们经常容易把平均负载和 CPU 使用率混淆,所以在这里,我也做一个区分。
可能你会疑惑,既然平均负载代表的是活跃进程数,那平均负载高了,不就意味着 CPU 使用率高吗?
我们还是要回到平均负载的含义上来,平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。
所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。
比如:
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
3、使用top命令查看CPU使用情况
使用top命令查看cpu使用情况
Tasks: 250 total, 1 running, 242 sleeping, 0 stopped, 1 zombie
Mem: 2007724k total, 862320k used, 1145404k free, 18576k buffers
Swap: 1505788k total, 0k used, 1505788k free, 415260k cached
400%cpu 2%user 0%nice 1%sys 397%idle 0%iow 0%irq 0%sirq 0%host
PID USER PR NI VIRT RES SHR S[%CPU] %MEM TIME+ ARGS
5645 root 20 0 6.4M 3.6M 2.9M R 2.3 0.1 0:00.46 top
515 system 18 -2 1.1G 153M 134M S 0.3 7.7 5:03.83 system_server
318 shell 20 0 12M 1.2M 1.0M S 0.3 0.0 0:37.92 adbd --root_seclabel=u:r:su:s0
5642 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/u9:1]
5638 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/u8:2]
5614 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/u9:0]
可以看到cpu使用率不是很高
但是查看平均负载的时候,就很高
08:44:56 up 19:55, 0 users, load average: 6.00, 6.00, 6.00
我们是4核CPU,如果平均负载低于4.0就是比较正常的,现在已经远远高于4.0了。
4、使用trace查看cpuloading
先使用脚本抓取trace文件
get_trace.bat 文件
@echo off
adb root
adb wait-for-device
adb root
rem set size
adb shell "echo 16384 > /sys/kernel/debug/tracing/buffer_size_kb"
rem set or use debug method
adb shell "echo nop > /sys/kernel/debug/tracing/current_tracer"
rem set debug event
adb shell "echo 'sched_switch sched_wakeup sched_wakeup_new' > /sys/kernel/debug/tracing/set_event"
rem enable debug
rem adb shell "echo 1 > /sys/kernel/debug/tracing/tracing_enabled >nul 2>&1"
rem stop debug
adb shell "echo 0 > /sys/kernel/debug/tracing/tracing_on"
rem clear debug data
adb shell "echo > /sys/kernel/debug/tracing/trace"
rem wait user to start
echo press any key to start ...
pause
rem start debug
adb shell "echo 1 > /sys/kernel/debug/tracing/tracing_on"
rem wait user to stop
echo press any key to stop ...
pause
rem stop debug
adb shell "echo 0 > /sys/kernel/debug/tracing/tracing_on"
echo pull debug data start ...
adb pull /sys/kernel/debug/tracing/trace sys_ftrace_data
echo pull debug data end
pause
获取trace文件 sys_ftrace_data 。
通过谷歌浏览器打开地址
chrome://tracing/
导入刚才的文件
