
案例|MySQL OOM排查之旅转载
一 背景
微盟是中小企业云端商业及营销解决方案提供商,客户营销活动天天有,7月17日是某客户的超级营销日,老板要求全力护航,不允许任何故障。而营销活动前几天陆续收到几条腾讯云CDB实例OOM的短信报警。因为用云数据库,处理这个报警对于DBA来说太easy,腾讯DBA团队接管了。腾讯DBA大神们拿出各种经验来揣测原因,但收效甚微,MySQL OOM还在继续报警。为了保证线上稳定性以及营销活动的顺利开展,腾讯 CDB 的兄弟们和我们深度合作去重现问题,一起开启了问题排查之旅。
二 现象
在并发场景下跑一系列的SQL后,内存不断上涨,超出实例内存15G多,最终会导致实例OOM。
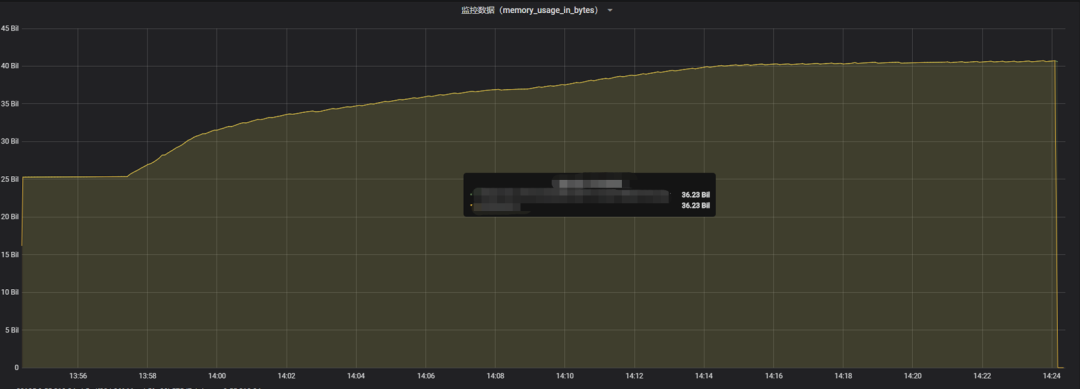
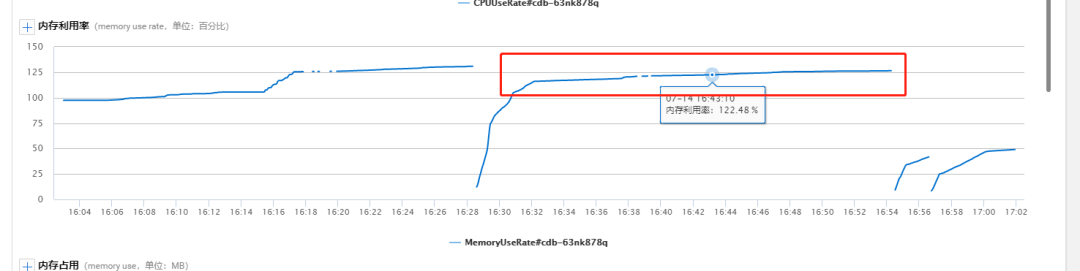
三 问题排查过程
反馈VIP群腾讯CDB技术团队接手(怀疑SQL问题)-> 开启数据库审计 ->排除无“特殊” SQL-> 开启 performance_schema ->源码分析
3.1 server层内存占用分析
腾讯云CDB支持通过全局status变量 total_server_memory_used 来展示server层内存占用情况。从server层看内存才使用4G,server层内存并没有异常。
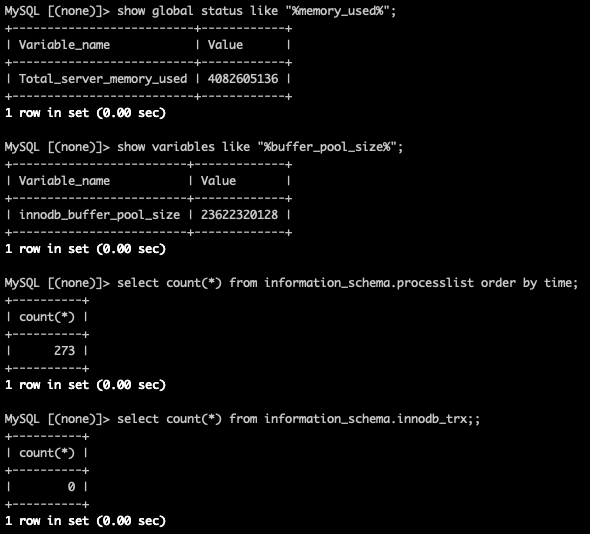
同时,腾讯云CDB实例通过show full processlist可以查看各个线程在server层的内存占用情况,也没有发现异常。

3.2 线下SQL分析
通过sql审计以及业务开发同学提供的SQL语句。经过逐个分析,SQL没有join,比较简单,索引使用也都很合理。同时线下进行单个sql测试以及并发场景测试,也没有发现内存异常的情况。
3.3 官方OOM相关bug分析
在SQL没有发现明显异常的情况下,CDB内核团队试图从官方bug着手,看能否发现蛛丝马迹。我们使用的是CDB 5.7版本,CDB 也会定期更新 merge一些官方严重的bug。从官方release notes发现了如下可疑bug
InnoDB: A dangling pointer caused a memory leak. (Bug #28693568)
A query employing a dynamic range and an index merge could use more memory than expected. (Bug #89953, Bug #27659490)
首先看看第一个bug Bug#28693568,这个是MySQL一个指针没有及时释放导致的内存泄漏问题,经过分析这个bug是MySQL官方中间版本引入的,CDB 5.7并不存在此问题。
commit 2a07e8d69f35a94fb0133011e3ea84ca6072171d
Author: Tor Didriksen <tor.didriksen@oracle.com>
Date: Mon Sep 24 13:16:23 2018 +0200
