
起因:Mysql大概1700W大表删除1000W左右数据,发现数据大小和索引大小并没有减少思考
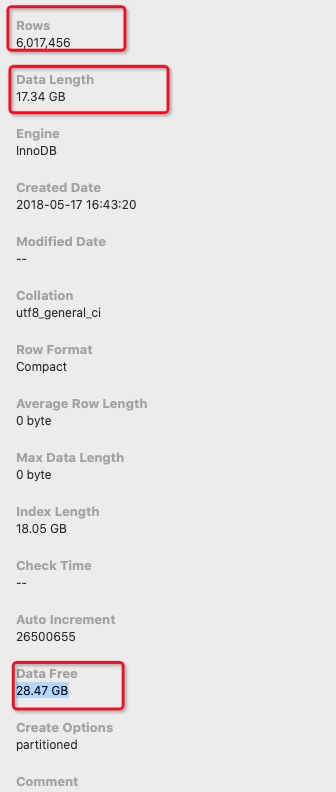
因为近期在重构优化一个业务的时候 发现有一张表(send_log)数据量将近1700W 左右 占用数据大小17G,索引18G左右 而我们的核心应用在使用的时候 会去临时查询这张表 获取一些数据 先不管设计的合不合理吧,因为是维护 不出问题为第一要务 所以想到要物理删除一下表数据 计划把18年1000W左右数据给腾出空间 但运维执行删除操作后 发现情况没有那么理想 行数是少了 但表空间 大小 没降下去
在 InnoDB 中,你的 delete 操作,并不会真的把数据删除,mysql 实际上只是给删除的数据打了个标记,标记为删除,因此你使用 delete 删除表中的数据,表文件在磁盘上所占空间不会变小,我们这里暂且称之为假删除。
Rows原来是1700W 已经delete删除了1000W左右 但dataLength indexLength都没变。。。
在 InnoDB 中,你的 delete 操作,并不会真的把数据删除,mysql 实际上只是给删除的数据打了个标记,标记为删除,因此你使用 delete 删除表中的数据,表文件在磁盘上所占空间不会变小,我们这里暂且称之为假删除。
上面这个是结论,我们可以通过一个例子来验证下。
沿用前面文章中的例子吧,先创建一个存储过程,插入 10w 条数据,然后看下这 10w 条数据占了多大的空间。
- CREATE TABLE `t` (
- `id` int(11) NOT NULL,
- `a` int(11) DEFAULT NULL,
- `b` int(11) DEFAULT NULL,
- PRIMARY KEY (`id`),
- KEY `a` (`a`),
- KEY `b` (`b`)
- ) ENGINE=InnoDB;
- #定义分割符号,mysql 默认分割符为分号;,这里定义为 //
- #分隔符的作用主要是告诉mysql遇到下一个 // 符号即执行上面这一整段sql语句
- delimiter //
- #创建一个存储过程,并命名为 testData
- create procedure testData()
- #下面这段就是表示循环往表里插入10w条数据
- begin
- declare i int;
- set i=1;
- while(i<=100000)do
- insert into t values(i, i, i);
- set i=i+1;
- end while;
- end // #这里遇到//符号,即执行上面一整段sql语句
- delimiter ; #恢复mysql分隔符为;
- call testData(); #调用存储过程
- #下面这两条命令可以查看表文件所占空间大小
- mysql> use information_schema;
- Reading table information for completion of table and column names
- You can turn off this feature to get a quicker startup with -A
- Database changed
- mysql> select concat(round(sum(DATA_LENGTH/1024/1024),2),'M') from tables where table_schema='test' AND table_name='t';
- +-------------------------------------------------+
- | concat(round(sum(DATA_LENGTH/1024/1024),2),'M') |
- +-------------------------------------------------+
- | 3.52M |
- +-------------------------------------------------+
- 1 row in set (0.04 sec)
可以看到 10w 条数据在 mysql 中占用了 3.52M 大小的空间,那么我们执行删除命令 delete from t,再看看呢。
- #先删除表所有数据,再重新查看表文件大小
- mysql> delete from t;
- Query OK, 100000 rows affected (0.46 sec)
- mysql> use information_schema;
- Reading table information for completion of table and column names
- You can turn off this feature to get a quicker startup with -A
- Database changed
- mysql> select concat(round(sum(DATA_LENGTH/1024/1024),2),'M') from tables where table_schema='test' AND table_name='t';
- +-------------------------------------------------+
- | concat(round(sum(DATA_LENGTH/1024/1024),2),'M') |
- +-------------------------------------------------+
