
一次 Kafka 导致的 Sentry 无法处理 MiniDump 问题分析原创
业务反馈部署的 Sentry 系统处理 Electron 的 MiniDump 信息出现异常,界面提示。
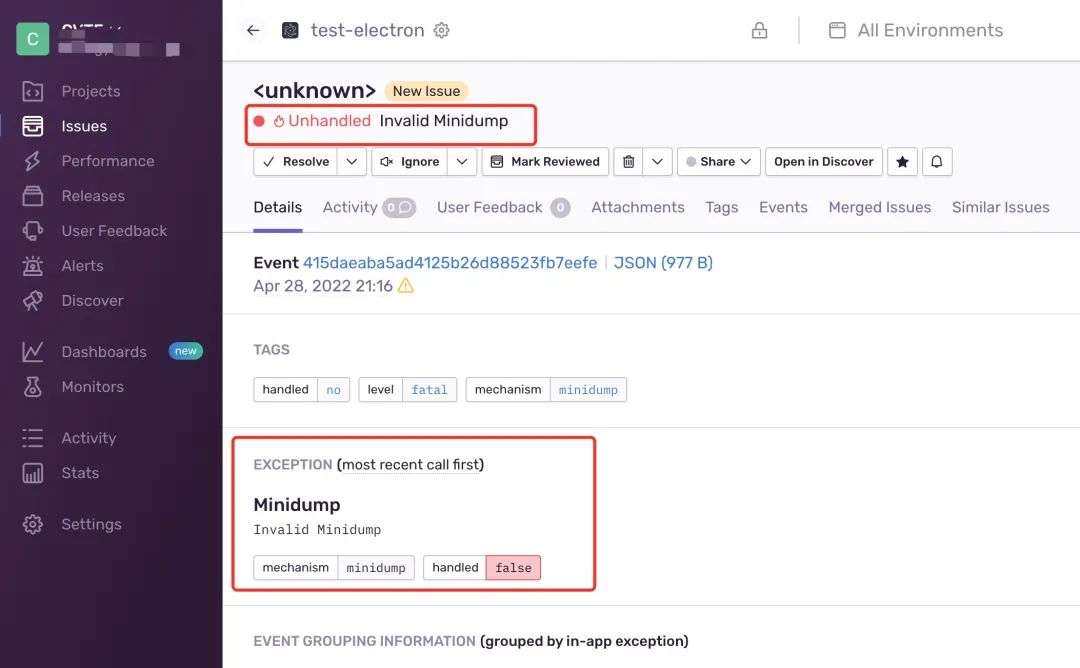
于是做了一次分析,记录如下。
Sentry 是什么
Sentry 是一个跨平台的应用错误跟踪系统,专注于错误报告,支持 web 前后端、移动应用以及游戏,此次反馈问题的是 Windows PC 端 Electron 客户端。官网:https://sentry.io/
做过客户端的通信可能对 MiniDump 比较清楚,拿 Windows 为例,每次 Windows 操作系统意外遇到错误时(例如在“蓝屏死机”崩溃期间)都会生成一个小文件。该文件包含有关错误性质的信息,例如崩溃之前和崩溃期间的系统状态。其中包含诸如运行服务和流程之类的信息,以及每个服务所使用的资源。除了系统,应用 crash 也是可以生成 MiniDump 文件的,本例中就是一个 Electron 的客户端程序生成的 MiniDump。
初步分析