Bug#28693568 MEMORY LEAK IN EMBEDDED SERVER
Backport patch from 8.0 to avoid dangling char* pointer for filepath.
Change-Id: I049dceaec9103b9ba93e58732b92c412459ead7a
再来看第二个 bugBug#27659490,这个bug主要是index-merge时导致使用了大量的MEM_ROOT内存。MEM_ROOT是每个连接thd上的内存,属于server层的内存。我们通过以下两个两点,可以确定并不是这个bug导致我们的问题。
前面分析过的sql查询计划发现并没有使用index-merge.
通过前面server层内存使用分析,内存问题并不在server层,而这个bug的内存问题在server层。
Bug #27659490 :
SELECT USING DYNAMIC RANGE AND INDEX
MERGE USE TOO MUCH MEMORY(OOM)
Issue:
While creating a handler object, index-merge access creates it in statement MEM_ROOT.
However when this is used with "Dynamic range access method", as range optimizer gets invoked multiple times, mysql ends up consuming a lot of memory.
Solution:
Instead of using statement MEM_ROOT to allocate the handler object, use the local MEM_ROOT of the range optimizer which gets destroyed at the end of range optimizer's usage.
3.4 开启 performance_schema
在前面排查无果的情况下,我们配合CDB内核同学开启performance_schema来监控整体内存使用情况。开启后发现除 buffer_pool 外,engine层内存占用最多的是memory/innodb/row0sel和memory/innodb/mem0mem
注意开启performance_schema会有3%左右的性能损耗,这个需要结合具体业务情况来决定是否可以开启performance_schema。
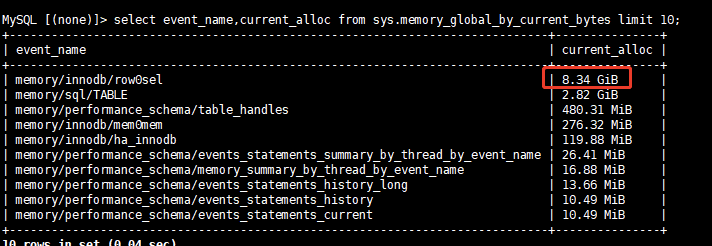
3.5 深入源码
接着从源码角度分析内存分配来源
3.5.1 memory/innodb/row0sel
memory/innodb/row0sel 主要有4个地方分配内存,前两个都跟fetch cache 有关。第四个是空间索引rtree,我们的场景没有空间索引,这个可以忽略。至此,问题应该大概率和 fetch_cache 相关,那么,什么是 fetch_cache,为什么要引入 fetch_cache呢?