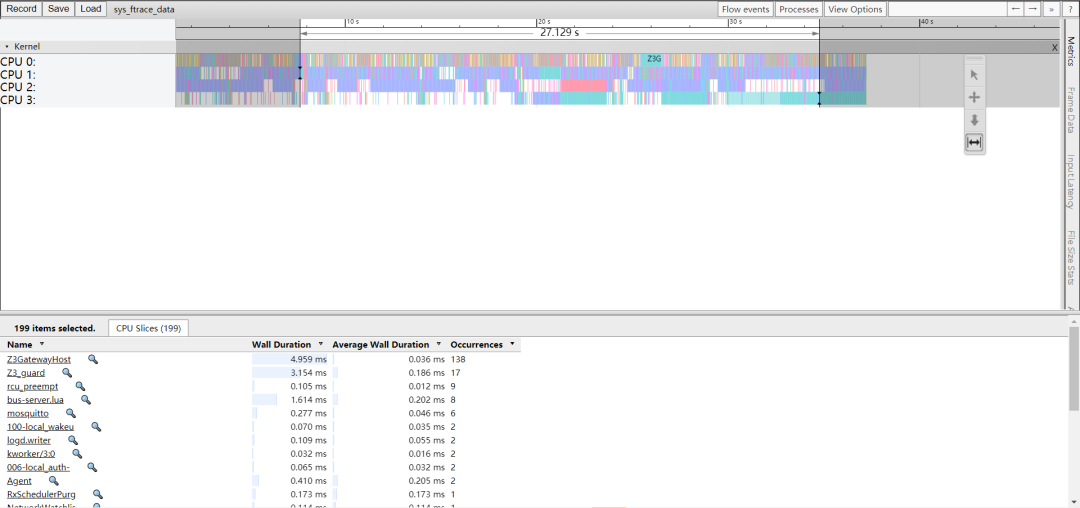
w放大,s缩小
a左移,d右移
通过分析CPU的使用情况,发现CPU工作不是非常繁忙,这和从TOP上看到的情况是一样的。
5、使用命令查看系统的D进程
首先要了解下什么是D进程
Linux进程状态
S (TASK_INTERRUPTIBLE),可中断的睡眠状态
D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态。
使用如下命令查看D进程的backtrace
echo w > proc/sysrq-trigger
关于 sysrq-trigger的说明可以自行百度,可能会给你带来惊喜。
然后查看内核日志,可以看到如下关键信息
[ 6619.317533] (0)[1621:sh] task PC stack pid father
[ 6619.317562] (0)[1621:sh]GCPU D c0b6f590 0 25 2 0x00000000
[ 6619.317576] (0)[1621:sh]Backtrace:
[ 6619.317585] (0)[1621:sh][<c0b6f244>] (__schedule) from [<c0b6faa0>] (schedule+0x54/0xc4)
[ 6619.317609] (0)[1621:sh] r10:c1103948 r9:00000201 r8:c1103948 r7:c1103948
[ 6619.317627] (0)[1621:sh][<c0b6fa4c>] (schedule) from [<c0b72e4c>] (schedule_timeout+0x178/0x264)
[ 6619.317644] (0)[1621:sh] r4:7fffffff r3:dc8ba692
[ 6619.317655] (0)[1621:sh][<c0b72cd4>] (schedule_timeout) from [<c0b71bfc>] (__down+0x78/0xc4)
[ 6619.317670] (0)[1621:sh] r10:c1103948 r9:00000201 r8:c1103948 r7:00000002
[ 6619.317687] (0)[1621:sh][<c0b71b84>] (__down) from [<c018d2d0>] (down+0x4c/0x60)
[ 6619.317705] (0)[1621:sh] r8:d038de88 r7:ffff1234 r6:c1103948 r5:d038ddcc
[ 6619.317721] (0)[1621:sh][<c018d284>] (down) from [<c070d630>] (KREE_ServSemaphoreDown+0x14/0x1c)
[ 6619.317740] (0)[1621:sh] r4:c0cc5fd8
[ 6619.317748] (0)[1621:sh][<c070d61c>] (KREE_ServSemaphoreDown) from [<c070bcf8>] (tz_service_call+0x74/0xc4)
[ 6619.317767] (0)[1621:sh][<c070bc84>] (tz_service_call) from [<c070bf30>] (KREE_TeeServiceCall+0xe8/0x290)
[ 6619.317781] (0)[1621:sh] r7:00000002 r6:00000001 r5:00000002 r4:00000000
[ 6619.317799] (0)[1621:sh][<c070be48>] (KREE_TeeServiceCall) from [<c070c120>] (kree_thread_function+0x48/0x64)
[ 6619.317814] (0)[1621:sh] r10:00000000 r9:00000000 r8:00000000 r7:c070c0d8
[ 6619.317831] (0)[1621:sh][<c070c0d8>] (kree_thread_function) from [<c0148aec>] (kthread+0x114/0x12c)
[ 6619.317849] (0)[1621:sh] r5:d0354d40 r4:00000000
[ 6619.317862] (0)[1621:sh][<c01489d8>] (kthread) from [<c0108730>] (ret_from_fork+0x14/0x24)
[ 6619.317908] (0)[1621:sh]fuse_log D c0b6f590 0 78 2 0x00000000
[ 6619.317922] (0)[1621:sh]Backtrace:
[ 6619.317930] (0)[1621:sh][<c0b6f244>] (__schedule) from [<c0b6faa0>] (schedule+0x54/0xc4)
