
因索引合并导致的MySQL死锁分析与解决实战!转载
前言:
死锁问题是大家在工作中经常遇到的问题,如何解决sql中的死锁问题,如何定位sql中是哪个代码片段导致,通过分析死锁来解决mysql中的死锁问题~
正文:
生产上偶现这段代码会出现死锁,死锁日志如下。
*** (1) TRANSACTION:
TRANSACTION 424487272, ACTIVE 0 sec fetching rows
mysql tables in use 3, locked 3
LOCK WAIT 6 lock struct(s), heap size 1184, 4 row lock(s)
MySQL thread id 3205005, OS thread handle 0x7f39c21c8700, query id 567774892 10.14.34.30 finance Searching rows for update
update repay_plan_info_1
SET actual_pay_period_amount = 38027,
actual_pay_principal_amount = 36015,
actual_pay_interest_amount = 1980,
actual_pay_fee = 0,
actual_pay_fine = 32,
actual_discount_amount = 0,
repay_status = 'PAYOFF',
repay_type = 'OVERDUE',
actual_repay_time = '2019-08-12 15:48:15.025'
WHERE ( user_id = '938467411690006528'
and loan_order_no = 'LN201907120655461690006528458116'
and seq_no = 1
and repay_status <> 'PAYOFF' )
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3680 page no 30 n bits 136 index `PRIMARY` of table `db_loan_core_2`.`repay_plan_info_1` trx id 424487272 lock_mode X locks rec but not gap waiting
Record lock, heap no 64 PHYSICAL RECORD: n_fields 33; compact format; info bits 0
0: len 8; hex 800000000000051e; asc ;;
1: len 6; hex 0000193d35df; asc =5 ;;
2: len 7; hex 06000001d402e7; asc ;;
3: len 30; hex 323031393036313332303532303634323936303534323130353730303030; asc 201906132052064296054210570000; (total 32 bytes);
4: len 30; hex 4c4e32303139303631333031323934303136393030303635323831373534; asc LN2019061301294016900065281754; (total 32 bytes);
5: len 4; hex 80000002; asc ;;
6: len 18; hex 393338343637343131363930303036353238; asc 938467411690006528;;
7: len 4; hex 80000003; asc ;;
8: len 4; hex 80000258; asc X;;
9: len 3; hex 646179; asc day;;
10: SQL NULL;
11: SQL NULL;
12: len 8; hex 8000000000005106; asc Q ;;
13: len 8; hex 8000000000000000; asc ;;
14: len 8; hex 8000000000004e1e; asc N ;;
15: len 8; hex 8000000000000000; asc ;;
16: len 8; hex 80000000000002d6; asc ;;
17: len 8; hex 8000000000000000; asc ;;
18: len 8; hex 8000000000000000; asc ;;
19: len 8; hex 8000000000000000; asc ;;
20: len 8; hex 8000000000000012; asc ;;
21: len 8; hex 8000000000000000; asc ;;
22: len 8; hex 8000000000000000; asc ;;
23: len 8; hex 8000000000000000; asc ;;
24: len 8; hex 3230313930383131; asc 20190811;;
25: len 7; hex 4f564552445545; asc OVERDUE;;
26: SQL NULL;
27: len 1; hex 59; asc Y;;