遇事不决先抓包,因为是 HTTPS 的请求包,所以这里需要特殊处理。
SSLKEYLOGFILE=/Users/arthur/keylog.txt
curl -X POST \
'https://o0.ingest.sentry.io/api/0/minidump/?sentry_key=examplePublicKey' \
-F upload_file_minidump=@mini.dmp
发现请求是没有什么问题的,HTTP 放回了正确的结果和对应的 EventId
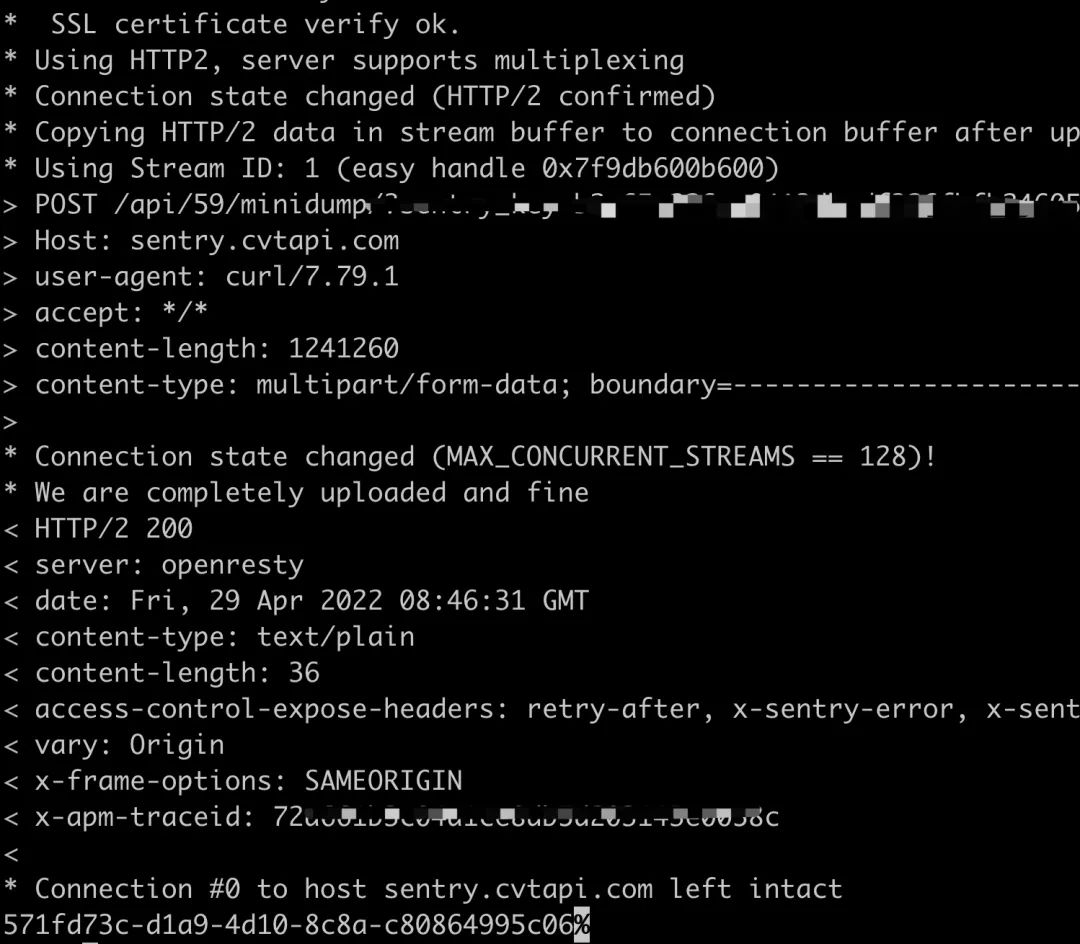
出问题的同学反馈,当上传的 MiniDump 文件是小文件时,比如 300k 没有任何问题。当上传一个 1M 多的文件时,就会出现 Invalid Minidump 异常,怀疑是 sentry 后端处理文件上传的时候有一些问题。
但是这个系统完全不熟,只能硬分析,找到它对应的 Nginx 看下请求跑到了哪里。通过 nginx -T 查看当前的 Nginx 配置文件
server {
listen 8080;
proxy_redirect off;
proxy_set_header Host $host;
