
一、推送平台特点
vivo推送平台是vivo公司向开发者提供的消息推送服务,通过在云端与客户端之间建立一条稳定、可靠的长连接,为开发者提供向客户端应用实时推送消息的服务,支持百亿级的通知/消息推送,秒级触达移动用户。
推送平台的特点是并发高、消息量大、送达及时性较高。目前现状最高推送速度140w/s,单日最大消息量150亿,端到端秒级在线送达率99.9%。
二、推送平台Redis使用介绍
基于vivo推送平台的特点,对并发和时效性要求较高,并且消息数量多,消息有效期短。所以,推送平台选择使用Redis中间件作为消息存储和中转,以及token信息存储。之前主要使用两个Redis集群,采用Redis Cluster 集群模式。两个集群如下:
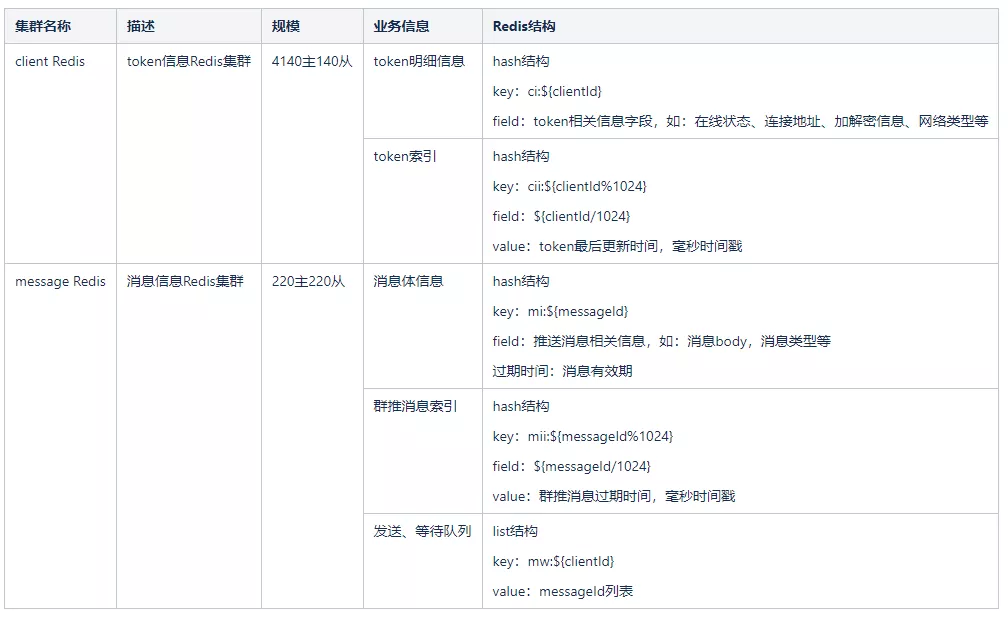
对Redis的操作,主要包括如下几方面:
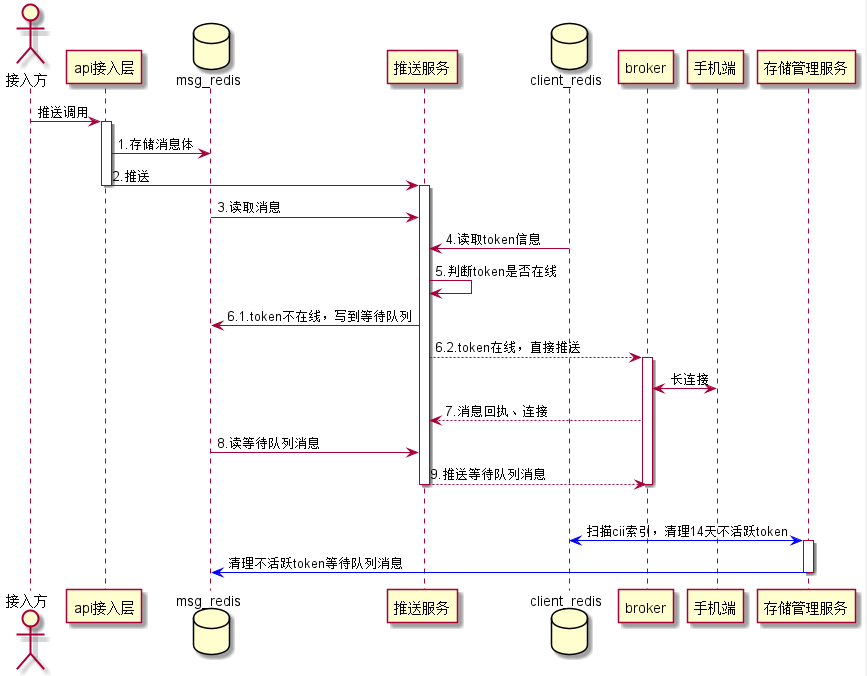
1)推送环节,在接入层存储消息体到msg Redis集群,消息过期时间为msg Redis存储消息的过期时间。
2)推送服务层经过一系列逻辑后,从msg Redis集群查出消息体,查询client Redis集群client信息,如果client在线,直接推送。如果client不在线,将消息id写到等待队列。
3)如果连接上来,推送服务层,读取等待队列消息,进行推送。
4)存储管理服务,会定期扫描cii索引,根据cii存储的最后更新时间,如果14天都没更新,说明是不活跃用户,会清理该token信息,同时清理该token对应的等待队列消息。
推送环节操作Redis流程图如下:
三、推送平台线上问题
如上面介绍,推送平台使用Redis主要msg集群和client集群,随着业务的发展,系统对性能要求越来越高,Redis出现一些瓶颈问题,其中msg Redis集群在优化前,规模已达到220个master,4400G容量。随着集群规模变大,维护难度增加,事故率变高。特别是4月份,某某明星离婚事件,实时并发消息量5.2亿,msg Redis集群出现单节点连接数、内存暴增问题,其中一个节点连接数达到24674,内存达到23.46G,持续30分钟左右。期间msg Redis集群读写响应较慢,平均响应时间500ms左右,影响到整体系统的稳定性和可用性,可用性降到85%。

