
背景现象
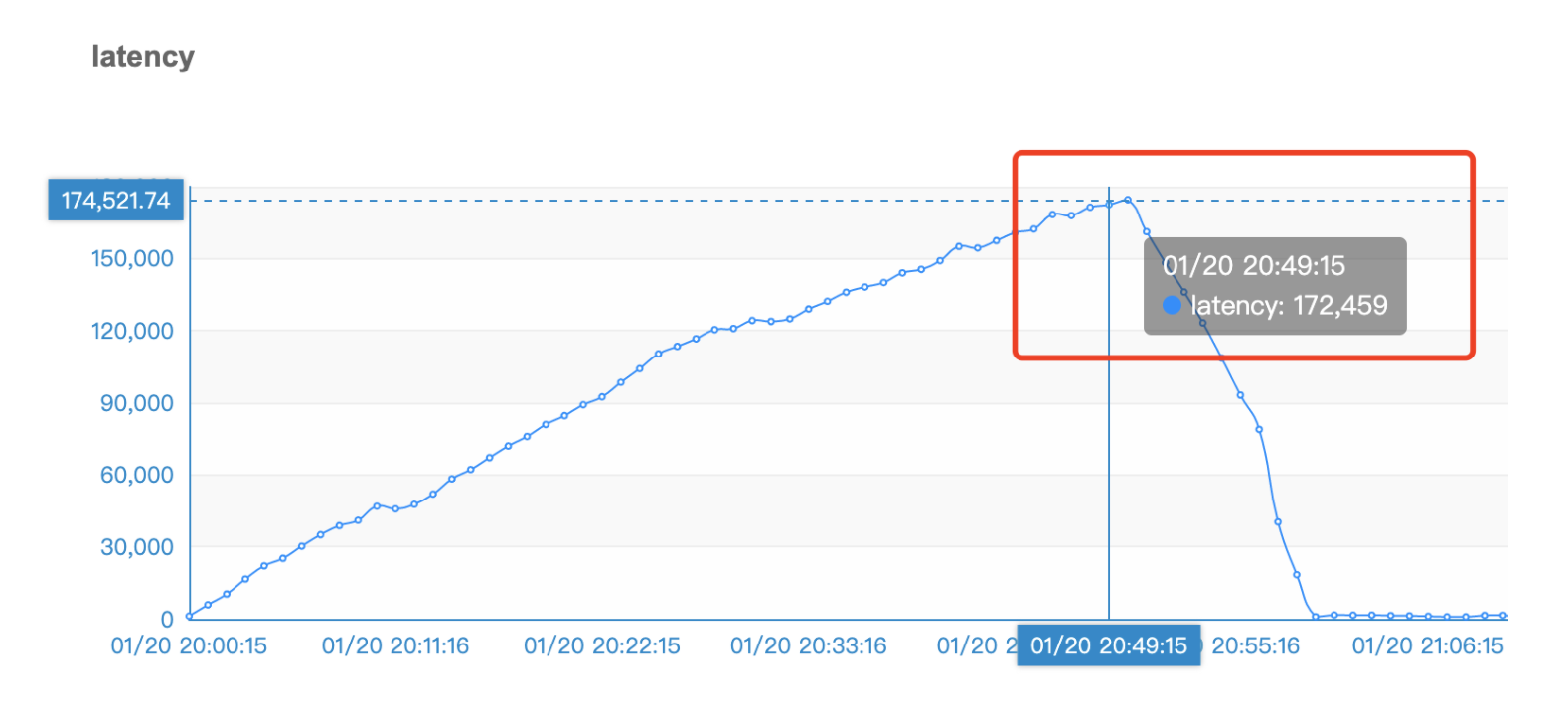
1.20晚上8点业务线开始切换LBS相关流量,在之后的1个小时时间内,积压量呈上升趋势,一路到达50W左右,第二天的图没贴出具体是50W数字,以下是第一天晚上的贴图部分。
现象一:
现象二:
当时现场图后来就找不回来了,凭印象说明了一下数字。
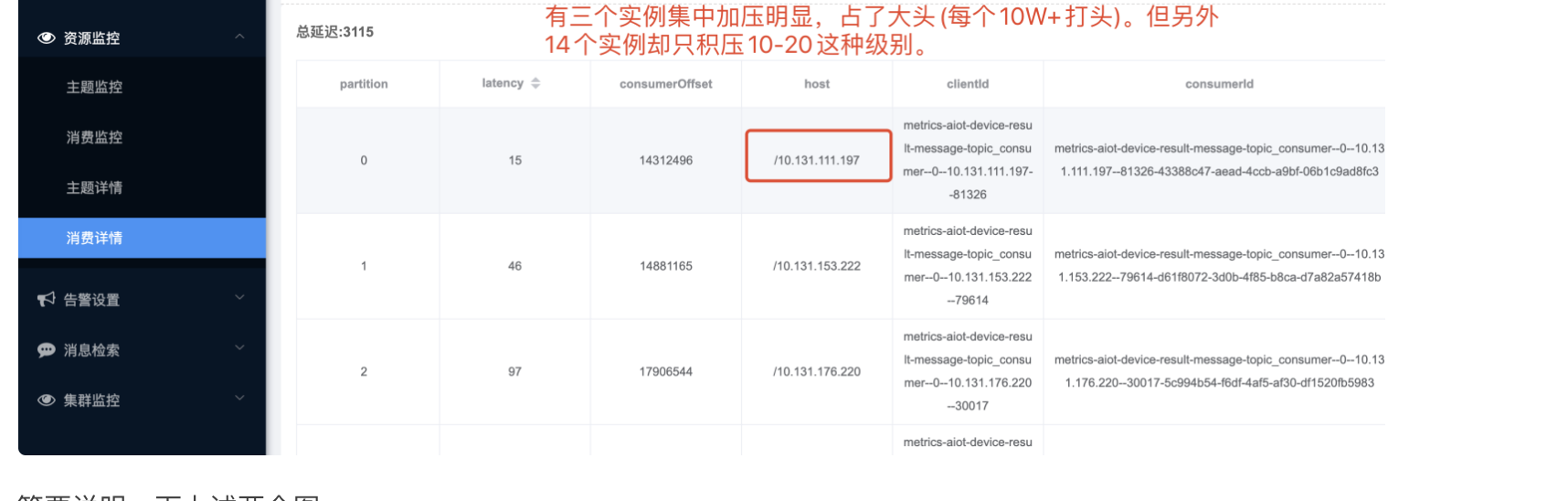
简要说明一下上述两个图
图一:其实很明显,明显看出,消费者消费速度明显跟不上生产者的发送速度,导致出现积压情况。
图二:图二就有点意思了,因为上游通过Kafka消息队列发送消息给我,topic对应的分区数是20个。由于我的应用消费组内消费者实例是17个,所以从宏观上分析,势必会有3个消费者会承担多消费一个分区的情况。这个倒也容易理解。但为什么会积压这么多。个人分析了一下,主要还是跟消费者本身消费的消费业务逻辑有关。