[ 6619.317945] (0)[1621:sh] r10:00000000 r9:00000000 r8:00000000 r7:c0392b8c
[ 6619.317963] (0)[1621:sh][<c0b6fa4c>] (schedule) from [<c0148aa8>] (kthread+0xd0/0x12c)
[ 6619.317977] (0)[1621:sh] r4:00000000 r3:cf9032c0
[ 6619.317989] (0)[1621:sh][<c01489d8>] (kthread) from [<c0108730>] (ret_from_fork+0x14/0x24)
[ 6619.318020] (0)[1621:sh]hang_detect D c0b6f590 0 124 2 0x00000000
[ 6619.318034] (0)[1621:sh]Backtrace:
[ 6619.318043] (0)[1621:sh][<c0b6f244>] (__schedule) from [<c0b6faa0>] (schedule+0x54/0xc4)
[ 6619.318137] (0)[1621:sh] r10:00000001 r9:c1102100 r8:df5ebb80 r7:c1103948
[ 6619.318162] (0)[1621:sh][<c0b6fa4c>] (schedule) from [<c0b72e1c>] (schedule_timeout+0x148/0x264)
[ 6619.318180] (0)[1621:sh] r4:001cfb65 r3:00000000
[ 6619.318190] (0)[1621:sh][<c0b72cd4>] (schedule_timeout) from [<c01ad908>] (msleep+0x34/0x40)
[ 6619.318209] (0)[1621:sh] r10:00000000 r9:c116e0a4 r8:cfb7dedc r7:c116e158
[ 6619.318228] (0)[1621:sh][<c01ad8d4>] (msleep) from [<c0733f5c>] (hang_detect_thread+0x94/0x318)
[ 6619.318244] (0)[1621:sh] r5:c116e158 r4:c1483ba8
[ 6619.318255] (0)[1621:sh][<c0733ec8>] (hang_detect_thread) from [<c0148aec>] (kthread+0x114/0x12c)
[ 6619.318270] (0)[1621:sh] r10:00000000 r9:00000000 r8:00000000 r7:c0733ec8
[ 6619.318286] (0)[1621:sh][<c01489d8>] (kthread) from [<c0108730>] (ret_from_fork+0x14/0x24)
[ 6619.318320] (0)[1621:sh]mt_gpufreq_inpu D c0b6f590 0 164 2 0x00000000
[ 6619.318333] (0)[1621:sh]Backtrace:
[ 6619.318340] (0)[1621:sh][<c0b6f244>] (__schedule) from [<c0b6faa0>] (schedule+0x54/0xc4)
[ 6619.318354] (0)[1621:sh] r10:00000000 r9:00000000 r8:00000000 r7:c0512ebc
[ 6619.318370] (0)[1621:sh][<c0b6fa4c>] (schedule) from [<c0148aa8>] (kthread+0xd0/0x12c)
[ 6619.318384] (0)[1621:sh] r4:00000000 r3:cf825e40
[ 6619.318395] (0)[1621:sh][<c01489d8>] (kthread) from [<c0108730>] (ret_from_fork+0x14/0x24)
[ 6619.318412] (0)[1621:sh]display_esd_che D c0b6f590 0 169 2 0x00000000
[ 6619.318424] (0)[1621:sh]Backtrace:
[ 6619.318432] (0)[1621:sh][<c0b6f244>] (__schedule) from [<c0b6faa0>] (schedule+0x54/0xc4)
[ 6619.318446] (0)[1621:sh] r10:00000000 r9:00000000 r8:00000000 r7:c0620888
[ 6619.318463] (0)[1621:sh][<c0b6fa4c>] (schedule) from [<c0148aa8>] (kthread+0xd0/0x12c)