四、推送平台Redis优化
Redis一般从以下几方面优化:
1)容量:Redis属于内存型存储,相较于磁盘存储型数据库,存储成本较昂贵,正是由于内存型存储这个特性使得它读写性能较高,但是存储空间有限。因此,业务在使用时,应注意存储内容尽量是热数据,并且容量是可预先评估的,最好设置过期时间。在存储设计时,合理使用对应数据结构,对于一些相对大的value,可以压缩后存储。
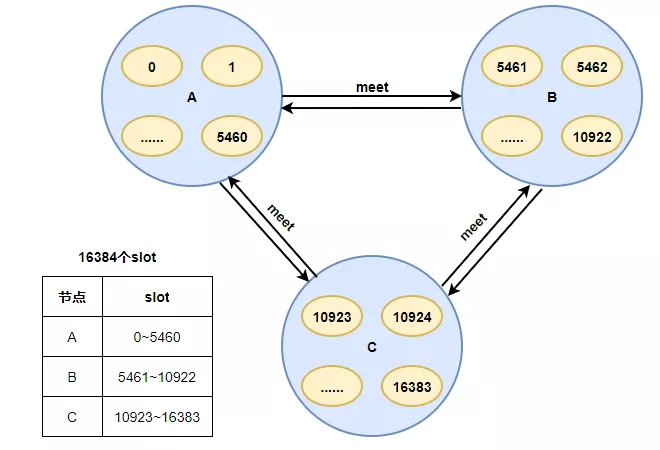
2)热key倾斜:Redis-Cluster把所有的物理节点映射到[0-16383]slot(槽)上,每个节点负责一部分slot。当有请求调用时,根据 CRC16(key) mod 16384的值,决定将key请求到哪个slot中。由于Redis-cluster这个特性,每个节点只负责一部分slot,因此,在设计key的时候应保证key的随机性,特别是使用一些hash算法映射key时,应保证hash值的随机分布。另外,控制热点key并发问题,可以采用限流降级或者本地缓存方式,防止热点key并发请求过高导致Redis热点倾斜。
3)集群过大:Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。每个节点都保存所有节点与slot映射关系。当节点较多时,每个节点保存的映射关系也会变多。各节点之间心跳包的消息体内携带的数据越多。在扩缩容时,集群重新进行clusterSlots时间相对较长。集群会存在阻塞风险,稳定性受影响。因此,在使用集群时,应该尽量避免集群节点过多,最后根据业务对集群进行拆分。
这里有个问题:为什么Redis-Cluster使用16384个slot,而不是更多,最多可以有多少个节点?
