
#看视频聊个天5#:盘一盘那些“崩溃”过的互联网企业原创
宕机
说到这个话题,大部分工程师的第一反应会是什么呢🙃
大概运维的反应是最大的吧

全球几乎每年都发生过大规模宕机事故
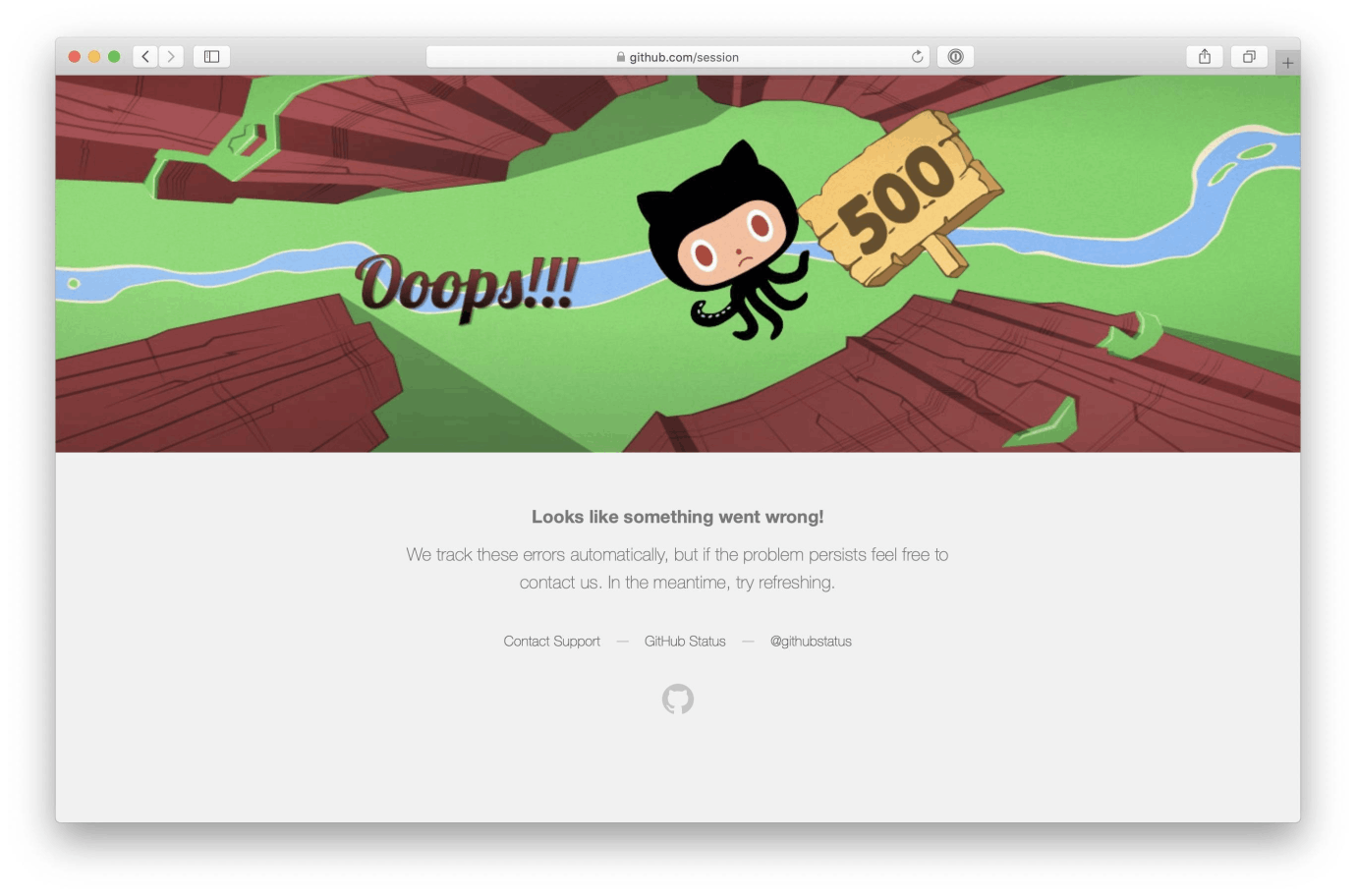
今年3月,由于数据库的问题,GitHub 经历了多起宕机事件,导致平台的服务降级, 影响了许多用户的使用。
在过去的几年里,GitHub 已经进行了许多优化,例如添加集群以支持平台的增长、对主数据库进行分区等,但这些改进工作并不能一劳永逸,一直到现在他们仍在积极地解决这个问题。
随着平台的不断发展,GitHub 将一直努力扩展基础设施,包括对数据库进行分片和扩展硬件。
随着互联网的繁荣,全球范围内各行业服务均开始转向线上。
一些关键行业的线上服务深刻影响着各国人民日常生活的正常进行。
提供关键服务的信息系统一旦出现宕机,将给社会造成巨大影响。但由于用户基数不断增大、功能需求逐渐多元化,导致各类信息系统功能范围不断扩大,系统架构逐渐复杂,存在大量潜在风险,导致事故频发。
2021年,全球发生多起重大宕机事件,涉及全球范围内多个国家的电商、交通、社交媒体、金融等多个领域。
国内关心的比较多的哪些宕机(热门)事件
说到国内大家印象比较深的事件大多跟某某热门事件挂上钩。
比如,春晚发红包,春节不宕机保卫战14亿人百亿红包和加班的工程师。