[ 6619.318477] (0)[1621:sh] r4:00000000 r3:cfbfe580
[ 6619.318487] (0)[1621:sh][<c01489d8>] (kthread) from [<c0108730>] (ret_from_fork+0x14/0x24)
[ 6619.318510] (0)[1621:sh]entropy_thread D c0b6f590 0 182 2 0x00000000
[ 6619.318523] (0)[1621:sh]Backtrace:
[ 6619.318531] (0)[1621:sh][<c0b6f244>] (__schedule) from [<c0b6faa0>] (schedule+0x54/0xc4)
[ 6619.318545] (0)[1621:sh] r10:c1103948 r9:00020107 r8:c1103948 r7:c1103948
[ 6619.318562] (0)[1621:sh][<c0b6fa4c>] (schedule) from [<c0b72e4c>] (schedule_timeout+0x178/0x264)
[ 6619.318577] (0)[1621:sh] r4:7fffffff r3:dc8ba692
[ 6619.318587] (0)[1621:sh][<c0b72cd4>] (schedule_timeout) from [<c0b71bfc>] (__down+0x78/0xc4)
[ 6619.318602] (0)[1621:sh] r10:c1103948 r9:00020107 r8:c1103948 r7:00000002
[ 6619.318619] (0)[1621:sh][<c0b71b84>] (__down) from [<c018d2d0>] (down+0x4c/0x60)
[ 6619.318634] (0)[1621:sh] r8:ced01e68 r7:0000002d r6:c1103948 r5:ced01dac
[ 6619.318651] (0)[1621:sh][<c018d284>] (down) from [<c070d630>] (KREE_ServSemaphoreDown+0x14/0x1c)
[ 6619.318666] (0)[1621:sh] r4:c0cc5fd8
[ 6619.318674] (0)[1621:sh][<c070d61c>] (KREE_ServSemaphoreDown) from [<c070bcf8>] (tz_service_call+0x74/0xc4)
[ 6619.318689] (0)[1621:sh][<c070bc84>] (tz_service_call) from [<c070bf30>] (KREE_TeeServiceCall+0xe8/0x290)
[ 6619.318703] (0)[1621:sh] r7:00000002 r6:00000001 r5:00000003 r4:00000000
[ 6619.318720] (0)[1621:sh][<c070be48>] (KREE_TeeServiceCall) from [<c070e418>] (entropy_thread+0xfc/0x228)
[ 6619.318734] (0)[1621:sh] r10:00000000 r9:00000000 r8:00000000 r7:c1103948
[ 6619.318751] (0)[1621:sh][<c070e31c>] (entropy_thread) from [<c0148aec>] (kthread+0x114/0x12c)
[ 6619.318765] (0)[1621:sh] r7:c070e31c r6:00000000 r5:cf703080 r4:00000000
[ 6619.318781] (0)[1621:sh][<c01489d8>] (kthread) from [<c0108730>] (ret_from_fork+0x14/0x24)
[ 6619.318999] (0)[1621:sh]Sched Debug Version: v0.11, 4.4.146 #10
[ 6619.319008] (0)[1621:sh]ktime : 6619310.281712
[ 6619.319016] (0)[1621:sh]sched_clk : 6619318.998704
[ 6619.319024] (0)[1621:sh]cpu_clk : 6619318.998857
[ 6619.319032] (0)[1621:sh]jiffies : 1895794
[ 6619.319040] (0)[1621:sh]
[ 6619.319045] (0)[1621:sh]sysctl_sched
[ 6619.319052] (0)[1621:sh] .sysctl_sched_latency : 10.000000
