
Kafka的生产者优秀架构设计原创
前言
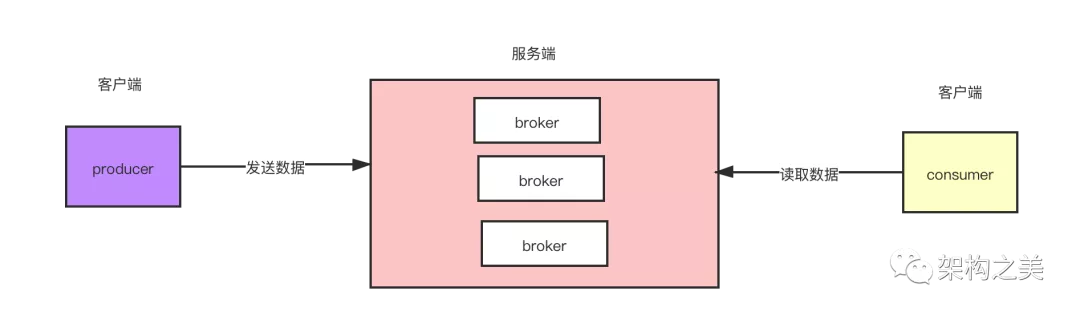
Kafka 是一个高吞吐量的分布式的发布订阅消息系统,在全世界都很流行,在大数据项目里面使用尤其频繁。笔者看过多个大数据开源产品的源码,感觉 Kafka 的源码是其中质量比较上乘的一个,这得益于作者高超的编码水平和高超的架构设计能力。
Kafka 的核心源码分为两部分:客户端源码和服务端源码,客户端又分为生产者和消费者,而个人认为 Kafka 的源码里面生产者的源码技术含量最高,所以今天给大家剖析 Kafka 的生产者的架构设计,Kafka 是一个飞速发展的消息系统,其架构也在一直演进中,我们今天分析的 Kafka 的版本是比较成熟稳定的 Kafka1.0.0 版本源码。
生产者流程概述
先给大家介绍一下生产者的大概的运行的流程。
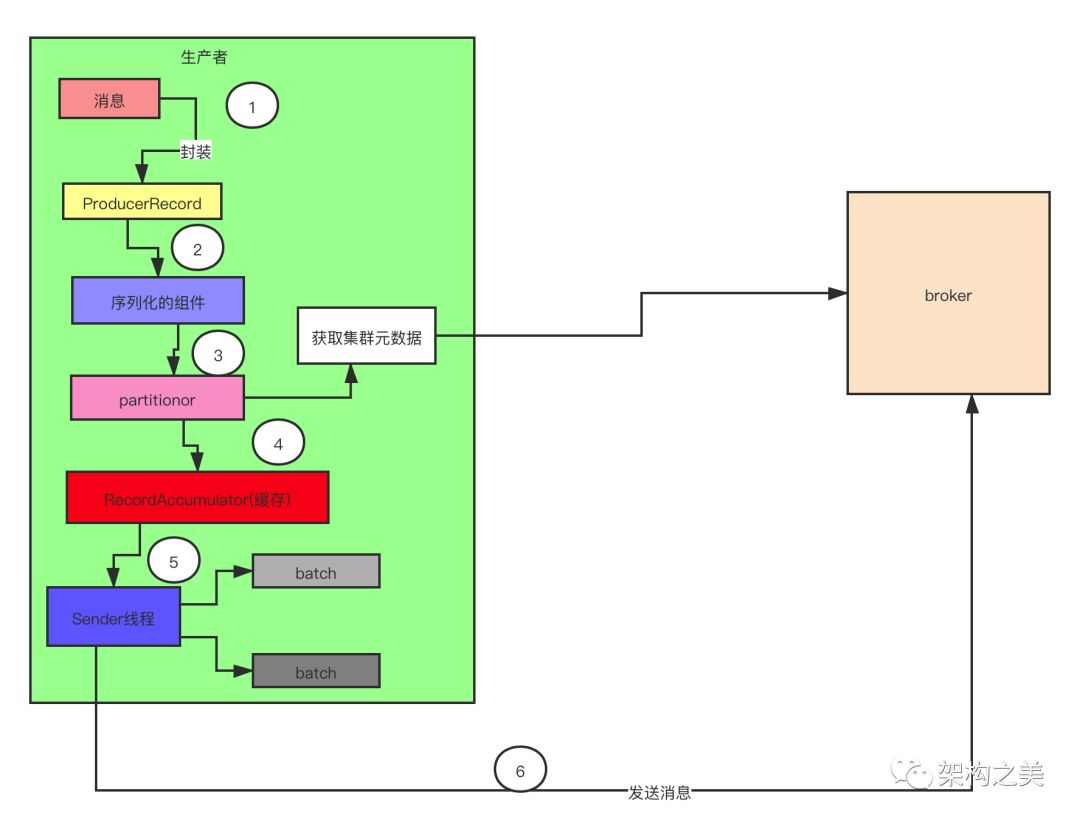
如上图所示:
步骤一:一条消息过来首先会被封装成为一个 ProducerRecord 对象。
步骤二:接下来要对这个对象进行序列化,因为 Kafka 的消息需要从客户端传到服务端,涉及到网络传输,所以需要实现序列。Kafka 提供了默认的序列化机制,也支持自定义序列化(这种设计也值得我们积累,提高项目的扩展性)。
步骤三:消息序列化完了以后,对消息要进行分区,分区的时候需要获取集群的元数据。分区的这个过程很关键,因为这个时候就决定了,我们的这条消息会被发送到 Kafka 服务端到哪个主题的哪个分区了。