MySQL中 Server 层与 Engine 之间的是以 row 为单位进行交互的,engine 将记录返回给 server 层,server 层对 engine 的行数据进行相应的计算,然后缓存或发送至客户端,为了减少交互过程所需要的时间,MySQL 做了两个优化:
如果同一个查询语句连续取出了 MYSQL_FETCH_CACHE_THRESHOLD(4) 条记录,则会调用函数 row_sel_enqueue_cache_row_for_mysql 将 MYSQL_FETCH_CACHE_SIZE(8) 记录缓存至 prebuilt->fetch_cache 中,在随后的 prebuilt->n_fetch_cached 次交互中,都会从 prebuilt->fetch_cache 中直接取数据返回到 server 层,那么问题来了,即使是用户只需要 4 条数据,Engine 层也会将 MYSQL_FETCH_CACHE_SIZE 条数据放入 fetch_cache 中,造成了不必要的缓存使用。另外,5.7 可以根据用户的设置来调整缓存用户记录的条数;
Engine 取出数据后,会将 cursor 的位置保存起来,当取下一条数据时,会尝试恢复 cursor 的位置,成功则并继续取下一条数据,否则会重新定位 cursor 的位置,从而通过保存 cursor 位置的方法可以减少 server 层 & engine 层交互的时间;
所以,fetch_cache 在满足一定的条件下用于缓存innodb层的记录,这样server层从engine取记录时可以直接从 fetch_cache 取记录,提升取数据的效率,每个打开的table在engine层都可以对应到一个fetch_cache.
sel_col_prefetch_buf_alloc:
column->prefetch_buf = static_cast<sel_buf_t*>(ut_malloc_nokey(SEL_MAX_N_PREFETCH * sizeof(sel_buf_t)));
row_sel_prefetch_cache_init:
sz = UT_ARR_SIZE(prebuilt->fetch_cache) * (prebuilt->mysql_row_len + 8);
ptr = static_cast<byte*>(ut_malloc_nokey(sz));
row_search_mvcc:
if (end_range_cache == NULL) {
end_range_cache = static_cast<byte*>(
ut_malloc_nokey(prebuilt->mysql_row_len));
}
row_count_rtree_recs:
ulint bufsize = ut_max(UNIV_PAGE_SIZE, prebuilt->mysql_row_len);
buf = static_cast<byte*>(ut_malloc_nokey(bufsize));
3.5.2 memory/innodb/mem0mem
memory/innnodb/mem0mem主要两个地方分配内存,但这两块是engine层内存分配的基础函数,被调用的地方非常多。
-
mem_strdup/mem_strdupl
-
mem_heap_create_block_func
3.6 Index Condition pushdown & fetch_cache
经过抓取堆栈分析,发现分配fetch_cache的堆栈如下

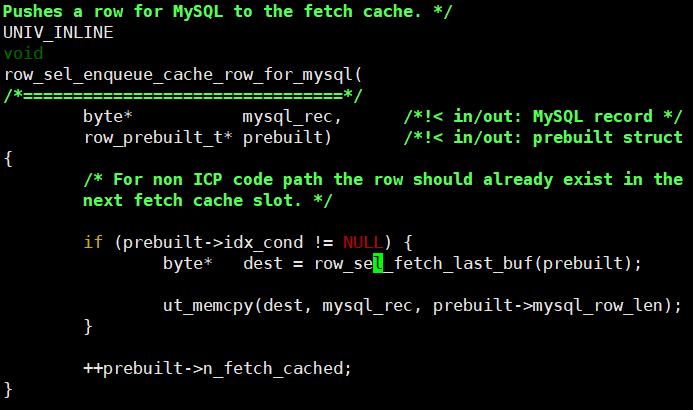
row_sel_fetch_last_buf 最后会调用 row_sel_prefetch_cache_init 分配fetch_cache.