官方作者给出了解释,并且在解释中说明,Redis-Cluster不建议超过1000个主节点。
基于以上一些优化方向,和自身业务特性,推送平台从以下几方面开启Redis优化之路。
-
msg Redis集群容量优化;
-
msg Redis大集群根据业务属性拆分;
-
Redis热点key排查;
-
client Redis集群并发调用优化。
4.1 msg Redis集群容量优化
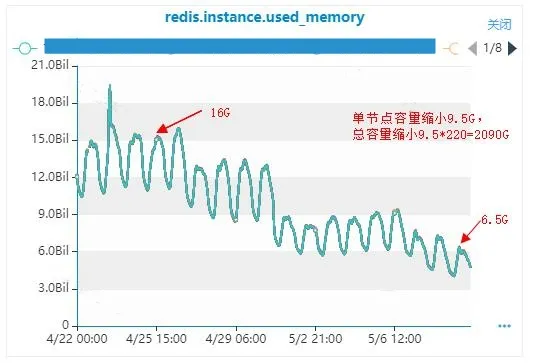
前文提及,msg Redis集群规模达到220个master、4400G容量,高峰期已使用容量达到3650G,使用了83%左右,如果后续推送提量,还需扩容,成本太高。于是对msg Redis集群存储内容进行分析,使用的分析工具是雪球开源RDB分析工具RDR 。github网址:这里不多介绍,大家可以去github网址下载相应的工具使用。这个工具可以分析Redis快照情况,包括:Redis不同结构类型容量、key数量、top 100 largest keys、前缀key数量和容量。
分析后的结论:msg Redis集群中,mi:开头的结构占比80%左右,其中单推消息占比80%。说明:
-
单推:1条消息推送1个用户
-
群推:1条消息可以重复推送多个用户,消息可以复用。
单推的特点是一对一推送,推送完或者推送失败(被管控、无效用户等)消息体就不再使用。
优化方案:
-
及时清理单推消息,如果用户已经收到单推消息,收到puback回执,直接删除Redis消息。如果单推消息被管控等原因限制发送,直接删除单推消息体。
-
对于相同内容的消息,进行聚合存储,相同内容消息存储一条,消息id做标识推送时多次使用。
经过这个优化后,缩容效果较明显。全量上线后容量缩小了2090G,原最高容量为3650G,容量缩小了58%。
4.2 msg Redis大集群根据业务属性拆分
虽然进行了集群容量优化,但是高峰期msg Redis压力依然很大。