28: SQL NULL;
29: len 5; hex 99a35a1768; asc Z h;;
30: len 4; hex 5d503dd8; asc ]P= ;;
31: SQL NULL;
32: len 5; hex 99a3d80281; asc ;;
*** (2) TRANSACTION:
TRANSACTION 424487271, ACTIVE 0 sec fetching rows
mysql tables in use 3, locked 3
5 lock struct(s), heap size 1184, 3 row lock(s)
MySQL thread id 3204980, OS thread handle 0x7f3db0cf6700, query id 567774893 10.14.34.30 finance Searching rows for update
update repay_plan_info_1
SET actual_pay_period_amount = 20742,
actual_pay_principal_amount = 19998,
actual_pay_interest_amount = 726,
actual_pay_fee = 0,
actual_pay_fine = 18,
actual_discount_amount = 0,
repay_status = 'PAYOFF',
repay_type = 'OVERDUE',
actual_repay_time = '2019-08-12 15:48:15.025'
WHERE ( user_id = '938467411690006528'
and loan_order_no = 'LN201906130129401690006528175485'
and seq_no = 2
and repay_status <> 'PAYOFF' )
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 3680 page no 30 n bits 136 index `PRIMARY` of table `db_loan_core_2`.`repay_plan_info_1` trx id 424487271 lock_mode X locks rec but not gap
Record lock, heap no 64 PHYSICAL RECORD: n_fields 33; compact format; info bits 0
0: len 8; hex 800000000000051e; asc ;;
1: len 6; hex 0000193d35df; asc =5 ;;
2: len 7; hex 06000001d402e7; asc ;;
3: len 30; hex 323031393036313332303532303634323936303534323130353730303030; asc 201906132052064296054210570000; (total 32 bytes);
4: len 30; hex 4c4e32303139303631333031323934303136393030303635323831373534; asc LN2019061301294016900065281754; (total 32 bytes);
5: len 4; hex 80000002; asc ;;
6: len 18; hex 393338343637343131363930303036353238; asc 938467411690006528;;
7: len 4; hex 80000003; asc ;;
8: len 4; hex 80000258; asc X;;
9: len 3; hex 646179; asc day;;
10: SQL NULL;
11: SQL NULL;
12: len 8; hex 8000000000005106; asc Q ;;
13: len 8; hex 8000000000000000; asc ;;
14: len 8; hex 8000000000004e1e; asc N ;;
15: len 8; hex 8000000000000000; asc ;;
16: len 8; hex 80000000000002d6; asc ;;
17: len 8; hex 8000000000000000; asc ;;
18: len 8; hex 8000000000000000; asc ;;
19: len 8; hex 8000000000000000; asc ;;
20: len 8; hex 8000000000000012; asc ;;
21: len 8; hex 8000000000000000; asc ;;
22: len 8; hex 8000000000000000; asc ;;
23: len 8; hex 8000000000000000; asc ;;
24: len 8; hex 3230313930383131; asc 20190811;;
25: len 7; hex 4f564552445545; asc OVERDUE;;
26: SQL NULL;
27: len 1; hex 59; asc Y;;
