
一个问题带你了解半/全连接队列(上)原创

最近项目上遇到一个问题,运维反馈有一个服务会不定时出现健康检查异常,于是去排查了一下。问题最终发现和半连接、全连接队列大小有关,所以打算好好研究一下。
(本文涉及的Linux内核源码以v3.10为主)
一个偶发的线上问题
该项目通过WebSocket对外提供服务,每次出现异常时,都会伴随一些现象发生:
1.健康检查提示请求超时。
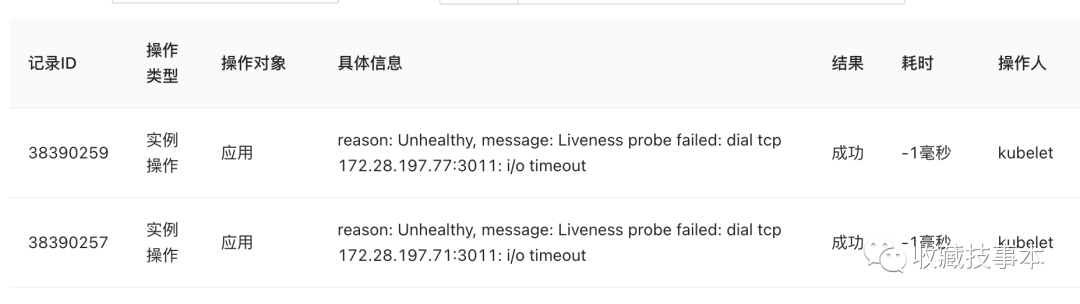
2. 通过监控发现在异常时间段,有大量状态码是101的HTTP请求,并且upstream_time时间较长。
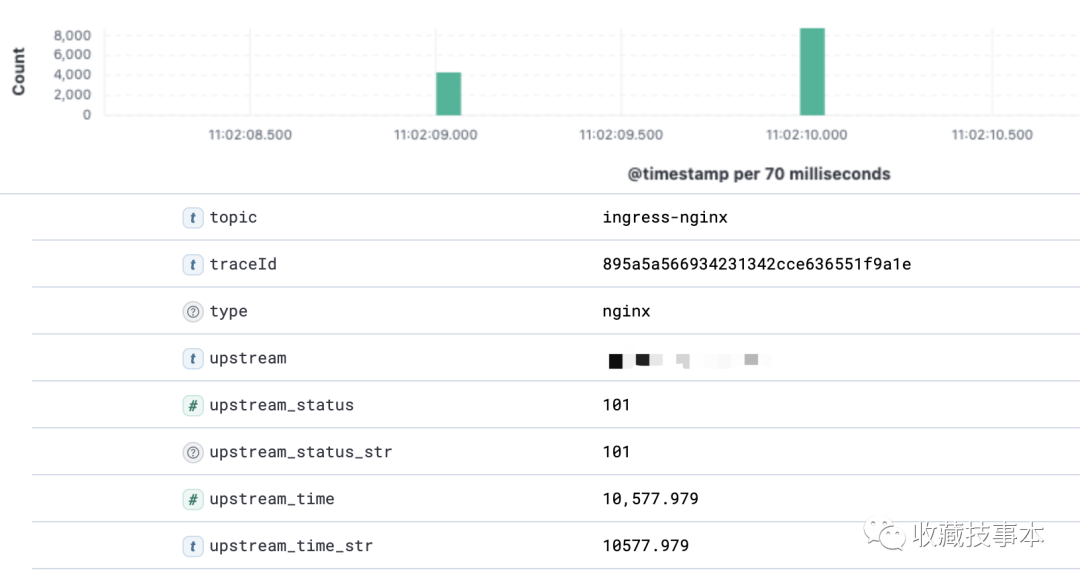
可以看出,当时有大量客户端同时进行WebSocket建连,而该项目的健康检查机制是通过TCP进行端口建连来判断服务是否健康,很大可能是实例短时无法承载大量建连导致异常。
和并发建连有关的参数,首先想到的就是半连接、全连接队列,于是登录到容器中通过netstat -s查看两个队列是否有溢出。