主要原因:
1)连接msg Redis的节点很多,导致高峰期连接数较高。
2)消息体还有等待队列都存储在一个集群,推送时都需要操作,导致Redis并发很大,高峰期cpu负载较高,到达90%以上。
3)老集群Redis版本是3.x,拆分后,新集群使用4.x版本。相较于3.x版本有如下优势:
-
PSYNC2.0:优化了之前版本中,主从节点切换必然引起全量复制的问题。
-
提供了新的缓存剔除算法:LFU(Least Frequently Used),并对已有算法进行了优化。
-
提供了非阻塞del和flushall/flushdb功能,有效解决删除了bigkey可能造成的Redis阻塞。
-
提供了memory命令,实现对内存更为全面的监控统计。
-
更节约内存,存储同样多的数据,需要更少的内存空间。
-
可以做内存碎片整理,逐步回收内存。当使用Jemalloc内存分配方案的时候,Redis可以使用在线内存整理。
拆分方案根据业务属性对msg Redis存储信息进行拆分,把消息体和等待队列拆分出来,放到独立的两个集群中去。这样就有两种拆分方案。
方案一:把等待队列从老集群拆分出来
只需推送节点进行修改,但是发送等待队列连续的,有状态,与clientId在线状态相关,对应的value会实时更新,切换会导致数据丢失。
方案二:把消息体从老集群拆分出来
所有连接msg Redis的节点替换新地址重启,推送节点进行双读,等到老集群命中率为0时,直接切换读新集群。由于消息体的特点是只有写和读两个操作,没有更新,切换不用考虑状态问题,只要保证可以写入读取没问题。并且消息体容量具有增量属性,需要能方便快速的扩容,新集群采用4.0版本,方便动态扩缩容。

考虑到对业务的影响及服务可用性,保证消息不丢失,最终我们选择方案二。采用双读单写方案设计:
