
背景
最近一个后台功能列表,业务人员反馈查询和导出速度非常慢。
通过定位发现列表查询和数据导出都是使用的同样的一个连表查询SQL。
这个功能刚上线不久,起初查询和导出速度都是蛮快的,把这个SQL放到测试环境也是挺快的。
对比了一下测试环境和生产环境相关表结构都是一样的,之后我们把目光放在了数量的问题上面,但是几张关联表的数据量也不大,不到1w的数据量为何会这么慢呢。
排查
通过Explain发现,连表查询中的table c没有使用到索引且是全表扫描。另外在Extra中特别说明了Using join buffer (Block Nested Loop)。
其中table c中的filtered=100% 表示右表没有应用索引下推(ICP),因为where条件没有索引。
另外Using join buffer (Block Nested Loop)是因为右表没有在join列上建索引导致嵌套循环。

解决
通过对table c中的连接字段content_id和user_no分别加上了索引,
加上索引后的执行计划如下

总结
需要注意:参与join的表,需要在连接条件上建索引。
知识延伸
MySQL使用嵌套循环算法或其变种来进行表之间的连接。
在5.5版本之前,MySQL只支持一种表间关联方式,也就是嵌套循环(Nested Loop)。如果关联的表数据量很大,那么join关联的时间会很长。在5.5版本以后,MySQL引入了BNL算法来优化嵌套循环。
1.嵌套循环连接算法(Nested-Loop Join Algorithm)
一个简单的嵌套循环连接(NLJ)算法从循环中的第一个表中逐行读取一行,将每行传递给处理连接中下一个表的嵌套循环。 这个过程会重复多次,因为还有剩余的表被连接。
假定要使用以下连接类型执行三个表t1,t2和t3之间的连接:
Table Join Type
t1 range
t2 ref
t3 ALL如果使用一个简单的NLJ算法,连接就像这样处理:
for(row_1 in table_1){
for(row_2 in table_2){
if(row_1,row_2满足join条件){
...
for(row_n in table_n){
if(row_1,row_2...row_n都满足join条件){
把row_1,row_2...row_n的join结果加到结果集
}
}
}
如图所示
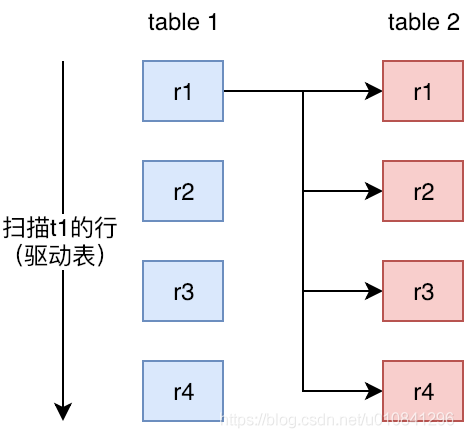
这种算法缺陷也很明显,随着join表数量的增加,计算量呈指数上升。如果其中出现了一张数据量很大的表,对整个过程的效率也影响很大。
于是,mysql5.5对这个算法进行了优化,新增了Index Nested-loop Join,Block Nested-loop Join。
2.索引嵌套循环连接算法(Index Nested-loop Join Algorithm)
Index Nested-loop Join是针对有索引的情况,而Block Nested-loop Join是针对没有命中索引的情况。

由于索引的效率要比逐条循环效率高,所以当使用索引联表时,能大大加快查询速度,但是索引也不是万能的,如果你需要取索引以外的字段,那么依旧需要回到表中查出相应的数据。
3.块嵌套循环连接算法(Block Nested-Loop Join Algorithm)
Block Nested-loop Join 块嵌套循环(BNL)连接算法使用在外部循环中读取的行的缓冲来减少必须读取内部循环中的表的次数。
举个简单的例子:外层循环结果集有1000行数据,使用NLJ算法需要扫描内层表1000次,但如果使用BNL算法,则先取出外层表结果集的100行存放到join buffer, 然后用内层表的每一行数据去和这100行结果集做比较,可以一次性与100行数据进行比较,这样内层表其实只需要循环1000/100=10次,减少了9/10。
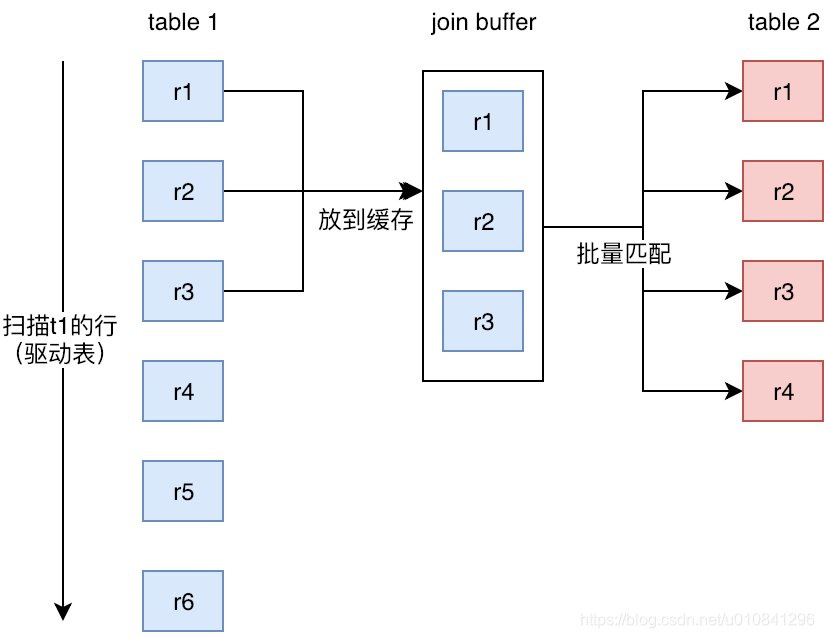
参考文章:
https://blog.csdn.net/itas109/article/details/79152144
http://blog.sina.com.cn/s/blog_a1e9c7910102x1bz.html
https://blog.csdn.net/fatesunlove/article/details/105809280
作者:翎野君