步骤四:分好区的消息不是直接被发送到服务端,而是放入了生产者的一个缓存里面。在这个缓存里面,多条消息会被封装成为一个批次(batch),默认一个批次的大小是 16K。
步骤五:Sender 线程启动以后会从缓存里面去获取可以发送的批次。
步骤六:Sender 线程把一个一个批次发送到服务端。大家要注意这个设计,在 Kafka0.8 版本以前,Kafka 生产者的设计是来一条数据,就往服务端发送一条数据,频繁的发生网络请求,结果性能很差。后面的版本再次架构演进的时候把这儿改成了批处理的方式,性能指数级的提升,这个设计值得我们积累。
生产者细节深度剖析
接下来我们生产者这儿技术含量比较高的一个地方,前面概述那儿我们看到,一个消息被分区以后,消息就会被放到一个缓存里面,我们看一下里面具体的细节。默认缓存块的大小是 32M,这个缓存块里面有一个重要的数据结构:batches,这个数据结构是 key-value 的结果,key 就是消息主题的分区,value 是一个队列,里面存的是发送到对应分区的批次,Sender 线程就是把这些批次发送到服务端。
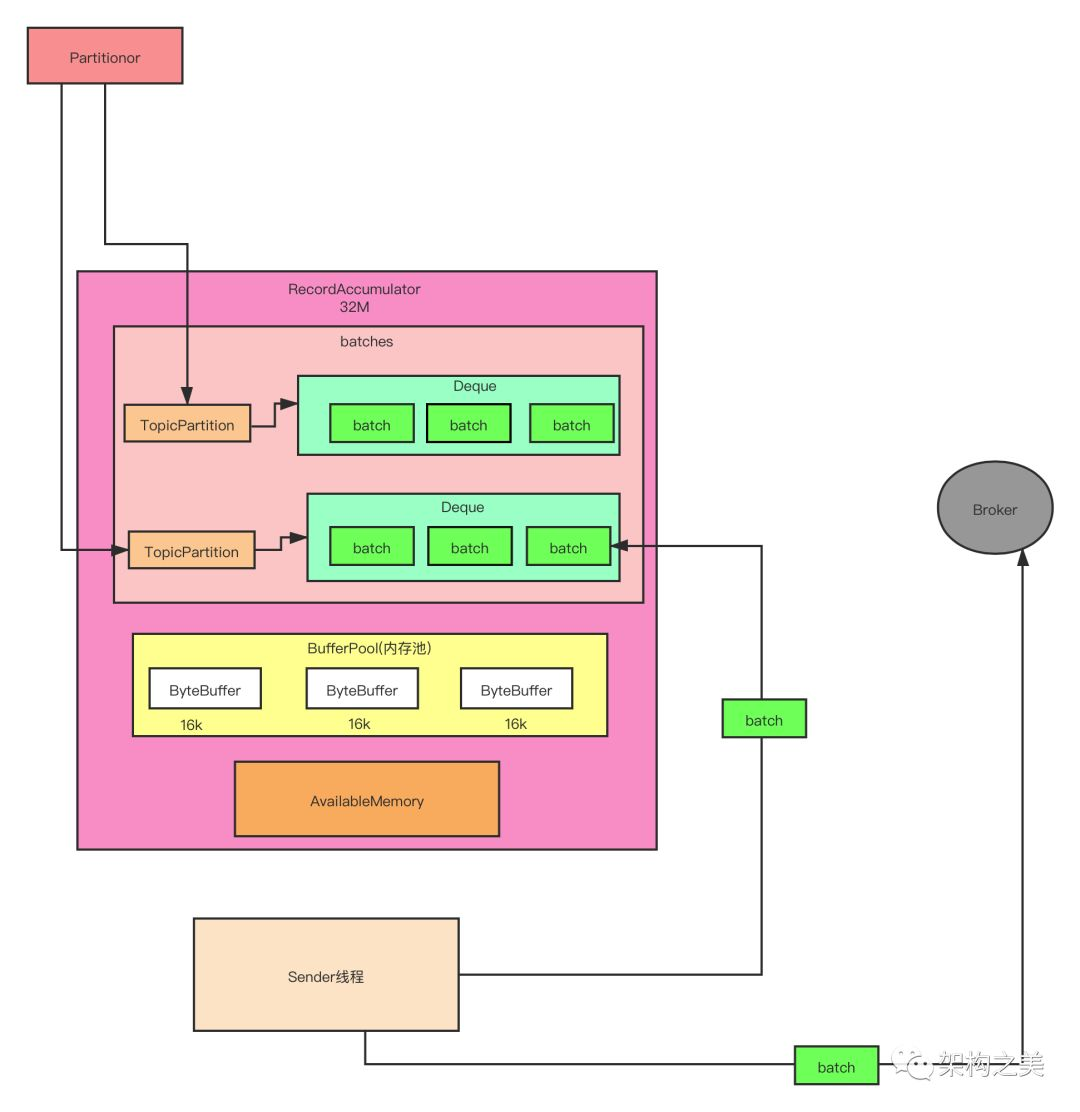
生产者高级设计之自定义数据结构
生产者把批次信息用 batches 这个对象进行存储。如果是大家,大家会考虑用什么数据结构去存储批次信息?