location /api/store/ {
proxy_pass http://relay;
}
location ~ ^/api/[1-9]\d*/ {
proxy_pass http://relay;
}
location / {
proxy_pass http://sentry;
}
}
可以看到请求去到了 relay 这个 upstream 上游服务中,这个服务是一个用 rust 写的服务,先搜索了一下处理文件上传部分的逻辑。
发现大小受限于 max_attachment_size 参数。

max_attachment_size 这个参数的默认值是 50MB
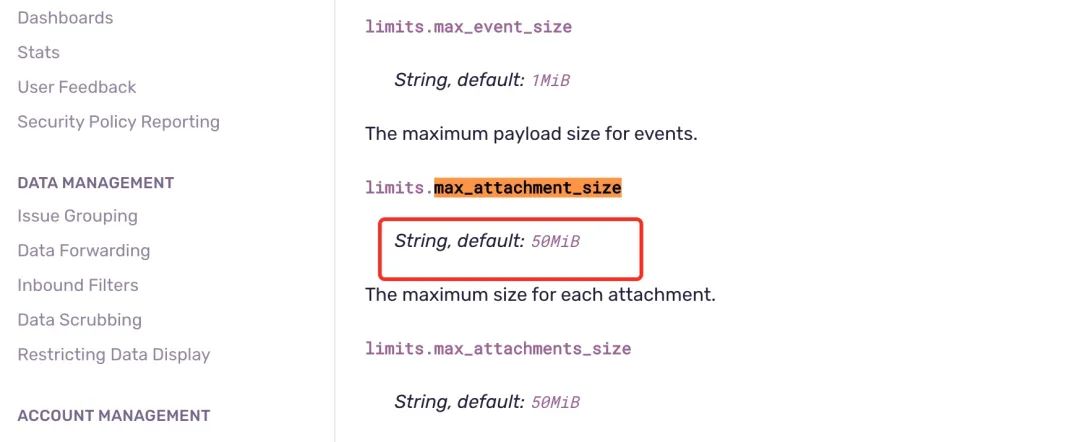
讲道理,我们没有修改默认值应该不会触发文件上传这里的校验错误,出问题的应该是在后续的逻辑里,也就是文件上传完以后,继续处理的部分发送数据到 kafka 交给后面的服务继续处理。
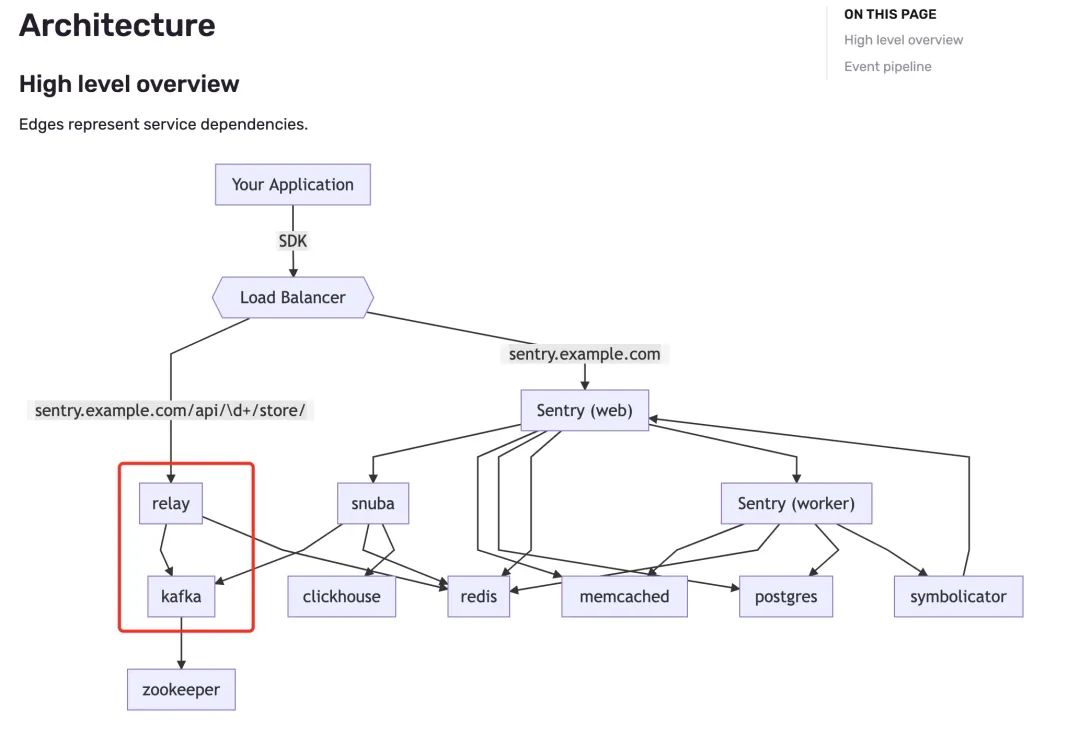
艰难的找到了 relay 打印的日志