由于将消息体切换到新集群,那在切换期间一段时间(最多30天),新的消息体写到新集群,老集群存储老消息体内容。这期间推送节点需要双读,保证数据不丢失。为了保证双读的高效性,需要支持不修改代码,不重启服务的动态规则调整措施。
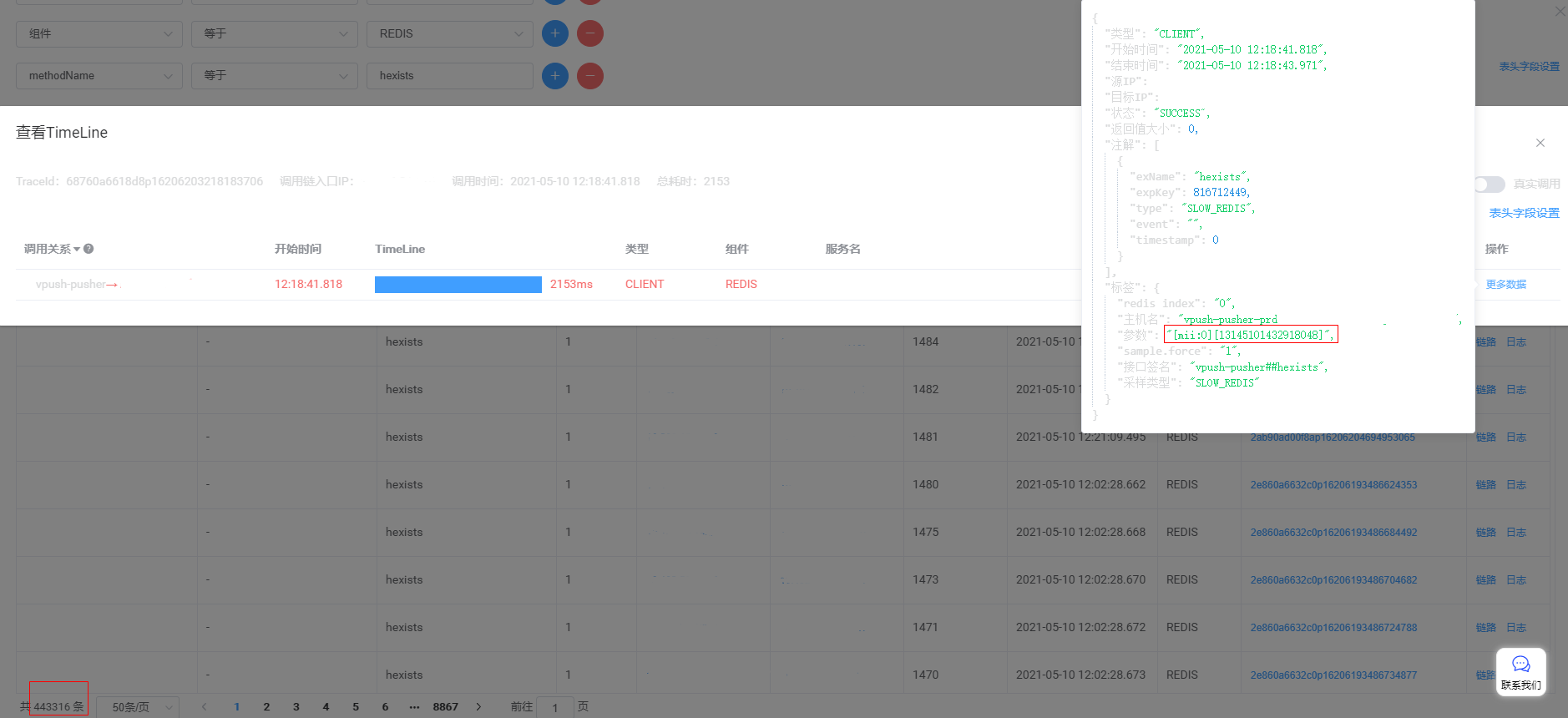
大致规则分为4个:只读老、只读新、先读老后读新、先读新后读老。
设计思路:服务端支持4种策略,通过配置中心的配置决定走哪个规则。
规则的判断依据:根据老集群的命中数和命中率决定。上线初期规则配置“先读老再读新”;当老集群命中率低于50%,切换成"先读新后读老";当老集群命中数为0后,切换成“只读新”。
老集群的命中率和命中数通过通用监控增加埋点。
方案二流程图如下:
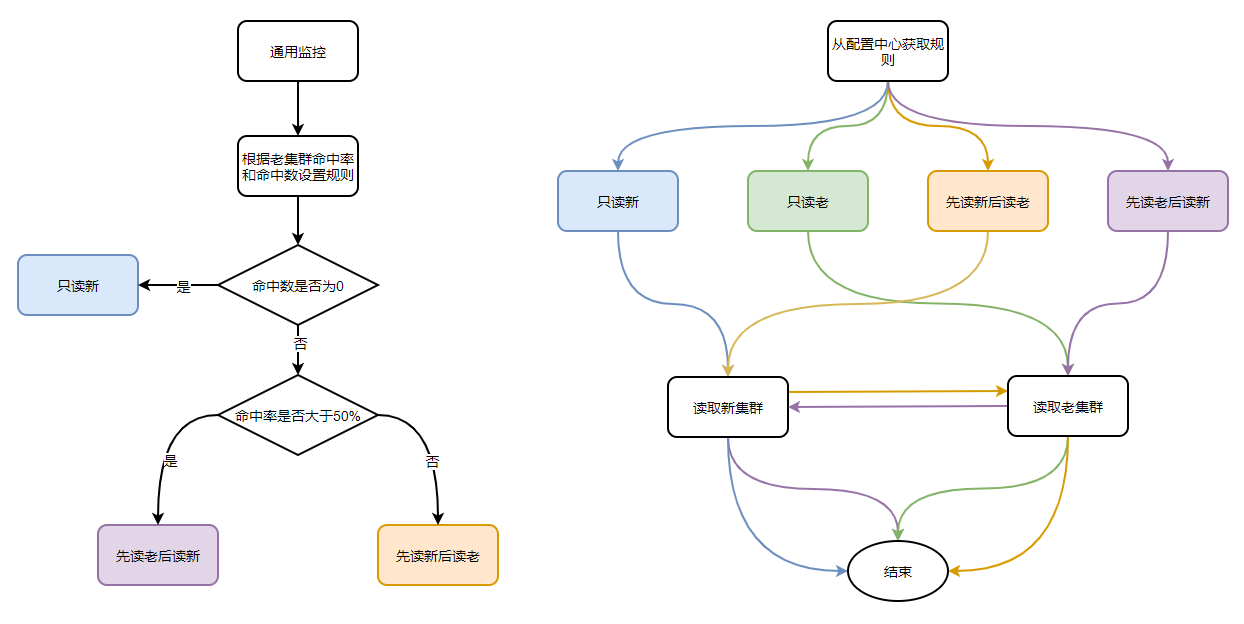
拆分后效果:
-
拆分前,老msg Redis集群同时期高峰期负载95%以上。
-
拆分后,同时期高峰期负载降低到70%,下降15%。
拆分前,msg Redis集群同时期高峰期平均响应时间1.2ms,高峰期存在调用Redis响应慢情况。拆分后,平均响应时间降低到0.5ms,高峰期无响应慢问题。
4.3 Redis热点key排查
前面有说过,4月某某明星热点事件,出现msg Redis单节点连接数、内存飙升问题,单节点节点连接数达到24674,内存达到23.46G。
由于Redis集群使用的虚拟机,起初怀疑是虚拟机所在宿主机存在压力问题,因为根据排查发现出现问题的节点所在宿主机上挂载Redis主节点很多,大概10个左右,而其他宿主机挂载2-4个左右主节点,于是对master进行了一轮均衡化优化,使每台宿主机分配的主节点都比较均衡。均衡化之后,整体有一定改善。但是,在推送高峰期,尤其是全速全量推送时,还是会偶尔出现单节点连接数、内存飙升问题。观察宿主机网卡出入流量,都没出现瓶颈问题,同时也排除了宿主机上其他业务节点的影响。因此怀疑还是业务使用Redis存在热点倾斜问题。