Kafka 这儿采取的方式是自定义了一个数据结构:CopyOnWriteMap。熟悉 Java 的同学都知道,JUC 下面是有一个 CopyOnWriteArrayList 的数据结构的,但是没有 CopyOnWriteMap,我这儿给大家解释一下 Kafka 为什么要设计这样的一个数据结构。
-
他们存储的信息的是 key-value 的结构,key 是分区,value 是要存到这个分区的对应批次(批次可能有多个,所以用的是队列),故因为是 key-value 的数据结构,所以锁定用 Map 数据结构。
-
这个 Kafka 生产者面临的是一个高并发的场景,大量的消息会涌入这个这个数据结构,所以这个数据结构需要保证线程安全,这样我们就不能使用 HashMap 这样的数据结构了。
-
这个数据结构需要支持的是读多写少的场景。读多是因为每条消息过来都会根据 key 读取 value 的信息,假如有 1000 万条消息,那么就会读取 batches 对象 1000 万次。写少是因为,比如我们生产者发送数据需要往一个主题里面去发送数据,假设这个主题有 50 个分区,那么这个 batches 里面就需要写 50 个 key-value 数据就可以了(大家要搞清楚我们虽然要写 1000 万条数据,但是这 1000 万条是写入 queue 队列的 batch 里的,并不是直接写入 batches,所以就我们刚刚说的这个场景,batches 里只需要最多写 50 条数据就可以了)。
根据第二和第三个场景我们总结出来,Kafka 这儿需要一个能保证线程安全的,支持读多写少的 Map 数据结构。但是 Java 里面并没有提供出来的这样的一个数据,唯一跟这个需求比较接近的是 CopyOnWriteArrayList,但是偏偏它又不是 Map 结构,所以 Kafka 这儿模仿 CopyOnWriteArrayList 设计了 CopyOnWriteMap。采用了读写分离的思想解决了线程安全且支持读多写少等问题。
高效的数据结构保证了生产者的性能。(CopyOnWriteArrayList 不熟悉的同学,可以尝试百度学习)。这儿笔者建议大家可以去看看 Kafka 生产者往 batches 里插入数据的源码,生产者为了保证插入数据的高性能,采用了多线程,又为了线程安全,使用了分段加锁等多种手段,源码非常精彩。
生产者高级设计之内存池设计
刚刚我们看到 batches 里面存储的是批次,批次默认的大小是 16K,整个缓存的大小是 32M,生产者每封装一个批次都需要去申请内存,正常情况下如果一个批次发送出去了以后,那么这 16K 的内存就等着 GC 来回收了。但是如果是这样的话,就可能会频繁的引发 FullGC,故而影响生产者的性能,所以在缓存里面设计了一个内存池(类似于我们平时用的数据库的连接池),一个 16K 的内存用完了以后,把数据清空,放入到内存池里,下个批次用的时候直接从里面获取就可以。这样大大的减少了 GC 的频率,保证了生产者的稳定和高效(Java 的 GC 问题是一个头疼的问题,所以这种设计也非常值得我们去积累)。
结尾
Kafka 的设计之中精彩的地方有很多,今天我们截取了一部分跟大家分享。之前我看到过 Kafka 的源码以后,就想以后如果我要去当老师,去培养架构师的话,那么我一定得跟学生分享 Kafka 的源码,通过学习 Kafka 源码提升系统架构能力,再次建议大家有空可以研究研究 Kafka 的源码,大家加油!!
作者:孙玄,奈学教育CEO,『架构之美』公众号作者,前58同城技术委员会主席。