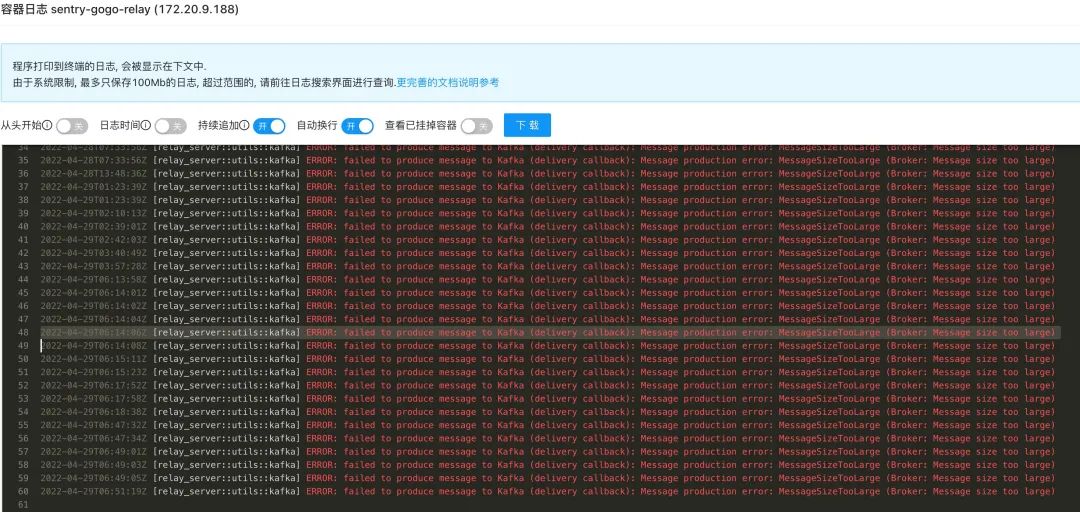
可以看到 rust 打印提示发送到 kafka 的消息过大,对应的代码如下。
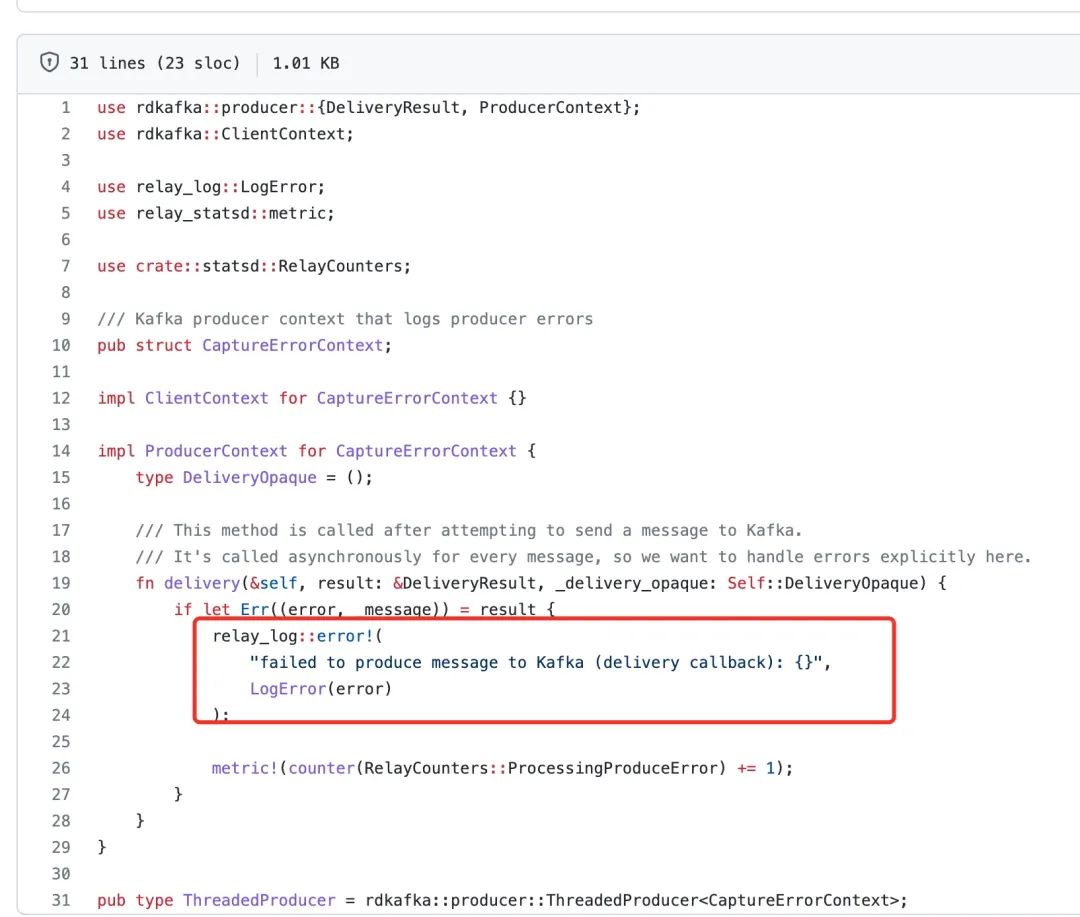
在 relay 服务 tcpdump 抓包同步确认,因为不止我一个人在使用,但是如何找到对应的包呢?
这里有一个小技巧,wireshark 里可以过滤包体里的内容,因为我发现 Minidump 文件的文件头有一个魔数 "MDMP"
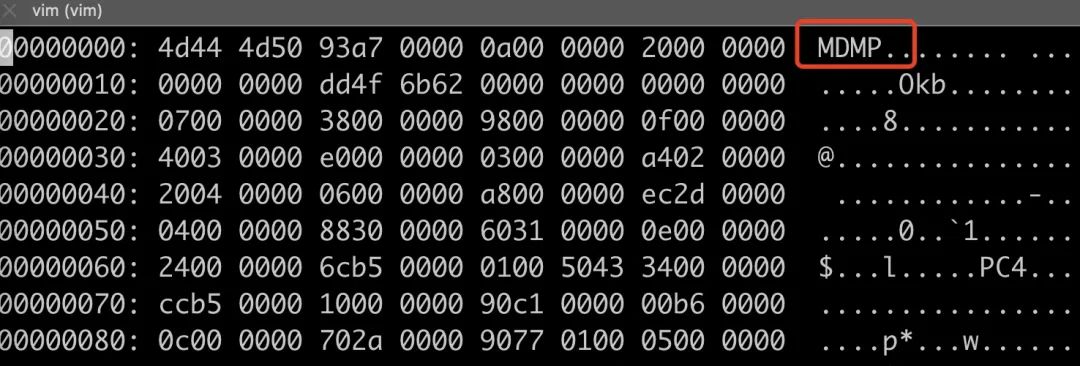
于是就可以过滤了,在 wireshark 中输入 frame contains "MDMP",就可以找到对应的kafka 发送那一条的记录。

然后使用 follow tcp stream 就可以看到这个包发送的全过程。
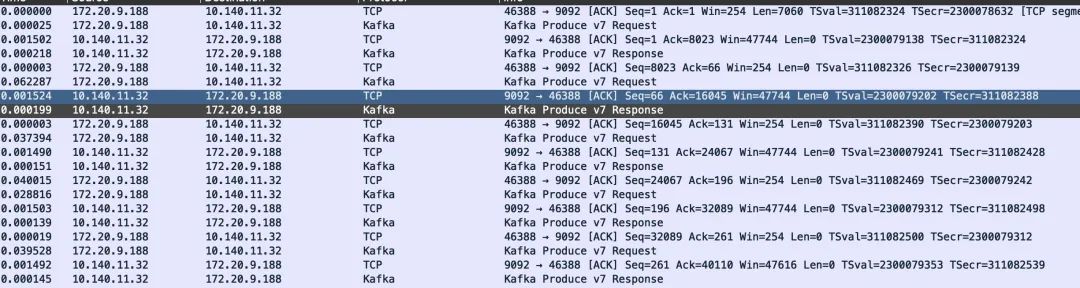
这里有非常多的包,如何快速定位到 kafka 可能发生错误的包呢,wireshark 足够智能可以分析 Kakfa 的包,这里有一个骚操作,kafka 的头部里都有两字节表示的 error 字段,如果无异常,这个值就等于 0