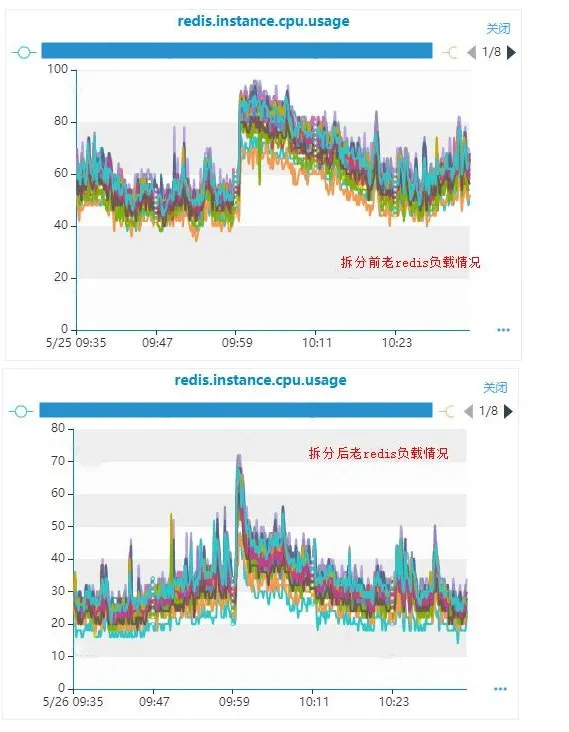
通过高峰期抓取调用链监控,从下图可以看到,我们11:49到12:59这期间调用msg Redis的hexists命令耗时很高,该命令主要是查询消息是否在mii索引中,链路分析耗时的key大都为mii:0。同时对问题节点Redis内存快照进行分析,发现mii:0容量占比很高,存在读取mii:0热点问题。
经过分析排查,发现生成消息id的雪花算法生成的messageId,存在倾斜问题,由于同一毫秒的序列值都是从0开始,并且序列长度为12位,所以对于并发不是很高的管理后台及api节点,生成的messageId基本都是最后12位为0。由于mii索引key是mi:${messageId%1024},messageId最后12位为0,messageId%1024即为0,这样就导致msg Redis中mii:0这个key很大,查询时命中率高,因此导致了Redis的热key问题。

优化措施:
1)雪花算法改造,生成消息id时使用的sequence初始值不再是0,而是从0~1023随机取一个数,防止热点倾斜问题。
2)通过msg消息体中消息类型及消息体是否存在来替换调hexists命令。
最终效果:优化后,mii索引已分布均匀,Redis连接数很平稳,内存增长也较平稳,不再出现Redis单节点内存、连接数暴增问题。
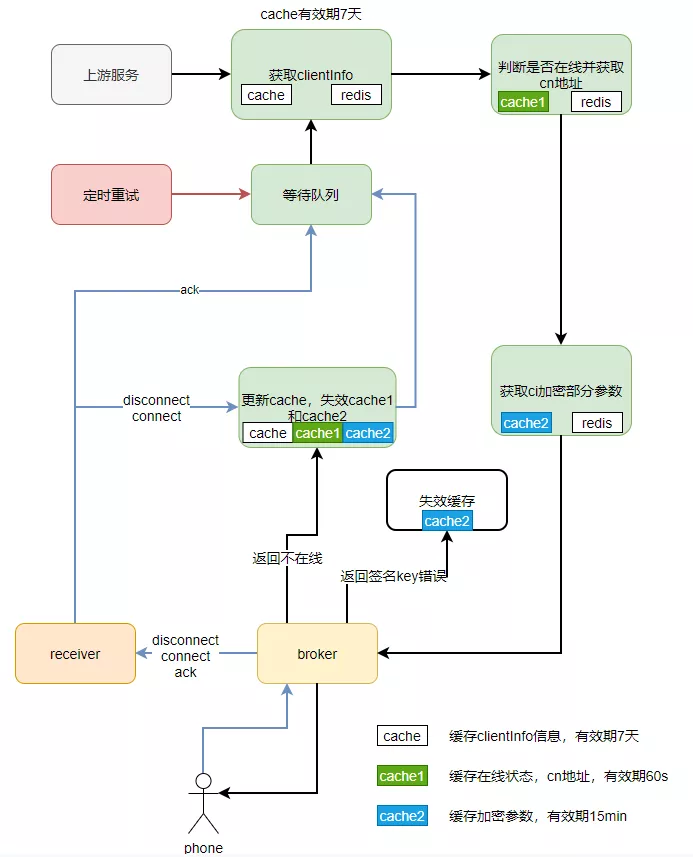
4.4 client Redis集群并发调用优化
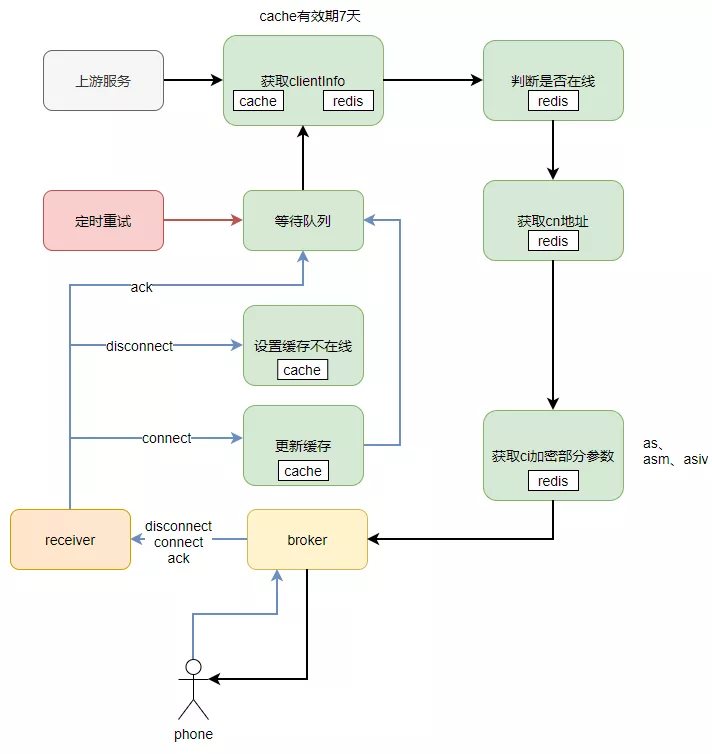
上游节点调用推送节点是通过clientId进行一致性hash调用的,推送节点会缓存clientInfo信息到本地,缓存时间7天,推送时,优先查询本地缓存,判断该client是否有效。对于重要且经常变更的信息,直接查询client Redis获取,这样导致推送高峰期,client Redis集群压力很大,并发高,cpu负载高。