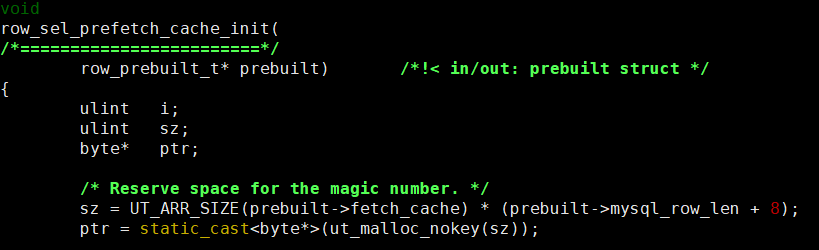
在这里我们看到了prebuild->inx_cond 这个条件,这个是https://dev.mysql.com/doc/refman/5.6/en/index-condition-pushdown-optimization.html,简称ICP,这里就不展开了。从代码可以看到,我们的场景下当使用ICP时会去分配fetch_cache.
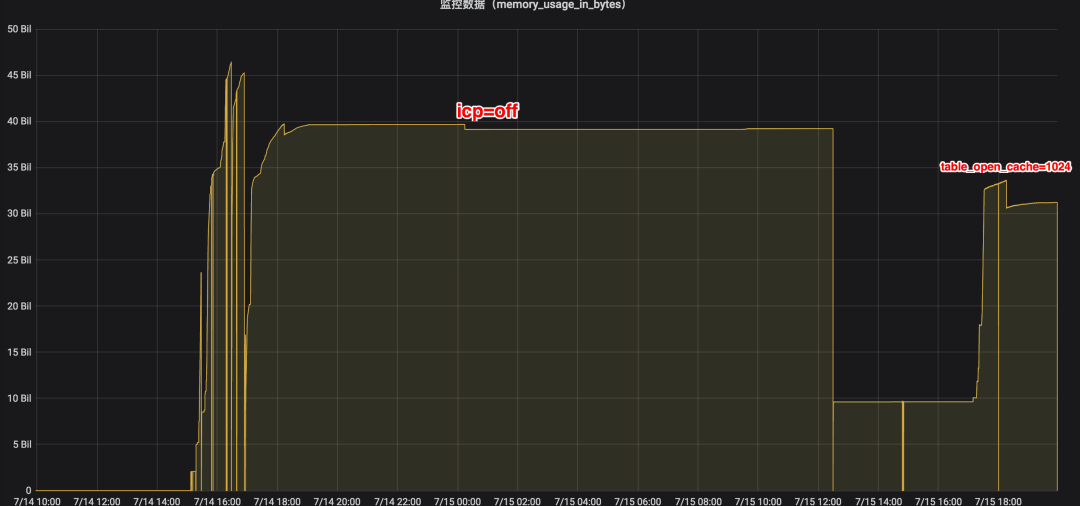
因此我们尝试关闭ICP,修改optimizer_switch 将 index_condition_pushdown设置为off。经过验证关闭ICP后,内存使用下降了很多
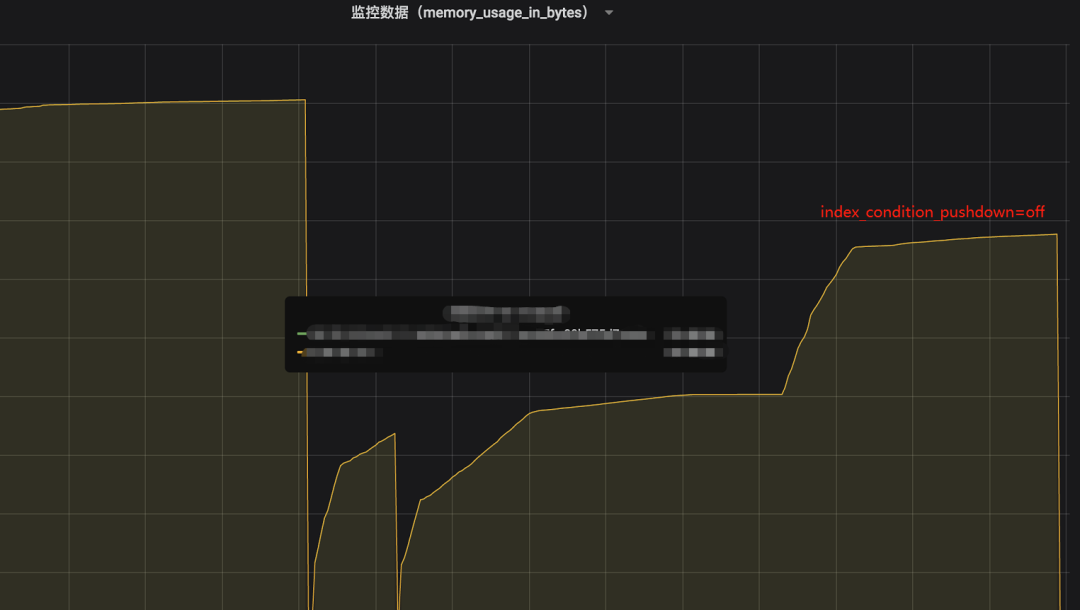
同时从performance_schema中也观察到memory/innodb/row0sel内存占用比之前也明显下降。
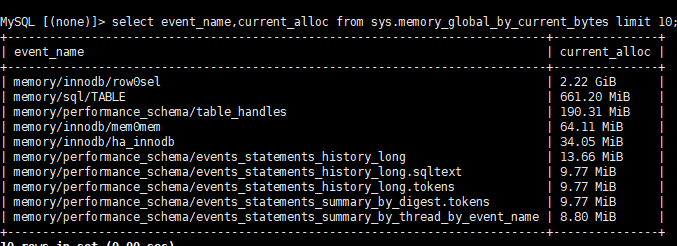
至此,经过测试关闭ICP后内存上涨不再那么多,也不会导致OOM,同时业务上在关闭ICP后发现性能影响几乎不受影响是可以接受的。但CDB内核团队仍然坚持和研发一起测试,希望找根本原因。
3.7 根本原因
经过一系列的源码调试和分析发现, fetch_cache等占用的内存需要在关闭表 (ha_innodb::close) 的时候才释放。对于业务中的某张表的其单行记录大小 (prebuilt->mysql_row_len)为 11458,其
fetch_cache大小(prebuilt->mysql_row_len + 8)*8=91728。
而另外一张表其单行记录大小(prebuilt->mysql_row_len)更是达到了58565,