[ 6619.319060] (0)[1621:sh] .sysctl_sched_min_granularity : 2.250000
[ 6619.319068] (0)[1621:sh] .sysctl_sched_wakeup_granularity : 2.000000
[ 6619.319076] (0)[1621:sh] .sysctl_sched_child_runs_first : 0
[ 6619.319084] (0)[1621:sh] .sysctl_sched_features : 36667
[ 6619.319091] (0)[1621:sh] .sysctl_sched_tunable_scaling : 0 (none)
[ 6619.319099] (0)[1621:sh]
从日志里面可以看到有6个进程属于D进程状态,这几个进程一直在等待事件,导致CPU负载过高,但是实际上又没有使用CPU,所以CPU使用率并不高。
使用命令查看我们系统的D进程

为了验证上面的说话,我们需要把系统中的D进程干掉再继续查看CPU负载。
display_esd_che 这个进程看起来是和ESD静电相关,可能在屏幕死掉后才会被触发,这个是内核线程,所以我修改了内核代码,重新烧录再查看CPU负载。
0:/ # uptime
17:55:09 up 1:11, 0 users, load average: 3.09, 3.08, 3.12
可以明显看到CPU负载已经变低了,我们是4核CPU,平均负载低于4.0就属于正常。
6、排查问题需要用到的几个命令解释
6.1top 命令
top 可以查看系统CPU的状态,以百分比的形式显示出来。
Tasks: 251 total, 1 running, 243 sleeping, 0 stopped, 1 zombie
Mem: 2007724k total, 862108k used, 1145616k free, 18560k buffers
Swap: 1505788k total, 0k used, 1505788k free, 415260k cached
400%cpu 16%user 0%nice 6%sys 377%idle 0%iow 0%irq 0%sirq 0%host
PID USER PR NI VIRT RES SHR S[%CPU] %MEM TIME+ ARGS
5628 root 20 0 5.9M 3.1M 2.7M R 19.3 0.1 0:00.07 top
5614 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/u9:0]
5609 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/3:2]
5607 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/u8:2]
5590 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/u9:4]
5585 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/u8:3]
5577 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/u9:2]
5571 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/3:0]
5537 root 20 0 0 0 0 S 0.0 0.0 0:00.05 [kworker/u8:1]
5448 root 20 0 0 0 0 S 0.0 0.0 0:00.67 [kworker/3:1]
- us(user cpu time):用户态使用的cpu时间比。该值较高时,说明用户进程消耗的 CPU 时间比较多,比如,如果该值长期超过 50%,则需要对程序算法或代码等进行优化。
- sy(system cpu time):系统态使用的cpu时间比。
- ni(user nice cpu time):用做nice加权的进程分配的用户态cpu时间比
- id(idle cpu time):空闲的cpu时间比。如果该值持续为0,同时sy是us的两倍,则通常说明系统则面临着 CPU 资源的短缺。
- wa(wait):等待使用CPU的时间。
- hi(hardware irq):硬中断消耗时间
- si(software irq):软中断消耗时间
- st(steal time):虚拟机偷取时间
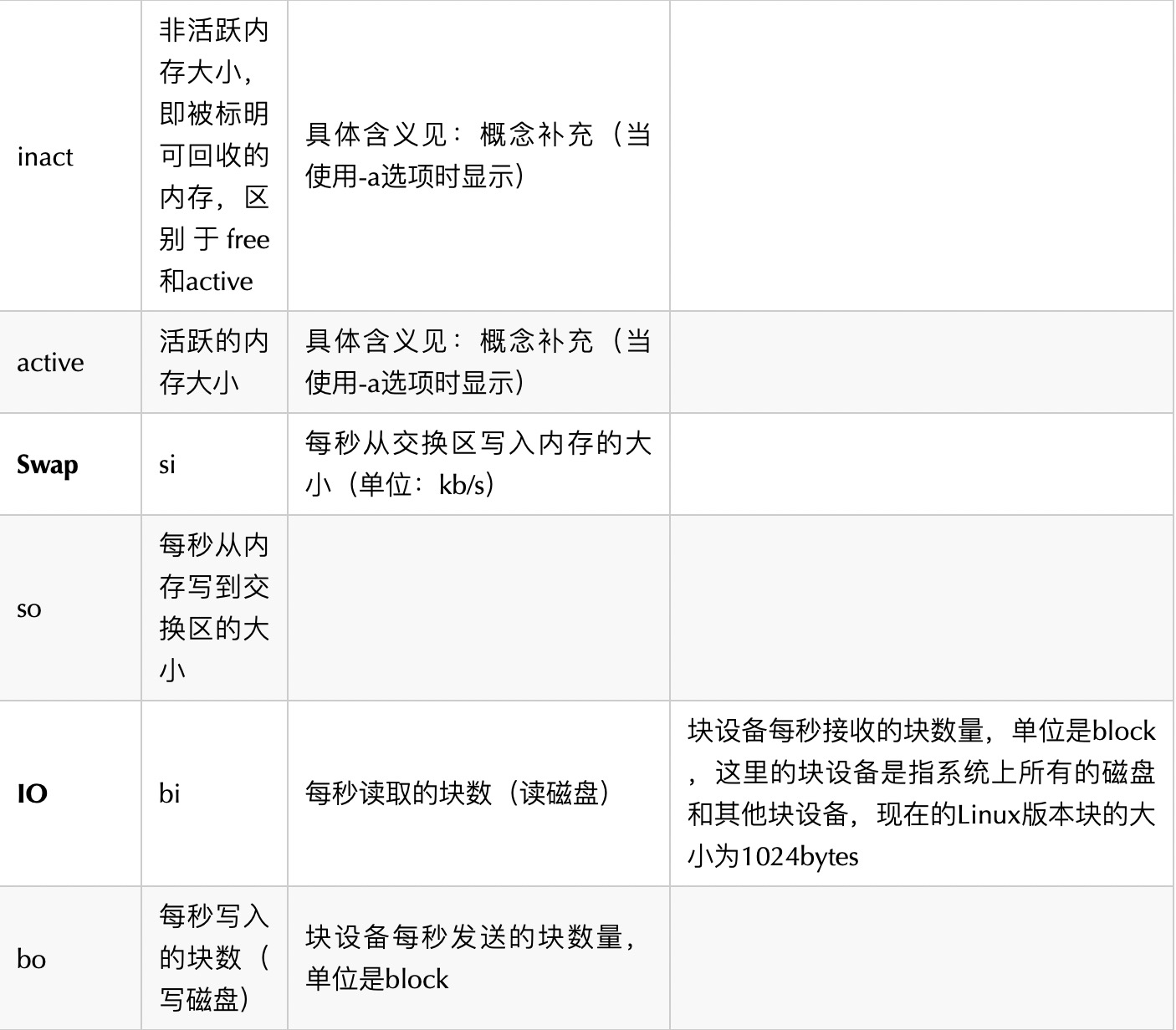
6.2vmstat 1 命令
vmstat用来检测系统的状态,包括CPU和内存,非常方便系统调试使用。
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 1146440 18564 415260 0 0 2 1 0 95 0 0 100 0
0 0 0 1146476 18564 415260 0 0 0 0 0 384 0 0 100 0