28: SQL NULL;
29: len 5; hex 99a35a1768; asc Z h;;
30: len 4; hex 5d503dd8; asc ]P= ;;
31: SQL NULL;
32: len 5; hex 99a3d80281; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3680 page no 137 n bits 464 index `idx_user_id` of table `db_loan_core_2`.`repay_plan_info_1` trx id 424487271 lock_mode X locks rec but not gap waiting
Record lock, heap no 161 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 18; hex 393338343637343131363930303036353238; asc 938467411690006528;;
1: len 8; hex 800000000000051e; asc ;;
*** WE ROLL BACK TRANSACTION (2)
代码定位
按照死锁的update sql语句,我们先定位这个死锁SQL中代码是哪个代码片段导致的。后面我们定位到,是如下代码片段导致的:
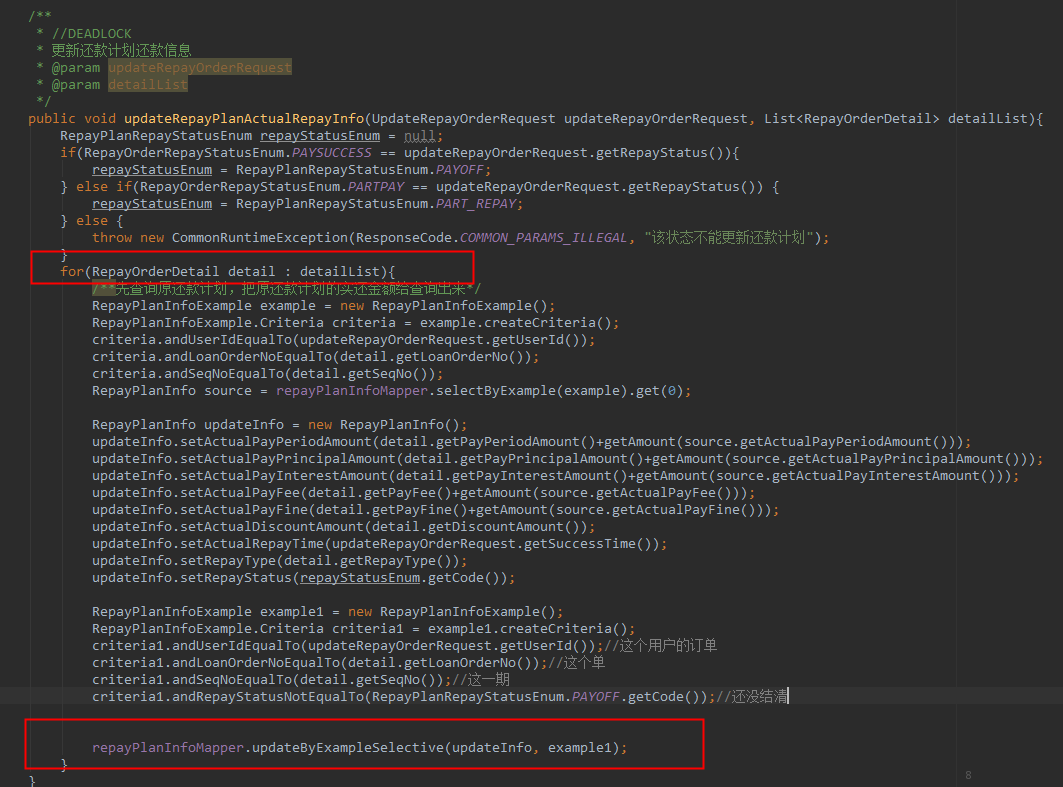
实际上一眼看上去,这段代码有一个很典型的业务开发场景问题:开启事务在for循环写SQL。
注:这在实际的问题定位过程中并不容易,因为死锁日志并不能反向直接定位到方法的对账、线程名等,如果一个库被多个服务同时连接,甚至定位是哪个服务都不容易。
死锁分析(1)——猜测可能消息重发
按照死锁的必要条件:循环等待条件。即 T1事务应该持有了某把锁L1,然后去申请锁L2,而这时候发现T2事务已经持有了L2,而T2事务又去申请L1,这时候就发生循环等待而死锁。
一开始会猜测,是否我们更新表的顺序在两个事务里面是反方向的,即T1事务更新ta、tb表,锁ta表的记录,准备去拿tb表记录的锁;T2事务更新tb、ta表,锁了tb记录准备去拿ta的锁,这是比较常见的死锁情况。但是从SQL看,我们死锁的SQL是同一张表的,即同一张表不同的记录。
而且从死锁日志中可以发现,两个死锁的SQL居然是“一样”的,也就是说是“同一条”SQL/同一段代码(不同的where条件参数)导致的,。即上图代码中的这段for循环更新还款计划的代码。
但是光这段For循环来看,如果要发生死锁,有可能同一批请求,更新记录的顺序是反过来的,然后又并发执行的时候,可能出现。
一开始会猜测上游触发了两条一样的请求(我们这个场景是MQ重发),出现了并发,两条消息分在两个事务中并发执行。但是如果是MQ导致的原因,FOR循环更新的记录顺序是一样的,一样的顺序意味着一样的一样的加锁顺序,一样的加锁顺序意味着最多出现获取锁超时,不会满足【循环等待】的条件,不可能死锁。所以排除MQ重发的可能。
死锁分析(2)
仔细阅读出现问题的两条SQL,可以发现一个规律,这里面都带一个相同的where条件:userId= 938467411690006528,意味着这两个事务的请求都来自一个用户发起的,然后从actual_repay_time = '2019-08-12 15:48:15.025' 来看,的确是瞬间一起执行的两个事务,但是却是不一样的两个借据。对应到真实的用户的操作上,用户的确有可能发起两个借据的同时还款,例如同时结清多笔借据。
通过出现了几次的死锁,总结出了其相同的规律:每次的死锁SQL条件都有一样的特征——相同的userId+不同的借据+并发。基本可以断定,相同的用户在同时还款多笔的时候,可能会发现死锁,但很可惜,测试环境、生产环境我们模拟这个场景都无法复现死锁的情况。
只能靠技术手段分析原因了。
思路:这是了两个完全不同的借据环境计划,操作完全不一样的数据记录,为什么会发生死锁呢?是不是锁的不是行而是锁了表?
死锁日志分析
从事务1中的
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3680 page no 30 n bits 136 index `PRIMARY` of table `db_loan_core_2`.`repay_plan_info_1` trx id 424487272 lock_mode X locks rec but not gap waiting
事务2中的
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 3680 page no 30 n bits 136 index `PRIMARY` of table `db_loan_core_2`.`repay_plan_info_1` trx id 424487271 lock_mode X locks rec but not gap
从RECORD LOCKS的标示可知,的确锁的是行锁不是表锁。且从”but not gap”的信息来看,也不存在间隙锁(注:我们线上隔离级别是read committed,本来就不存在间隙锁问题)。所以锁的位置应该的确是我们操作的行记录才对。但是非常奇怪的是,实际业务上操作的记录的确是完全隔离的(因为是不同的借据,记录没有交集),为什么会冲突呢?