优化前推送节点操作缓存和client Redis流程图:
优化方案:对原有clientInfo缓存进行拆分,拆分成三个缓存,采取分级方案。
-
cache还是保存原来clientInfo一些信息,这些信息是不经常变更的,缓存时间还是7天。
-
cache1缓存clientInfo经常变更的信息,如:在线状态、cn地址等。
-
cache2缓存ci加密部分参数,这部分缓存只在需要加密时使用,变更频率没那么高,只有连接时才会变更。
由于新增了缓存,需考虑缓存一致性问题,于是新增一下措施:
1)推送缓存校验,调用broker节点,根据broker的返回信息,更新和清理本地缓存信息。broker新增不在线、aes不匹配错误码。下次推送或者重试时,会重新从Redis中加载,获取最新的client信息。
2)根据手机端上行事件,connect和disconnect时,更新和清理本地缓存信息,下次推送或者重试时,会重新从Redis中加载,获取最新的client信息。
整体流程:消息推送时,优先查询本地缓存,缓存不存在或者已过期,才从client Redis中加载。推送到broker时,根据broker返回信息,更新或失效缓存。上行,收到disconnect、connect事件,及时更新或失效缓存,再次推送时重新从client Redis加载。
优化后推送节点操作缓存和client Redis流程图:
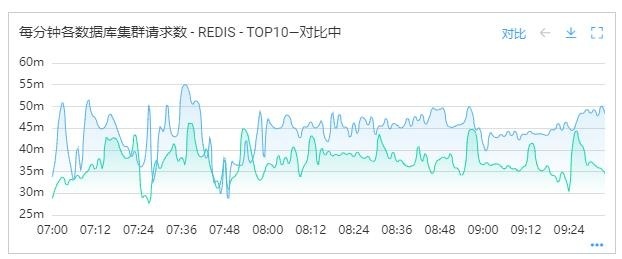
优化后效果:
1)新增cache1缓存命中率52%,cache2缓存命中率30%。
2)client Redis并发调用量减少了近20%。
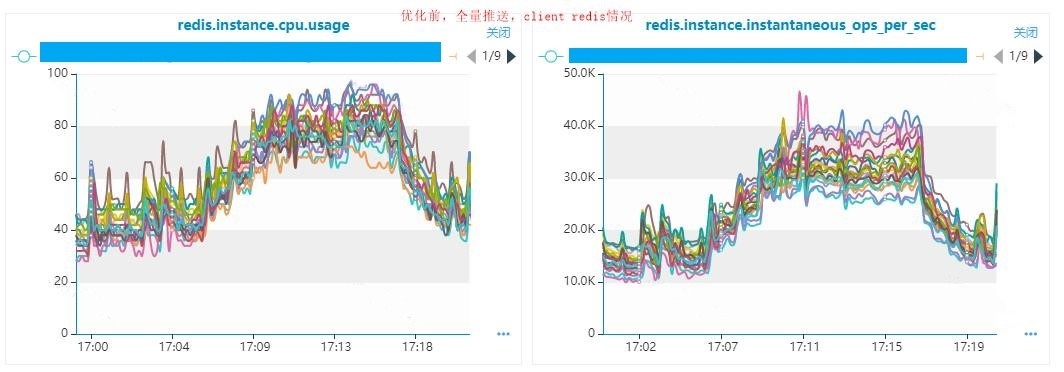
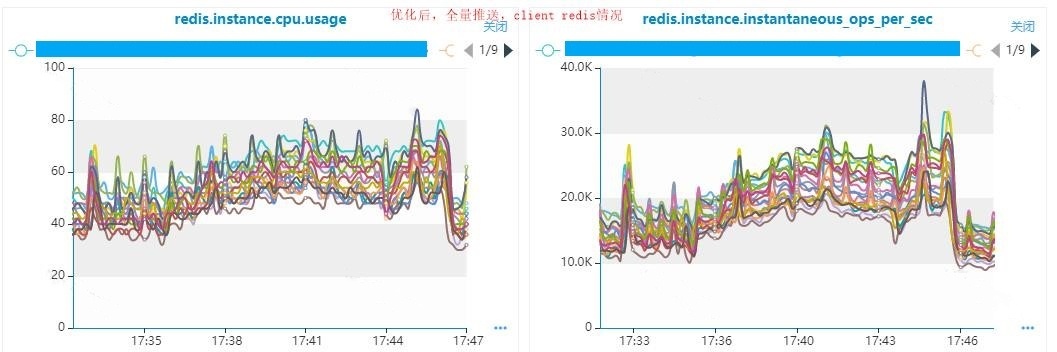
3)高峰期Redis负载降低15%左右。