0 0 0 1146104 18564 415260 0 0 0 0 0 375 0 0 100 0
0 0 0 1146724 18564 415260 0 0 0 0 0 387 0 0 100 0
0 0 0 1146848 18564 415260 0 0 0 0 0 369 0 0 100 0

6.3pidstat 命令

这个命令在Android上是没有的,我在github上找到了个半成品,编译了出来安装到我们的设备上
https://github.com/weiqifa0/pidstat/blob/main/README.md
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
-C comm #只显示那些包含字符串(可是正则表达式)comm的命令的名字
-d #显示I/O统计信息(须内核2.6.20及以后)
PID #进程号
kB_rd/s #每秒此进程从磁盘读取的千字节数
kB_wr/s #此进程已经或者将要写入磁盘的每秒千字节数
kB_ccwr/s #由任务取消的写入磁盘的千字节数
Command #命令的名字
-h #显示所有的活动的任务
-I #在SMP环境,指出任务的CPU使用(等同于选项-u)应该被除于cpu的总数
-l #显示进程的命令名和它的参数
-p { pid [,...] | SELF | ALL } #指定线程显示其报告
-r #显示分页错误的内存利用率
When reporting statistics for individual tasks, the following values are displayed:
PID #进程号
minflt/s #每秒次缺页错误次数(minor page faults),次缺页错误次数意即虚拟内存地址映射成物理内存地址产生的page fault次数
majflt/s #每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相应的page在swap中,这样的page fault为major page fault,一般在内存使用紧张时产生
VSZ #该进程使用的虚拟内存(以kB为单位)
RSS #该进程使用的物理内存(以kB为单位)
%MEM #当前任务使用的有效内存的百分比
Command #任务的命令名
When reporting global statistics for tasks and all their children, the following values are displayed:
PID #PID号
minflt-nr #在指定的时间间隔内收集的进程和其子进程的次缺页错误次数
majflt-nr #在指定的时间间隔内收集的进程和其子进程的主缺页错误次数
Command #命令名
-s #堆栈的使用
-t #显示与所选任务相关的线程的统计数据
-T { TASK | CHILD | ALL } #指定必须监测的内容:TASK是默认的,单个任务的报告;CHILD:指定的进程和他们的子进程的全局报告,ALL:相当于TASK和CHILD
-u #报告CPU使用
When reporting statistics for individual tasks, the following values are displayed:
PID
%usr #用户层任务正在使用的CPU百分比(with or without nice priority ,NOT include time spent running a virtual processor)
%system #系统层正在执行的任务的CPU使用百分比
%guest #运行虚拟机的CPU占用百分比
%CPU #所有的使用的CPU的时间百分比
CPU #处理器数量
Command #命令
When reporting global statistics for tasks and all their children, the following values are displayed:
PID #PID号
usr-ms #在指定时间内收集的在用户层执行的进程和它的子进程占用的CPU时间(毫秒){with or without nice priority,NOT include time spent running a virtual processor)
system-ms #在指定时间内收集的在系统层执行的进程和它的子进程占用的CPU时间(毫秒)
guest-ms #花在虚拟机上的时间
Command #命令
-V #版本号
-w #报告任务切换情况
PID #PID号
cswch/s #每秒自动上下文切换
nvcswch/s #每秒非自愿的上下文切换
Command #命令
6.4 查看系统的僵尸进程
ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]'
参考:
https://blog.csdn.net/qq_23864697/article/details/110671859