其fetch_cache大小(prebuilt->mysql_row_len + 8)*8=548584。
如以下表结构中包含了较多的varchar超长字段。
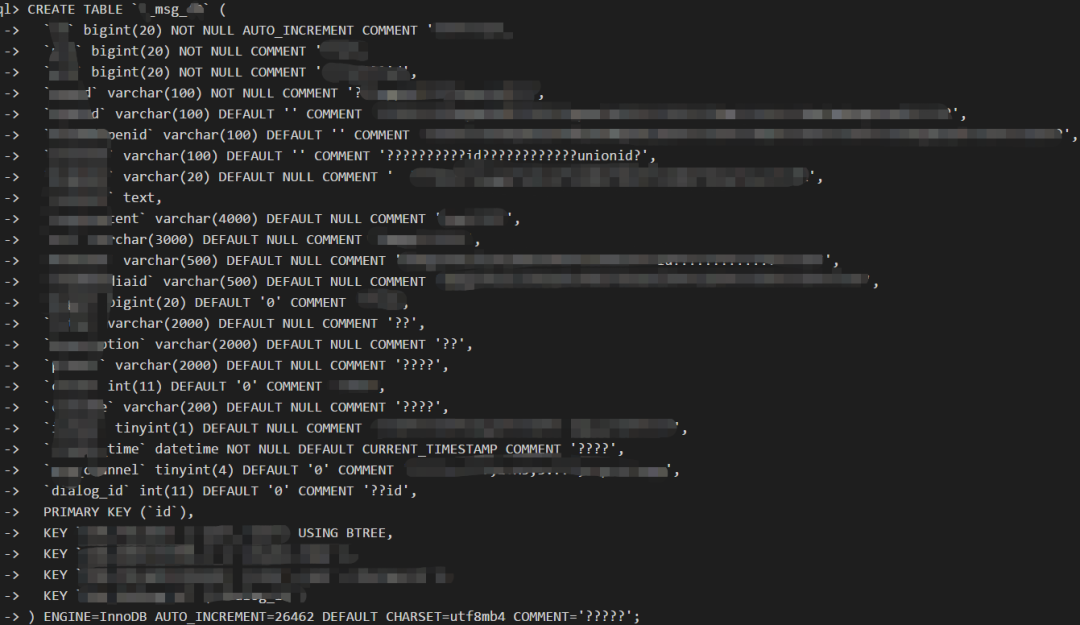
而我们的业务也分库分表了,这个表基本都是分表的形式存在,也就是说这个实例中绝大多数表都是这样的结构。
我们再来看是什么决定了fetch_cache的总个数。经过分析源码,在engine层每个table对象会有一个 row_prebuild_t 对象,每个row_prebuild_t 对象对应一个 fetch_cache。我们得出 fetch_cache总个数跟table_open_cache 和table_open_cache_instances 有关。
fetch_cache总个数=min(table_open_cache, table_open_cache_instances*总表数)
在本实例中总表数有两千左右,本例子中table_open_cache相关的参数如下,
show variables like '%table_open%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| table_open_cache | 102400 |
| table_open_cache_instances | 64 |
+----------------------------+-------+
我们以最大的fetch_cache大小548584为例子来估算出fetch_cache最大总大小为52G。
min(102400, 64*2000) * 548584 = 52G
另外在engine层每个table对象的row_prebuild_t也会从mem_heap中分配内存,大约7k左右。这个mem_heap就是前面performance_schema中看的 memory/innodb/mem0mem 中的部分。