比如,某平时日常官宣事件。
比如,各路电商节大比拼。
比如,春节、节假日抢火车票。
比如,……

发生了几次宕机事件后,吃瓜群众们对此表示已经习惯,甚至很多人认为,如果明星突然宣布结婚或分手微博还没崩,只能证明该明星还不够火。
大概微博宕机也是事件热度标尺吧。
B站链接
链接 2021年度宕机事件盘点https://www.bilibili.com/video/BV1P3411T7nT/
欢迎点赞评论关注HeapDump性能社区B站账号
视频号


欢迎点赞评论关注HeapDump性能社区视频号
以上所有视频,留言都有机会获得社区周边小礼品噢!
互联网技术发展到了 2022 年,理论上来说是可以做到“永不宕机”的。
但过去的 2021 年,宕机事故看起来貌似也不少。
随着“国民级应用”增多,大家对技术的依赖程度越来越高,面临的风险比以往任何时候都多。
疫情之下,万物皆可“云”。
上班族“云办公”,学生党“云上课”,美食爱好者“云下厨”……
而突如其来的流量暴增让各大线上平台上演“连环崩”,系统崩溃,加载错误时常发生。
- 访问量大了,理论上不会崩溃,只是理论上。
- 访问量大了,你的内存满了、TCP连接到顶了(比如time_wait太多,无法接受新连接)、CPU已经忙不过来了——这一切的理论后果是处理速度慢了,或者直接拒绝新的服务请求。
- 但如果你的服务器代码有缺陷,比如内存无法分配,抛出异常,而你没有处理这异常,会造成进程的退出——崩溃;
- 或者无法建立新的TCP连接,你又没有处理这种异常——崩溃;
- 磁盘满了——崩溃……
- 程序一大这种细小的问题会多如牛毛。
- 甚至你依赖的基础软件,如JVM,内存不足也可能导致崩溃。
- 虽然有交换分区的存在,但也只是延迟了内存分配失败的时间,但此时性能已经急剧下降,与崩溃无异——完全没响应了。

总之,宕机的常见原因也还有很多细节原因,比如,错误的环境配置、陷于死循环的错误程序、数据库索引缺失、数据库丢失等都会无端消耗大量服务器CPU、内存等资源,从而导致的服务器死机宕机等。
那么如何做好系统稳定性保障呢?
由于软件系统在本质上来说具备复杂性,其中任何一个环节出现问题都可能造成系统缺陷的引入,稳定性保障工作也必然需要覆盖整个软件生命周期。
当前大型互联网系统架构日趋复杂,稳定性风险也在升高。
宕机影响的不仅是内部用户,连带还会影响到客户和合作伙伴的收入、信誉和生产力等各个方面。
如何保证这些数据的安全和稳定是现在IT人员都关心的问题。
本期话题·盘一盘那些“崩溃”过的互联网企业
#国内宕机事件
#国际宕机事件
#云计算相关服务提供商
#你经历过哪些宕机事件
#半夜宕机如何处理
#
可能也许大概,每时每刻都在发生宕机。
我们大部分人的生活已经与互联网网络连接正在一起,连接的另一面就是24小时不间断的数据。
最后

祝不宕机吧!🚀
欢迎在话题区讨论留言
小伙伴们虎年有虎劲
🎁快来视频号或者B站点赞评论留言~