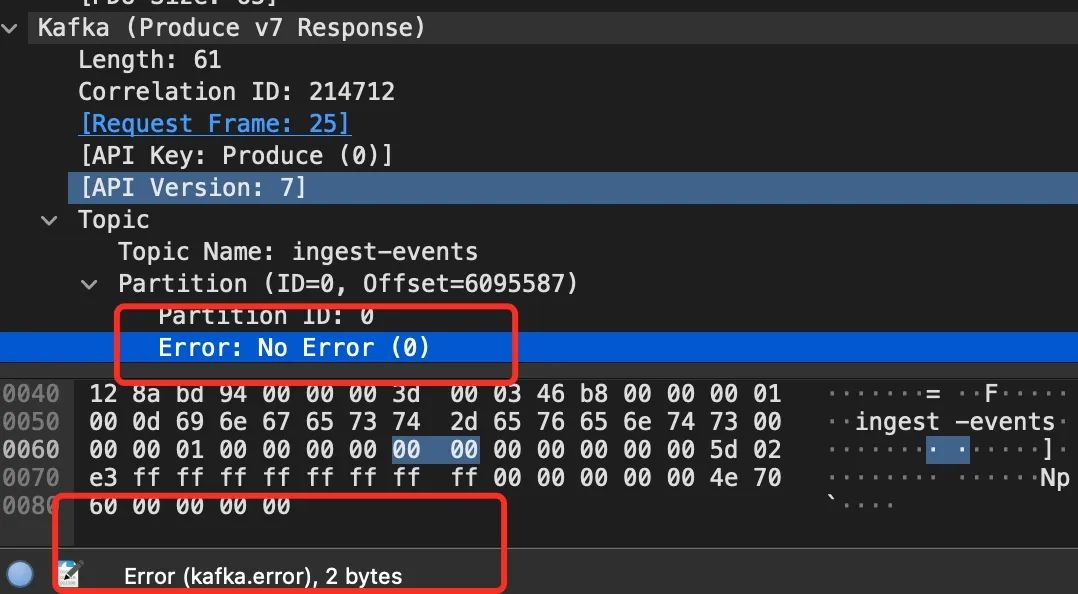
这里我们想看非 0 的,就可以这样来过滤了。
tcp.stream eq 2 and kafka.error != 0

这下就可以真的确认,我们的那个 MiniDump 的包,确实在发送到 kafka 的时候发生了错误。
后面的 MiniDump 解析的服务(一个 python 的服务)解析文件发现文件不完整,就解析失败了。
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/sentry/tasks/store.py",
line 255, in _do_symbolicate_event
symbolicated_data = symbolication_function(data)
File "/usr/local/lib/python3.6/site-packages/sentry/lang/native/processing.py",
line 259, in process_minidump
response = symbolicator.process_minidump(minidump.data)
File "/usr/local/lib/python3.6/site-packages/sentry/attachments/base.py",
line 61, in data
self._data = self._cache.get_data(self)
File "/usr/local/lib/python3.6/site-packages/sentry/attachments/base.py",
line 160, in get_data
raise MissingAttachmentChunks()
sentry.attachments.base.MissingAttachmentChunks
通过跟运维的同学确认,kafka 集群是自己新建的,消息体的大小使用的是 kakfa 的默认值 1M(message.max.bytes),于是动态调整这个值到 50M,然后再次测试,已经成功。
至此问题解决。
后记
这个项目啥语言都有,rust、python 等等,开源大杂烩。好了我滚回去学 rust 了。