- | 3.52M |
- +-------------------------------------------------+
- 1 row in set (0.00 sec)
从结果可以发现表数据被清空后,表所占空间大小并没有变化,这就验证了上面的结论,delete 操作并没有真正删除数据,表的空间并没有被释放。
这些被删除的记录行,只是被标记删除,是可以被复用的,下次有符合条件的记录是可以直接插入到这个被标记的位置的。
比如我们在 id 为 300-600 之间的记录中删除一条 id=500 的记录,这条记录就会被标记为删除,等下一次如果有一条 id=400 的记录要插入进来,那么就可以复用 id=500 被标记删除的位置,这种情况叫行记录复用。
还有一种情况是数据页复用,就是指整个数据页都被标记删除了,于是这整个数据页都可以被复用了,和行记录复用不同的是,数据页复用对要插入的数据几乎没有条件限制。
还以上面那个插入为例,假如要插入的记录是 id=1000,那么就不能复用 id=500 这个位置了,但如果有一整个数据页可复用的话,那么无论 id 值为多少都可以被复用在这个页上。
这些被标记删除的记录,其实就是一个空洞,有种占着茅坑不拉屎的感觉,浪费空间不说,还会影响查询效率。
因为你要知道,mysql 在底层是以数据页为单位来存储和读取数据的,每次向磁盘读一次数据就是读一个数据页,然而每访问一个数据页就对应一次磁盘 IO 操作,磁盘 IO 相对内存访问速度是相当慢的。
所以你想想,如果一个表上存在大量的数据空洞,原本只需一个数据页就保存的数据,由于被很多空洞占用了空间,不得不需要增加其他的数据页来保存数据,相应的,mysql 在查询相同数据的时候,就不得不增加磁盘 IO 操作,从而影响查询速度。
其实不仅仅是删除操作会造成数据空洞,插入和更新同样也会造成空洞,这里就不细说了,你知道就行。
因此,一个数据表在经过大量频繁的增删改之后,难免会产生数据空洞,浪费空间并影响查询效率,通常在生产环境中会直接表现为原本很快的查询会变得越来越慢。
对于这种情况,我们通常可以使用下面这个命令就能解决数据空洞问题。
- optimize table t
这个命令的原理就是重建表,就是建立一个临时表 B,然后把表 A(存在数据空洞的表) 中的所有数据查询出来,接着把数据全部重新插入到临时表 B 中,***再用临时表 B 替换表 A 即可,这就是重建表的过程。
我们再来试验一下,看看效果。
- mysql> optimize table t;
- +--------+----------+----------+-------------------------------------------------------------------+
- | Table | Op | Msg_type | Msg_text |
- +--------+----------+----------+-------------------------------------------------------------------+
- | test.t | optimize | note | Table does not support optimize, doing recreate + ****yze instead |
- | test.t | optimize | status | OK |
- +--------+----------+----------+-------------------------------------------------------------------+
- 2 rows in set (0.39 sec)
- mysql> use information_schema;
- Reading table information for completion of table and column names
- You can turn off this feature to get a quicker startup with -A
- Database changed
- mysql> select concat(round(sum(DATA_LENGTH/1024/1024),2),'M') from tables where table_schema='test' AND table_name='t';
- +-------------------------------------------------+
- | concat(round(sum(DATA_LENGTH/1024/1024),2),'M') |
- +-------------------------------------------------+
- | 0.02M |
- +-------------------------------------------------+
- 1 row in set (0.00 sec)
可以看到表文件大小已经变成 0.02M了,说明表空间被释放了,这个 0.02M 应该是定义表结构文件的大小了。
另外下面这个命令也可以实现重建表,可以达到跟上面一样的效果,而且推荐大家使用下面这个命令,大家可以试试。
- alter table t engine=InnoDB
注意本文内容是基于 InnoDB 引擎,对于其他引擎可能存在一些差异。原创不易,如果文章对你有启发,就点个在看吧,有疑问也可以在下面留言交流,也可以与我私信交流,感谢支持。
作者:星巴克男孩