可以看到半连接、全连接队列均有溢出的情况,所以可以初步推断是这两个队列大小的问题,最终通过扩大全连接队列的大小也解决了这个问题。
那么,到底什么是半/全连接队列呢?
什么是半/全连接队列
在TCP三次握手进行建连的过程中,Linux内核会通过这两个队列来进行连接过程状态的缓存和维护。
半连接队列,也称SYN队列,当服务端收到客户端发来的SYN请求后,就会将该连接存储到半连接队列中,并向客户端回复SYN+ACK。
全连接队列,也称ACCEPT队列,当服务端收到ACK回复,完成三次握手后,就会将该连接从半连接队列中移除,放入全连接队列中,等待应用进程调用accept()取走连接。
对应的过程如下:
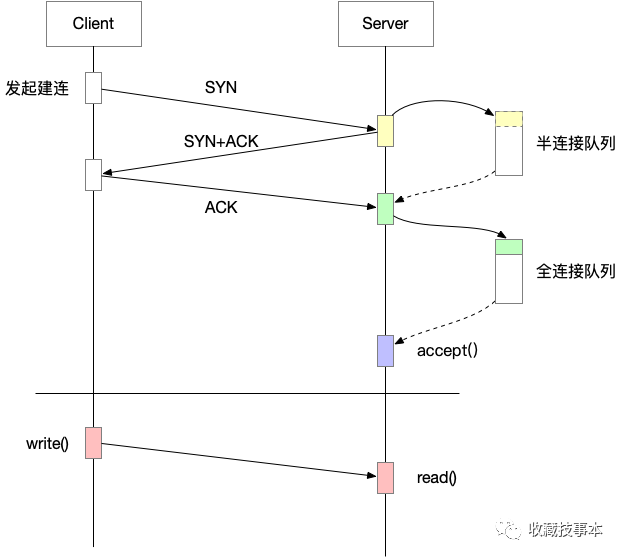
半连接队列
半连接队列大小
主要受两个参数的影响,backlog和tcp_max_syn_backlog。
在Linux内核源码中,半连接队列的空间分配在 net/core/request_socket.c 中的reqsk_queue_alloc()方法里进行,队列大小计算逻辑如下:
//其中,nr_table_entries记录最终队列大小nr_table_entries = min_t(u32, nr_table_entries, sysctl_max_syn_backlog);nr_table_entries = max_t(u32, nr_table_entries, 8);nr_table_entries = roundup_pow_of_two(nr_table_entries + 1);
队列大小受两个参数影响:
•backlog。源码中,nr_table_entries 的初始值为服务端 listen() 时传入的backlog;•sysctl_max_syn_backlog。该参数即是系统参数tcp_max_syn_backlog,通过sysctl可以查看和设置(源码中默认为256)。
队列大小会取两者的最小值,同时必须大于等于8,并将得到的结果进行 roundup_pow_of_two 运算,该操作会找到当前数值的二进制最高位数n,然后以1循环右移n次作为结果集,简单理解就是按2的倍数向上取整。
举个栗子,如果backlog设置为128,tcp_max_syn_backlog配置为64,则计算过程简化如下:
半连接队列大小 = roundup_pow_of_two(min(128, 64)) = 128半连接队列溢出的条件
在内核源码 net/ipv4/tcp_ipv4.c 的 tcp_v4_conn_request() 方法中,半连接队列有两个主要的场景:
在内核源码 net/ipv4/tcp_ipv4.c 的 tcp_v4_conn_request() 方法中,半连接队列有两个主要的场景:
-
半连接队列满了,且未开启 syn_cookies
if (inet_csk_reqsk_queue_is_full(sk) && !isn) { want_cookie = tcp_syn_flood_action(sk, skb, "TCP"); if (!want_cookie) goto drop;}(关于 syn_cookies ,我们之后单独介绍)
-
全连接队列满了,且半连接队列中有待回复 SYN+ACK 的连接
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) { NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS); goto drop;}半连接溢出的场景
1.短时间内大量并发建连,队列空间不足以存放收到的SYN包;2.全连接队列已满,半连接队列直接丢弃新的SYN包(即使当前仍有空间);3.建连时间过长,半连接队列积压导致溢出。
全连接队列
全连接队列大小
全连接队列大小的分配在 net/socket.c 中,计算逻辑如下:
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;if ((unsigned int)backlog > somaxconn) {backlog = somaxconn;}
队列大小受两个参数影响:
•backlog。由服务端 listen() 时传入的backlog决定。•sysctl_somaxconn。该参数同样为系统参数,通过sysctl可以查看和设置(源码中默认为128)。
全连接队列大小会设置为backlog和somaxconn中较小的值。
全连接队列溢出的条件
全连接队列的判断就比较简单了,在 net/ipv4/tcp_ipv4.c 中进行了判断:
if (sk_acceptq_is_full(sk))goto exit_overflow;
即在完成了三次握手,得到一个有效的synack时,如果发现全连接队列满了,则将其丢弃。
全连接队列溢出的场景
1.短时间内大量连接完成三次握手,队列放不下;2.业务层accept()速度较慢,全连接队列积压。
如何判断队列是否溢出
判断的方法很多,例如ss、netstat、/proc/net/netstat,这里主要介绍netstat,通过-s参数可以查看到所有网络统计信息。
netstat -s...//全连接队列溢出的累计次数85336 times the listen queue of a socket overflowed//半连接队列溢出的累计次数206804 SYNs to LISTEN sockets dropped...
netstat 是如何统计这些信息的?
看了一眼 netstat 的源码,也是从
/proc/net/netstat中读取的。
其中的数据来源于内核计数,相关定义在内核源码的 net/ipv4/proc.c 中,当内核发现半/全连接队列满,会相应的计数+1,对应LINUX_MIB_LISTENDROPS和LINUX_MIB_LISTENOVERFLOWS。
问题如何解决
既然知道了是两个队列均有溢出,那么就先从队列大小看起。
前文有提到,半/全连接队列大小与几个参数有关,tcp_max_syn_backlog、somaxconn和端口监听时传入的backlog。
先来看看系统参数:

可以看到系统参数配置中,半/全连接队列的大小均是配置为4096,对于我们的服务来说并不小。
那么再看代码中传入的backlog,该服务是前端Node实现的连接层,listen时没有传入backlog参数,源码中会默认设置为511。
此时,
半连接队列大小 = roundup_pow_of_two(min(4096, 511)) = 512
全连接队列大小 = min(4096, 511) = 511
Socket 中两个队列的实际大小都偏小。
最终我们将backlog参数设置为与系统一致的4096后,就没有再出现队列溢出的问题。

当两个队列均没有溢出时,
netstat的统计并不会有这两个结果,想要进一步确认也可以通过/proc/net/stat进行判断。
总结
如果了解半/全连接及基础的溢出判断方法,那么对于这一类问题的定位还是比较好解决的,先通过 netstat -s看半/全连接队列是否有溢出,再通过系统参数tcp_max_syn_backlog、somaxconn和监听参数backlog入参判断两个队列的实际大小是否合理。
但是,实际上遇到连接队列溢出的问题时并不好判断,本文更多通过一个简单的线上问题介绍半/全连接队列的概念。
想要了解更多半/全连接队列的问题,可以期待之后的实战及周边知识文章,持续更新中~
我之前也遇到过一个类似的问题,大家可以同步参考