因为我的消费业务逻辑是要调用下游一个LBS地图服务的,通过设备上报的WIFE内容经过公司LBS平台接口换取设备当前地理位置坐标信息,但这个地理位置服务,R通过命令:thread-n3-i 500 : 列出500毫秒内最忙的3个线程栈,其中就有两个属于调用地理位置服务的线程。

通过命令:thread-n3-i 500(阿里开源诊断工具Arthas:thread命令) : 列出500毫秒内最忙的3个线程栈,其中就有两个属于调用地理位置服务的线程。

原因分析
分析了具体原因具体是两个层面
- HMS-Client(公司自己封装的调用消息队列的SDK)层面
根据图一,其实想说明一点的是,在本应用调用下游服务延迟高的场景下,从图一的现象看出,消费者的利用率其实不高,topic有20个分片,消费组17个容器实例,14个实例基本对应一个分区,有三个实例对应2个分区,导致资源利用率其实很低,而我们其实是希望在下游服务相应慢的情况下,最好有更多线程参与去消费任务,增加吞吐率,提高处理效率(IO密集型应用,尽量提高处理线程数)。而我们的处理线程数是5个,即最高5个线程会去处理任务,其他都会等待进入
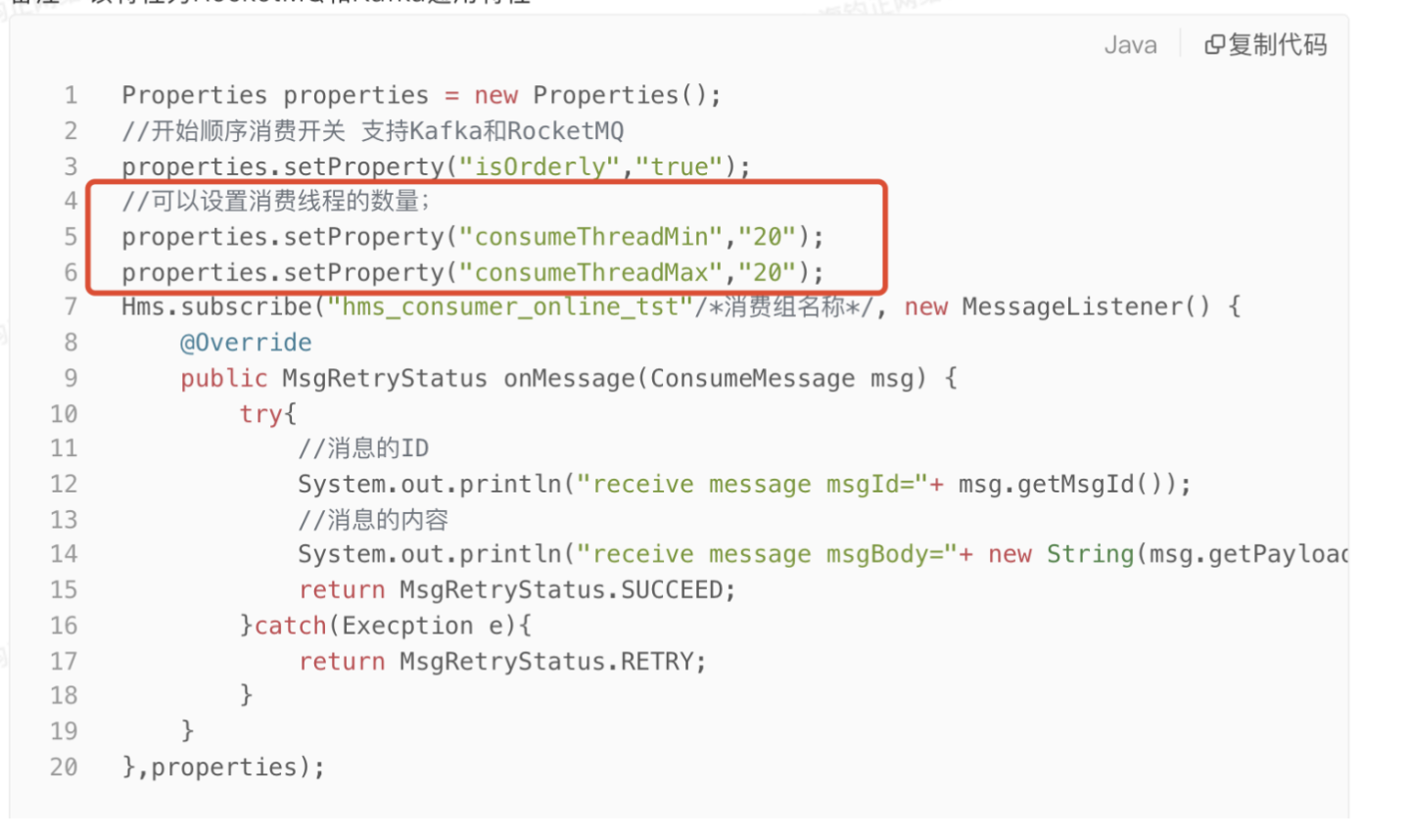
这两个参数,当下应用设置了5个,但我的机器配置是8核16G,参数设置是不合理的。这个参数主要是从其他项目中拷贝过来,没过多关注他,在高并发应用场景下,想不多却成为瓶颈,特别是消费线程内如果涉及到RT很高,QPS上不去的下游服务,就有讲究了。
- 调用下游服务响应延迟高
这个我上述图二已经有详细描述了
解决方案
- 调整Client 消费线程数,从原来的5调整到20个线程
- 增加KAFKA的分片数,临时方案,目前已经让中间件从原来的分片数20调整到60,积压下降的明显。因为消费组内的消费者实例一个承担了基本3-4个分区消息数。
作者:星巴克男孩