再细节阅读死锁日志从事务2中获取到了一点线索:
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3680 page no 137 n bits 464 index `idx_user_id` of table `db_loan_core_2`.`repay_plan_info_1` trx id 424487271 lock_mode X locks rec but not gap waiting Record lock, heap no 161 PHYSICAL RECORD: n_fields 2; compact format; info bits 0这个索引很奇怪,是userid的索引?
分析之前,我们先看先看锁持有情况:
T1等待锁space id 3680 page no 30
T2持有锁space id 3680 page no 30
T2等待锁space id 3680 page no 137
最后回滚了T2
可以推断space id 3680 page no 137应该被T1持有了,但是日志中没有显示出来。
- 3680 page no 30这个锁是一个主键索引PRIMARY导致的,实际上我们没有用到我们的自增主键,是非聚集索引,所以这是先锁的非主键索引最后找到的主键去加锁。
- 3680 page no 137这个锁就比较奇怪了,他锁在了idx_user_id这个索引,这个索引是加在userId上的,也就是T2他正在尝试锁所有这个用户的还款计划的记录!
如果是这样,问题就解释通了:
T1: 锁了某行记录X(具体怎么锁的,从死锁日志中未能获取),然后准备去获取LN201907120655461690006528458116,SEQ=1的记录的锁。
T2: 锁了LN201907120655461690006528458116,SEQ=1的锁,而他想去锁所有userId=938467411690006528的记录,这里面肯定包含了记录X,所以他无法获得X的锁。
这样就造成死锁了,因为X已经被T1持有了,而T1又在等T2释放LN201907120655461690006528458116,SEQ=1这个锁。
至于为什么T2明明准备操作LN201906130129401690006528175485,SEQ=2的记录,却之前持有了LN201907120655461690006528458116,SEQ=1的锁,大概率不是因为之前的SQL真的操作LN201907120655461690006528458116,SEQ=1的记录,也是因为他之前本想持有别的记录(从锁的详细信息上猜,可能是LN2019061301294016900065281754的相关记录),但是因为这个idx_user_id的索引问题,顺带锁着了LN201907120655461690006528458116,SEQ=1,因为都属于一个userId。
所以从时间线上分析,顺序应该是:
1、T1锁了某记录X
2、T2锁了某记录Y(从hold this lock的日志细节中推断,是LN2019061301294016900065281754),然后准备锁LN201906130129401690006528175485,SEQ=2,这时候的这条SQL触发了idx_user_id,连带一起锁锁住了LN201907120655461690006528458116,SEQ=1并准备锁其它同用户记录
3、T1 执行下一条sql,准备获取LN201907120655461690006528458116,SEQ=1的锁,发现被T2获取了,等待。
4、T2在锁其它记录的过程中发现了X,但是锁不住,发现X被T1持有。而自己又持有了LN201907120655461690006528458116,SEQ=1这行记录的锁。
这时候循环等待,死锁!
所以根源是为什么SQL会使用idx_user_id这个索引呢?
索引信息
RIMARY KEY (`id`),
UNIQUE KEY `uk_repay_order` (`loan_order_no`,`seq_no`),
UNIQUE KEY `uk_repay_plan_no` (`repay_plan_no`),
KEY `idx_user_id` (`user_id`),
KEY `idx_create_time` (`create_time`)从我们SQL上看loan_order_no+seq_no是唯一主键,应该肯定能唯一定位一行记录,索引应该使用这个是最优的才对。
这时候我们去看T2的那条SQL的执行计划得知:其没有使用索引uk_repay_order,而使用了一个type: index_merge,走的索引是uk_repay_order_,idx_user_id,也就是他居然两个索引同时生效了。

解决方案
实际上,由于index merge,客观上就会增加update语句的死锁可能性,相关bug连接如下:https://bugs.mysql.com/bug.php?id=77209
而其实如果出现了index merge,在很多情况下意味着我们索引的建立可能并不合理。
解决方案有两个:
1、建立联合索引,以避免index merge,让联合索引生效则不会因此锁住所有该userId的记录
2、取消index merge的优化
遗留问题
什么时候才会触发index merge,这个在文档中似乎并没有很明确的触发实际,从这些死锁的SQL来看,某些SQL在事后explain的时候,并没有走index merge,而有些却走了。从本案例来看,事务1的SQL并没有走index merge,但是事务2这样类似的SQL却走了。
更锁思考:
关于sql死锁的问题会经常出现在我们工作中,大家可以根据以下文章来提高实战能力!
MySQL 死锁套路:一次诡异的批量插入死锁问题分析
手把手教你分析MySQL死锁问题
最后感谢薛定谔的风口猪老师的实战分享~