五、总结
Redis由于其高并发性能和支持丰富的数据结构,在高并发系统中作为缓存中间件是较好的选择。当然,Redis是否能发挥高性能,还依赖业务是否真的理解和正确使用Redis。有如下几点需要注意:
1)由于Redis集群模式,每个主节点只负责一部分slot,业务在设计Redis key时要充分考虑key的随机性,均匀分散在Redis各节点上,同时应避免大key出现。另外,业务上应避免Redis请求热点问题,同一时刻请求打到少部分节点。
2)Redis实际吞吐量还与请求Redis的包数据大小,网卡有关,官方文档有相关说明,单个包大小超过1000bytes时,性能会急剧下降。所以在使用Redis时应尽量避免大key。另外,最好根据实际业务场景和实际网络环境,带宽和网卡情况进行性能压测,对集群实际吞吐量做摸底。
以我们client Redis集群为例:(仅供参考)
-
Network:10000Mb;
-
Redis Version:3.x;
-
Payload size:250bytes avg;
-
命令:hset(25%)、hmset(10%)、hget(60%)、hmget(5%);
-
性能情况:连接数5500、48000/s、cpu 95%左右。
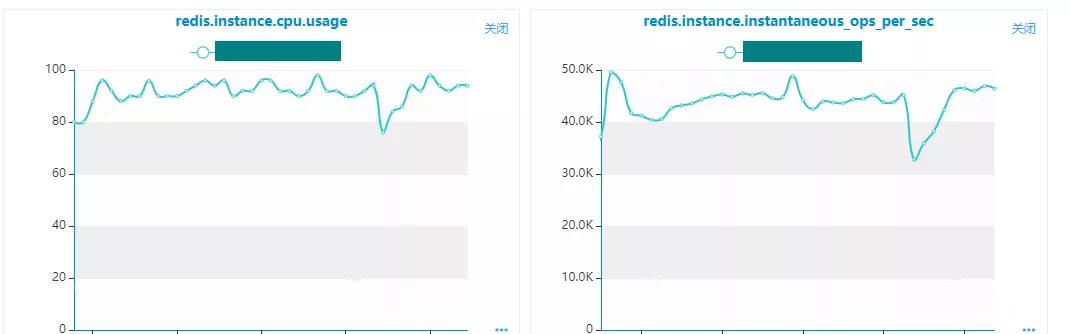
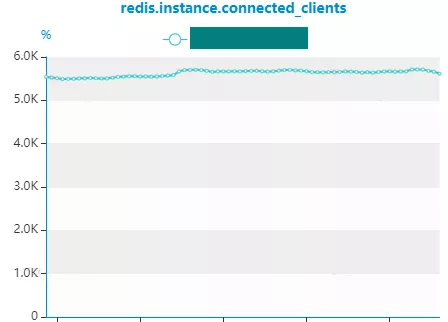
Redis在实时分析这块支持较少,除了基本指标监控外,实时内存数据分析暂不支持。在实际业务场景下如果出现Redis瓶颈,往往监控数据也会缺失,定位问题较难。对Redis的数据分析只能依赖分析工具对Redis快照文件进行分析。因此,对Redis的使用依赖业务对Redis的充分认知,方案设计的时候充分考虑。同时根据业务场景对Redis做好性能压测,了解瓶颈在哪,做好监控和扩缩容准备。
作者:vivo互联网服务器团队-Yu Quan