这块的内存总占用为600M左右,这个同performance_schema中看到 memory/innodb/mem0mem 部分量级相当。
min(102400, 64*2000) * 7k=680M
因此我们得出结论,线上建议将 table_open_cache 改为10240同时将 table_open_cache_instances 改为8或16将有效减少内存使用。
3.8 一些疑问
3.8.1 线下同样sql测试为什么没能重现问题?
线下测试仅仅是将用户的一些特定sql进行测试,虽然也增加了并发的场景。但因为是分库分表,因此只取了个别分表进行测试,所以构造的例子中涉及的表数仅是个位数。
min(table_open_cache, table_open_cache_instances*总表数)
回到前面的公式,这个内存占用是依赖于测试的总表数的,因此线下测试没能复现内存异常的场景。
3.8.2 之前自建实例为什么不会OOM?
腾讯云上对CDB实例的内存是有规格限制的,超出规格会OOM。而本例中随着打开表数增长table_open_cache内存占用会超实例规格,从而OOM。而自建实例对内存没有限制,取决于主机内存大小,而table_open_cache的内存占用并不是内存泄漏,在达到顶峰后会内存将不再增长,而这个顶峰并没有达到主机内存上限,因此没有OOM。
总结
对于CDB实例OOM的问题,原因多种多样。有些是MySQL bug导致,例如表较多时查询information_schema导致OOM。有些是用户使用方法导致,例如用户使用超多union的SQL导致SQL解析overflow而OOM。腾讯云CDB提供了各种内存诊断方法,包括前面介绍的server层内存使用统计,Performance_schema内存使用统计等等。
文章来源:微信公众号


